










1. 概述
Ultralytics YOLOv8 是一种前沿、最先进 (SOTA) 的模型,它在之前的 YOLO 版本的成功基础上引入了新功能和改进,以提高性能和灵活性。YOLOv8 旨在快速、准确、易于使用,是广泛应用于目标检测和跟踪、实例分割、图像分类和姿态估计等任务的优秀选择。
与之前的 YOLOv5 不同的是,YOLOv8 是在一个名为 Ultralytics 项目下,该项目将该团队之前制作的 YOLOv3、YOLOv5 整合到了一起,并添加了 YOLOv8。初次之外,Ultralytics 更是整合了 YOLOv6、YOLOv9、YOLOv8-World、百度的 RT-DETR。
ultralytics/cfg/models
|-- README.md
|-- rt-detr
| |-- rtdetr-l.yaml # 百度的 RT-DETR 目标检测模型(L 规格),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
| |-- rtdetr-x.yaml # 百度的 RT-DETR 目标检测模型(X 规格),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
| |-- rtdetr-resnet101.yaml # Backbone 使用 ResNet101 的 RE-DETR 目标检测模型,使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
| `-- rtdetr-resnet50.yaml # Backbone 使用 ResNet50 的 RE-DETR 目标检测模型,使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
|-- v3
| |-- yolov3.yaml # YOLOv3 目标检测模型,使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
| |-- yolov3-tiny.yaml # YOLOv3 目标检测模型(Tiny 规格),使用的后处理模块为 Detect,💡 使用的预测特征图为 P4, P5,从原来擅长“小中大”目标变为“中大”目标
| `-- yolov3-spp.yaml # 加入 SPP 的 YOLOv3 目标检测模型,使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
|-- v5
| |-- yolov5.yaml # YOLOv5 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
| `-- yolov5-p6.yaml # YOLOv5-p6 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,💡 使用的预测特征图为 P3, P4, P5, P6,加强对大目标的检测能力
|-- v6
| `-- yolov6.yaml # YOLOv6 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
|-- v8
| |-- yolov8.yaml # YOLOv8 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
| |-- yolov8-p2.yaml # YOLOv8 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的预测特征图为 P2, P3, P4, P5,增加对小目标的检测能力
| |-- yolov8-p6.yaml # YOLOv8 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5, P6,增加对大目标的检测能力
| |-- yolov8-ghost.yaml # YOLOv8 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的卷积是 GhostConv 和 C3Ghost,使用的预测特征图为 P3, P4, P5
| |-- yolov8-ghost-p2.yaml # YOLOv8 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的卷积是 GhostConv 和 C3Ghost,使用的预测特征图为 P2, P3, P4, P5,增加了对小目标的检测能力
| |-- yolov8-ghost-p6.yaml # YOLOv8 目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Detect,使用的卷积是 GhostConv 和 C3Ghost,使用的预测特征图为 P3, P4, P5, P6,增加了对大目标的检测能力
| |-- yolov8-cls.yaml # YOLOv8 分类模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Classify
| |-- yolov8-cls-resnet50.yaml # YOLOv8 分类模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Classify,使用的 Backbone 为 ResNet50
| |-- yolov8-cls-resnet101.yaml # YOLOv8 分类模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Classify,使用的 Backbone 为 ResNet101
| |-- yolov8-seg.yaml # YOLOv8 分割模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Segment,使用的预测特征图为 P3, P4, P5
| |-- yolov8-seg-p6.yaml # YOLOv8 分割模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Segment,使用的预测特征图为 P3, P4, P5, P6,增加对大目标的分割能力
| |-- yolov8-obb.yaml # YOLOv8 旋转目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 OBB,使用的预测特征图为 P3, P4, P5
| |-- yolov8-pose.yaml # YOLOv8 关键点/人体姿态估计模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Pose,使用的预测特征图为 P3, P4, P5
| |-- yolov8-pose-p6.yaml # YOLOv8 关键点/人体姿态估计模型(可选规格有:n、s、m、l、x),使用的后处理模块为 Pose,使用的预测特征图为 P3, P4, P5, P6,增加对大目标的估计能力
| |-- yolov8-rtdetr.yaml # YOLOv8 加上 RT-DETR 的目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 RTDETRDecoder,使用的预测特征图为 P3, P4, P5
