







目录
Yolo的任务分类
Train(训练)
概念
YOLOv8 中的 "训练 "模式充分利用现代硬件能力,专为高效训练物体检测模型而设计。可以训练出自己的模型
demo
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from YAML
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
model = YOLO("yolov8n.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)参数
| 参数 | 默认值 | 说明 |
|---|---|---|
model | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
data | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
epochs | 100 | 训练历元总数。每个历元代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
time | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的历元数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
batch | 16 | 训练的批量大小,表示在更新模型内部参数之前要处理多少张图像。自动批处理 (batch=-1)会根据 GPU 内存可用性动态调整批处理大小。 |
imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
save | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
save_period | -1 | 保存模型检查点的频率,以 epochs 为单位。值为-1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
cache | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False).通过减少磁盘 I/O 提高训练速度,但代价是增加内存使用量。 |
device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
workers | 8 | 加载数据的工作线程数(每 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
project | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
exist_ok | False | 如果为 True,则允许覆盖现有的项目/名称目录。这对迭代实验非常有用,无需手动清除之前的输出。 |
pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
optimizer | 'auto' | 为培训选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
verbose | False | 在训练过程中启用冗长输出,提供详细日志和进度更新。有助于调试和密切监控培训过程。 |
seed | 0 | 为训练设置随机种子,确保在相同配置下运行的结果具有可重复性。 |
deterministic | True | 强制使用确定性算法,确保可重复性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
single_cls | False | 在训练过程中将多类数据集中的所有类别视为单一类别。适用于二元分类任务,或侧重于对象的存在而非分类。 |
rect | False | 可进行矩形训练,优化批次组成以减少填充。这可以提高效率和速度,但可能会影响模型的准确性。 |
cos_lr | False | 利用余弦学习率调度器,根据历时的余弦曲线调整学习率。这有助于管理学习率,实现更好的收敛。 |
close_mosaic | 10 | 在训练完成前禁用最后 N 个历元的马赛克数据增强以稳定训练。设置为 0 则禁用此功能。 |
resume | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
amp | True | 启用自动混合精度 (AMP) 训练,可减少内存使用量并加快训练速度,同时将对精度的影响降至最低。 |
fraction | 1.0 | 指定用于训练的数据集的部分。允许在完整数据集的子集上进行训练,这对实验或资源有限的情况非常有用。 |
profile | False | 在训练过程中,可对ONNX 和TensorRT 速度进行剖析,有助于优化模型部署。 |
freeze | None | 冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。这对微调或迁移学习非常有用。 |
lr0 | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
momentum | 0.937 | 用于 SGD 的动量因子,或用于 Adam 优化器的 beta1,用于将过去的梯度纳入当前更新。 |
weight_decay | 0.0005 | L2 正则化项,对大权重进行惩罚,以防止过度拟合。 |
warmup_epochs | 3.0 | 学习率预热的历元数,学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
warmup_momentum | 0.8 | 热身阶段的初始动力,在热身期间逐渐调整到设定动力。 |
warmup_bias_lr | 0.1 | 热身阶段的偏置参数学习率,有助于稳定初始历元的模型训练。 |
box | 7.5 | 损失函数中边框损失部分的权重,影响对准确预测边框坐标的重视程度。 |
cls | 0.5 | 分类损失在总损失函数中的权重,影响正确分类预测相对于其他部分的重要性。 |
