






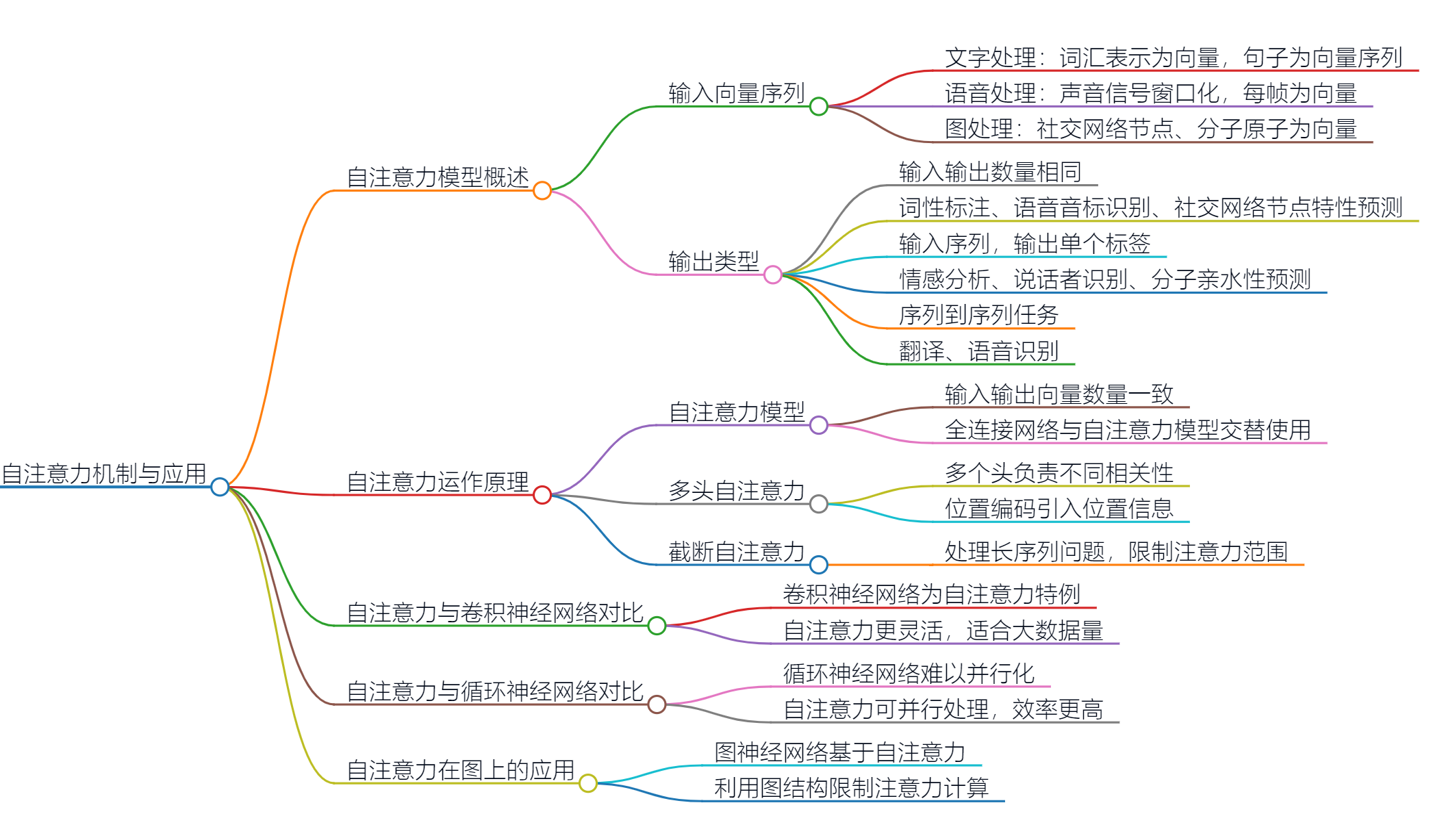
我们要讲另外一个常见的网络架构——自注意力模型(selfattention model)。目前为止,不管是在预测观看人数的问题上,还是图像处理上,网络的输入都是一个向量。当然,输入可以看作是一个向量,如果是回归问题,输出是一个标量,如果是分类问题,输出是一个类别。

6.1 输入是向量序列的情况
每次模型输入的序列长度都不一样,这个时候应该要怎么处理呢?我们通过几个例子来讲解一下。
第一个例子是文字处理,假设网络的输入是一个句子,每一个句子的长度都不一样(每个句子里面词汇的数量都不一样)。如果把一个句子里面的每一个词汇都描述成一个向量,用向量来表示,模型的输入就是一个向量序列,而且该向量序列的大小每次都不一样(句子的长度不一样,向量序列的大小就不一样)。
将词汇表示成向量最简单的做法是**独热编码,但从独热向量中不能看到这件事情,其里面没有任何语义的信息。
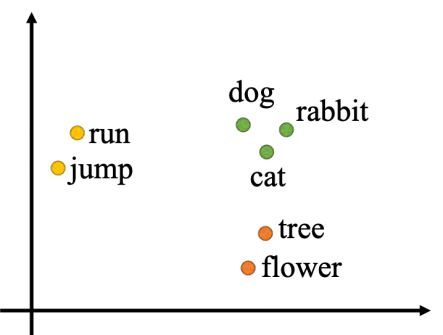
第二种方法是词嵌入(word embedding) 也可将词汇表示成向量。词嵌入使用一个向量来表示一个词汇,而这个向量是包含语义信息的。如图所示,如果把词嵌入画出来,所有的动物可能聚集成一团,所有的植物可能聚集成一团,所有的动词可能聚集成一团等等。词嵌入会给每一个词汇一个向量,而一个句子就是一组长度不一的向量。
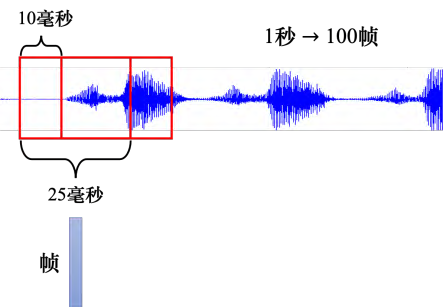
接下来举一些把一个向量的序列当做输入的例子。如图 6.4 所示,一段声音信号其实是一组向量。我们会把一段声音信号取一个范围,这个范围叫做一个窗口(window),把该窗口里面的信息描述成一个向量,这个向量称为一帧(frame)。通常这个窗口的长度就是 25 毫秒。为了要描述一整段的声音信号,我们会把这个窗口往右移一点,通常移动的大小是 10 毫秒。 (Q: 为什么窗口的长度是 25 毫秒,窗口移动的大小是 10 毫秒? A:前人帮我们调好了。他们尝试了大量可能的值,这样得到的结果往往最理想。)
**
一个图(graph)也是一堆向量。
药物发现(drug discovery)跟图有关,一个分子也可以看作是一个图。如果把一个分子当做是模型的输入,每一个分子可以看作是一个图,分子上面的每一个球就是一个原子,每个原子就是一个向量。每个原子可以用独热向量来表示。
6.1.1 类型 1:输入与输出数量相同

什么样的应用会用到第一种类型的输出呢?举个例子,如图 6.7 所示,在文字处理上,假设我们要做的是词性标注(Part-Of-Speech tagging, POS tagging)。机器会自动决定每一个词汇的词性,判断该词是名词还是动词还是形容词等等。
如果是语音,一段声音信号里面有一串向量。每一个向量都要决定它是哪一个音标。这不是真正的语音识别,这是一个语音识别的简化版。如果是社交网络,给定一个社交网络,模型要决定每一个节点有什么样的特性,比如某个人会不会买某个商品,这样我们才知道要不要推荐某个商品给他。以上就是举输入跟输出数量一样的例子,这是第一种可能的输出。** **
6.1.2 类型 2:输入是一个序列,输出是一个标签

举例而言,如图 6.9 所示,输入是文字,比如情感分析。情感分析就是给机器看一段话,模型要决定说这段话是积极的(positive)还是消极的(negative)。
6.1.3 类型 3:序列到序列

我们不知道应该输出多少个标签,机器要自己决定输出多少个标签。如图 6.10 所示,输入是 _N _个向量,输出可能是 _N′ _个标签。 _N′ _是机器自己决定的。这种任务又叫做序列到序列的任务。翻译就是序列到序列的任务,因为输入输出是不同的语言,它们的词汇的数量本来就不会一样多。真正的语音识别输入一句话,输出一段文字,其实也是一个序列到序列的任务。