| |-- yolov8-world.yaml # YOLOv8 加上 YOLO-World 的目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 WorldDetect,head 部分与 YOLOv8 差异较大,使用的预测特征图为 P3, P4, P5,❌ 不支持导出为 ONNX,mAP 低于 YOLOv8-Worldv2
| `-- yolov8-worldv2.yaml # 🌟 YOLOv8 加上 YOLO-World 的目标检测模型(可选规格有:n、s、m、l、x),使用的后处理模块为 WorldDetect,head 部分与 YOLOv8 差异较大,与 YOLOv8-World 也有一些区别,使用的预测特征图为 P3, P4, P5,✅ 支持导出为 ONNX,mAP 高于 YOLOv8-World
`-- v9
|-- yolov9c.yaml # YOLOv6 目标检测模型(规格为 C,t->s->m->c->e),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
`-- yolov9e.yaml # YOLOv6 目标检测模型(规格为 E,t->s->m->c->e),使用的后处理模块为 Detect,使用的预测特征图为 P3, P4, P5
|-- yolov9c-seg.yaml # YOLOv6 分割模型(规格为 C,t->s->m->c->e),使用的后处理模块为 Segment,使用的预测特征图为 P3, P4, P5
`-- yolov9e-seg.yaml # YOLOv6 分割模型(规格为 E,t->s->m->c->e),使用的后处理模块为 Segment,使用的预测特征图为 P3, P4, P5
2. 安装
我们有两种方式使用 Ultralytics 这个项目:
- 方法 1:我们就是用来训练模型,不修改具体的代码。
- 方法 2:我们会修改代码。
这里我推荐大家使用第 2 种方法,适用方法更加广泛。
2.1 第一种方法
我们就使用内置的代码来训练、预测、评估模型,不会对模型进行修改,那么我们就可以直接通过安装 ultralytics 这个库,那么这样会导致项目中名为 ultralytics 的库不会生效了。
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
通过这种方式安装 ultralytics 库之后,原本项目中名为 ultralytics 的文件夹就不会生效了。所以当我们修改代码后并不会生效,因为我们用的就不是项目中的 ultralytics 文件夹。
2.2 🌟 第二种方法
这里推荐使用第二种方式,我们直接项目中的 ultralytics 这个文件夹当做一个包。安装命令为:
# 将本地项目安装为库,其中 -v 表示 verbose,-e 表示可编辑的
pip install -v -e .
运行完上面的命令后,我们使用 pip list 查看已安装的库:

可以发现 ultralytics 这个库已经安装完毕了,并且后面有一个地址,这个地址其实就是我们的项目的本地地址。意思就是说,上面的命令将我们本地的项目封装为一个 Python 的库,所以我们修改本地的代码,也是可以生效的。
3. 快速上手
3.1 方法 1
在我们安装好 ultralytics 库并下载 ultralytics 项目后,可以直接使用命令行(Command Line Interface, CLI)进行快速推理一张图片、视频、视频流、摄像头等等,举个例子:
yolo 任务名称 model=本地模型权重路径 source=图片路径
示例:
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
(wsl) leovin@DESKTOP-XXXX:/mnt/f/Projects/项目/本地代码/Learning-Notebook-Codes/ObjectDetection/YOLOv8/code$ yolo predict model=pretrained_weights/yolov8n.p
t source='https://ultralytics.com/images/bus.jpg'
Ultralytics YOLOv8.2.4 🚀 Python-3.8.18 torch-2.1.0+cpu CPU (Intel Core(TM) i7-7700 3.60GHz)
YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs
Downloading https://ultralytics.com/images/bus.jpg to 'bus.jpg'...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 476k/476k [00:02<00:00, 164kB/s]
image 1/1 /mnt/f/Projects/项目/本地代码/Learning-Notebook-Codes/ObjectDetection/YOLOv8/code/bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 249.3ms
Speed: 63.1ms preprocess, 249.3ms inference, 1250.6ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/detect/predict
💡 Learn more at https://docs.ultralytics.com/modes/predict
3.2 🌟 方法 2
除了使用 CLI 来进行推理外,我们也可以写一个 Python 脚本来进行相同的操作:
3.2.1 模型训练
# 导入必要的库
from ultralytics import YOLO
# ---------- 加载模型 ----------
# 方法 1:通过 yaml 文件新建一个模型 (根据 yaml 文件中的模型定义自动搭建一个模型)
model = YOLO('yolov8n.yaml')
# 方法 2:加载一个训练好的模型(直接从 pt 文件中读取模型架构从而搭建模型)
model = YOLO('yolov8n.pt')
# ---------- 模型训练 ----------
# 训练 coco128.yaml 中定义的数据集,并且 epochs 为 3
model.train(
data='coco128.yaml',
epochs=3
)
这里推荐使用这种创建一个 Python 脚本进行的方式,方便后续的代码复用。
训练过程展示:
(leovin) root@XXXX:/project/leovin/ultralytics# python quick_start/detect/train.py
New https://pypi.org/project/ultralytics/8.2.4 available 😃 Update with 'pip install -U ultralytics'
Ultralytics YOLOv8.1.47 🚀 Python-3.8.18 torch-1.10.1 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11020MiB)
WARNING ⚠️ Upgrade to torch>=2.0.0 for deterministic training.
