







最近要在imagenet数据集上做实验,以前只知道这个数据集很大,但是没用过,这次亲自下载然后按照训练集和验证集划分好了,记录一下。
主要参考了这个 https://zhuanlan.zhihu.com/p/370799616
1. 数据集下载
数据集官网:https://www.image-net.org/challenges/LSVRC/index.php
目前实验一般都用ILSVRC 2012,下载需要用学生邮箱注册,之后能进到下载界面
https://image-net.org/challenges/LSVRC/2012/2012-downloads.php
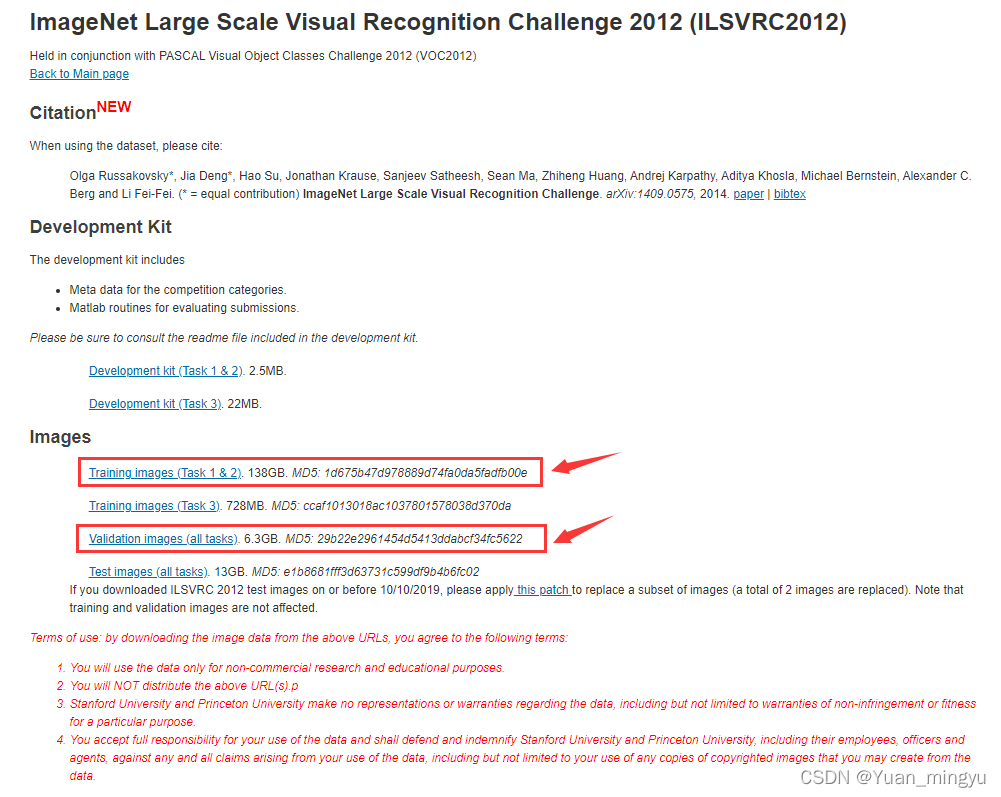
如果是图像识别任务的话,下载这两个就可以了。
放上链接:
Training images (Task 1 & 2)
Validation images (all tasks)
正常下载的话应该是非常慢,而且由于数据集很大,容易中断,建议科学上网。
这里有个磁力链接,亲测可用:https://hyper.ai/datasets/4889
2. 数据集处理
已经下载了两个数据集,一个是训练集,一个是验证集,现在就要把这数据集整理成可以供模型直接加载的形式。
2.1 训练集
首先解压 ILSVRC2012_img_train.tar到train,里边包含1000个小的tar压缩包,每一个对应一类的图片(压缩包的名称就代表这一类,不要修改),所以再将他们都解压成文件夹就好了。
先解压
mkdir train
tar xvf ILSVRC2012_img_train.tar -C ./train
因为数量多,写个脚本 touch unzip.sh
#!/bin/bash
dir=./train
for x in `ls $dir/*tar`
do
filename=`basename $x .tar`
mkdir $dir/$filename
tar -xvf $x -C $dir/$filename
done
rm *.tar
添加可执行权限,执行一下
chmod +x ./unzip.sh
./unzip.sh
由于压缩包ILSVRC2012_img_train.tar比较大,处理后可以删除了。可以直接把train.tar先移动到train中,再进行操作。
最终训练集形式:

2.2 验证集
验证集比较简单,只有50000张图片,直接解压 ILSVRC2012_img_val.tar就可以。但是为了后续的使用,也需要把这些图片分成1000类(创建1000个文件夹,把对应类的图片放进去,与训练集结构保持一致)。
先解压
mkdir val
tar xvf ILSVRC2012_img_val.tar -C ./val
分类的过程可以借助官网中给的development kit中的 data/ILSVRC2012_validation_ground_truth.txt 和 data/meta.mat 进行划分,但是需要自己写脚本,比较麻烦,所以这里用个现成的脚本,直接处理一下就行。
进入val,下载脚本,执行
cd val
wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh
chmod +x ./valprep.sh
./valprep.sh
rm valprep.sh
最终验证集形式:
3. 数据集加载
数据集处理后格式:
-imagenet
-train
-val
使用pytorch进行数据集加载
封装数据加载模块
# data_loader.py
import os
import torch
import torchvision.transforms as transforms
import torchvision.datasets as datasets
def data_loader(root, batch_size=256, workers=1, pin_memory=True):
traindir = os.path.join(root, 'train')
valdir = os.path.join(root, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
)
val_dataset = datasets.ImageFolder(
valdir,
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=workers,
pin_memory=pin_memory,
sampler=None
)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=workers,
pin_memory=pin_memory
)
return train_loader, val_loader
主程序调用
# Data loading
from data_loader import data_loader
def main():
...
# args.data = './imagenet'
train_loader, val_loader = data_loader(args.data, args.batch_size, args.workers, args.pin_memory)
...

















 1971
1971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









