







前言
pyspider 是由国人 binux 编写的强大的网络爬虫系统,pyspider 带有强大的 WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,它支持多种数据库后端、多种消息队列、JavaScript 渲染页面的爬取,使用起来很方便。
pyspider 安装问题:pyspider 常见启动问题解决汇总【detailed】
pyspider github 地址:GitHub - binux/pyspider
pyspider 官方文档:Introduction - pyspider
pyspider 功能:
- 提供方便易用的 WebUI 系统,可以可视化地编写和调试爬虫
- 提供爬取进度监控、爬取结果查看、爬虫项目管理等功能
- 支持多种后端数据库,如 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL
- 支持多种消息队列,如 RabbitMQ、Beanstalk、Redis、Kombu
- 提供优先级控制、失败重试、定时抓取等功能
- 对接了 PhantomJS,可以抓取 JavaScript 渲染的页面
- 支持单机和分布式部署,支持 Docker 部署
pyspider 的使用
1. 创建项目
输入 localhost:5000 成功进入 pyspider WebUI 界面后,点击蓝色 create 按钮即可创建项目:


创建完成后,状态如下:
 2. 进入项目
2. 进入项目
点击项目名称,即可进入项目:

以下为进入项目后的初始调试页面代码:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://travel.qunar.com/travelbook/list.htm', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}3. 编辑项目


