






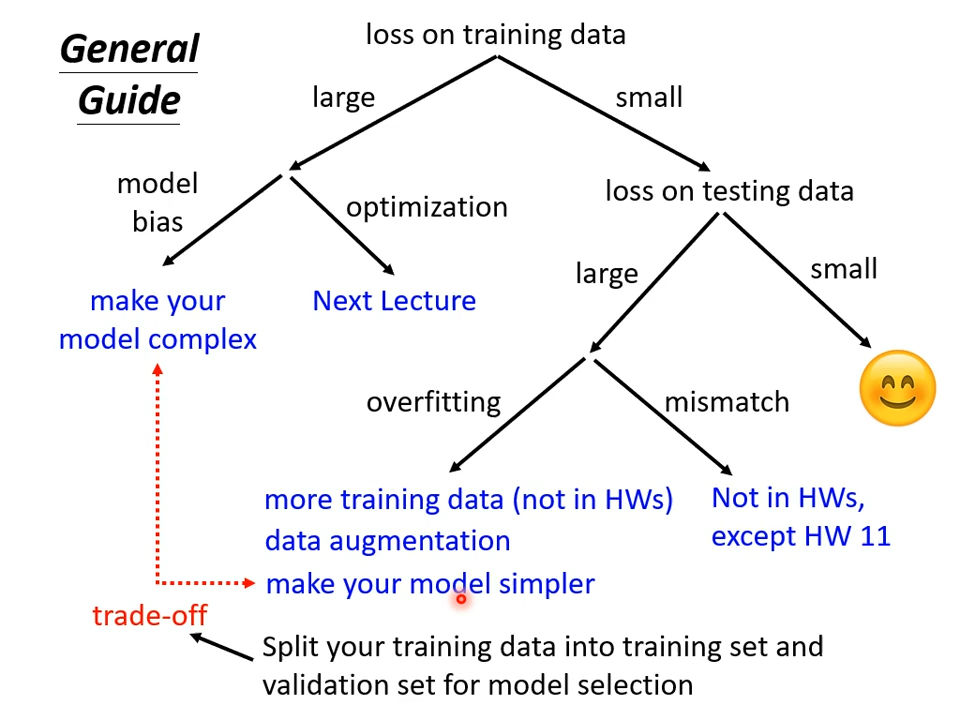
2.1 模型偏差
问题原因:
- 模型过于简单(大海捞针,大海里没有针。)
- 损失函数无法降低(大海捞针,在大海中无法找到这个针。)
但是并不是训练的时候,损失大就代表一定是模型偏差,可能会遇到另外一个问题:优化做得不好。 这里我们引入了下文:优化问题。
2.2优化问题
梯度下降等优化方法存在局限性,可能会卡在局部最小值处,无法找到真正让损失很低的参数。同时,模型的灵活性也是关键因素之一,当模型的灵活性不足时,即使使用梯度下降等优化方法也无法获得更好的结果。
首先,我们的问题是上面提问两种问题的哪一个?
一个建议判断的方法,通过比较不同的模型来判断模型现在到底够不够大。举个例子,这一个实验是从残差网络的论文里面节录出来的。
