






在当前的技术发展下,越来越多的基于生成式的软件出现,例如通过一张照片,让软件自动生成一段音乐,或者是让软件自动生成一段视频。这些软件的背后都有一个基础模型——生成模型。
8.1 生成对抗网络
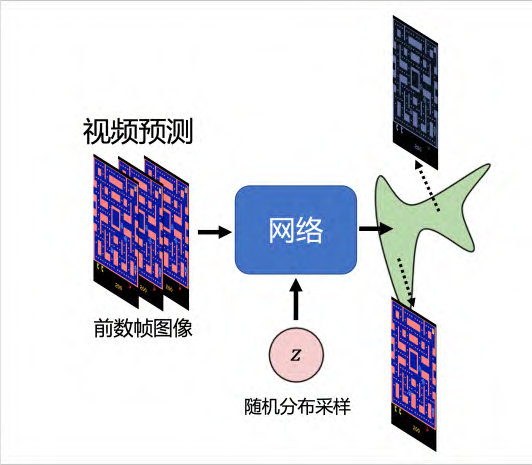
本章介绍 **生成模型(generative model)** 。到目前为止,我们学习到的网络本质上都是一个函数,即提供一个输入 _ x_ ,网络就可以输出一个结果 _ y_ 。** **不同于之前介绍的模型,生成模型中网络会被作为一个生成器来使用。在模型输入时,会将一个随机变量 z与原始输入 x一并输入到模型中,这个变量是从随机分布中采样得到。通常,我们对于该随机分布的要求是其足够简单,可以较为容易地进行采样,或者可以直接写出该随机分布的函数,例如**高斯分布(Gaussian distribution) 、 均匀分布(uniform distribution) **等等。因此每次有一个输入 x的同时,我们都从随机分布中采样得到 z,来得到最终的输出 y。随着采样得到的 z的不同,我们得到的输出 y也会不一样。同理,对于网络来说,其输出也不再来固定,而变成了一个复杂的分布,我们也将这种可以输出一个复杂分布的网络称为生成器。