engine/trainer: task=detect, mode=train, model=yolov8n.pt, data=coco128.yaml, epochs=3, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train3, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs/detect/train3
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
16 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
19 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 1 493056 ultralytics.nn.modules.block.C2f [384, 256, 1]
22 [15, 18, 21] 1 897664 ultralytics.nn.modules.head.Detect [80, [64, 128, 256]]
Model summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
Transferred 355/355 items from pretrained weights
TensorBoard: Start with 'tensorboard --logdir runs/detect/train3', view at http://localhost:6006/
Freezing layer 'model.22.dfl.conv.weight'
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
train: Scanning /project/leovin/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 [00:00<?,
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
val: Scanning /project/leovin/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 [00:00<?, ?
Plotting labels to runs/detect/train3/labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.000119, momentum=0.9) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias(decay=0.0)
TensorBoard: model graph visualization added ✅
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs/detect/train3
Starting training for 3 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/3 2.64G 1.206 1.496 1.27 199 640: 100%|██████████| 8/8 [00:01<00:00, 4.03it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 7.02it/s]
all 128 929 0.653 0.539 0.615 0.456
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/3 2.65G 1.204 1.514 1.281 163 640: 100%|██████████| 8/8 [00:01<00:00, 6.17it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 6.46it/s]
all 128 929 0.668 0.536 0.625 0.462
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/3 2.82G 1.247 1.45 1.271 197 640: 100%|██████████| 8/8 [00:01<00:00, 7.06it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:00<00:00, 7.14it/s]
all 128 929 0.654 0.552 0.633 0.467
3 epochs completed in 0.003 hours.
Optimizer stripped from runs/detect/train3/weights/last.pt, 6.5MB
Optimizer stripped from runs/detect/train3/weights/best.pt, 6.5MB
Validating runs/detect/train3/weights/best.pt...
Ultralytics YOLOv8.1.47 🚀 Python-3.8.18 torch-1.10.1 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11020MiB)
Model summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:03<00:00, 1.25it/s]
all 128 929 0.666 0.542 0.633 0.468
person 128 254 0.808 0.664 0.768 0.544
bicycle 128 6 0.5 0.333 0.33 0.27
car 128 46 0.771 0.217 0.285 0.176
motorcycle 128 5 0.684 0.871 0.881 0.708
airplane 128 6 0.681 0.667 0.913 0.708
bus 128 7 0.748 0.714 0.73 0.671
train 128 3 0.545 0.667 0.806 0.677
...
...
Speed: 1.6ms preprocess, 1.1ms inference, 0.0ms loss, 5.8ms postprocess per image
Results saved to runs/detect/train3
3.2.2 模型评估(验证)
当我们训练得到一个 .pt 文件后,可能需要对其进行评估以获取该 .pt 的指标,代码如下:
from ultralytics import YOLO
# ---------- 加载模型 ----------
model = YOLO('runs/detect/train3/weights/best.pt')
# ---------- 模型评估 ----------
model.val(data='coco128.yaml')
模型评估过程如下:
(leovin) root@XXXX:/project/leovin/ultralytics# python quick_start/detect/eval.py
Ultralytics YOLOv8.1.47 🚀 Python-3.8.18 torch-1.10.1 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11020MiB)
Model summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs
val: Scanning /project/leovin/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 [00:00<?, ?
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 8/8 [00:05<00:00, 1.57it/s]
all 128 929 0.625 0.565 0.628 0.463
person 128 254 0.774 0.681 0.768 0.545
bicycle 128 6 0.468 0.333 0.324 0.269
car 128 46 0.6 0.217 0.285 0.176
motorcycle 128 5 0.697 0.927 0.881 0.708
...
...