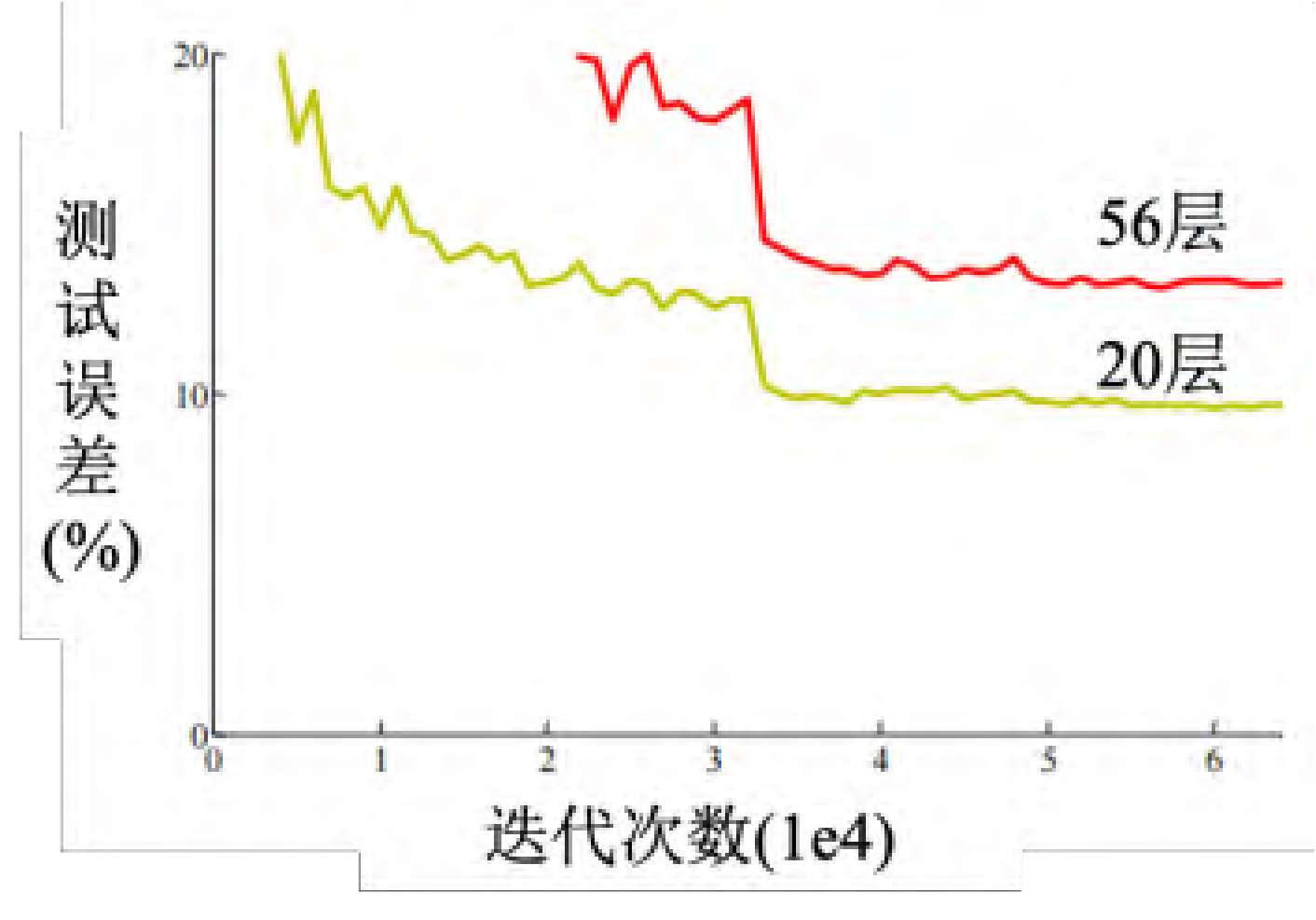
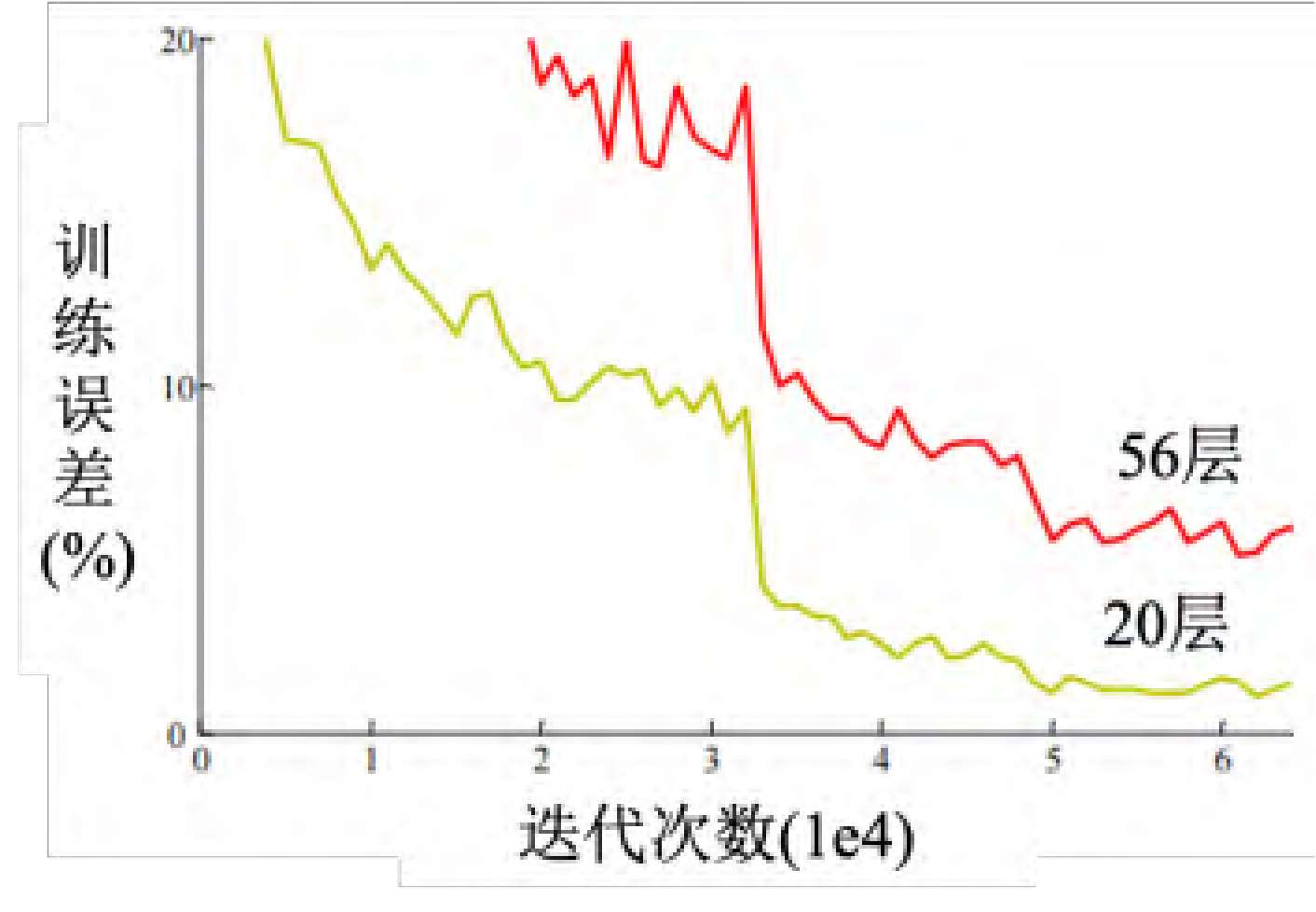
这篇论文在测试集上测试两个网络,一个网络有 20 层 ,一个网络有 56 层
横轴指的是训练的过程,就是参数更新的过程,随着参数的更新,损失会越来越低,但是结果20层的损失比较低,56 层的损失还更高。残差网络是比较早期的论文, 2015年的论文。很多人看到这张图认为这个代表过拟合,深度学习不奏效, 56层太深了不奏效,根本就不需要这么深。但 这个不是过拟合,并不是所有的结果不好,都叫做过拟合。在训练集上, 20层的网络损失其实是比较低的, 56层的网络损失是比较高的,如图 所示,这代表 层的网络的优化没有做好,它的优化不给力。