那么如何训练生成器。由于任务需要“创造性”的输出,或者我们需要知道一个可以输出多种可能的模型,且这些输出都是对的模型的时候,生成模型才能够满足需求。因此,我们可以让网络有概率的输出一切可能的结果,或者说输出一个概率的分布,而不是原来的单一的输出。举个例子,如果我们要让网络预测下一帧的游戏画面,我们可以将过去的几帧游戏画面作为输入,让网络输出一个分布,包含向左转和向右转的可能性。这样就能够避免监督学习中的“两面讨好”问题了。
首先,我们为什么要需要训练生成器,为什么需要输出一个分布呢?下面介绍一个视频预测的例子,即给模型一段的视频短片,然后让它预测接下来发生的事情。视频环境是小精灵游戏,预测下一帧的游戏画面
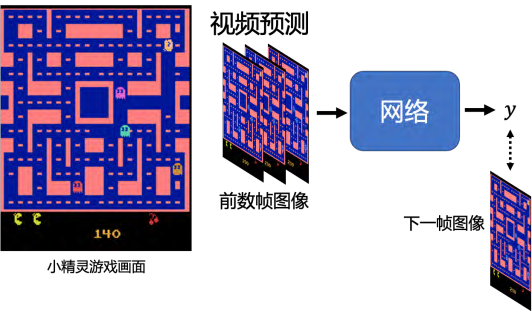
要预测下一帧的游戏画面,我们只需要输入给网络过去几帧游戏画面。要得到这样的训练数据很简单,只需要在玩小精灵的同时进行录制,就可以训练我们的网络,只要让网络的输出 y,与我们的真实图像越接近越好。当然在实践中,我们为了保证高效训练,我们会将每一帧画面分割为很多块作为输入,并行分别进行预测。我们接下来为了简化,假设网络是一次性输入的整个画面。如果我们使用前几章介绍的基于监督学习的训练方法,我们得到的结果可能会是的十分模糊的甚至游戏中的角色消失、出现残影的。
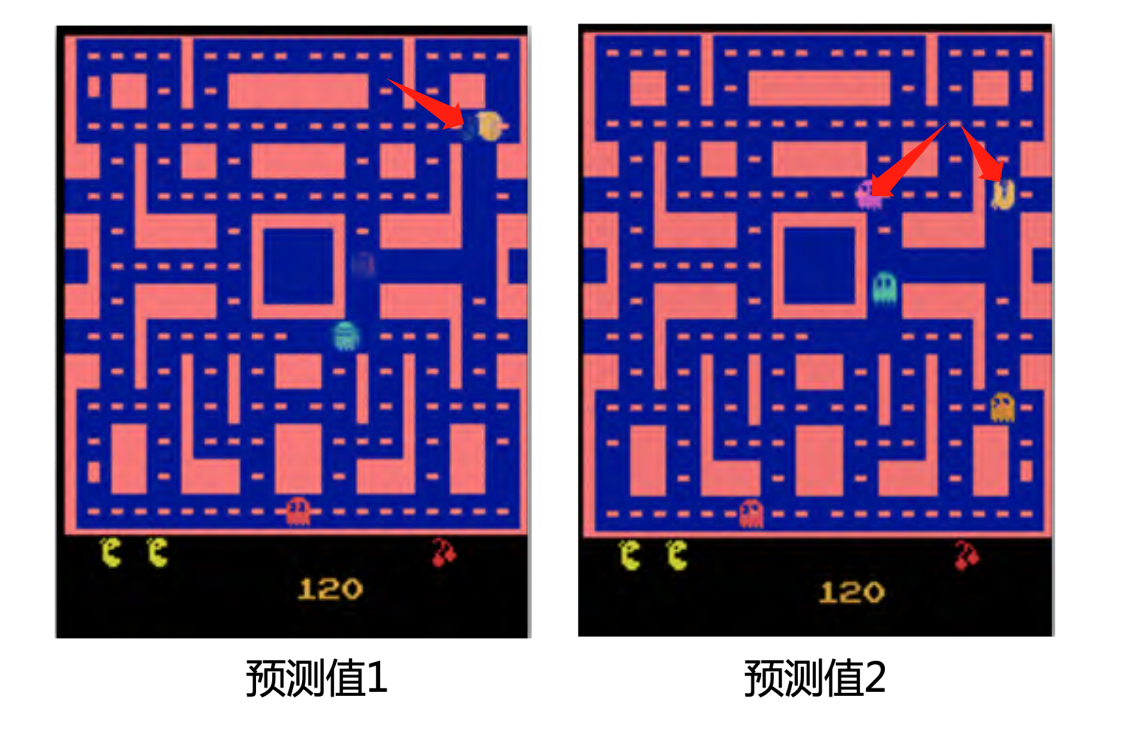
造成该问题的原因是,我们监督学习中的训练数据对于同样的转角同时存储有角色向左转和向右转两种输出。当我们在训练的时候,对于一条向左转的训练数据,网络得到的指示就是要学会游戏角色向左转的输出。同理,对于一条向右转的训练数据,网络得到的指示就是学会角色向右转的输出。但是实际上这两种数据可能会被同时训练,所以网络就会学到的是“两面讨好”。当这个输出同时距离向左转和向右转最近,网络就会得到一个错误的结果————向左转是对的,向右转也是对的。
所以我们应该如何解决这个问题呢?答案是让网络有概率的输出一切可能的结果,或者说输出一个概率的分布,而不是原来的单一的输出。
回到生成器的讨论中,我们什么需要这类的生成模型呢?答案是当我们的任务需要“创造性”的输出,或者我们想知道一个可以输出多种可能的模型,且这些输出都是对的模型的时候。这可以类比于,让很多人一起处理一个开放式的问题,或者是头脑风暴,大家的回答五花八门可以各自发挥,但是回答都是正确的。所以生成模型也可以被理解为让模型自己拥有了创造的能力。再举两个更具体的例子,对于画图,假设画一个红眼睛的角色,那每个人可能画出来或者心中想的动画人物都不一样。对于聊天机器人,它也需要有创造力。比如我们对机器人说,你知道有哪些童话故事吗?聊天机器人会回答安徒生童话、格林童话甚至其他的,没有一个标准的答案。**所以对于我们的生成模型来说,其需要能够输出一个分布,或者说多个答案。当然在生成模型中,非常知名的就是生成式对抗网络(generative adversarial network) ,我们通常缩写为 GAN。这一节我们就讲介绍这个生成对抗网络。**** **
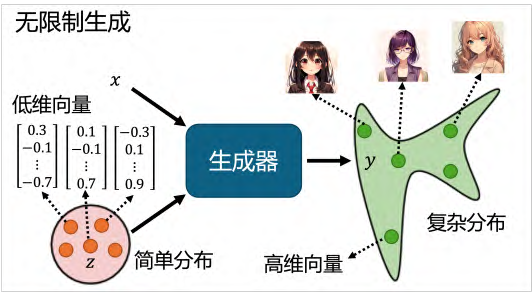
我们通过让机器生成动画人物的面部来形象地介绍 GAN,首先介绍的是无限制生成(unconditional generation) ,也就是我们不需要原始输入 x。其对应的就是需要原始输入 x的条件型生成(conditional generation) 。
对于无限制的 GAN,它的唯一输出就是 z,这里假设为正态分布采样出的向量。其通常是一个低维的向量,例如 50、 100 的维度。我们首先从正态分布中采样得到一个向量 z,并输入到生成器中,生成器会给我们一个对应的输出——一个动漫人物的脸。我们聚焦一下生成器输出一个动漫人物面部的过程。其实很简单,一张图片就是一个高维的向量,所以生成器实际上做的事情就是输出一个高维的向量,比如是一个 64×64 的图片(如果是彩色图片那么输出就是 64×64×3)。当输入的向量 z不同的时候,生成器的输出就会跟着改变,所以我们从正态分布中采样出不同的 z,得到的输出 y 也就会不同,动漫人脸照片也不同。当然,我们也可以选择其他的分布,但是根据经验分布之间的差异可能并没有非常大。大家可以找到一些文献,并且尝试去探讨不同的分布之间的差异。我们这里选择正态分布是因为其简单且常见,而且生成器自己会想方设法把这个简单的分布对应到一个更复杂的分布。所以我们后续的讨论都以正态分布为前提。
8.1.2 辨别器
GAN是由**生成器和判别器**组成。生成器的任务是生成逼真的样本,而判别器的任务则是判断一个样本是否真实。通过不断地训练生成器和判别器,GAN可以生成高质量的样本,例如动漫人物的面部等。在深度学习中,除了生成器外,还需要训练一个**判别器(discriminator)**,它通常是一个神经网络。判别器的作用是输入一张图片,输出一个标量值,数值越大则代表这张图片越像真实的动漫人物图像。判别器和生成器一样都是神经网络,可以根据需要选择不同的结构,比如卷积神经网络等。在训练过程中,生成器和判别器相互竞争,互相促进,最终达到生成高质量的动漫人物图像的目的。

这是一个可能得训练过程:

8.2 生成器与辨别器的训练过程
在训练开始前,需要对生成器和判别器进行参数初始化。**首先,固定生成器,只训练判别器。**由于生成器的初始参数是随机初始化的,因此它没有学到任何东西。通过输入一系列采样得到的向量给生成器,它的输出肯定是随机、混乱的图片,与真实的动漫头像完全不同。同时,我们需要一个包含许多动漫人物头像的图像数据库,可以从其中采样一些动漫人物头像图片来与生成器产生的结果进行对比,从而训练判别器。判别器的训练目标是分辨真正的动漫人物与生成器产生的动漫人物之间的差异。具体来说,我们将真正的图片标记为1,生成器产生的图片标记为0。接下来,对于判别器来说,这是一个分类或回归问题。如果是分类问题,我们将真正的图片视为类别1,生成器产生的图片视为类别0,然后训练一个分类器。如果是回归问题,判别器看到真实图片就需要输出1,生成器的图片就需要输出0,并且进行之间的打分。总之,判别器需要学习如何区分真实图像和生成图像之间的差异。在完成判别器的训练后,**接下来固定判别器并训练生成器。**训练生成器的目的是让它想办法欺骗判别器,因为在第一步中判别器已经学会了分辨真实图像和假图像之间的差异。生成器如果能够成功欺骗判别器,那么它可以产生以假乱真的图片。具体操作如下:首先,生成器输入一个向量,可以来自高斯分布中的采样。然后,生成器会产生一张图片。接着,这张图片会被输入到判别器中,判别器会给出一个打分。在这个过程中,判别器是固定的,它只需要给更真实的图片更高的分数即可。生成器训练的目标是使图片更加真实,即提高分数。
对于真实场景中的生成器和判别器,它们通常是由多个神经网络层组成的大型网络。我们通常将它们看作一个整体,但不会调整判别器部分的模型参数。因为假设输出的分数越高越好,我们完全可以调整最后的输出层,改变偏差值设为较大的值,从而使输出的分数变得更高。然而,这种做法并不能达到我们想要的效果。因此,我们只能训练生成器的部分,训练方法与前面介绍的网络训练方法基本相同。不过,我们的优化目标是最大化而不是最小化,这与之前希望损失函数尽可能小的要求相反。当然,我们也可以在优化目标前加上负号,将其转化为损失函数的形式。另外一种方法是使用梯度上升进行优化,代替之前的梯度下降优化算法。
总结一下, GAN 算法的两个步骤。步骤一,固定生成器训练判别器;步骤二,固定判别器训练生成器。接下来就是重复以上的训练,训练完判别器固定判别器训练生成器。训练完生成器以后再用生成器去产生更多的新图片再给判别器做训练。训练完判别器后再训练生成器,如此反覆地去执行。当其中一个进行训练的时候,另外一个就固定住,期待它们都可以在自己的目标处达到最优,如图所示。**
**** **
8.3 的应用案例
从下图可以看出,通过对算法的训练,轮次的增加,**机器能够学习到不同的特征,例如眼睛、嘴巴等,从而生成越来越逼真的图片**。
除了产生动画人物以外,当然也可以产生真实的人脸,如图产生高清人脸的技术,叫做渐进式 GAN(progressive GAN),上下两排都是由机器产生的人脸。同样,我们可以用 GAN 产生我们从没有看过的人脸。

举例来说,先前我们介绍的 GAN 中的生成器,就是输入一个向量,输出一张图片。此外,我们还可以把输入的向量做内差,在输出部分我们就会看到两张图片之间连续的变化。比如我们输入一个向量通过 GAN 产生一个看起来非常严肃的男人,同时输入另一个向量通过 GAN 产生一个微笑着的女人。那我们输入这两个向量中间的数值向量,就可以看到这个男人逐渐地笑了起来。另一个例子,输入一个向量产生一个往左看的人,同时输入一个向量产生一个往右看的人,我们在之间做内差,机器并不会傻傻地将两张图片叠在一起,而是生成一张正面的脸。神奇的是,我们在训练的时候其实并没有真的输入正面的人脸,但机器可以自己学到把这两张左右脸做内差,应该会得到一个往正面看的人脸。

总之,渐进式生成人脸技术,可以通过输入不同的向量来生成不同的人脸,并且可以在两个向量之间进行内差,实现连续变化的效果。虽然这种技术可能会产生一些奇怪的图片(网球狗[doge]),但是它仍然具有很大的潜力和趣味性。

8.4 GAN 的理论介绍
训练的目标是找到一个生成器模型,使其能够生成与真实数据分布相似的样本。 在训练网络时,我们要确定一个损失函数,然后使梯度下降策略来调整网络参数,并使得设定的损失函数的数值最小或最大即可。使生成器能够生成与真实数据分布相似的样本。生成器的输入是一系列的从分布中采样出的向量,生成器就会产生一个比较复杂的分布,我们称之为 PG。另外我们还有一系列的数据,这些原始的数据本身会形成另外一个分布,我们称之为 Pdata。
我们现在的目标就是训练一组生成器模型中的网络参数,可以让生成的 PG 和 Pdata 之间的差异越小越好,这个最优生成器称为 G∗。
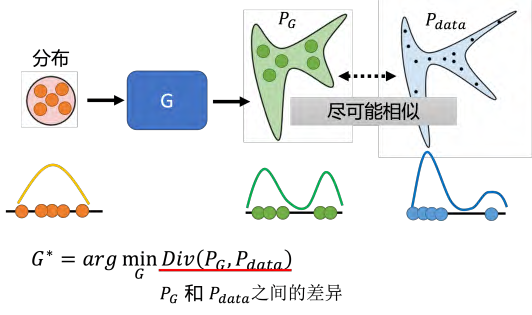
生成器和判别器的交互过程:生成器接受来自正态分布的向量作为输入,并生成一系列的图像。判别器则负责判断这些图像是否来自于真实数据分布。通过反复迭代训练,生成器和判别器逐渐提高自己的性能,最终生成器能够生成与真实数据分布相似的样本。
具体来说,对于 GAN,只要我们知道怎样从 PG 和 Pdata 中采样,就可以计算得到差异,而不需要知道实际的公式。例如,我们对于图库进行随机采样时,就会得到 Pdata。对于生成器,我们需要从正态分布中采样出来的向量通过生成器生成一系列的图片,这些图片就是 PG 采样出来的结果。所以我们有办法从 PG 采样,也可以从 Pdata 进行采样。接下来,我们将介绍如何只做以上采样的前提下,即不知道 PG 和 Pdata 的形式以及公式的情况下,如何估算得到差异,这其中要依靠判别器的力量。
我们首先回顾下判别器的训练方式。首先,我们有一系列的真实数据,也就是从 Pdata 采样得到的数据。同时,还有一系列的生成数据,从 PG 中采样出来的数据。根据真实数据和生成数据,我们会去训练一个判别器,其训练目标是看到真实数据就给它比较高的分数,看到生成的数据就给它比较低的分数。我们可以把它当做是一个优化问题,具体来说,我们要训练一个判别器,其可以最大化一个目标函数,当然如果我们最小化它就可以称它为损失函数。这个目标函数如图 8.16所示,其中有一些 y 是从 Pdata 中采样得到的,也就是真实的数据,而我们把这个真正的数据输入到判别器中,得到一个分数。另一方面,我们还有一些 y 来源于生成器,即从 PG 中采样出来的,将这些生成图片输入至判别器中同样得到一个分数,再取Log(1 − D(Y ))。
我们希望目标函数 V 越大越好,其中 y 如果是从 Pdata 中采样得到的真实数据,它就要越大越好;如果是从 PG 采样得到的生成数据,它就要越小越好。这个过程在 GAN 提出之初,人们将其写为这样其实还有一个缘由,就是为了让判别器和二分类产生联系,因为这个目标函数本身就是一个交叉熵乘上一个负号。训练一个分类器时的操作就是要最小化交叉熵,所以当我们最大化目标函数的时候,其实等同于最小化交叉熵,也就是等同于是在训练一个分类器。这个它做的事情就是把图中蓝色点,从 Pdata 采样出的真实数据当作类别 1,把从 PG 采样出的这些假的数据当作类别 2。有两个类别的数据,训练一个二分类的分类器,训练后就等同于是解了这个优化问题。而图中红框里面的数值,它本身就和 JS 散度有关。或许最原始的 GAN 的文章,它的出发点是从二分类开始的,一开始是把判别器写成二分类的分类器然后有了这样的目标函数,然后再经过一番推导后发现这个目标函数的最大值和 JS 散度是相关的。