Speed: 1.5ms preprocess, 9.6ms inference, 0.0ms loss, 3.0ms postprocess per image
Results saved to runs/detect/val
3.2.3 模型预测
from ultralytics import YOLO
# ---------- 加载模型 ----------
model = YOLO('runs/detect/train3/weights/best.pt')
# ---------- 模型评估 ----------
model.predict(
source='https://ultralytics.com/images/bus.jpg',
save=True
)
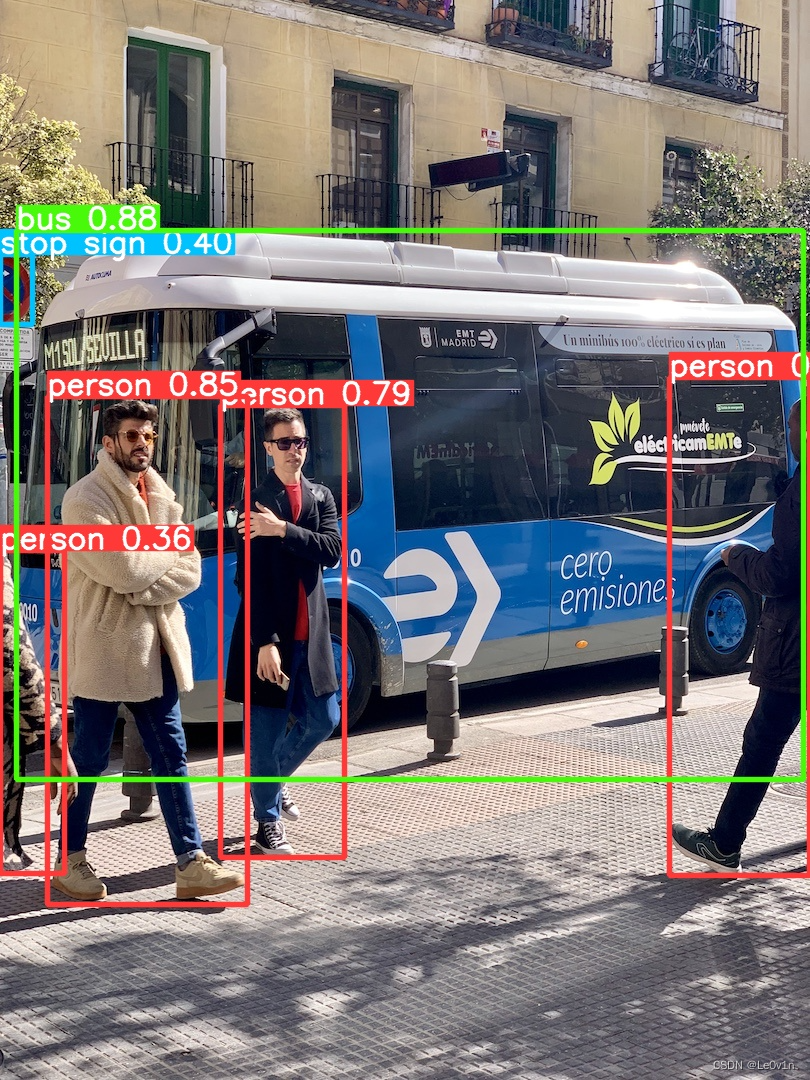
(leovin) root@XXXX:/project/leovin/ultralytics# python quick_start/detect/predict.py
Found https://ultralytics.com/images/bus.jpg locally at bus.jpg
image 1/1 /project/leovin/ultralytics/bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 27.8ms
Speed: 6.8ms preprocess, 27.8ms inference, 96.9ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs/detect/predict
3.2.4 模型导出
from ultralytics import YOLO
# ---------- 加载模型 ----------
model = YOLO('runs/detect/train3/weights/best.pt')
# ---------- 模型导出 ----------
model.export(format='onnx', simplify=True)
(leovin) root@XXXX:/project/leovin/ultralytics# python quick_start/detect/export.py
Ultralytics YOLOv8.1.18 🚀 Python-3.8.18 torch-1.10.1 CPU (Intel Xeon Silver 4216 2.10GHz)
Model summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs
PyTorch: starting from 'runs/detect/train3/weights/best.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 84, 8400) (6.2 MB)
ONNX: starting export with onnx 1.15.0 opset 13...
ONNX: export success ✅ 2.4s, saved as 'runs/detect/train3/weights/best.onnx' (12.2 MB)
Export complete (4.1s)
Results saved to /project/leovin/ultralytics/runs/detect/train3/weights
Predict: yolo predict task=detect model=runs/detect/train3/weights/best.onnx imgsz=640
Validate: yolo val task=detect model=runs/detect/train3/weights/best.onnx imgsz=640 data=/root/anaconda3/envs/leovin/lib/python3.8/site-packages/ultralytics/cfg/datasets/coco128.yaml
Visualize: https://netron.app

4. YOLOv8 支持的任务
前面我们说过,YOLOv8 的团队(Ultralytics)不光提供了目标检测的模型,还基于 YOLOv8 开发了其他模型,下面我们对其进行简单的介绍。为了增加模型的适用范围,官方提供了不同规格的模型,其含义分别如下:
| 规格 | 含义 | 示例 |
|---|---|---|
| YOLOv8 Nano | 非常小 | YOLOv8n |
| YOLOv8 Small | 小 | YOLOv8s |
| YOLOv8 Medium | 中 | YOLOv8m |
| YOLOv8 Large | 大 | YOLOv8l |
| YOLOv8 X(Extra Large) | 非常大 | YOLOv8x |
4.1 目标检测模型
4.1.1 模型概况
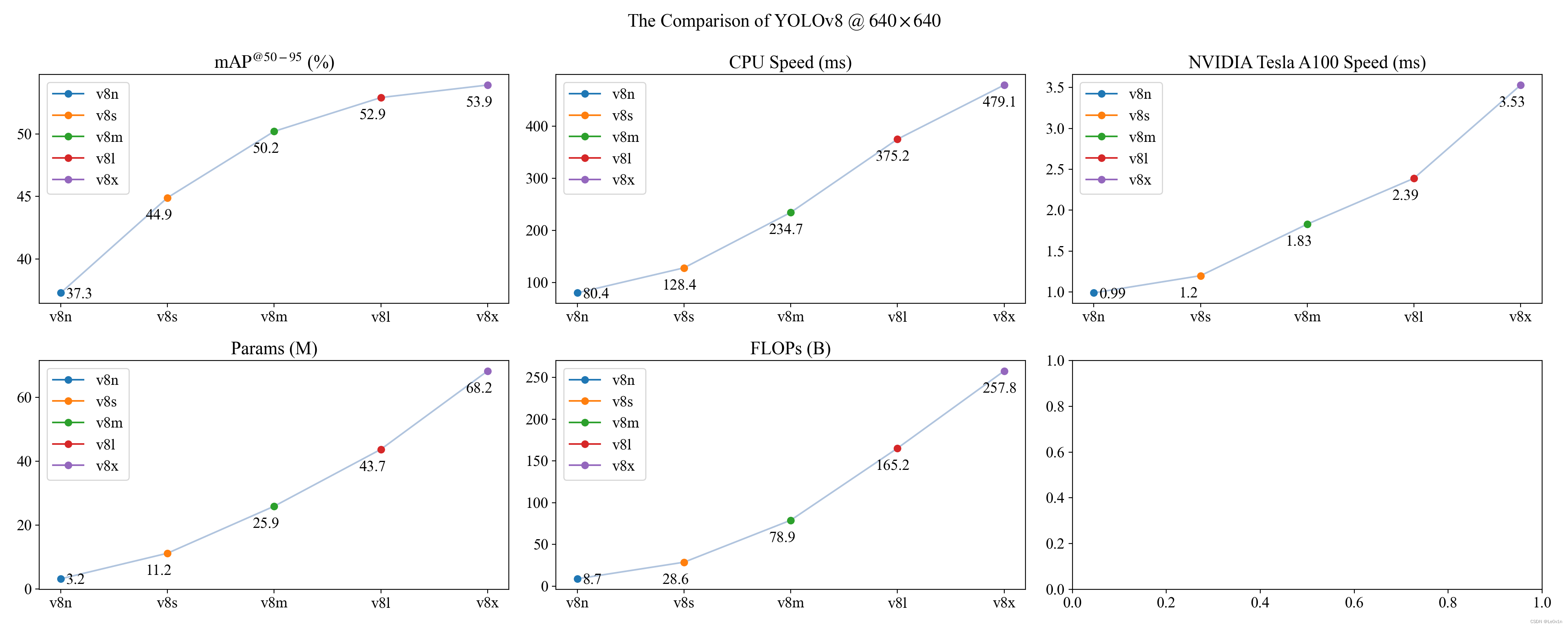
| 模型名称 | 输入图片大小 | mAP@50-95 | CPU@ONNX Speed (ms) | A100@TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
