






1.首先我们要安装lxml库(不知道lxml的同学可以去搜索了解一下这里简单提一下:lxml库是帮助HTML,XML文件,快速定位,搜索,获取特定内容的python库)
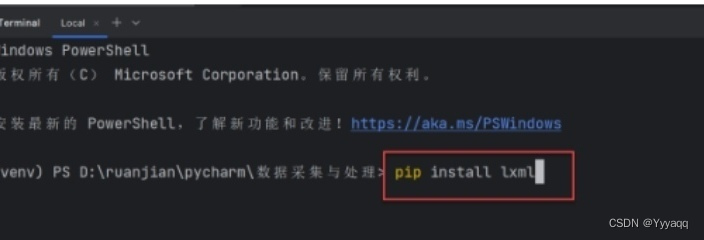
2.获取文本元素内容
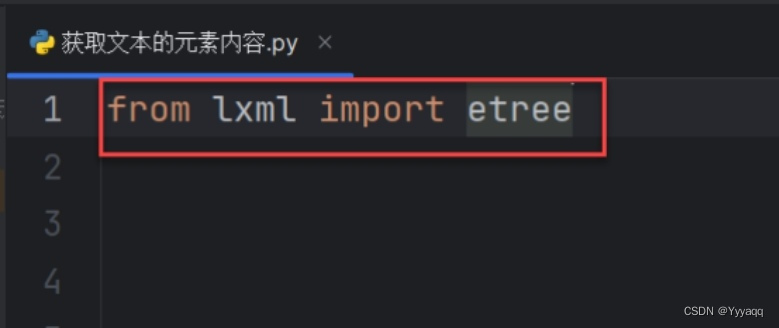
(1)导入lxml库的etree包(通过 requests . get 方法获得 html 源代码后,可以通过 etree 进行解析,进而从源代码中提取关键信息 etree 主要通过 xpath 进行定位)
(2)截取网页文本内容(在网页中按F12进入控制台)
(3)使用etree解析网页

然后就可以一层一层的定位打印所需要的内容例如: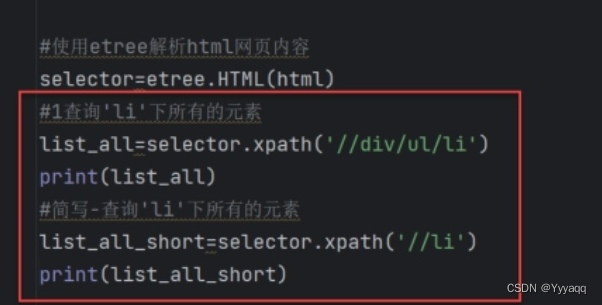
接下来是我学习时做的笔记,感兴趣的可以看一下















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