给大家的建议是 :看到一个从来没有做过的问题,
- 可以先跑一些比较小的、比较浅的网络,或甚至用一些非深度学习的方法,比如线性模型、支持向量机(SVM)
- 接下来还缺一个深的模型,如果深的模型跟浅的模型比起来,深的模型明明灵活性比较大,但损失却没有办法比浅的模型压得更低代表说优化有问题,梯度下降不给力,因此要有一些其它的方法来更好地进行优化。
如果训练数据上面的损失小,测试数据上的损失大,可能是真的过拟合。
2.3 过拟合
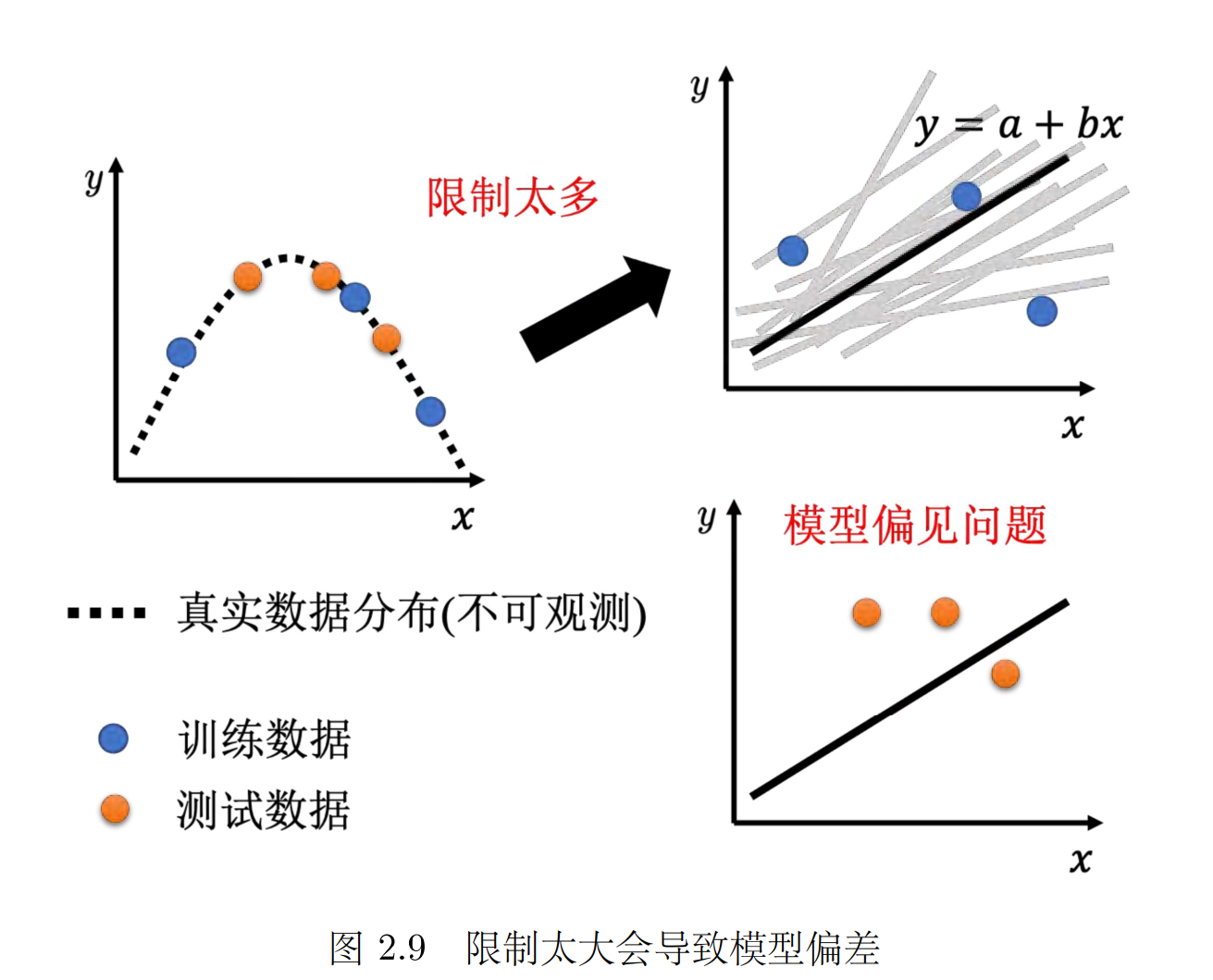
为什么会有过拟合这样的情况呢?举一个极端的例子,这是训练集。假设根据这些训练集,某一个很废的机器学习的方法找出了一个一无是处的函数。这个一无是处的函数,只要输入 x 有出现在训练集里面,就把它对应的 y 当做输出。