当然我们还是要直观理解下为什么目标函数的值会和散度有关。这里我们假设 PG 和Pdata 的差距很小,就如图中蓝色的星星和红色的星星混在一起。这里,判别器就是在训练一个 0、 1 分类的分类器,但是因为这两组数据差距很小,所以在解决这个优化问题时,就很难让目标函数 V 达到最大值。但是当两组数据差距很大时,也就是蓝色的星星和红色的星星并没有混在一起,那么就可以轻易地把它们分开。当判别器可以轻易把它们分开的时候,目标的函数就可以变得很大。**所以当两组数据差距很大的时候,目标函数的最大值就可以很大。**当然这里面有很多的假设,例如判别器的分类能力无穷大。
我们再来看下计算生成器 + 判别器的过程,我们的目标是要找一个生成器去最小化两个分布 PG 和 Pdata 的差异。这个差异就是使用训练好的判别器来最大化它的目标函数值来实现。最小和最大的 MinMax 过程就像是生成器和判别器进行互动,互相“欺骗”的过程。注意,这里的差异函数不一定使用 KL 或者 JS 等函数,可以尝试不同的函数来得到不同差异衡量指标。
8.5 WGAN 算法
因为要进行 MinMax 操作,所以 GAN 是很不好训练的。我们接下来介绍一个 GAN训练的小技巧,就是著名的 **Wasserstein GAN(Wasserstein Generative AdversarialNetwork)。** 在讲这个之前,我们分析下 **JS 散度有什么问题。**首先, JS 散度的两个输入** PG和 Pdata 之间的重叠部分往往非常少**。这个其实也是可以预料到的,我们从不同的角度来看:图片其实是高维空间里低维的流形,因为在高维空间中随便采样一个点,它通常都没有办法构成一个人物的头像,所以人物头像的分布,在高维的空间中其实是非常狭窄的。换个角度解释,如果是以二维空间为例,图片的分布可能就是二维空间的一条线,也就是 PG 和 Pdata都是二维空间中的两条直线。而二维空间中的两条直线,除非它们刚好重合,否则它们相交的范围是几乎可以忽略的。从另一个角度解释,我们从来都不知道 PG 和 Pdata 的具体分布,因为其源于采样,所以也许它们是有非常小的重叠分布范围。比如采样的点不够多,就算是这两个分布实际上很相似,也很难有任何的重叠的部分。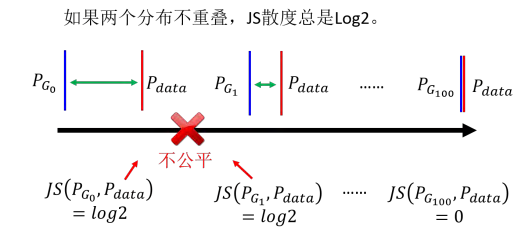
所以以上的问题就会对于 JS 分布造成以下问题:首先,对于两个没有重叠的分布, JS 散度的值都为 Log2,与具体的分布无关。(太过宽泛了)就算两个分布都是直线,但是它们的距离不一样,得到的 JS 散度的值就都会是 Log2,如上图所示。所以 JS 散度的值并不能很好地反映两个分布的差异。另外,对于两个有重叠的分布, JS 散度的值也不一定能够很好地反映两个分布的差异。因为 JS 散度的值是有上限的,所以当两个分布的重叠部分很大时, JS 散度不好区分不同分布间的差异。所以既然从 JS 散度中,看不出来分布的差异。那么在训练的时候,我们就很难知道我们的生成器有没有在变好,我们也很难知道我们的判别器有没有在变好。所以我们需要一个更好的衡量两个分布差异的指标。
既然是 JS 散度的问题,肯定有人就想问说会不会换一个衡量两个分布相似程度的方式,就可以解决这个问题了呢?是的,于是就有了 Wasserstein,或使用 Wasserstein 距离的想法。Wasserstein 距离的想法如下,假设两个分布分别为 P 和 Q,我们想要知道这两个分布的差异,我们可以想像有一个推土机,它可以把 P 这边的土堆挪到 Q 这边,那么推土机平均走的距离就是 Wasserstein 距离。 在这个例子里面,我们假设 P 集中在一个点, Q 集中在一个点,对推土机而言,假设它要把 P 这边的土挪到 Q 这边,那它要平均走的距离就是 D,那么 P和 Q 的 Wasserstein 距离就是 D。但是如果 P 和 Q 的分布不是集中在一个点,而是分布在一个区域,那么我们就要考虑所有的可能性,也就是所有的推土机的走法,然后看平均走的距离是多少,这个平均走的距离就是 Wasserstein 距离。 Wasserstein 距离可以想象为有一个推土机在推土,所以 Wasserstein 距离也称为推土机距离(Earth Mover’s Distance, EMD)。