dfl | 1.5 | 分布焦点损失权重,在某些YOLO 版本中用于精细分类。 |
pose | 12.0 | 姿态损失在姿态估计模型中的权重,影响着准确预测姿态关键点的重点。 |
kobj | 2.0 | 姿态估计模型中关键点对象性损失的权重,平衡检测可信度与姿态精度。 |
label_smoothing | 0.0 | 应用标签平滑,将硬标签软化为目标标签和标签均匀分布的混合标签,可以提高泛化效果。 |
nbs | 64 | 用于损耗正常化的标称批量大小。 |
overlap_mask | True | 决定在训练过程中分割掩码是否应该重叠,适用于实例分割任务。 |
mask_ratio | 4 | 分割掩码的下采样率,影响训练时使用的掩码分辨率。 |
dropout | 0.0 | 分类任务中正则化的丢弃率,通过在训练过程中随机省略单元来防止过拟合。 |
val | True | 可在训练过程中进行验证,以便在单独的数据集上对模型性能进行定期评估。 |
plots | False | 生成并保存训练和验证指标图以及预测示例图,以便直观地了解模型性能和学习进度。 |
超参数
| 参数名 | 类型 | 默认值 | 范围 | 说明 |
|---|---|---|---|---|
hsv_h | float | 0.015 | 0.0 - 1.0 | 通过色轮的一部分来调整图像的色调,从而引入色彩的可变性。帮助模型在不同的光照条件下通用。 |
hsv_s | float | 0.7 | 0.0 - 1.0 | 改变图像饱和度的一部分,影响色彩的强度。可用于模拟不同的环境条件。 |
hsv_v | float | 0.4 | 0.0 - 1.0 | 将图像的数值(亮度)修改一部分,帮助模型在不同的光照条件下表现良好。 |
degrees | float | 0.0 | -180 - +180 | 在指定的度数范围内随机旋转图像,提高模型识别不同方向物体的能力。 |
translate | float | 0.1 | 0.0 - 1.0 | 以图像大小的一小部分水平和垂直平移图像,帮助学习检测部分可见的物体。 |
scale | float | 0.5 | >=0.0 | 通过增益因子缩放图像,模拟物体与摄像机的不同距离。 |
shear | float | 0.0 | -180 - +180 | 按指定角度剪切图像,模拟从不同角度观察物体的效果。 |
perspective | float | 0.0 | 0.0 - 0.001 | 对图像进行随机透视变换,增强模型理解三维空间中物体的能力。 |
flipud | float | 0.0 | 0.0 - 1.0 | 以指定的概率将图像翻转过来,在不影响物体特征的情况下增加数据的可变性。 |
fliplr | float | 0.5 | 0.0 - 1.0 | 以指定的概率将图像从左到右翻转,这对学习对称物体和增加数据集多样性非常有用。 |
bgr | float | 0.0 | 0.0 - 1.0 | 以指定的概率将图像通道从 RGB 翻转到 BGR,用于提高对错误通道排序的稳健性。 |
mosaic | float | 1.0 | 0.0 - 1.0 | 将四幅训练图像合成一幅,模拟不同的场景构成和物体互动。对复杂场景的理解非常有效。 |
mixup | float | 0.0 | 0.0 - 1.0 | 混合两幅图像及其标签,创建合成图像。通过引入标签噪声和视觉变化,增强模型的泛化能力。 |
copy_paste | float | 0.0 | 0.0 - 1.0 | 从一幅图像中复制物体并粘贴到另一幅图像上,用于增加物体实例和学习物体遮挡。 |
auto_augment | str | randaugment | - | 自动应用预定义的增强策略 (randaugment, autoaugment, augmix),通过丰富视觉特征来优化分类任务。 |
erasing | float | 0.4 | 0.0 - 0.9 | 在分类训练过程中随机擦除部分图像,鼓励模型将识别重点放在不明显的特征上。 |
crop_fraction | float | 1.0 | 0.1 - 1.0 | 将分类图像裁剪为其大小的一小部分,以突出中心特征并适应对象比例,减少背景干扰。 |
常用参数
epoch、 imgsz、 save、 device、 workers
Val(评估)
概念
Val 模式提供了一套强大的工具和指标,用于评估对象检测模型的性能
demo
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category参数/超参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
data | str | None | 指定数据集配置文件的路径(如 coco8.yaml).该文件包括验证数据的路径、类名和类数。 |
imgsz | int | 640 | 定义输入图像的尺寸。所有图像在处理前都会调整到这一尺寸。 |
batch | int | 16 | 设置每批图像的数量。使用 -1 的自动批处理功能,可根据 GPU 内存可用性自动调整。 |
save_json | bool | False | 如果 True此外,还可将结果保存到 JSON 文件中,以便进一步分析或与其他工具集成。 |
save_hybrid | bool | False | 如果 True,保存混合版本的标签,将原始注释与额外的模型预测相结合。 |
conf | float | 0.001 | 设置检测的最小置信度阈值。置信度低于此阈值的检测将被丢弃。 |
iou | float | 0.6 | 设置非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。有助于减少重复检测。 |
max_det | int | 300 | 限制每幅图像的最大检测次数。在密度较高的场景中非常有用,可以防止检测次数过多。 |
half | bool | True | 可进行半精度(FP16)计算,减少内存使用量,在提高速度的同时,将对精度的影响降至最低。 |
device | str | None | 指定验证设备 (cpu, cuda:0等)。可灵活利用 CPU 或 GPU 资源。 |
