







一、传统神经网络与卷积神经网络
传统多层神经网络
传统意义上的多层神经网络是只有输入层、隐藏层、输出层。

卷积神经网络
卷积神经网络CNN,在原来多层神经网络的基础上,加入了更加有效的特征学习部分,具体操作就是在原来的全连接的层前面加入了部分连接的卷积层与池化层。

二、CNN的结构
卷积层(Convolutional Layer)
池化层(Max Pooling Layer)
全连接层(Fully Connected Layer)
卷积层(卷积+激活)
神经网络(neural networks)的基本组成包括输入层、隐藏层、输出层。而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)以及激活层。
卷积层:通过在原始图像上平移来提取特征
激活层:增加非线性分割能力
池化层:压缩数据和参数的量,减小过拟合,降低网络的复杂度,(最大池化和平均池化)
为了能够达到分类效果,还会有一个全连接层(FC)也就是最后的输出层,计算损失进行分类(或回归)。
卷积层(Convolutional Layer)
卷积层(Convolutional layer),卷积神经网络中每层卷积层由若干卷积单元(卷积核)组成。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
其实卷积层就是我们所做的一大堆特定的滤波器,该滤波器会对某些特定的特征进行强烈的响应,一般情况下是结果值非常大。而对一些无关特性,其响应很小,大部分是结果相对较小,或者几乎为0
卷积的计算
现在看起来做卷积,就是把输入图片的像素矩阵与卷积核(过滤器,filter)做矩阵乘法,是已经简化的写法了。之前的卷积是要把filter做旋转,再和像素矩阵做乘法,但是实验表明直接乘法和旋转后乘法,对结果影响不大,所以逐渐简化了。

Stride 步长
▪滑动窗便开始向右边滑动。根据步长的不同选择滑动幅度。
▪比如,若 步长 stride=1,就往右平移一个像素。
▪若 步长 stride=2,就往右平移两个像素。
▪(除不断就向下取整)



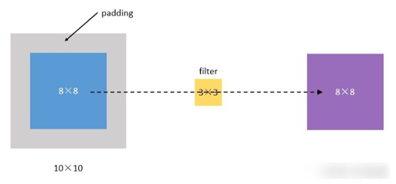
Padding 填白
▪ 原图像在经过filter卷积之后,变小了,从(8,8)变成了(6,6)。假设我们再卷一次,那大小就变成了(4,4)了。
▪主要有两个问题:
▪ - 每次卷积,图像都缩小,这样卷不了几次就没了;
▪ - 相比于图片中间的点,图片边缘的点在卷积中被计算的次数很少。这样的话,边缘的信息就易于丢失。
▪为了解决这个问题,我们可以采用padding的方法。我们每次卷积前,先给图片周围都补一圈空白,让卷积之后图片跟原来一样大,同时,原来的边缘也被计算了更多次。
▪“让卷积之后的大小不变”的padding方式,称为 “Same”方式, 把不经过任何填白的,称为 “Valid”方式。这个是我们在使用一些框架的时候,需要设置的超参数。
▪公式
▪nn () ff
▪步长s
▪ => (n+2p-f)/s + 1 () (n+2p-f)/s + 1
池化层(Max Pooling Layer)
▪池化层则是为了让训练的参数更少,防止模型过拟合,在保持采样不变的情况下,忽略掉一些信息。
▪可以减少展示量,提高计算速度,使特征检测功能更强大。

全连接层
全连接层的作用主要是进行分类。前面通过卷积和池化层得出的特征,在全连接层对这些总结好的特征做分类。全连接层就是一个完全连接的神经网络,根据权重每个神经元反馈的比重不一样,最后通过调整权重和网络得到分类的结果。
CNN输出的特征空间作为全连接层或全连接神经网络FCN的输入,用全连接层来完成从输入图像到标签集的映射,即分类
softmax
W是神经元的权值,K是要分类的类别数,X是上一层的输出平铺(Flatten)后的结果.
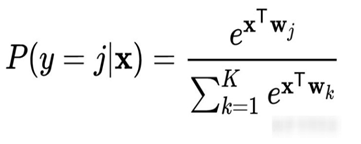

▪Y = a(wx+b)

三、CNN的优势
参数共享机制(parameters sharing)
连接的稀疏性(sparsity of connections)
▪参数共享机制(parameters sharing)

▪由卷积的操作可知,输出图像中的任何一个单元,只跟输入图像的一部分有关系:
▪而传统神经网络中,由于都是全连接,所以输出的任何一个单元,都要受输入的所有的单元的影响。这样无形中会对图像的识别效果大打折扣。比较,每一个区域都有自己的专属特征,我们不希望它受到其他区域的影响。

动起来的CNN:
https://poloclub.github.io/cnn-explainer/#article-relu















 4375
4375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