其中,mAP@50-95 指的是:设置的 IoU 阈值为 IoU = np.arange(0.50, 1.00, 0.05) 共 10 个 IoU 的 mAP 的均值:
mAP@0.50-0.95 = 0.1 * (mAP@0.50 + mAP@0.55 + mAP@0.60 + mAP@0.65 + mAP@0.70 + mAP@0.75 + mAP@0.80 + mAP@0.85 + mAP@0.90 + mAP@0.95)
4.1.2 训练情况

4.1.3 模型推理
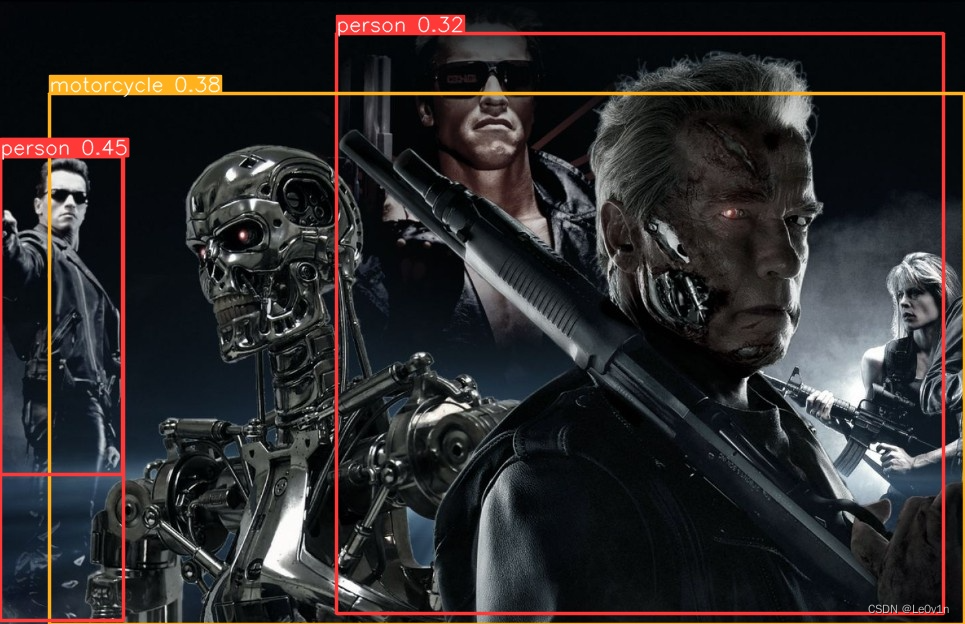
image 1/1 /data/data_01/XXXX/ultralytics-20240416/quick_start/images/detect_and_pose.jpg: 416x640 3 persons, 1 motorcycle, 19.0ms
Speed: 6.0ms preprocess, 19.0ms inference, 1.8ms postprocess per image at shape (1, 3, 416, 640)
Results saved to runs/detect/predict2
4.2 分割模型
4.2.1 任务介绍
实例分割模型的输出是一组 Mask,用于勾勒图像中的每个物体,同时还包括每个物体的类别标签和置信度分数。实例分割在我们需要知道物体在图像中的位置以及它们的确切形状时非常有用。

4.2.2 模型概况
| 模型名称 | 输入图片大小 | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
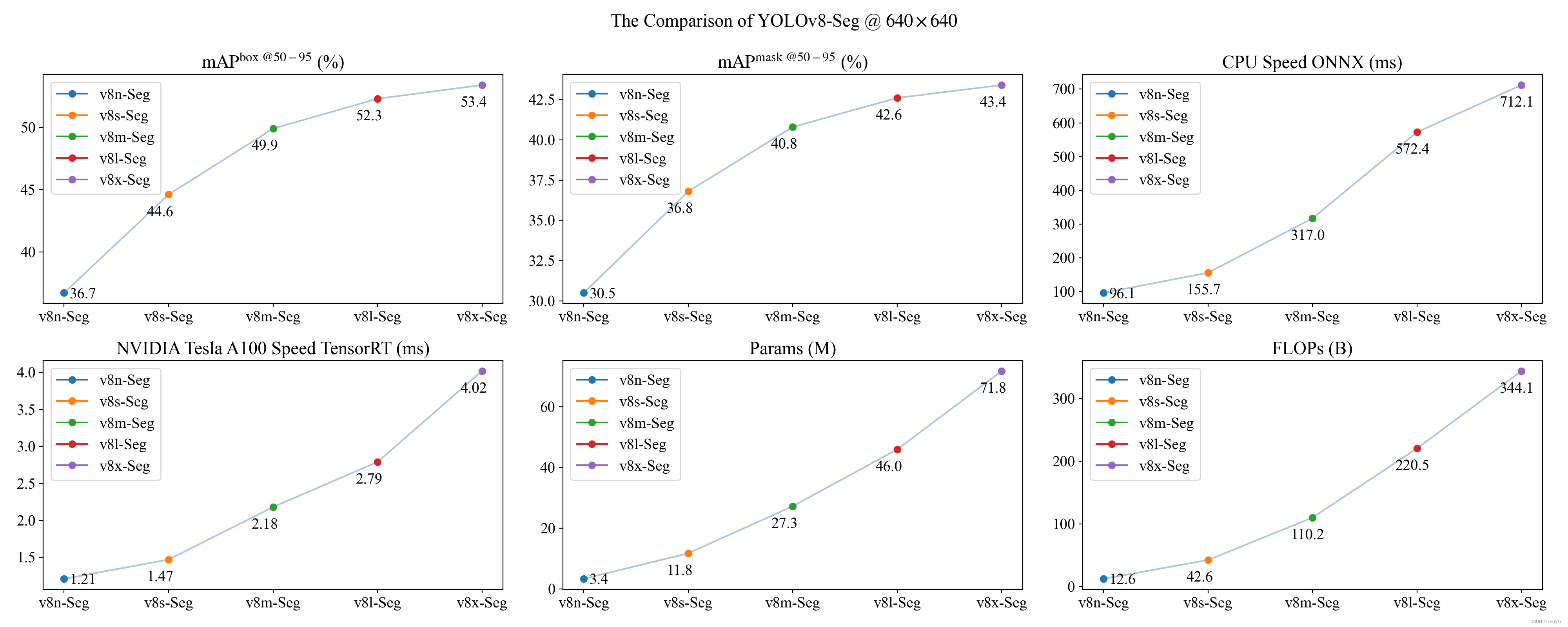
💡 需要注意的是,这里的指标仍然是目标检测中使用的 mAP 而非 mIoU。很多人在 Issue 中提出了添加 mIoU,但官方表示不会加入 🤣
4.2.3 训练情况
from ultralytics import YOLO
# ---------- 加载模型 ----------
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
# ---------- 训练模型 ----------
results = model.train(data='coco128-seg.yaml', epochs=20, imgsz=640)

Validating runs/segment/train2/weights/best.pt...