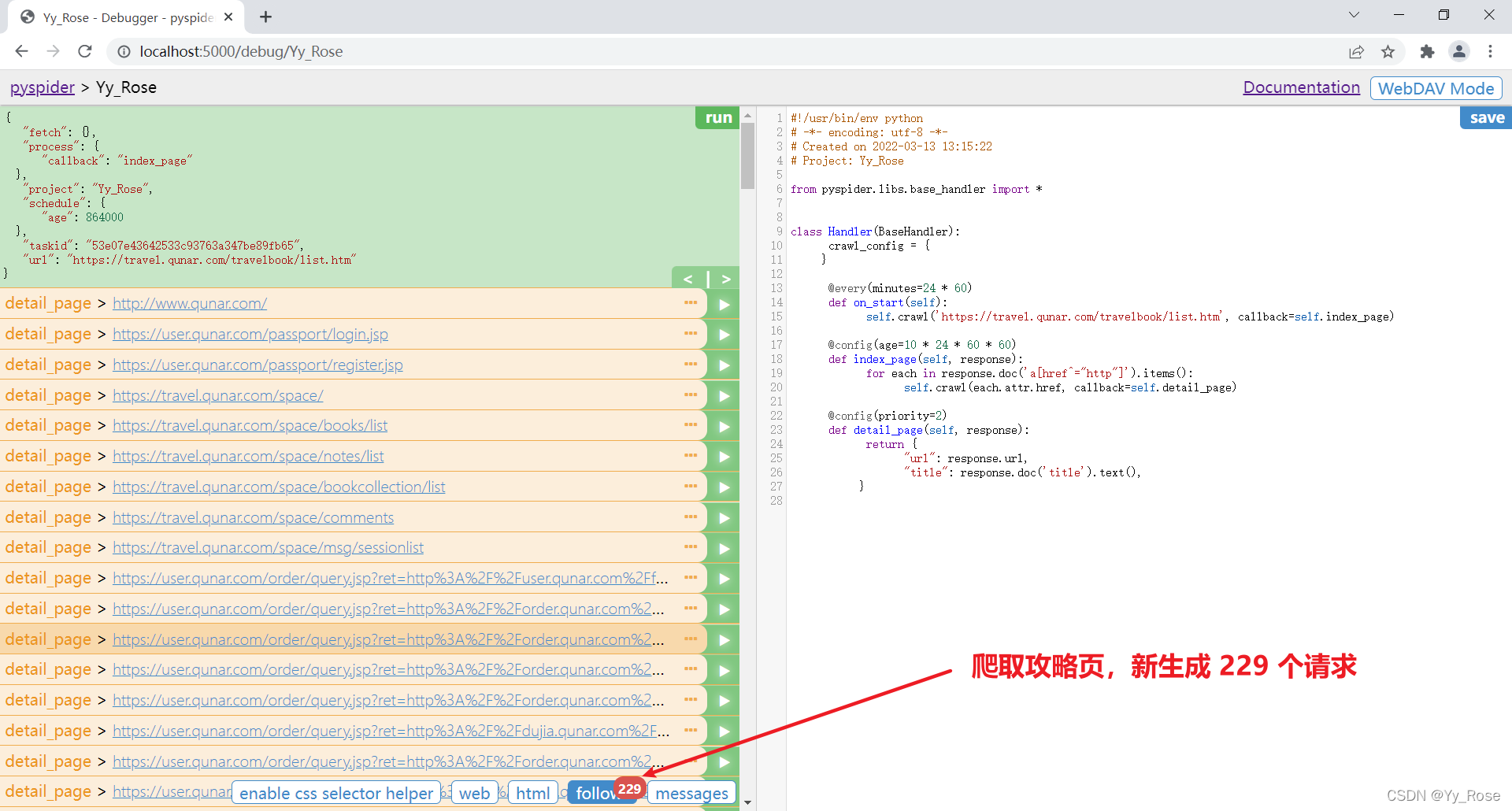

web 显示页面大小设置可参考:pyspider显示web太小,未设置之前 web 页面可能会很小


爬取下一页 index_page( ) 函数体中添加以下代码即可 :
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page)


运行结果切换到 Web 页面预览效果,页面下拉之后,头图正文中的一些图片一直显示加载中:

原因:pyspider 默认发送 HTTP 请求,请求的 HTML 文档本身就不包含 img 节点,但是在浏览器中我们看到了图片,这是因为这张图片是后期经过 JavaScript 出现的
解决方法:craw_config{ } 中可以添加一些头文件信息,例如代理 ip、浏览器 User-Agent、爬取设置等等,在其中添加 "fetch_type": 'js' 即可,该行代码也可以添加到如下位置:
def index_page(self, response):
for each in response.doc('li> .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page)
图片成功显示:

将详情页中需要的信息提取出来则将 detail_page( ) 下的代码改写为对应的元素标签节点定位即可,以下以日期节点为例(F12 即可进入开发者工具):

'date': response.doc('.when .data').text() # .text() 获取文本信息这里我们获取的是页面的链接、标题、出行日期、出行天数、人物、攻略正文、头图信息:
@config(priority=2)
def detail_page(self, response):
return {
'url': response.url,
'title': response.doc('#booktitle').text(),
'date': response.doc('.when .data').text(),
'day': response.doc('.howlong .data').text(),
'who': response.doc('.who .data').text(),
'text': response.doc('#b_panel_schedule').text(),
'image': response.doc('.cover_img').attr.src
}成功获取相关信息:

4. 查看爬取内容
再次进入链接 localhost:5000,将 status 改为 DEBUG 或 RUNNING,点击 run,即运行项目:

点击 Results 即可查看爬取内容:
点击右上角的按钮,即可获取数据的 JSON、CSV 格式:

点击 Active Tasks 即可查看最近请求的详细状况:

相关知识点
rate/burst 代表当前的爬取速率,rate 代表 1 秒发出多少个请求,burst 相当于流量控制中的令牌桶算法的令牌数,rate 和 burst 设置的越大,爬取速率越快,当然速率需要考虑本机性能和爬取过快被封的问题:

process 中的 5m、1h、1d 指的是最近 5 分、1 小时、1 天内的请求情况,all 代表所有的请求情况。请求由不同颜色表示,蓝色的代表等待被执行的请求,绿色的代表成功的请求,黄色的代表请求失败后等待重试的请求,红色的代表失败次数过多而被忽略的请求:

pyspider 中没有直接删除项目的选项,如要删除任务,那么将项目的状态设置为 STOP,将分组的名称设置为 delete,等待 24 小时,则项目会自动删除:

每个项目都有 6 个状态,分别是 TODO、STOP、CHECKING、DEBUG、RUNNING、PAUSE:
- TODO:它是项目刚刚被创建还未实现时的状态
- STOP:如果想停止某项目的抓取,可以将项目的状态设置为 STOP
- CHECKING:正在运行的项目被修改后就会变成 CHECKING 状态,项目在中途出错需要调整的时候会遇到这种情况
- DEBUG/RUNNING:这两个状态对项目的运行没有影响,状态设置为任意一个,项目都可以运行,但是可以用二者来区分项目是否已经测试通过
- PAUSE:当爬取过程中出现连续多次错误时,项目会自动设置为 PAUSE 状态,并等待一定时间后继续爬取
调试页面完整代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-06-08 00:45:57
# Project: qunar
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
"user_agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36",
"timeout": 120,
"connect_timeout": 60,
"retries": 5,
"fetch_type":'js',
"auto_recrawl": True,
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page)
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
return {
'url': response.url,
'title': response.doc('#booktitle').text(),
'date': response.doc('.when .data').text(),
'day': response.doc('.howlong .data').text(),
'who': response.doc('.who .data').text(),
'text': response.doc('#b_panel_schedule').text(),
'image': response.doc('.cover_img').attr.src
}总结
以上为 pyspider 的基本使用方法,感谢您的观看,欢迎评论区留言指正交流~
参考资料:[Python3网络爬虫开发实战] 静觅















 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