dnn | bool | False | 如果 True它使用 OpenCV DNN 模块进行ONNX 模型推断,为PyTorch 推断方法提供了一种替代方法。 |
plots | bool | False | 当设置为 True此外,它还能生成并保存预测结果与地面实况的对比图,以便对模型的性能进行可视化评估。 |
rect | bool | False | 如果 True该软件使用矩形推理进行批处理,减少了填充,可能会提高速度和效率。 |
split | str | val | 确定用于验证的数据集分割 (val, test或 train).可灵活选择数据段进行性能评估。 |
常用参数
batch 、 conf、 IoU、 half
Predict(预测)
demo
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
model = YOLO("yolov8n.pt")
# Run inference on 'bus.jpg' with arguments
result = model.predict("bus.jpg", save=True, imgsz=320, conf=0.5)
# Value of result
for result in results:
print("图像原始大小:", result.orig_shape)
data_numpy = result.boxes.data.cpu().numpy()
for data in data_numpy:
print("data", data)
print("左上角X轴坐标:", data[0])
print("左上角Y轴坐标:", data[1])
print("右下角X轴坐标:", data[2])
print("右下角Y轴坐标:", data[3])
print("置---信---度:", data[4])
print("检测到的类有:", data[5])参数
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
source | str | 'ultralytics/assets' | 指定推理的数据源。可以是图像路径、视频文件、目录、URL 或用于实时馈送的设备 ID。支持多种格式和来源,可灵活应用于不同类型的输入。 |
conf | float | 0.25 | 设置检测的最小置信度阈值。如果检测到的对象置信度低于此阈值,则将不予考虑。调整该值有助于减少误报。 |
iou | float | 0.7 | 非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。较低的数值可以消除重叠的方框,从而减少检测次数,这对减少重复检测非常有用。 |
imgsz | int or tuple | 640 | 定义用于推理的图像大小。可以是一个整数 640 或一个(高、宽)元组。适当调整大小可以提高检测精度和处理速度。 |
half | bool | False | 启用半精度(FP16)推理,可加快支持的 GPU 上的模型推理速度,同时将对精度的影响降至最低。 |
device | str | None | 指定用于推理的设备(例如:......)、 cpu, cuda:0 或 0).允许用户选择 CPU、特定 GPU 或其他计算设备来执行模型。 |
max_det | int | 300 | 每幅图像允许的最大检测次数。限制模型在单次推理中可检测到的物体总数,防止在密集场景中产生过多输出。 |
vid_stride | int | 1 | 视频输入的帧间距。允许跳过视频中的帧,以加快处理速度,但会牺牲时间分辨率。值为 1 时处理每一帧,值越大跳帧越多。 |
stream_buffer | bool | False | 确定在处理视频流时是否对所有帧进行缓冲 (True),或者模型是否应该返回最近的帧 (False).适用于实时应用。 |
visualize | bool | False | 在推理过程中激活模型特征的可视化,从而深入了解模型 "看到 "了什么。这对调试和模型解释非常有用。 |
augment | bool | False | 可对预测进行测试时间增强(TTA),从而在牺牲推理速度的情况下提高检测的鲁棒性。 |
agnostic_nms | bool | False | 启用与类别无关的非最大抑制 (NMS),可合并不同类别的重叠方框。这在多类检测场景中非常有用,因为在这种场景中,类的重叠很常见。 |
classes | list[int] | None | 根据一组类别 ID 过滤预测结果。只返回属于指定类别的检测结果。在多类检测任务中,该功能有助于集中检测相关对象。 |
retina_masks | bool | False | 如果模型中存在高分辨率的分割掩膜,则使用高分辨率的分割掩膜。这可以提高分割任务的掩膜质量,提供更精细的细节。 |
embed | list[int] | None | 指定从中提取特征向量或嵌入的层。这对聚类或相似性搜索等下游任务非常有用。 |
常用参数
conf、 IoU、 half、 imgsz、 device、 classes、
结果参数
| 属性 | 类型 | 说明 |
|---|---|---|
orig_img | numpy.ndarray | 原始图像的 numpy 数组。 |
orig_shape | tuple | 原始图像的形状,格式为(高、宽)。 |
boxes | Boxes, optional | 包含检测边界框的方框对象。 |
masks | Masks, optional | 包含检测掩码的掩码对象。 |
probs | Probs, optional | Probs 对象,包含分类任务中每个类别的概率。 |
keypoints | Keypoints, optional | 关键点对象,包含每个对象的检测关键点。 |
obb | OBB, optional | 包含定向包围盒的 OBB 对象。 |
speed | dict | 每幅图像的预处理、推理和后处理速度字典,单位为毫秒。 |
names | dict | 类名字典。 |
path | str | 图像文件的路径。 |