6.2 自注意力的运作原理
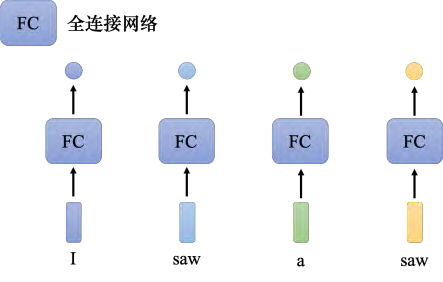
我们就先只讲第一个类型:输入跟输出数量一样多的状况,以**序列标注(sequence labeling)为例。序列标注要给序列里面的每一个向量一个标签。要怎么解决序列标注的问题呢?直觉的想法就是使用全连接网络。如图 6.11 所示,虽然输入是一个序列,但可以不要管它是不是一个序列,各个击破,把每一个向量分别输入到全连接网络里面得到输出。这种做法有非常大的瑕疵,以词性标注为例,给机器一个句子: I saw a saw。对于全连接网络,这个句子中的两个 saw 完全一模一样,它们是同一个词汇。既然全连接网络输入同一个词汇,它没有理由输出不同的东西。但实际上,我们期待第一个 saw 要输出动词,第二个 saw 要输出名词。但全连接网络无法做到这件事,因为这两个 saw 是一模一样的。有没有可能让全连接网络考虑更多的信息,比如上下文的信息呢?这是有可能的,如图 6.12 所示,把每个向量的前后几个向量都“串”起来,一起输入到全连接网络就可以了。
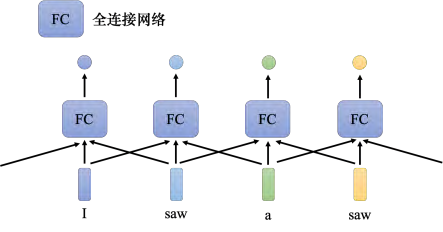
在语音识别里面,我们不是只看一帧判断这个帧属于哪一个音标,而是看该帧以及其前后 5 个帧(共 11 个帧)来决定它是哪一个音标。所以可以给全连接网络一整个窗口的信息,让它可以考虑一些上下文,即与该向量相邻的其他向量的信息。 **
但是如果要考虑一整个序列怎么办呢?有人可能会想说这个还不容易,把窗口开大一点啊,大到可以把整个序列盖住,就可以了。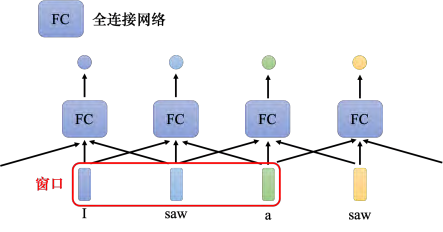
但是开一个这么大的窗口,意味着 全连接网络需要非常多的参数 ,可能不只运算量很大,还容易 过拟合。如果想要更好地考虑整个输入序列的信息,就要用到自注意力模型。 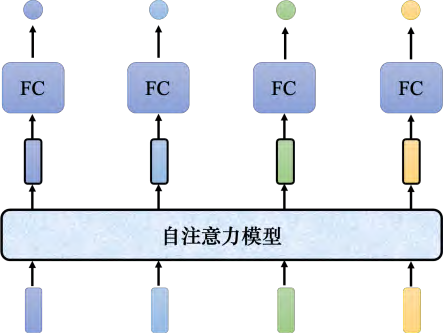
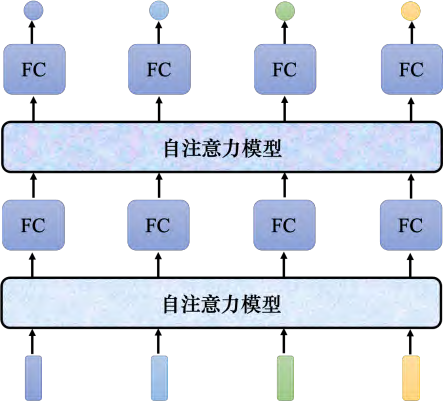
自注意力模型不是只能用一次,可以叠加很多次。如图 6.15 所示,自注意力模型的输出通过全连接网络以后,得到全连接网络的输出。全连接网络的输出再做一次自注意力模型,再重新考虑一次整个输入序列的数据,将得到的数据输入到另一个全连接网络,就可以得到最终的结果。全连接网络和自注意力模型可以交替使用。全连接网络专注于处理某一个位置的信息,自注意力把整个序列信息再处理一次。有关自注意力最知名的相关的论文是 “Attention Is All You Need”。 在这篇论文里面,谷歌提出了 Transformer 网络架构。其中最重要的模块是自注意力,就像变形金刚的火种源。有很多更早的论文提出过类似自注意力的架构,只是叫别的名字,比如叫 Self-Matching。 “Attention Is All You Need” 这篇论文将自注意力模块发扬光大
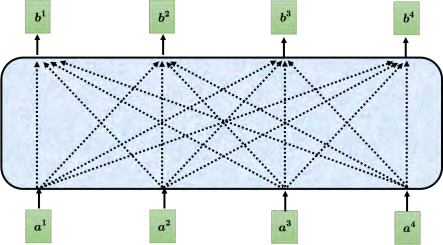
自注意力模型的运作过程如图 6.16 所示,其输入是一串的向量,这个向量可能是整个网络的输入,也可能是某个隐藏层的输出, 所以不用 x来表示它,而用 _**a **_来表示它,代表它有可能是前面已经做过一些处理,是某个隐藏层的输出。输入一组向量 a,自注意力要输出一组向量 b,每个 _**b **_都是考虑了所有的 _**a **_以后才生成出来的。 _b_1、 _b_2、 _b_3、 _b_4 是考虑整个输入的序列 _a_1、 _a_2、 _a_3、 _a_4 才产生出来的。
接下来介绍下向量 _b_1 产生的过程,了解产生向量 _b_1 的过程后,剩下向量 _b_2、 _b_3、 _b_4 产生的过程以此类推。怎么产生向量 _b_1 呢?如图 6.17 所示,第一个步骤是根据 _a_1 找出输入序列里面跟 _a_1 相关的其他向量。