Ultralytics YOLOv8.1.18 🚀 Python-3.8.18 torch-1.10.1 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11020MiB)
YOLOv8n-seg summary (fused): 195 layers, 3404320 parameters, 0 gradients, 12.6 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:03<00:00
all 128 929 0.696 0.656 0.7 0.537 0.705 0.623 0.659 0.422
person 128 254 0.809 0.654 0.754 0.541 0.814 0.602 0.72 0.392
bicycle 128 6 0.614 0.333 0.404 0.28 0.664 0.333 0.352 0.242
car 128 46 0.632 0.196 0.291 0.16 0.679 0.184 0.277 0.126
motorcycle 128 5 0.854 1 0.995 0.876 0.871 1 0.995 0.672
airplane 128 6 0.912 1 0.995 0.902 0.925 1 0.995 0.616
...
...
Speed: 1.2ms preprocess, 1.3ms inference, 0.0ms loss, 1.0ms postprocess per image
Results saved to runs/segment/train2
4.2.4 模型导出
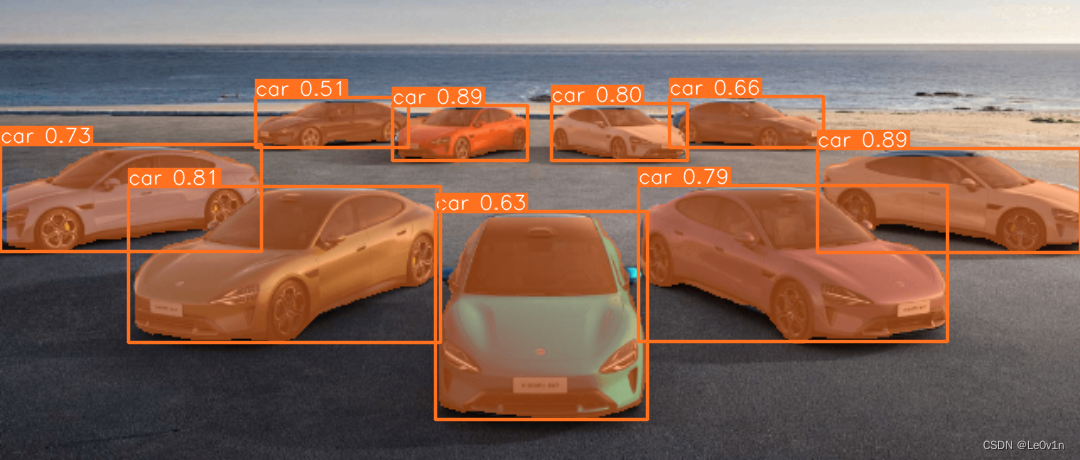
4.2.5 模型推理
image 1/1 /data/data_01/XXXX/ultralytics-20240416/quick_start/images/segment.png: 288x640 9 cars, 28.2ms
Speed: 4.7ms preprocess, 28.2ms inference, 3.7ms postprocess per image at shape (1, 3, 288, 640)
Results saved to runs/segment/predict3
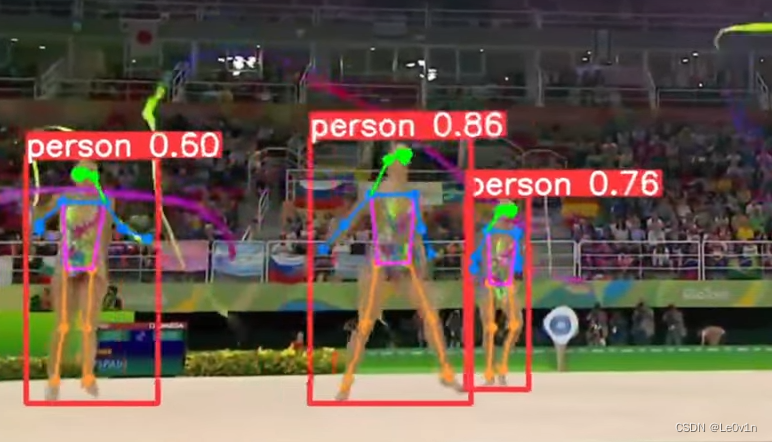