results支持方法
| 方法 | 返回类型 | 说明 |
|---|---|---|
update() | None | 更新结果对象的方框、掩码和 probs 属性。 |
cpu() | Results | 返回包含 CPU 内存中所有张量的结果对象副本。 |
numpy() | Results | 返回结果对象的副本,其中所有张量均为 numpy 数组。 |
cuda() | Results | 返回包含 GPU 内存中所有张量的 Results 对象副本。 |
to() | Results | 返回带有指定设备和 dtype 上张量的 Results 对象副本。 |
new() | Results | 返回一个具有相同图像、路径和名称的新结果对象。 |
plot() | numpy.ndarray | 绘制检测结果。返回注释图像的 numpy 数组。 |
show() | None | 在屏幕上显示带注释的结果。 |
save() | None | 将注释结果保存到文件中。 |
verbose() | str | 返回每个任务的日志字符串。 |
save_txt() | None | 将预测结果保存到 txt 文件中。 |
save_crop() | None | 将裁剪后的预测保存到 save_dir/cls/file_name.jpg. |
tojson() | str | 将对象转换为 JSON 格式。 |
Export(导出)
Ultralytics YOLOv8 中的导出模式为将训练好的模型导出为不同格式提供了多种选择,使其可以在各种平台和设备上部署
demo
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")参数
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
format | str | 'torchscript' | 导出模型的目标格式,例如 'onnx', 'torchscript', 'tensorflow'或其他,定义与各种部署环境的兼容性。 |
imgsz | int 或 tuple | 640 | 模型输入所需的图像尺寸。对于正方形图像,可以是一个整数,或者是一个元组 (height, width) 了解具体尺寸。 |
keras | bool | False | 启用导出为 Keras 格式的TensorFlow SavedModel ,提供与TensorFlow serving 和 API 的兼容性。 |
optimize | bool | False | 在导出到TorchScript 时,应用针对移动设备的优化,可能会减小模型大小并提高性能。 |
half | bool | False | 启用 FP16(半精度)量化,在支持的硬件上减小模型大小并可能加快推理速度。 |
int8 | bool | False | 激活 INT8 量化,进一步压缩模型并加快推理速度,同时将精度损失降至最低,主要用于边缘设备。 |
dynamic | bool | False | 允许ONNX 和TensorRT 导出动态输入尺寸,提高了处理不同图像尺寸的灵活性。 |
simplify | bool | False | 简化了ONNX 导出的模型图,可能会提高性能和兼容性。 |
opset | int | None | 指定ONNX opset 版本,以便与不同的ONNX 解析器和运行时兼容。如果未设置,则使用最新的支持版本。 |
workspace | float | 4.0 | 为TensorRT 优化设置最大工作区大小(GiB),以平衡内存使用和性能。 |
nms | bool | False | 在CoreML 导出中添加非最大值抑制 (NMS),这对精确高效的检测后处理至关重要。 |
batch | int | 1 | 指定导出模型的批量推理大小,或导出模型将同时处理的图像的最大数量。 predict 模式。 |
支持导出格式
| 格式 | format 论据 | 模型 | 元数据 | 论据 |
|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize, batch |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset, batch |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half, int8, batch |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, batch |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms, batch |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras, int8, batch |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz, batch |
| TF 轻型 | tflite | yolov8n.tflite | ✅ | imgsz, half, int8, batch |
| TF 边缘TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz, batch |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz, half, int8, batch |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz, batch |
| NCNN | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half, batch |
Yolo的模式类型
Detect(检测)
检测:包括检测图像或视频帧中的物体,并在其周围绘制边界框。YOLOv8 可在单幅图像或视频帧中高精度、高速度地检测多个物体

模型
| 模型 | 尺寸 (像素) | mAPval 50-95 | 速度 CPUONNX (ms) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