自注意力的目的是考虑整个序列,但是又不希望把整个序列所有的信息包在一个窗口里面。
所以有一个特别的机制,这个机制是根据向量 a1 找出整个很长的序列里面哪些部分是重要的,哪些部分跟判断 a1 是哪一个标签是有关系的。每一个向量跟a1 的关联的程度可以用数值 α 来表示。自注意力的模块如何自动决定两个向量之间的关联性呢?给它两个向量 a1 跟 a4,它怎么计算出一个数值 α 呢?我们需要一个计算注意力的模块。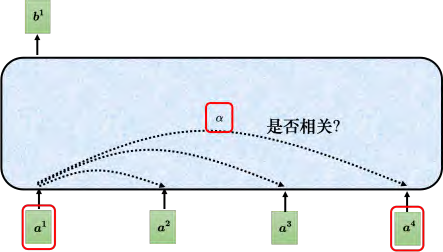
如图(a)所示,计算注意力的模块使用两个向量作为输入,**直接输出数值 **α**, ****α ****可以当做两个向量的关联的程度。怎么计算 **α?比较常见的做法是用点积(dot product)。
把输入两个向量分别乘上两个不同的矩阵,左边这个向量乘上矩阵 W q,右边这个向量乘上矩阵 W k,得到两个向量 q 跟 k,再把 ****q ****跟 ****k ****做点积,把它们做逐元素(element-wise)的相乘,再全部加起来以后就得到一个标量(scalar) **α**,这是一种计算 ****α ****的方式。 **
其实还有其他的计算方式,如图 (b) 所示,有另外一个叫做相加(additive)的计算方式,其计算方法就是把两个向量通过 Wq、 _Wk _得到 _**q **和 k,但不是把它们做点积,而是把**q **_和 **k **“串”起来“丢”到一个 tanh 函数,再乘上矩阵 _W _得到 α。总之,有非常多不同的方法可以计算注意力,可以计算关联程度 α。但是在接下来的内容里面,我们都只用点积这个方法,这也是目前最常用的方法,也是用在 Transformer 里面的方法。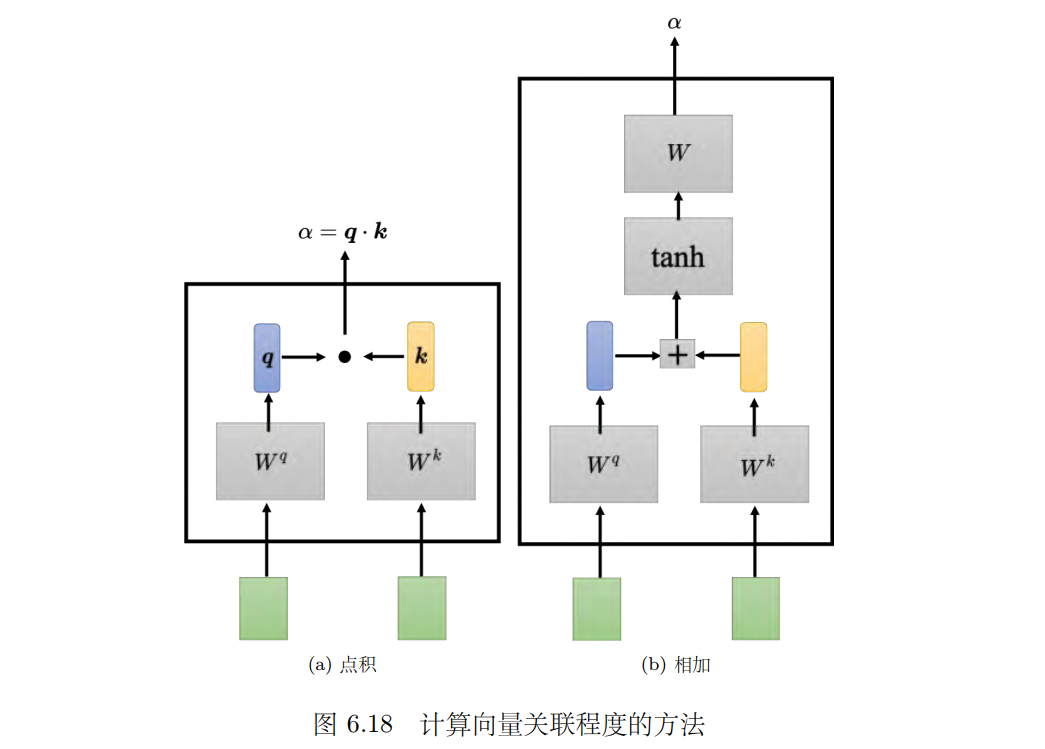
接下来如何把它套用在自注意力模型里面呢?自注意力模型一般采用查询-键-值(QueryKey-Value, QKV)模式。分别计算 _a_1 与 _a_2、 _a_3、 _a4 之间的关联性 α。如图 6.19 所示,把a_1 乘上 _Wq _得到 _q_1。 _**q **_称为查询(query),它就像是我们使用搜索引擎查找相关文章所使用的关键字,所以称之为查询。
接下来要去把 _a_2、 _a_3、 _a_4 乘上 _Wk _得到向量 k,向量 _k _称为键(key)。把查询 _q1 跟键k_2 算内积(inner-product)就得到 α_1,_2。 α_1,_2 代表查询是 _q_1 提供的,键是 _k_2 提供的时候, _q_1 跟 _k_2 之间的关联性。关联性 _α _也被称为注意力的分数。计算 _q_1 与 _k2 的内积也就是计算a_1 与 _a_2 的注意力的分数。计算出 _a_1 与 _a_2 的关联性以后,接下来还需要计算 _a_1 与 _a_3、 _a_4的关联性。把 _a_3 乘上 _Wk _得到键 _k_3, _a_4 乘上 _Wk _得到键 _k_4,再把键 _k_3 跟查询 _q_1 做内积,得到 _a_1 与 _a_3 之间的关联性,即 _a_1 跟 _a_3 的注意力分数。把 _k_4 跟 _q_1 做点积,得到 α_1,4,即a_1 跟 _a_4 之间的关联性。 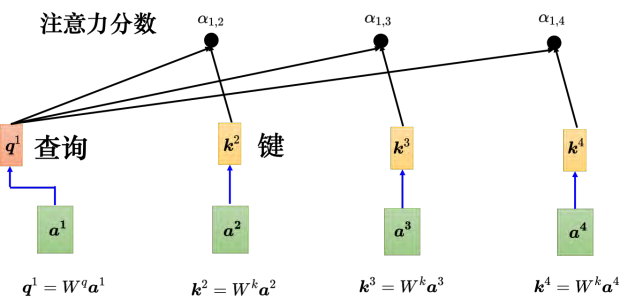
一般在实践的时候,如图 6.20 所示, _a_1 也会跟自己算关联性,把 _a_1 乘上 _Wk _得到 _k_1。用 _q_1 跟 _k_1 去计算 a1 与自己的关联性。 计算出a1 跟每一个向量的关联性以后,接下来会对所有的关联性做一个 softmax 操作,如式 (6.3) 所示,把 α全部取 e的指数,再把指数的值全部加起来做归一化(normalize)得到α′。这里的 softmax 操作跟分类的 softmax 操作是一模一样的 **