可视化来理解一下,但是如果是更复杂的分布,要算 Wasserstein 距离就有点困难了,如图所示。假设两个分布分别是 P 和 Q,我们要把 P 变成 Q,那有什么样的做法呢?我们可以把 P 的土搬到 Q 来,也可以反过来把 Q 的土搬到 P。所以当我们考虑比较复杂分布的时候,两种分布计算距离就有很多不同的方法,即不同的“移动”方式,从中计算算出来的距离,即推土机平均走的距离就不一样。对于左边这个例子,推土机平均走的距离比较少;右边这个例子因为舍近求远,所以推土机平均走的距离比较大。那两个分布 P 和 Q 的 Wasserstein 距离会有很多不同的值吗?这样的话,我们就不知道到底要用哪一个值来当作是 Wasserstein 距离了。为了让 Wasserstein 距离只有一个值,我们将距离定义为穷举所有的“移动”方式,然后看哪一个推土的方法可以让平均的距离最小。那个最小的值才是 Wasserstein 距离。所以其实要计算Wasserstein 距离挺麻烦的,因为里面还要解一个优化问题。

当使用 WGAN 时,使用 Wasserstein 距离来衡量分布间的偏差的时候。本来两个分布 PG0 和 Pdata 距离非常遥远,你要它一步从开始就直接跳到结尾,这是非常困难的。但是如果用 Wasserstein 距离,你可以让 PG0 和 Pdata 慢慢挪近到一起,可以让它们的距离变小一点,然后再变小一点,最后就可以让它们对齐在一起。所以这就是为什么我们要用 Wasserstein 距离的原因,因为它可以让我们的生成器一步一步地变好,而不是一下子就变好 。