Segment(分割)
分割是一项根据图像内容将图像分割成不同区域的任务。每个区域根据其内容分配一个标签。这项任务在图像分割和医学成像等应用中非常有用。YOLOv8 使用 U-Net 架构的变体来执行分割

模型
| 模型 | 尺寸 (像素) | mAPbox 50-95 | mAPmask 50-95 | 速度 CPUONNX (ms) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
Classify(分类)
YOLOv8 可用于根据图像内容对图像进行分类。它使用 EfficientNet 架构的一种变体来执行分类。

模型
| 模型 | 尺寸 (像素) | acc top1 | acc top5 | 速度 CPUONNX (ms) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) at 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 76.8 | 93.5 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 154.8 |
Pose(姿态)
姿势/关键点检测是一项涉及检测图像或视频帧中特定点的任务。这些点被称为关键点,用于跟踪运动或姿势估计。YOLOv8 可以高精度、高速度地检测图像或视频帧中的关键点。

模型
| 模型 | 尺寸 (像素) | 50-95 | mAPpose 50 | 速度 CPUONNX (ms) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-姿势 | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-姿势 | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-姿势 | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-姿势 | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-姿势 | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
OBB(定向检测)
YOLOv8 可以高精度、高速度地检测图像或视频帧中的旋转物体。

模型
| 模型 | 尺寸 (像素) | mAPtest 50 | 速度 CPUONNX (ms) | 速度 A100 TensorRT (毫秒) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n-obb | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
| YOLOv8s-obb | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
| YOLOv8m-obb | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
| YOLOv8l-obb | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
| YOLOv8x-obb | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
个人经验
如何使用Yolov8
github官网找到项目地址:[https://github.com/ultralytics/ultralytics]
所需下载PyTorch环境版本地址:[Start Locally | PyTorch]
下载项目以后安装依赖:
pip install ultralytics pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (根据自己电脑配置决定)注:本人使用Python版本3.11
使用显卡启动Yolo所需配置:
cuda,cudnn
nvidia-smi 查看自己电脑支持的最高cuda版本,建议安装11.8比较稳定 然后安装对应支持的cuda,cudnn 参考:https://blog.csdn.net/jhsignal/article/details/111401628
验证是否支持、是否安装成功
import torch print(torch.cuda.is_available()) x = torch.rand(5, 5).cuda() print(x)
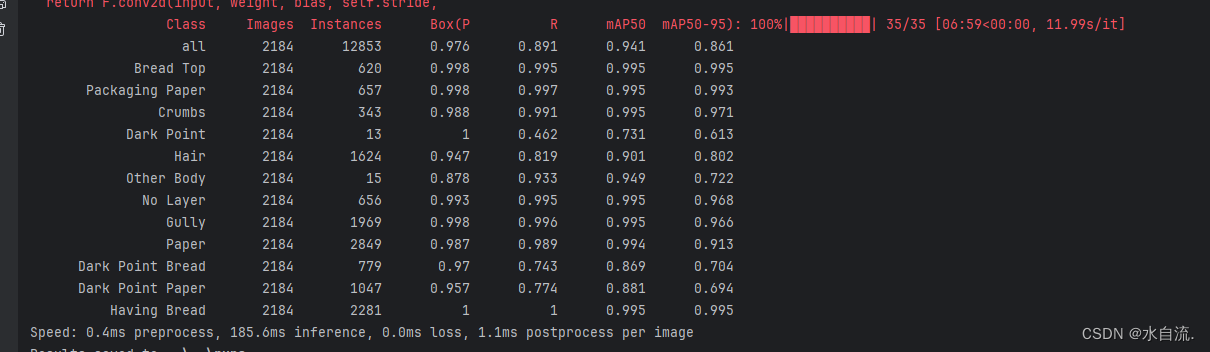
训练结果参数理解
Class:类别
Image:图片数量
Instances:类别数量
Box(P):边界框的精度(Precision),反映了模型预测的边界框中正确预测的比例。高精度表示模型产生的假阳性(False Positives)较少。其中,真阳性是正确预测的目标数,假阳性是错误标记的目标数。 计算方法(不懂):
R - Recall:R 即召回率(Recall),衡量了模型捕获真实目标的能力。高召回率表示模型能够检测到大多数真实目标,但可能包括一些错误的检测。
mAP50(mean Average Precision):mAP50 指的是在 IoU(交并比)阈值为0.50时的平均精度(Mean Average Precision)。这是一个常用的指标,因为它只考虑较为宽松的匹配标准。它测量的是当预测的边界框与真实边界框的交并比至少为0.50时的平均精度。
mAP50-95:mAP50-95 是一个更全面的性能指标,它计算了从 IoU=0.50 到 IoU=0.95(每隔0.05一个阶梯)的平均精度。这是评估模型整体性能的一个更严格的标准,因为它考虑了更多的匹配严格程度。
训练参数IoU(预测使用的):假设你有两个边界框,一个是预测边界框(Predicted Box),另一个是真实边界框(Ground Truth Box):