α
1
,
i
′
=
exp
(
α
1
,
i
)
/
∑
j
exp
(
α
1
,
j
)
\alpha_{1,i}'=\exp\left(\alpha_{1,i}\right)/\sum_j\exp\left(\alpha_{1,j}\right)
α1,i′=exp(α1,i)/∑jexp(α1,j)
所以本来有一组 α,**通过 softmax 就得到一组 **α′。 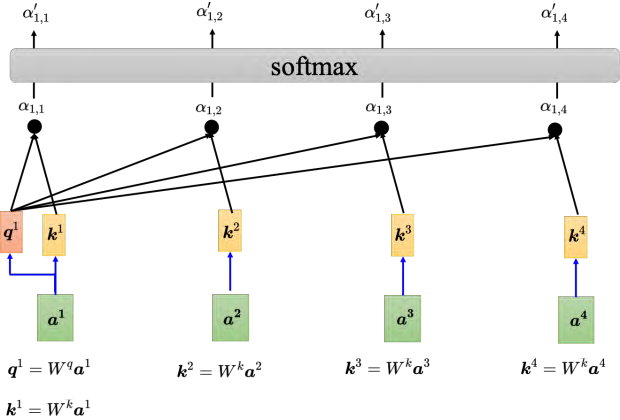
Q:为什么要用 softmax?
A:**这边不一定要用 softmax,可以用别的激活函数,比如 ReLU。有人尝试使用 ReLU,结果发现还比 softmax 好一点。**所以不一定要用 softmax, softmax 只是最常见的,我们可以尝试其他激活函数,看能不能试出比 softmax 更好的结果。
得到 _α′ _以后,接下来根据 _α′ _去抽取出序列里面重要的信息。如图 6.21 所示,根据 _α _可知哪些向量跟 _a_1 是最有关系的,接下来我们要根据关联性,即注意力的分数来抽取重要的信息。把向量 _a_1 到 _a_4 乘上 _**W v **_得到新的向量: _v_1、 _v_2、 _v_3 和 _v_4,接下来把每一个向量都去乘上注意力的分数 α′,再把它们加起来,如式 (6.4) 所示。
b
1
=
∑
i
α
1
,
i
′
v
i
b^1=\sum_i\alpha_{1,i}^{\prime}\boldsymbol{v}^i
b1=∑iα1,i′vi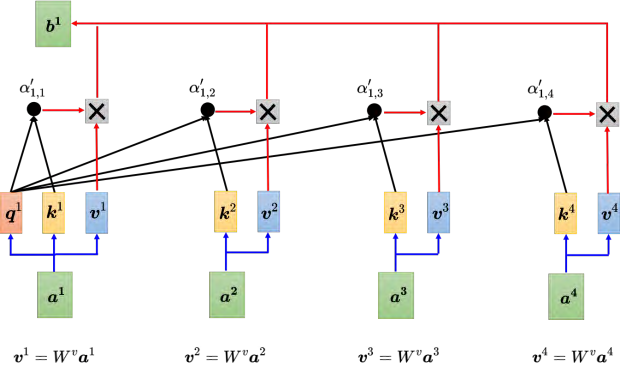
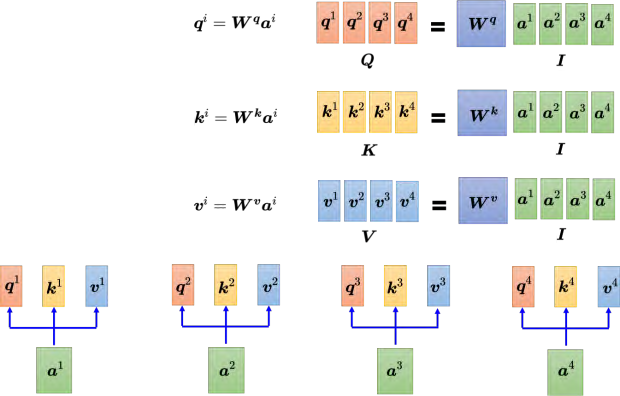
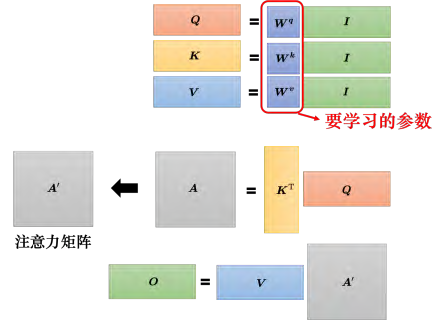
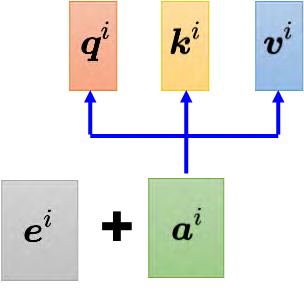
如何化简:如果要用矩阵运算表示这个操作,每一个 _ai _都乘上一个矩阵 _**W q **_得到 qi,这些不同的 _**a **_可以合起来当作一个矩阵。什么意思呢? _a_1 乘上 _**W q **_得到 _q_1, _a_2 也乘上 _**W q **_得到 _q_2,以此类推。把 _a_1 到 _a_4 拼起来可以看作是一个矩阵 I,矩阵 _**I **_有四列,它的列就是自注意力的输入: _a_1 到 _a_4。把矩阵 _**I **_乘上矩阵 _W q_得到 Q。 _**W q **_是网络的参数, _**Q **_的四个列就是 _q_1 到 _q_4。 (1️⃣第一步,我们首先得到查询Q)
产生 _**k **_和 _**v **_的操作跟 _**q **_是一模一样的, _**a **_乘上 _**W k **_就会得到键 k。把 _**I **_乘上矩阵 W k,就得到矩阵 K。 _**K **_的 4 个列就是 4 个键: _k_1 到 _k_4。 _**I **_乘上矩阵 _**W v **会得到矩阵 **V **。矩阵**V **_的 4 个列就是 4 个向量 _v_1 到 _v_4。因此把输入的向量序列分别乘上三个不同的矩阵可得到 q、 _**k **_和 v。 (1️⃣同样的,我们可以得到键K和值V)
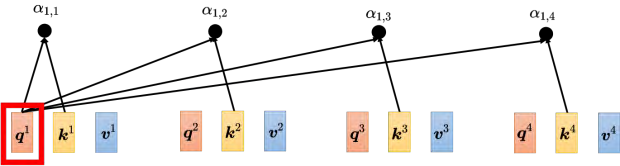
下一步是每一个 _**q **_都会去跟每一个 _**k **_去计算内积,去得到注意力的分数,先计算 _q_1 的注意力分数