如果 x 没有出现在训练集里面,就输出一个随机的值。这个函数啥事也没有干,其是一个一无是处的函数,但它在训练数据上的损失是 。把训练数据通通丢进这个函数里面,它的输出跟训练集的标签是一模一样的,所以在训练数据上面,这个函数的损失可是 呢,可是在测试数据上面,它的损失会变得很大,因为它其实什么都没有预测,这是一个比较极端的例子,在一般的情况下,也有可能发生类似的事情。
** 如何避免过拟合现象的发生**,主要有两种方法:一是增加训练数据量,二是对模型进行限制。对于第一种方法,可以通过数据增强(data augmentation ,数据增强就是根据问题的理解创造出新的数据。
)的方式来扩充训练数据,但对于第二种方法,有这几种方法:1,给模型比较少的参数 e.g.全连接网络( FCN)其实是一个比较有灵活性的架构,而卷积神经网络(CNN)是一个比较有限制的架构。 2,用比较少的特征。3,还有别的方法,比如早停(Early stopping )、正则化(regularization)和丢弃法(dropout method)
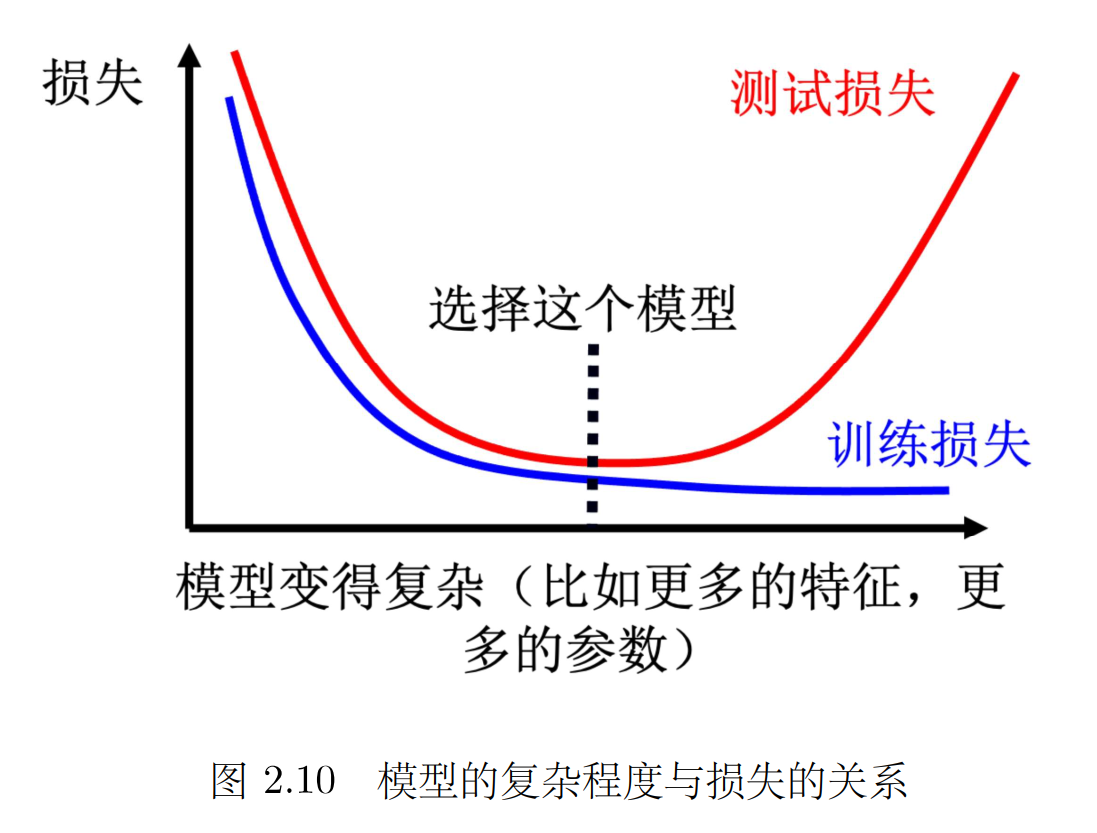
模型过于简单也会导致模型偏差的问题,因此需要在训练集和测试集上寻找平衡点,选取适当的模型复杂度。(不能过于复杂,当复杂的程度,超过某一个程度以后,测试损失就会突然暴增了。这就是因为当模型越来越复杂的时候,复杂到某一个程度,过拟合的情况就会出现,所以在训练损失上面可以得到比较好的结果。 )
计算分数的时候,会同时考虑公开和私人的分数。
Q:为什么要把测试集分成公开和私人?