所以 WGAN 实际上就是用 Wasserstein 距离来取代 JS 距离,这个 GAN 就叫做 WGAN。那接下来的问题是, Wasserstein 距离是要如何计算呢?我们可以看到, Wasserstein 距离的定义是一个最优化的问题,如上图所示。这里我们简化过程直接介绍结果,也就是解图中最大化问题的解,解出来以后所得到的值就是 Wasserstein 距离,即 PG0 和 Pdata 的 Wasserstein距离。我们观察一下上图的公式,即我们要找一个函数 D,这个函数 D 是一个函数,我们可以想像成是一个神经网络,这个神经网络的输入是 x,输出是 D(x)。 X 如果是从 Pdata采样来的,我们要计算它的期望值 Ex∼Pdata,如果 X 是从 PG 采样来的,那我们要计算它的期望值 Ex∼PG,然后再乘上一个负号,所以如果要最大化这个目标函数就会达成。如果 X 如果是从 Pdata 采样得到的,那么判别器的输出要越大越好,如果 X 如果是从 PG **采样得到的,从生成器采样出来的输出应该要越小越好**** **
此外还有另外一个限制。函数 D 必须要是一个 1-Lipschitz 的函数。我们可以想像成,如果有一个函数的斜率是有上限的(足够平滑,变化不剧烈),那这个函数就是 1-Lipschitz 的函数。如果没有这个限制,只看大括号里面的值只单纯要左边的值越大越好,右边的值越小越好,那么在蓝色的点和绿色的点,也就是真正的图像和生成的图像没有重叠的时候,我们可以让左边的值无限大,右边的值无限小,这样的话,这个目标函数就可以无限大。这时整个训练过程就根本就没有办法收敛。所以我们要加上这个限制,让这个函数是一个 1-Lipschitz的函数,这样的话,左边的值无法无限大,右边的值无法无限小,所以这个目标函数就可以收敛。所以当判别器够平滑的时候,假设真实数据和生成数据的分布距离比较近,那就没有办法让真实数据的期望值非常大,同时生成的值非常小。因为如果让真实数据的期望值非常大,同时生成的值非常小,那它们中间的差距很大,判别器的更新变化就很剧烈,它就不平滑了,也就不是 1-Lipschitz 了。
那接下来的问题就是如何确保判别器一定符合 1-Lipschitz 函数的限制呢?其实最早刚提出 WGAN 的时候也没有什么好想法。最早的一篇 WGAN 的文章做了一个比较粗糙的处理,就是训练网络时,把判别器的参数限制在一个范围内,如果超过这个范围,就把梯度下降更新后的权重设为这个范围的边界值。但其实这个方法并不一定真的能够让判别器变成 1- Lipschitz 函数。虽然它可以让判别器变得平滑,但是它并没有真的去解这个优化问题,它并没有真的让判别器符合这个限制。
后来就有了一些其它的方法,例如说有一篇文章叫做 Improved WGAN,它就是使用了梯度惩罚(gradient penalty) 的方法,这个方法可以让判别器变成 1-Lipschitz 函数。具体来说,如图所示,假设蓝色区域是真实数据的分布,橘色是生成数据的分布,在真实数据这边采样一个数据,在生成数据这边取一个样本,然后在这两个点之间取一个中间的点,然后计算这个点的梯度,使之接近于 1。就是在判别器的目标函数里面,加上一个惩罚项,这个惩罚项就是判别器的梯度的范数减去 1 的平方,这个惩罚项的系数是一个超参数,这个超参数可以让你的判别器变得越平滑。在 Improved WGAN 之后,还有 Improved Improved WGAN,就是把这个限制再稍微改一改。另外还有方法是将判别器的参数限制在一个范围内,让它是1-Lipschitz 函数,这个叫做谱归一化。总之,这些方法都可以让判别器变成 1-Lipschitz 函数,但是这些方法都有一个问题,就是它们都是在判别器的目标函数里面加了一个惩罚项,这个惩罚项的系数是一个超参数,这个超参数会让你的判别器变得越平滑。
8.6 训练 GAN 的难点与技巧
GAN由两个神经网络组成,一个是生成器,另一个是判别器。生成器的任务是生成虚假的图像来欺骗判别器,而判别器的任务是识别真实图像和虚假图像之间的差异。 所以这也是为什么 GAN 很难训练的原因,因为这两个网络必须要同时训练,而且必须要同时训练到一个比较好的状态 所以 GAN 本质上它的训练仍然不是一件容易的事情,当然它是一个非常重要的前瞻技术。有一些训练 GAN 的小技巧,例如 Soumith、 DCGAN、 BigGAN 等等。大家可以自己看看相关文献进行尝试 。 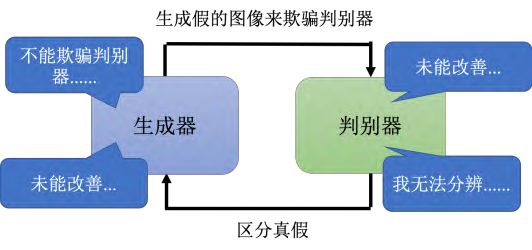- GAN在文字生成中的挑战
序列到序列模型的难点:GAN用于生成文字时,需要一个序列到序列的模型,其中解码器负责产生文字。难点在于,使用梯度下降训练解码器时,由于输出分布的小变化对词元影响不大,导致难以通过微分来优化模型。
词元的定义:词元是生成序列的基本单位,可以是汉字、字母或单词,其定义影响模型的输出和训练。
强化学习的应用:由于梯度下降的局限性,可能需要使用强化学习来训练生成器,但强化学习本身训练难度大,与GAN结合后难度进一步增加。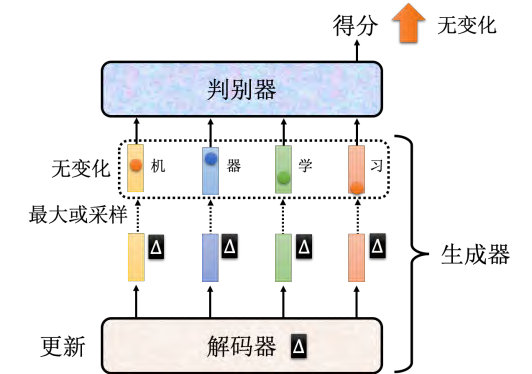
- 解决方案与进展
ScratchGAN的提出:ScratchGAN提出了一种无需预训练的方法,直接从随机初始化参数开始训练生成器,通过调节超参数和里用 SeqGAN-Step 的技术,并且将训练批大小设置的很大,要上千,然后要用强化学习的方法,要改一下强化学习的参数,同时加一些正则化等等技巧,就可以从真的把 GAN 训练起来,然后让它来产生序列 。
生成式模型的多样性:除了GAN,还有VAE和流模型等生成式模型,各有优缺点。GAN在图片生成方面表现最佳,而VAE和流模型在文字生成方面可能更为合适。
生成式潜在优化:对于直接使用监督学习生成图片的挑战,提出了生成式潜在优化等特殊方法,以改善训练效果。
那为什么我们需要用生成式来做输出新图片的事情呢?如果我们今天的目标就是,输入一个高斯分布的变量,然后使用采样出来的向量,直接输出一张照片,能不能直接用监督学习的方式来实现呢?具体做法比如我有一堆图片,每一个图片都去配一个向量,这个向量来源于从高斯分布中采样得到的向量,然后我就可以用监督学习的方式来训练一个网络,这个网络的输入是这个向量,输出是这个图片。确实能这么做,也真的有这样的生成式模型。但是难点在于,如果纯粹放随机的向量,那训练起来结果会很差。所以需要有一些特殊的方法例如生成式潜在优化等方法,供大家参考。
8.7 GAN 的性能评估方法
我们可以发现比较早年 GAN 的论文,它没有数字结果,整篇论文里面没有准确度等等的数字结果,它只有一些图片,然后说这个生成器产生出来的图片是不是比较好,接着就结束了。这样显然是不行的,并且有很多的问题,比如说不客观、不稳定等等诸多的问题。所以有没有比较客观而且自动的方法来度量一个生成器的好坏呢? 针对特定的一些任务,是有办法设计一些特定方法的。比如说我们要产生一些动画人物的头像,那我们可以设计一个专门用于动画人物面部的识别系统,然后看看我们的生成器产生出来的图片里面,有没有可以被识别的动画人物的人脸。如果有的话,那就代表说这个生成器产生出来的图片是比较好的。但是这个方法只能针对特定的任务,如果我们要产生的东西不是动画人物的头像,而是别的东西,那这个方法就不行了。那如果是更一般的案例,比如它不一定是产生动画人物的,它专门产生猫、专门产生狗、专门产生斑马等等,那我们怎么知道它做得好不好呢?其实有一个方法,是训练一个图像的分类系统,然后把 GAN 产生出来的图片输入到这个图像的分类系统里面,看它产生什么样的结果,如图 所示。这个图像分类系统的输入是一张图片,输出是一个概率分布,这个概率分布代表说这张图片是猫的概率、狗的概率、斑马的概率等等。如果这个概率分布越集中,就代表现在产生的图片可能越好。如果生成出来的图片是一个四不像,图像识别系统就会非常地困惑,它产生出来的这个概率分布就会是非常平均地分布

这个是靠图像识别系统来判断产生出来的图片好坏,这是一个可能的做法,但是光用这个做法是不够的。光用这个做法会被一个叫做模式崩塌/模式丢失(mode collapse) 的问题骗过去。模式崩塌是指在训练 GAN 的过程中遇到的一个状况,假设如图 蓝色的星星是真正的数据的分布,红色的星星是 GAN 的模型的分布。我们会发现生成式的模型它输出来的图片来来去去就是那几张,可能单一张拿出来你觉得好像还做得不错,但让它多产生几张就露出马脚,产生出来就只有那几张图片而已,这就是模式崩塌的问题。(聚集在一起,多样性差)