如果从矩阵操作的角度来看注意力计算这个操作,把 _q_1 跟 _k_1 做内积,得到 α_1,_1。 _q1 乘上 (k_1)T,也就是 _q_1 跟 _k_1 做内积。同理, α_1,_2 是 _q_1 跟 _k_2 做内积, α_1,3 是q_1 跟 _k_3 做内积, α_1,_4 就是 _q_1 跟 _k_4 做内积。这四个步骤的操作,其实可以把它拼起来,看作是矩阵跟向量相乘。 _q_1 乘 _k_1, _q_1 乘 _k_2, _q_1 乘 _k_3, _q_1 乘 _k4 这四个动作,可以看作是把(k1)T 到 (k_4)T 拼起来当作是一个矩阵的四行,把这个矩阵乘上 _q_1 可得到注意力分数的矩阵,矩阵的每一行都是注意力的分数,即 α_1,_1 到 α_1,_4。 (2️⃣通过Q和K,我们可以得到注意力分数阿尔法)
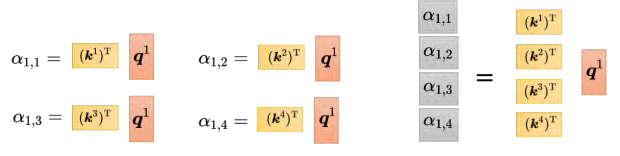
通过两个矩阵的相乘就得到注意力的分数。一个矩阵的行就是 k,即 _k_1到 _k_4。另外一个矩阵的列就是 q,即 _q_1 到 _q_4。把 _**k **_所形成的矩阵 _K_T 乘上 _**q **_所形成的矩阵 _**Q **_就得到这些注意力的分数。假设 _**K **_的列是 _k_1 到 _k_4,在这边相乘的时候,要对矩阵 _K_做一下转置得到 _K_T, _K_T 乘上 _**Q **_就得到矩阵 A, _**A **_里面存的就是 _**Q **_跟 _**K **_之间的注意力的分数。对注意力的分数做一下归一化(normalization),比如使用 softmax,对 _**A **_的每一列做 softmax,让每一列里面的值相加是 1。 softmax 不是唯一的选项,完全可以选择其他的操作,比如 ReLU 之类的,得到的结果也不会比较差。由于把 _α _做 softmax 操作以后,它得到的值有异于 _α _的原始值,所以用 _A′ _来表示通过 softmax 以后的结果。(3️⃣我们对所有得到的阿尔法进行softmax.归一化。)

计算出 _A′ _以后,需要把 _v_1 到 _v_4 乘上对应的 _α _再相加得到 b。如果把 _v_1 到 _v_4 当成是矩阵 _**V **_的 4 个列拼起来,则把 _A′ _的第一个列乘上 _**V **_就得到 _b_1,把 _A′_的第二个列乘上 _**V **_得到 _b_2,以此类推。所以等于把矩阵 _A′ _乘上矩阵 _**V **得到矩阵 O。矩阵**O **_里面的每一个列就是自注意力的输出 _b_1 到 _b_4。所以整个自注意力的操作过程可分为以下步骤,先产生了 q、 _**k **_和 v,再根据 _**q **_去找出相关的位置,然后对 _**v **做加权和。这一串操作就是一连串矩阵的乘法。 (4️⃣我们将得到的归一化后的矩阵与V相乘,得到b)
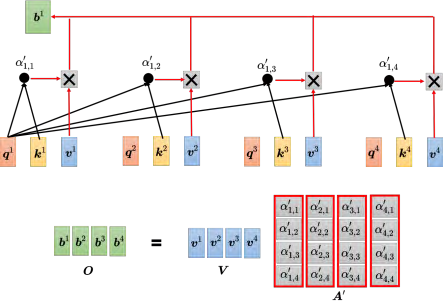
总结:自注意力的输入是一组的向量,将这排向量拼起来可得到矩阵 I。输入**I **_分别乘上三个矩阵: W q、 _**W k **_跟 **W v **,得到三个矩阵 Q、 _**K **_和 **V **。接下来 _**Q **_乘上 _K_T 得到矩阵 A。把矩阵 _**A **_做一些处理可得到 A′, _A′ 称为注意力矩阵(attention matrix)。把A′ _再乘上 _**V **_就得到自注意力层的输出 O。自注意力的操作较为复杂,但自注意力层里面唯一需要学的参数就只有 W q、 _**W k **_跟 W v。只有 W q、 W k、 _**W v **_是未知的,需要通过训练数据把它学习出来的。其他的操作都没有未知的参数,都是人为设定好的,都不需要通过训练数据学习。
6.3 多头注意力