A:假设所有的数据都是公开,就算是一个一无是处的模型,它也有可能在公开的数据上面得到好的结果。如果只有公开的测试集,没有私人测试集,写一个程序不断随机产生输出就好,不断把随机的输出上传到 ,可以随机出一个好的结果。这个显然没有意义。而且如果公开的测试数据是公开的,公开的测试数据的结果是已知的,一个很废的模型也可能得到非常好的结果。不要用公开的测试集调模型,因为可能会在私人测试集上面得到很差的结果,不过因为在公开测试集上面的好的结果也有算分数。
2.4交叉验证
比较合理选择模型的方法是把训练的数据分成两半,一部分称为训练集( training set),一部分是验证集(validation set )。比如 90%的数据作为训练集,有 10%的数据作为验证集。在训练集上训练出来的模型会使用验证集来衡量它们的分数,根据验证集上面的分数去挑选结果
来一个【doge】🤤根据过去的经验,就在公开排行榜上排前几名的,往往私人测试集很容易就不好
最好的做法,就是用验证损失,最小的直接挑就好了,不要管公开测试集的结果。在实现上,不太可能这么做,因为公开数据集的结果对模型的选择,可能还是会有些影响的。理想上就用验证集挑就好,有过比较好的**基线(Baseline )**算法以后,就不要再去动它了,就可以避免在测试集上面过拟合。