发生模式崩塌的原因,从直觉上理解可以想成这个地方就是判别器的一个盲点,当生成器学会产生这种图片以后,它就永远都可以骗过判别器,判别器没办法看出来图片是假的。那对于如何避免模式坍塌,其实到今天其实还没有一个非常好的解答,不过有方法是模型在生成器训练的时候,一直将训练的节点存下来,在模式坍塌之前把训练停下来,就只训练到模式崩塌前,然后就把之前的模型拿出来用。不过模型崩塌这种问题,我们至少是知道有这个问题,是可以看得出的,生成器总是产生这张脸的时候,你不会说你的生成器是个好的生成器。但是有一些问题是你不知道的并且更难侦测到的,即你不知道生成器产生出来的图片是不是真的有多样性。
虽然存在以上模式坍塌、模式丢失等等的问题,但是我们需要去度量生成器产生出来的图片到底多样性够不够。有一个做法是借助我们之前介绍过的图像分类,把一系列图片都丢到图像分类器里,看它被判断成哪一个类别,如图所示。每张图片都会给我们一个分布,我们将所有的分布平均起来,接下来看看平均的分布长什么样子。如果平均的分布非常集中,就代表现在多样性不够,如果平均的分布非常平坦,就代表现在多样性够了。具体来讲,如果什么图片输入到图像分类系统中的输出都是第二种类别,那代表说每一张图片也许都很像,也就代表输出的多样性是不够的,那如果另外一个案例不同张图片丢进去,它的输出分布都不一样,那就代表说多样性是够的。并且平均完以后发现结果是非常平坦的,那这个时候代表多样性是足够的。
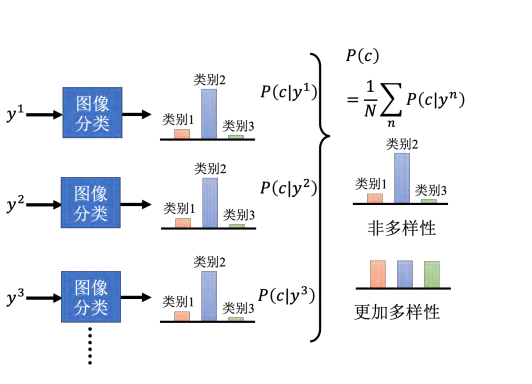
当我们用这个图像分类器来做评估的时候,对于结果的多样性和质量好像是有点互斥的。因为我们刚才在讲质量的时候说,分布越集中代表质量越高,多样性的分布越平均。但是如果分布越平均,那质量就会越低,因为分布越平均,代表图片都不太像,所以质量就会越低。这里要强调一下质量和多样性的评估范围不一样,质量是只看一张图片,一张图片丢到分类器的时候,分布有没有非常地集中。而多样性看的是一堆图片分布的平均,一堆图片中图像分类器输出的越平均,那就代表现在的多样性越大。
过去有一个非常常被使用的分数,叫做Inception 分数。 其顾名思义就是用 Inception 网络来做评估,用 Inception 网络度量质量和多样性。如果质量高并且多样性又大,那 Inception分数就会比较大。目前研究人员通常会采取另外一个评估方式,叫 Fréchet Inception distance(FID)。 具体来讲,先把生成器产生出来的人脸图片,丢到 InceptionNet 里面,让 Inception网络输出它的类别。这里我们需要的不是最终的类别,而是进入 Softmax 之前的隐藏层的输出向量,这个向量的维度是上千维的,代表这个图片,如图 所示。图中所有红色点代表把真正的图片丢到 Inception 网络以后,拿出来的向量。这个向量其实非常高维度,甚至是上千维的,我们就把它降维后画在二维的平面上。蓝色点是 GAN 的生成器产生出来的图片,它丢到 Inception 网络以后进入 Softmax 之前的向量。接下来,我们假设真实的图片和生成的图片都服从高斯分布,然后去计算这两个分布之间的 Fréchet 的距离。两个分布间的距离越小越好,距离越小越代表这两组图片越接近,也就是产生出来的品质越高。这里还有几个细节问题,首先,假设为高斯分布没问题吗?另外一个问题是如果要准确的得到网络的分布,那需要产生大量的采样样本才能做到,这需要一点运算量,也是做 FID 不可避免的问题。
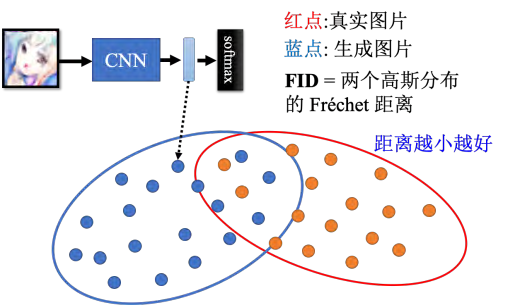
此外,还有一个状况。假设 GAN 产生出来的图片,跟真实的图片长得一模一样,那此时FID 会是零,因为两个分布是一模一样的。如果你不知道真实数据长什么样子,光看这个生成器的输出可能会觉得太棒了,那 FID 算出来一定是非常小的, 但是如果它产生出来的图片都跟数据库里面的训练数据的一模一样的话,那干脆直接从训练数据集里面采样一些图像出来不是更好,也就不需要训练生成器了。我们训练生成器其实是希望它产生新的图片,也就是训练集里面没有的人脸。
对于这种问题,就不是普通的度量标准可以侦测的。那怎么解决呢?其实有一些方法,例如可以用一个分类器,这个分类器是用来判断这张图片是不是真实的,是不是来自于你的训练集的。这个分类器的输入是一张图片,输出是一个概率,这个概率代表说这张图片是不是来自于你的训练集。如果这个概率是 1,那就代表说这张图片是来自于你的训练集,如果这个概率是 0,那就代表说这张图片不是来自于你的训练集。但是另外一个问题,假设生成器学到的是把所有训练数据里面的图片都左右反转呢,那它也是什么事都没有做。但是你的分类器会觉得说,这张图片是来自于你的训练集,因为它是来自于你的训练集的图片,只不过是左右反转而已。进行分类时或者进行相似度的比较时,又比不出来。所以 GAN 的评估是非常地困难的,还甚至如何评估一个生成器做得好不好都是一个可以研究的题目
8.8 条件型生成
下面,我们要介绍**条件型生成(conditional generation)**。我们之前讲的 GAN 中的生成器,它没有输入任何的条件,它只是输入一个随机的分布,然后产生出来一张图片。 **我们现在想要更进一步的是希望可以操控生成器的输出,我们给它一个条件 x,让他根据条件 x 跟输入 z 来产生输出 y。** 那这样的条件型生成器有什么样的应用呢?比如可以做文字对图片的生成,那如果要做文字对图片的生成,它其实是一个监督学习的问题,我们需要一些有标签的数据,需要去搜集一些人脸图片,然后这些人脸都要有文字的描述。比如这个样本是红眼睛、黑头发,另一个是黄头发、有黑眼圈等等标签的样本,才能够训练这种条件型生成器。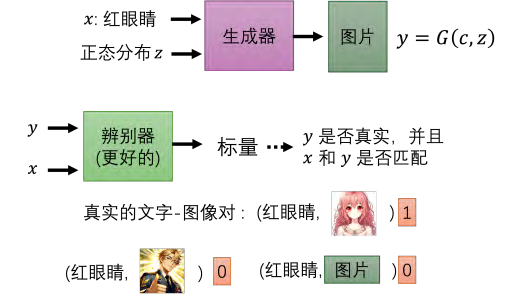
1. 条件型GAN的实现
- 生成器的设计:生成器接受两个输入,一个是随机采样的高斯分布变量z,另一个是条件输入x(如一段文字),生成输出y(如一张图片)。
- 判别器的改进:为了使生成器考虑条件输入x,判别器不仅输入图片y,还要输入条件x。判别器输出一个数值,不仅评估图片y的真实性,还评估y与条件x的匹配度。
- 训练方法:使用成对的标注数据训练判别器,如果y与x匹配,输出高分;如果不匹配,输出低分。实际操作中,还需要故意制造不匹配的负样本对来更好地训练判别器。
2. 条件型GAN的应用
- 图像翻译:输入一张图片,生成另一张图片,如将黑白图片上色、将素描图转换为实景图等。这种应用称为图像翻译或Pix2pix。
- 声音到图像的转换:给GAN输入声音(如狗叫声),生成对应的图像(如一只狗的图片)。这种应用需要声音和图像成对的数据来训练。
- 动态图片生成:条件型GAN还可以用于生成动态图片,如让静态的蒙娜丽莎画像动起来并讲话。
3. 训练与优化
- 监督学习的结合:为了提高生成图片的质量,可以将GAN与监督学习结合,确保生成器不仅骗过判别器,而且生成的图片与标准答案尽可能相似。
8.9 Cycle GAN
**1. Cycle GAN简介**- 无监督学习的挑战:传统的监督学习需要成对的数据来训练网络,但在某些情况下,如图像风格转换,我们可能没有成对的数据。
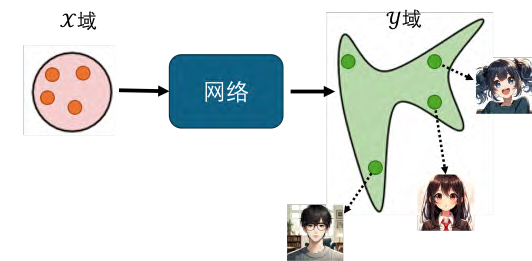
- Cycle GAN的提出:Cycle GAN是一种用于无监督学习的GAN变体,能够在没有成对数据的情况下进行图像风格转换等任务。
2. Cycle GAN的工作原理
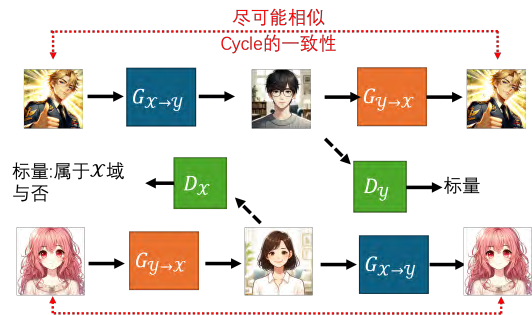
- 生成器的双重角色:Cycle GAN包含两个生成器,一个将x域的图片转换为y域,另一个将y域的图片还原回x域。
- 一致性原则:通过确保经过两次转换后的输出与原始输入尽可能接近,来强化输入与输出之间的关系。
- 判别器的作用:判别器用于判断生成器输出的图片是否像真实的y域图片,同时确保生成器输出的图片与输入的条件相匹配。
**3. ****循环生成对抗网络(Cycle GAN)**的双向架构