自注意力有一个进阶的版本——多头自注意力(multi-head self-attention)。多头自注意力的使用是非常广泛的,有一些任务,比如翻译、语音识别,用比较多的头可以得到比较好的结果。至于需要用多少的头,这个又是另外一个超参数,也是需要调的。为什么会需要比较多的头呢?在使用自注意力计算相关性的时候,就是用 **q _去找相关的 k。但是相关有很多种不同的形式,所以也许可以有多个 **q**,不同的 ****q **_**负责不同种类的相关性,这就是多头注意力 **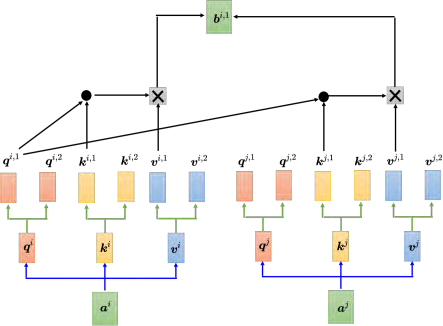
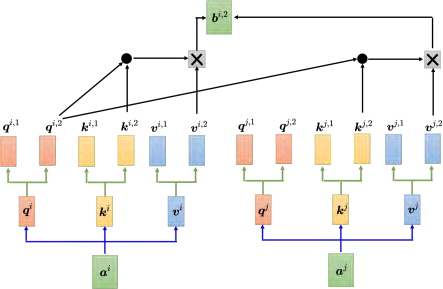
其实就是把 q、 k、 _**v **_分别乘上两个矩阵,得到不同的头。对另外一个位置也做一样的事情,另外一个位置在输入 _**a **_以后,它也会得到两个 q、两个 k、两个 v。接下来怎么做自注意力呢,跟之前讲的操作是一模一样的,只是现在 1 那一类的一起做, 2 那一类的一起做。也就是 _q_1 在算这个注意力的分数的时候,就不要管 _k_2 了,它就只管 _k_1 就好。 _qi,_1 分别与 _ki,_1、 _kj,_1 算注意力,在做加权和的时候也不要管 _v2 了,看vi,_1 跟 _vj,_1 就好,把注意力的分数乘 _vi,_1 和 _vj,_1,再相加得到 _bi,_1,这边只用了其中一个头。 
6.4 位置编码
自注意力层少了一个也许很重要的信息,即位置的信息。 对一个自注意力层而言,每一个输入是出现在序列的最前面还是最后面,它是完全没有这个信息的。有人可能会问:输入不是有位置 1、 2、 3、 4 吗?但 1、 2、 3、 4 是作图的时候,为了帮助大家理解所标上的一个编号。对自注意力而言,位置 1、位置 2、位置 3 跟位置 4 没有任何差别,这四个位置的操作是一模一样的。对它来说, _q_1 跟 _q_4 的距离并没有特别远, 1 跟 4 的距离并没有特别远, 2 跟 3 的距离也没有特别近,对它来说就是天涯若比邻,所有的位置之间的距离都是一样的,没有谁在整个序列的最前面,也没有谁在整个序列的最后面。但是这可能会有一个问题:位置的信息被忽略了,而有时候位置的信息很重要。举个例子,在做词性标注的时候,我们知道动词比较不容易出现在句首,如果某一个词汇它是放在句首的,它是动词的可能性就比较低,位置的信息往往也是有用的。可是到目前为止,自注意力的操作里面没有位置的信息。因此做自注意力的时候,如果我们觉得位置的信息很重要,需要考虑位置信息时,就要用到位置编码(positional encoding)。如图 6.32 所示,位置编码为每一个位置设定一个向量,即位置向量(positional vector)。位置向量用 _ei _来表示,上标 _i _代表位置,不同的位置就有不同的向量,不同的位置都有一个专属的 e,把 _**e **_加到 _ai _上面就结束了。这相当于告诉自注意力位置的信息,如果看到 _ai _被加上 ei,它就知道现在出现的位置应该是在 _i _这个位置。
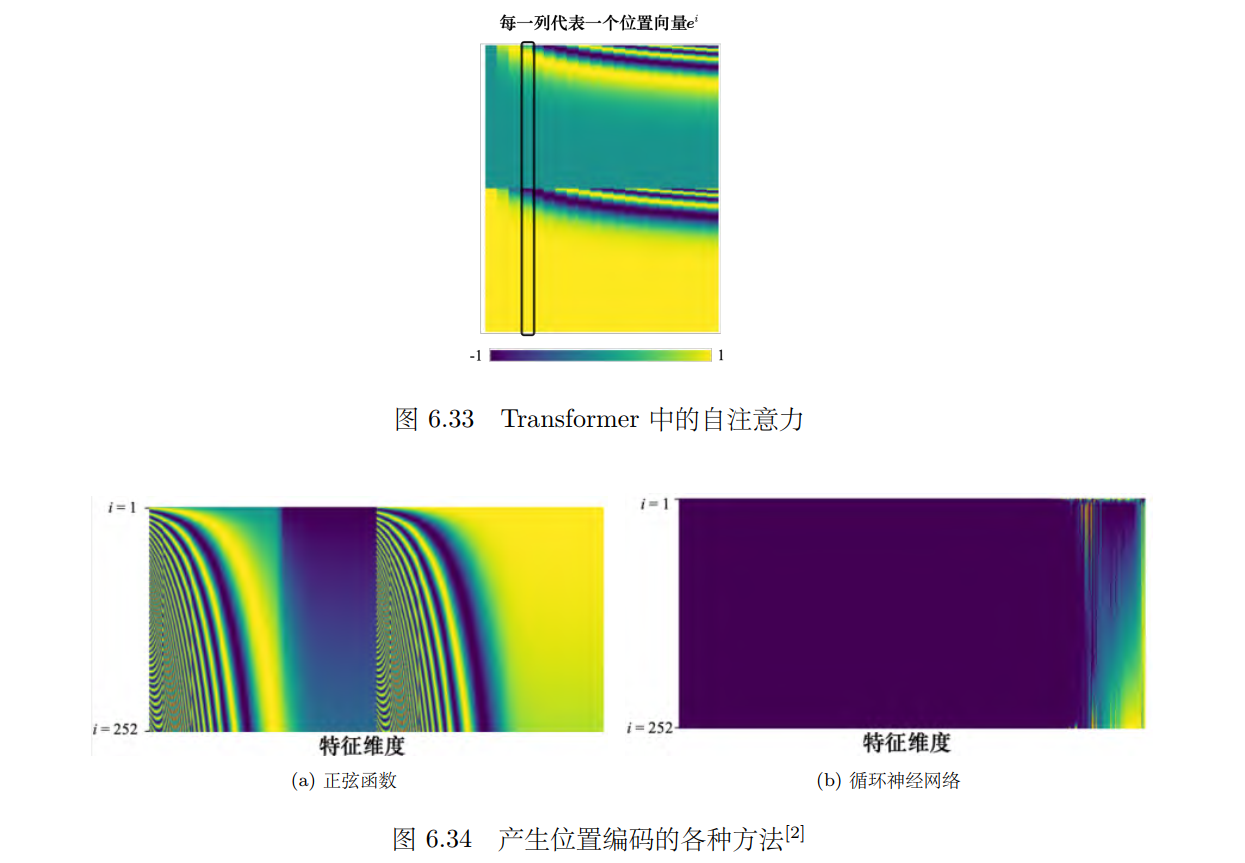
最早的 Transformer 论文 “Attention Is All You Need” 用的 _ei _如图 6.33 所示。图上面每一列就代表一个 e,第一个位置就是 _e_1,第二个位置就是 _e_2,第三个位置就是 _e_3,以此类推。每一个位置的 _**a **_都有一个专属的 e。模型在处理输入的时候,它可以知道现在的输入的位置的信息,这个位置向量是人为设定的。人为设定的向量有很多问题,假设在定这个向量的时候只定到 128,但是序列的长度是 129,怎么办呢?**在最早的 “Attention Is All You Need” 论文中,其位置向量是通过正弦函数和余弦函数所产生的,避免了人为设定向量固定长度的尴尬 **
Q:为什么要通过正弦函数和余弦函数产生向量,有其他选择吗?为什么一定要这样产生手工的位置向量呢?