但是这边会有一个问题,如果随机分验证集,可能会分得不好,分到很奇怪的验证集,会导致结果很差,如果有这个担心的话,可以用 k 折交叉验证(k-fold cross validation),如图 所示。k 折交叉验证就是先把训练集切成 k 等份。
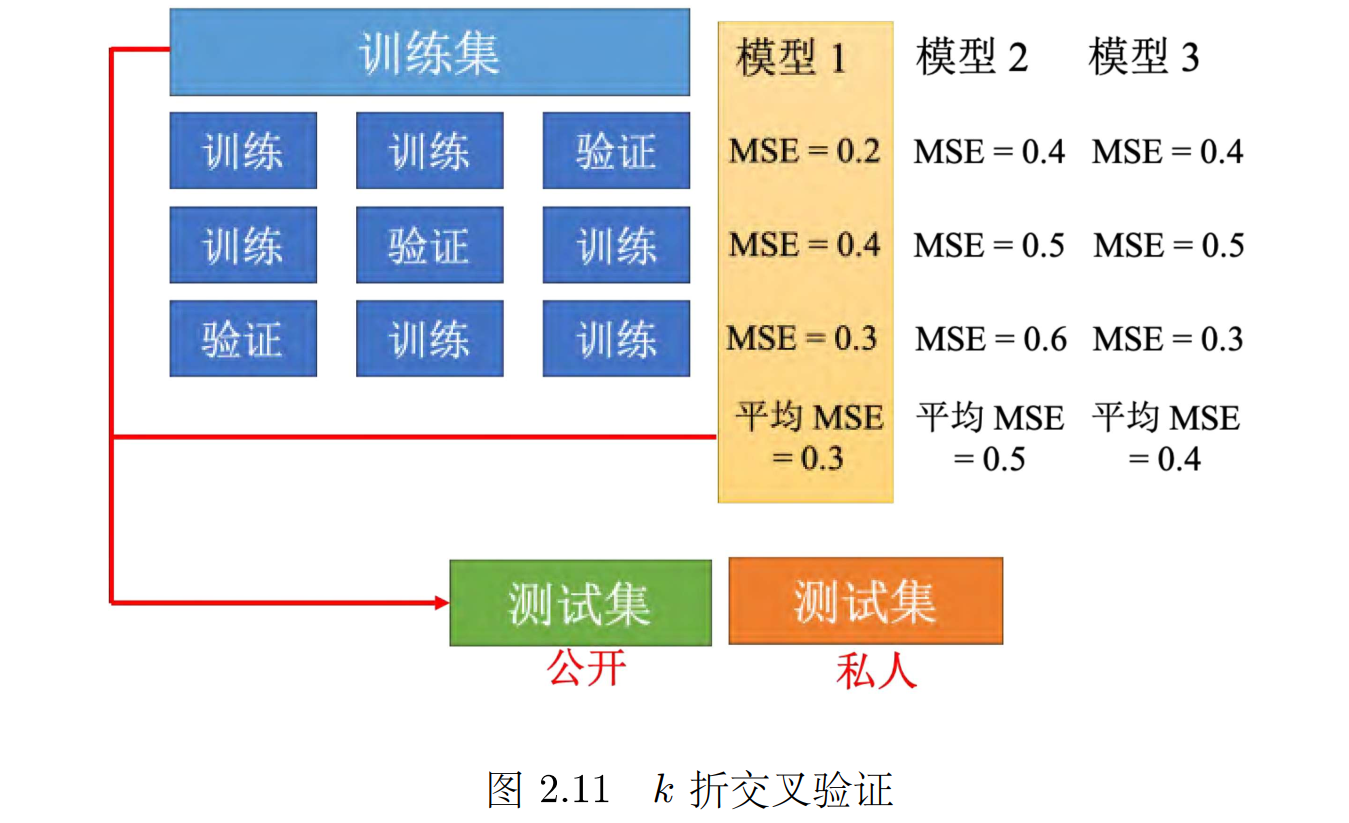
把每一个模型在这 3 种情况的结果,都平均起来,再看看谁的结果最好假设现在模型 1 的结果最好,3 折交叉验证得出来的结果是,模型 1 最好。再把模型 1 用在全部的训练集上,训练出来的模型再用在测试集上面。
2.5不匹配
2月 26日出现了反常的情况。这种情况应该算是另外一种错误的形式,这种错误的形式称为不匹配( mismatch)。
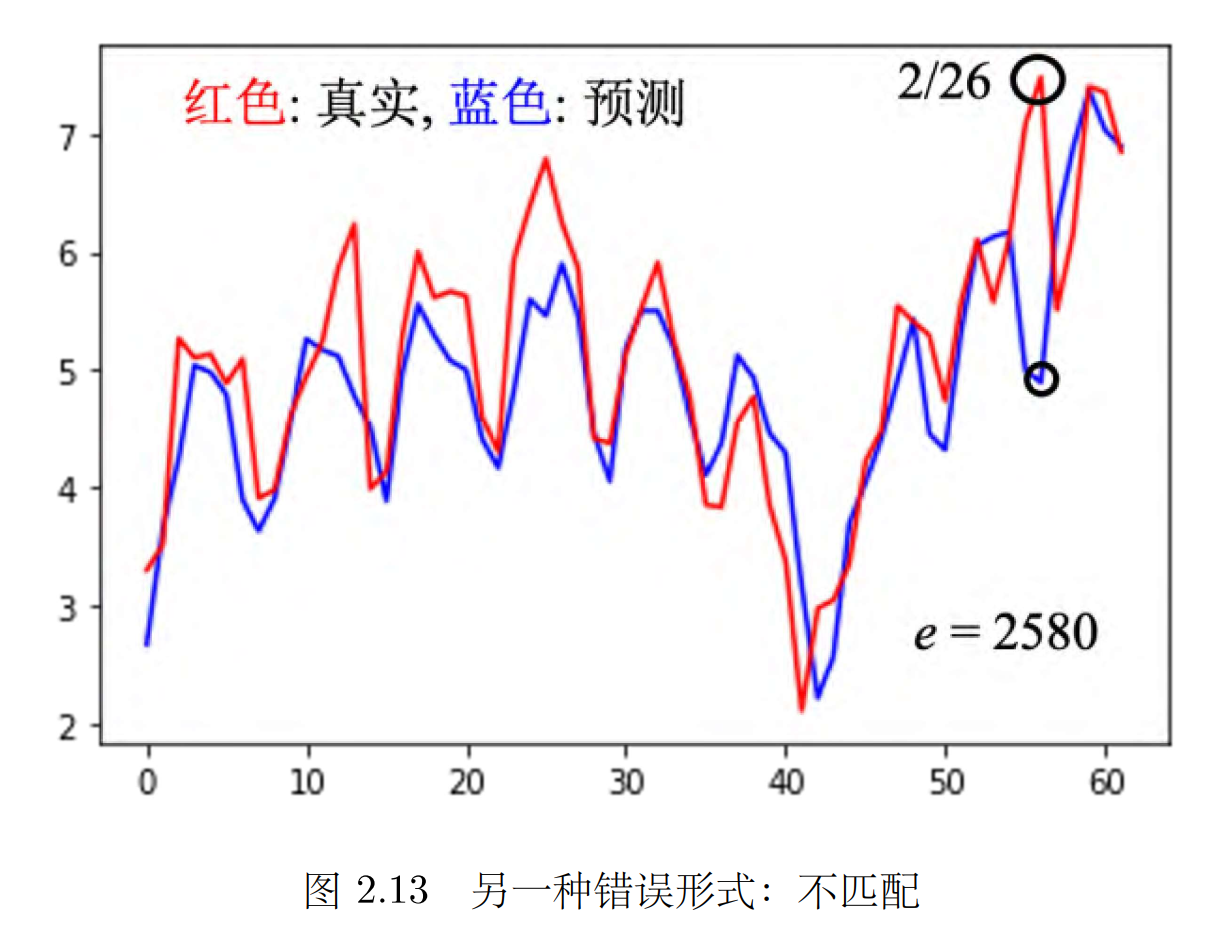
不匹配和过拟合的不同:
不匹配跟过拟合其实不同,一般的过拟合可以用搜集更多的数据来克服,但是不匹配是指训练集跟测试集的分布不同,**训练集再增加其实也没有帮助了。 **
loss指示















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