- 双向转换:Cycle GAN不仅可以将x域转换为y域,还可以将y域转换回x域,形成一个双向的转换循环。(在 Cycle GAN 中,我们会训练两个生成器。第一个生成器是把 x 域的图变成y 域的图,第二个生成器它的工作是看到一张 y 域的图,把它还原回 x 域的图。在训练的时候,我们会增加一个额外的目标,就是我们希望输入一张图片,其从 x 域转成 y 域以后,要从 y 域转回原来一模一样的 x 域的图片。)
- 其他风格转换的GAN:除了Cycle GAN,还有Disco GAN、Dual GAN等其他GAN变体,它们也用于图像风格转换,但各有特点。

4. Cycle GAN的应用
- 文字风格转换:Cycle GAN不仅可以用于图像风格转换,还可以用于文字风格转换,如将负面句子转换为正面句子。
- 无监督翻译:Cycle GAN还可用于无监督的翻译任务,如将中文句子翻译成英文,即使没有成对的数据。
- 语音识别:Cycle GAN还可应用于无监督的语音识别,将声音转换为文字。
这一节有关 GAN 的内容就介绍完了,主要为大家介绍了生成式模型、 GAN、 GAN 的理论、 GAN 的训练小技巧、评估 GAN 的方法、条件型 GAN 以及 Cycle GAN 这种不需要数据对的 GAN 网络。如果大家想继续深入研究 GAN 的理论和应用,可以多去看一些综述类型的文章以及最新的论文。
全文思维导图



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