A:不一定要通过正、余弦函数来产生向量,我们可以提出新的方法。此外,不一定要这样产生手工的向量,位置编码仍然是一个尚待研究的问题,甚至位置编码是可以根据数据学出来的。有关位置编码,**可以参考论文 “Learning to Encode Position for Transformer with Continuous Dynamical Model”,该论文比较了不同的位置编码方法并提出了新的位置编码。 **
如图 6.34a 所示,最早的位置编码是用正弦函数所产生的,图 6.34a 中每一行代表一个位置向量。如图 6.34b 所示,位置编码还可以使用循环神经网络生成。总之,位置编码可通过各种不同的方法来产生。目前还不知道哪一种方法最好,这是一个尚待研究的问题。所以不用纠结为什么正弦函数最好,我们永远可以提出新的做法。
6.5 截断自注意力
一段声音信号,通过向量序列描述它的时候,这个向量序列的长度是非常大的。非常大的长度会造成什么问题呢?在计算注意力矩阵的时候,其复杂度(complexity)是长度的平方。假设该矩阵的长度为 L,计算注意力矩阵 _A′ _需要做 _L × L _次的内积,如果 _L _的值很大,计算量就很可观,并且需要很大内存(memory)才能够把该矩阵存下来。所以如果在做语音识别的时候,我们讲一句话,这一句话所产生的这个注意力矩阵可能会太大,大到不容易处理,不容易训练
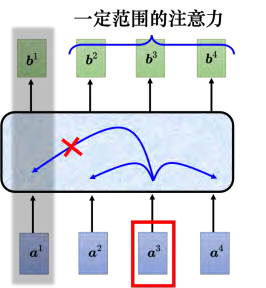
截断自注意力(truncated self-attention) 可以处理向量序列长度过大的问题。截断自注意力在做自注意力的时候不要看一整句话,就只看一个小的范围 就好,这个范围是人设定的。在做语音识别的时候,如果要辨识某个位置有什么样的音标,这个位置有什么样的内容,并不需要看整句话,只要看这句话以及它前后一定范围之内的信息,就可以判断。在做自注意力的时候,也许没有必要让自注意力考虑一整个句子,只需要考虑一个小范围就好,这样就可以加快运算的速度。这就是截断自注意力。
6.6 自注意力与卷积神经网络对比
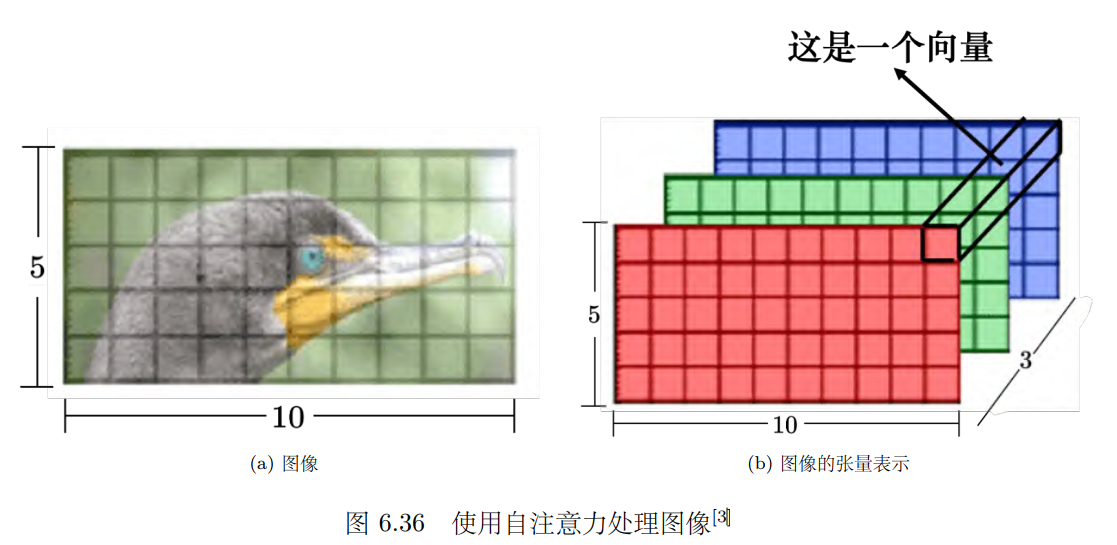
自注意力还可以被用在图像上。到目前为止,在提到自注意力的时候,自注意力适用的范围是输入为一组向量的时候。一张图像可以看作是一个向量序列,如图 6.36 所示,一张分辨率为 5 _× _10 的图像(图 6.36a)可以表示为一个大小为 5 _× _10 _× _3 的张量(图 6.36b), 3 代表 RGB 这 3 个通道(channel),每一个位置的像素可看作是一个三维的向量,整张图像是5 _× _10 个向量。所以可以换一个角度来看图像,图像其实也是一个向量序列,它既然也是一个向量序列,完全可以用自注意力来处理一张图像。自注意力在图像上的应用,读者可以参考 “Self-Attention Generative Adversarial Networks” 和 “End-to-End Object Detection with Transformers” 这两篇论文。
在做卷积神经网络的时候,卷积神经网络会“画”出一个感受野,每一个滤波器,每一个神经元,只考虑感受野范围里面的信息。所以如果我们比较卷积神经网络跟自注意力会发现,卷积神经网络可以看作是一种简化版的自注意力,因为在做卷积神经网络的时候,只考虑感受野里面的信息。而在做自注意力的时候,会考虑整张图像的信息。在卷积神经网络里面,我们要划定感受野。每一个神经元只考虑感受野里面的信息,而感受野的大小是人决定的。 而用自注意力去找出相关的像素,就好像是感受野是自动被学出来的,网络自己决定感受野的形状。网络决定说以这个像素为中心,哪些像素是真正需要考虑的,哪些像素是相关的,所以感受野的范围不再是人工划定,而是让机器自己学出来。关于自注意力跟卷积神经网络的关系,读者可以读论文 “On the Relationship between Self-attention and Convolutional Layers”,这篇论文里面会用数学的方式严谨地告诉我们, **卷积神经网络就是自注意力的特例。 ** 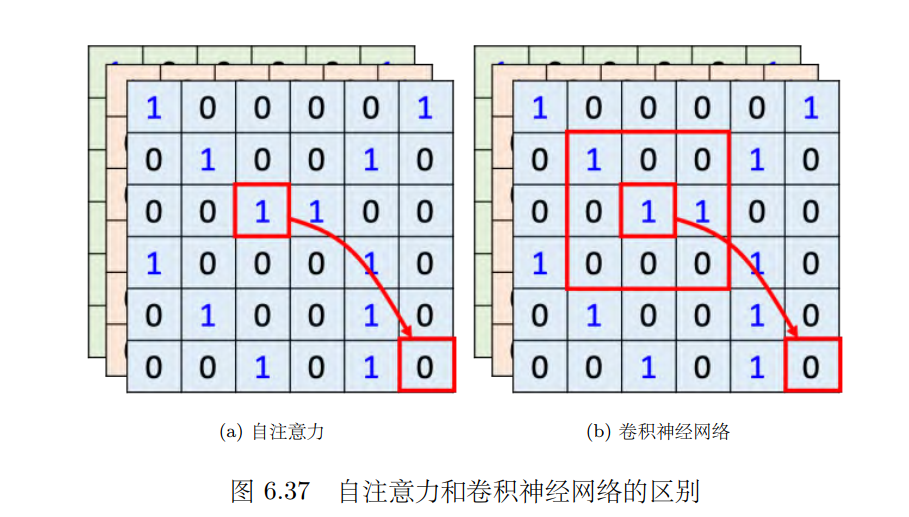
自注意力只要通过某些设计、某些限制就会变成卷积神经网络

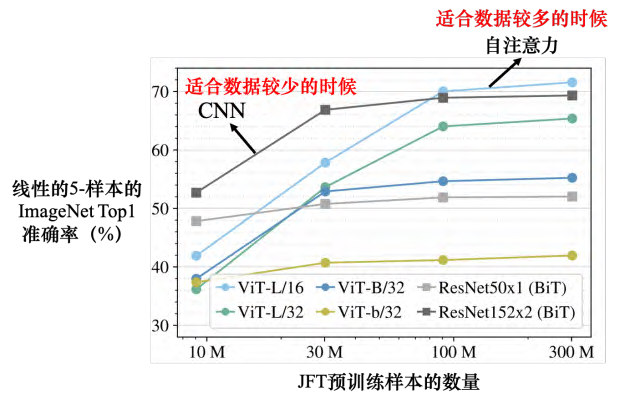
既然卷积神经网络是自注意力的一个子集,说明自注意力更灵活。更灵活的模型需要更多的数据。如果数据不够,就有可能过拟合。而比较有限制的模型,它适合在数据少的时候使用,它可能比较不会过拟合。如果限制设的好,也会有不错的结果。
研究表明:随着数据量越来越多,自注意力的结果越来越好。 最终在数据量最多的时候,自注意力可以超过卷积神经网络,但在数据量少的时候,卷积神经网络是可以比自注意力得到更好的结果的。自注意力的弹性比较大,所以需要比较多的训练数据,训练数据少的时候就会过拟合。而卷积神经网络的弹性比较小,在训练数据少的时候结果比较好。但训练数据多的时候,它没有办法从更大量的训练数据得到好处。
Q:自注意力跟卷积神经网络应该选哪一个?