交集(Intersection):预测边界框和真实边界框重叠区域的面积。 并集(Union):预测边界框和真实边界框覆盖的总面积,但重叠区域只计算一次。 IoU 的值范围从0到1:IoU = 0 表示没有重叠。IoU = 1 表示完全重叠。
2024-05-30
训练自己的数据集
Yolo目录结构
ultralytics/
├── datasets/
│ └──myselfData
│ │── images│ │ └── *.jpg
│ │── labels│ │ └── *.txt
│ └── myselfData.yaml
│
├── ultralytics/
│ ├── assets/
│ ├── cfg/
│ ├── data/
│ ├── demo/
│ ├── engine/
│ ├── hub/
│ ├── models/
│ ├── nn/
│ ├── solutions/
│ ├── trackers/
│ ├── utils/
│ ├── xxx.py
│ │
└── readMe.md新建一个datasets文件夹存放数据集
yaml文件夹内容如下:
path: D:\PythonProject\ultralytics\datasets\myselfData # dataset中的文件夹路径 train: images/train2017 # train images 训练的图片路径 val: images/train2017 # val images 验证的图片路径 test: images/train2017 # test images 测试的图片路径 # Classes names: 0: Bread 1: Paper 2: People启动训练函数
from ultralytics import YOLO def train(): # 确保配置文件是正确的,通常是与预训练模型相同的配置文件 model = YOLO('yolov8m.yaml').load('yolov8n.pt') # 开始训练模型 results = model.train(data='datasets/myselfData/myselfData.yaml', epochs=300, batch=16, device=0, workers=8, imgsz=640) return results if __name__ == '__main__': results = train()预测函数
import os import cv2 import numpy as np from ultralytics import YOLO model = YOLO('../yolopt/best.pt') folder_path = "D:/PythonProject/xxx" #可以使用绝对路径/相对路径,文件夹图片都可以放 results = model.predict(folder_path, save=True, imgsz=320, conf=0.5, device='0', half=True) for result in results: data_numpy = result.boxes.data.cpu().numpy() for data in data_numpy: print("左上角X轴坐标:", data[0]) print("左上角Y轴坐标:", data[1]) print("右下角X轴坐标:", data[2]) print("右下角Y轴坐标:", data[3]) print("置---信---度:", data[4]) print("检测到的类有:", [int(data[5])])验证函数
from ultralytics import YOLO def val(): model = YOLO("../bestX.pt") validation_results = model.val(data="datasets/myselfData/myselfData.yaml", imgsz=640, batch=64, conf=0.5, iou=0.6, device="0") if __name__ == '__main__': val()模型转换(Pt转Onnx)
import cv2 import torch from tensor_rt.main import YOLOv8 from ultralytics import YOLO # # Pt转换Onnx模型 device = "cuda:0" if torch.cuda.is_available() else "cpu" onnx_model = YOLO("DarkPointX.onnx") results = onnx_model("202404201048220.jpg") print(results)模型(Pt转Engine)
from ultralytics import YOLO import torch # 检查GPU是否可用,并设置为默认设备 device = 'cuda' if torch.cuda.is_available() else 'cpu' print(f"Using device: {device}") # 载入模型并转移到设备 model = YOLO("DarkPointX.pt").to(device) model.export( format="engine", dynamic=True, batch=32, workspace=4, half=True, data="bread.yaml", ) print("Done") # results = self.model.predict(image, save=False, imgsz=640, conf=self.conf, device='0', half=True) # Load the exported TensorRT INT8 model model = YOLO("DarkPointX.engine") # Run inference result = model.predict("https://ultralytics.com/images/bus.jpg")















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









