import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
if __name__ == '__main__':
data = pd.read_csv("D:\\GoogleWebDown\\testdata.csv")
# print(data)
# figure = plt.figure()
# plt.scatter(data.loc[:, 'Exam1'], data.loc[:, 'Exam2'])
# plt.title('Exam1-Exam2')
# plt.xlabel('Exam1')
# plt.ylabel('Exam2')
# # plt.show()
# # pass=1赋值给PASS变量
mask = data.loc[:, 'Pass'] == 1
# # print(mask)
# figure2 = plt.figure()
# passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask])
# failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask])
# plt.title('first-Exam1-Exam2')
# plt.xlabel('Exam1')
# plt.ylabel('Exam2')
# plt.legend((passed, failed), ('passed', 'failed'))
#plt.show()
# 将Exam1和Exam2作为x变量,Pass作为y变量,调用sklearn的逻辑回归模型,训练数据
x = data.drop(['Pass'], axis=1)
y = data.loc[:, 'Pass']
x1 = data.loc[:, 'Exam1']
x2 = data.loc[:, 'Exam2']
LG = LogisticRegression()
LG.fit(x,y)
y_predict = LG.predict(x)
#print(y_predict)
accuracy_score_1 = accuracy_score(y,y_predict)
print('accuracy_score_1:\n',accuracy_score_1)
# theta0 + theta1 * x1 + theta2 * x2 = 0
theta0 = LG.intercept_
theta1,theta2 = LG.coef_[0][0],LG.coef_[0][1]
#print(theta0,theta1,theta2)
x2_new = -(theta0+theta1*x1) / theta2
print(x2_new)
fih3 = plt.figure()
passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask])
failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask])
plt.plot(x1,x2_new)
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.legend((passed, failed), ('passed', 'failed'))
plt.show()
# 预测Exam1 = 75,Exam2 = 60时,该同学能否通过Exam3
# y_test = LG.predict([[75,50]])
# print('Pass' if y_test==1 else 'Failed')
# 二阶边界函数
X1_X1 = x1 * x1
# print(X1_X1)
X2_X2 = x2 * x2
X1_X2 = x1 * x2
X_new = {'X1': x1, 'X2': x2, 'X1_X1': X1_X1, 'X2_X2': X2_X2, 'X1_X2': X1_X2}
X_new = pd.DataFrame(X_new)
# print(X_new)
LR2 = LogisticRegression()
LR2.fit(X_new, y)
y_predict2 = LR2.predict(X_new)
score = accuracy_score(y, y_predict2)
print('二阶score:\n',score)
print('before sort X1_new:\n',x1)
X1_new = np.sort(x1)
print('after sort X1_new:\n', X1_new)
theta0 = LR2.intercept_
theta1, theta2, theta3, theta4, theta5 = LR2.coef_[0][0], LR2.coef_[0][1], LR2.coef_[0][2], LR2.coef_[0][3], \
LR2.coef_[0][4]
a = theta4
b = theta5 * X1_new + theta2
c = theta0 + theta1 * X1_new + theta3 * X1_new*X1_new
X2_new_boundary = (-b + np.sqrt(b * b - 4 * a * c)) / (2 * a)
print(X2_new_boundary)
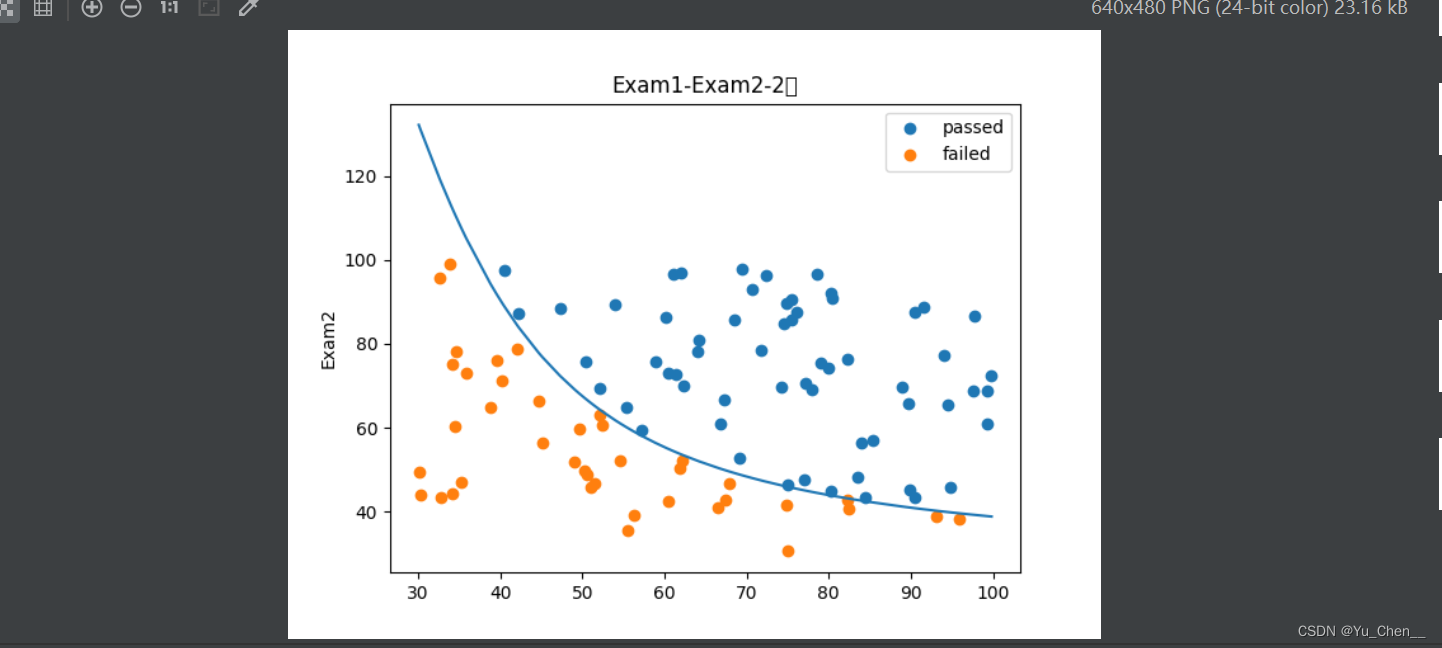
figure11 = plt.figure()
passed = plt.scatter(data.loc[:, 'Exam1'][mask], data.loc[:, 'Exam2'][mask])
failed = plt.scatter(data.loc[:, 'Exam1'][~mask], data.loc[:, 'Exam2'][~mask])
plt.plot(X1_new, X2_new_boundary)
plt.title('Exam1-Exam2-2阶')
# plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.legend((passed, failed), ('passed', 'failed'))
plt.show()
#预测
x11 = 75
x22 = 50
X11_X11 = x11 * x11
X22_X22 = x22 * x22
X11_X22 = x11 * x22
X_new2 = {'X1': x11, 'X2': x22, 'X1_X1': X11_X11, 'X2_X2': X22_X22, 'X1_X2': X11_X22}
X_new2 = pd.DataFrame(X_new2,index=[0])
print('X_new2:::',X_new2)
y_test = LR2.predict(X_new2)
print('Pass' if y_test==1 else 'Failed')






















 1192
1192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