A:事实上可以都用,比如 conformer 里面同时用到了自注意力和卷积神经网络。
6.7 自注意力与循环神经网络对比
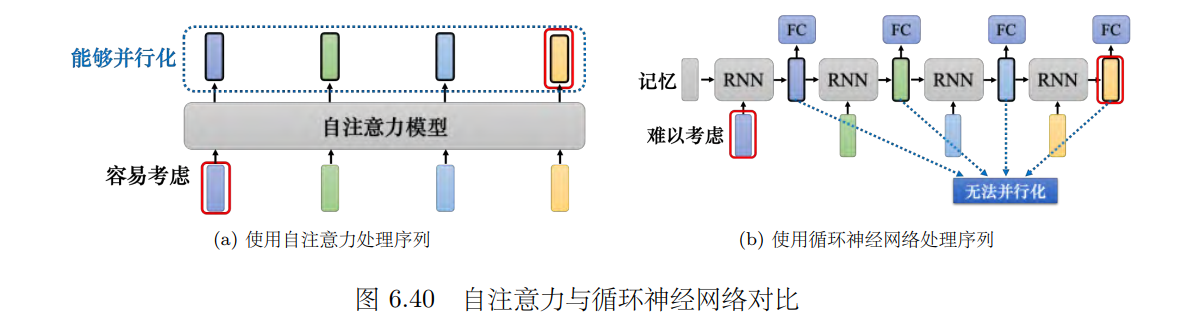
循环神经网络主要用于处理输入序列的情况,其中每个隐状态向量存储了历史信息,可以看作一种记忆。而自注意力则不需要考虑历史信息,每个向量都会考虑整个输入序列,从而更容易从整个序列中提取信息。但循环神经网络也可以是双向的,所以如果用双向循环神经网络(Bidirectional Recurrent Neural Network, Bi-RNN),那么每一个隐状态的输出也可以看作是考虑了整个输入的序列
自注意力跟循环神经网络还有另外一个更主要的不同是,循环神经网络在处理输入、输出均为一组序列的时候,是没有办法并行化的。 比如计算第二个输出的向量,不仅需要第二个输入的向量,还需要前一个时间点的输出向量。当输入是一组向量,输出是另一组向量的时候,循环神经网络无法并行处理所有的输出,但自注意力可以。自注意力输入一组向量,输出的时候,每一个向量是同时并行产生的,**因此在运算速度上,自注意力会比循环神经网络更有效率。很多的应用已经把循环神经网络的架构逐渐改成自注意力的架构了。**如果想要更进一步了解循环神经网络跟自注意力的关系,可以阅读论文 “Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention”
 举个例子,如图 6.41 所示,在这个图上,节点 1 只和节点 5、 6、 8 相连,因此只需要计算节点 1 和节点 5、节点 6、节点 8 之间的注意力分数;节点 2 之和节点 3 相连,因此只需要计算节点 2 和节点 3 之间的注意力的分数,以此类推。如果两个节点之间没有相连,这两个节点之间就没有关系。既然没有关系,就不需要再去计算它的注意力分数,直接把它设为 0就好了。因为图往往是人为根据某些领域知识(domain knowledge)建出来的,所以从领域知识可知这两个向量之间没有关联,就没有必要再用机器去学习这件事情。当把自注意力按照这种限制用在图上面的时候,其实就是一种 **图神经网络(Graph Neural Network, GNN)。 **
举个例子,如图 6.41 所示,在这个图上,节点 1 只和节点 5、 6、 8 相连,因此只需要计算节点 1 和节点 5、节点 6、节点 8 之间的注意力分数;节点 2 之和节点 3 相连,因此只需要计算节点 2 和节点 3 之间的注意力的分数,以此类推。如果两个节点之间没有相连,这两个节点之间就没有关系。既然没有关系,就不需要再去计算它的注意力分数,直接把它设为 0就好了。因为图往往是人为根据某些领域知识(domain knowledge)建出来的,所以从领域知识可知这两个向量之间没有关联,就没有必要再用机器去学习这件事情。当把自注意力按照这种限制用在图上面的时候,其实就是一种 **图神经网络(Graph Neural Network, GNN)。 **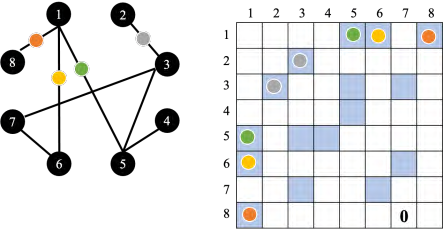
自注意力有非常多的变形,论文 “Long Range Arena: A Benchmark for Effcient Transformers” 里面比较了各种不同的自注意力的变形。自注意力最大的问题是其运算量非常大,如何减少自注意力的运算量是未来可研究的重点方向。自注意力最早是用在 Transformer 上面,所以 很多人讲 Transformer 的时候,其实指的是自注意力。有人说广义的 Transformer 指的就是自注意力,所以后来各种的自注意力的变形都叫做是 xxformer,比如 Linformer、 Performer、Reformer 等等。这些新的 xxformer 往往比原来的 Transformer 性能差一点,但是速度会比较快。论文 “Effcient Transformers: A Survey” 介绍了各种自注意力的变形。
思维导图















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