4.3 姿态估计
4.3.1 任务介绍
姿态估计是一项任务,涉及在图像中确定特定点的位置,通常称为关键点。关键点可以表示对象的各个部分,如关节、标志性或其他独特的特征。关键点的位置通常表示为一组 2D [x,y] 或 3D [x,y,visible] 坐标。姿态估计模型的输出是一组代表图像中对象上关键点的点,通常还包括每个点的置信度分数。当我们需要识别场景中对象的特定部分以及它们相对位置时,姿态估计是一个很好的选择。
4.3.2 模型概况
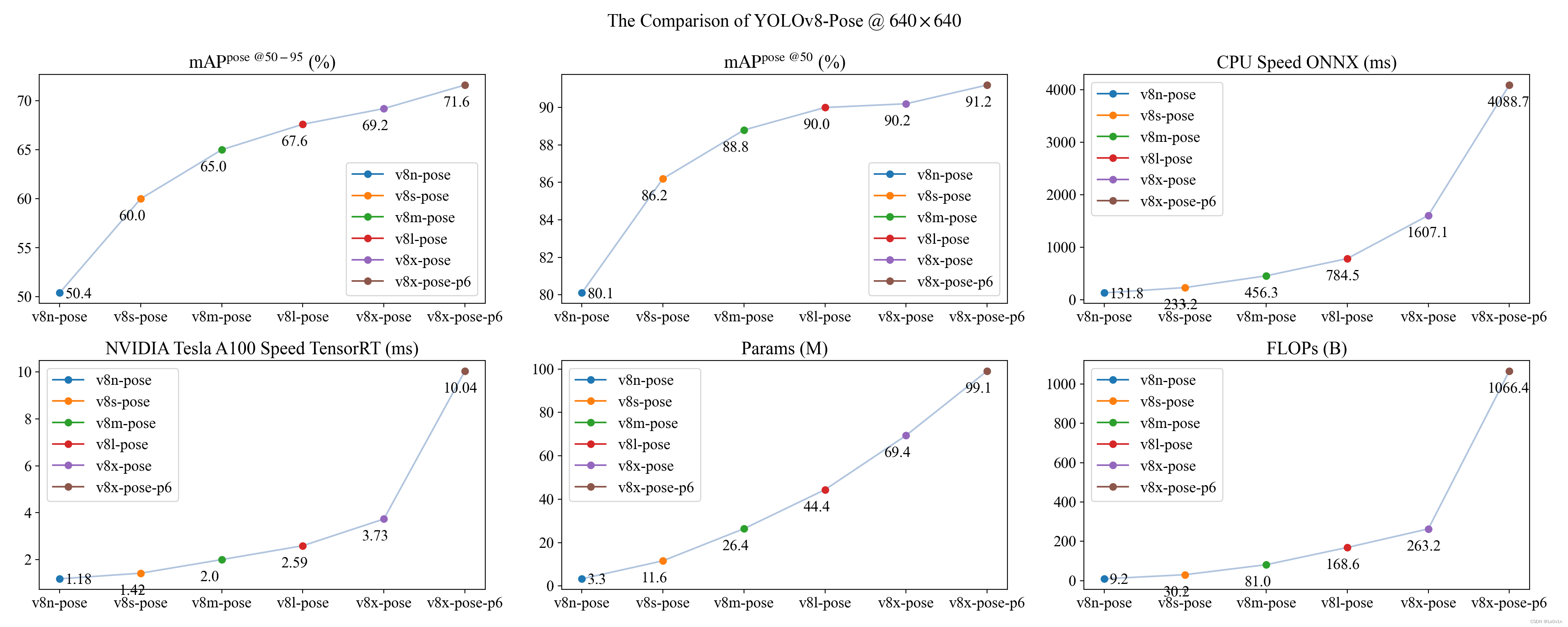
下面是基于 YOLOv8 的姿态估计模型:
| 模型名称 | 输入图片大小 | mAPpose 50-95 | mAPpose 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
4.3.3 训练情况
from ultralytics import YOLO
# ---------- 加载模型 ----------
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
# ---------- 训练模型 ----------
results = model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)

Validating runs/pose/train2/weights/best.pt...
Ultralytics YOLOv8.1.18 🚀 Python-3.8.18 torch-1.10.1 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11020MiB)
YOLOv8n-pose summary (fused): 187 layers, 3289964 parameters, 0 gradients, 9.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00
all 4 14 0.912 0.929 0.955 0.727 1 0.625 0.652 0.333
Speed: 0.2ms preprocess, 5.3ms inference, 0.0ms loss, 0.6ms postprocess per image
Results saved to runs/pose/train2
4.3.4 模型导出
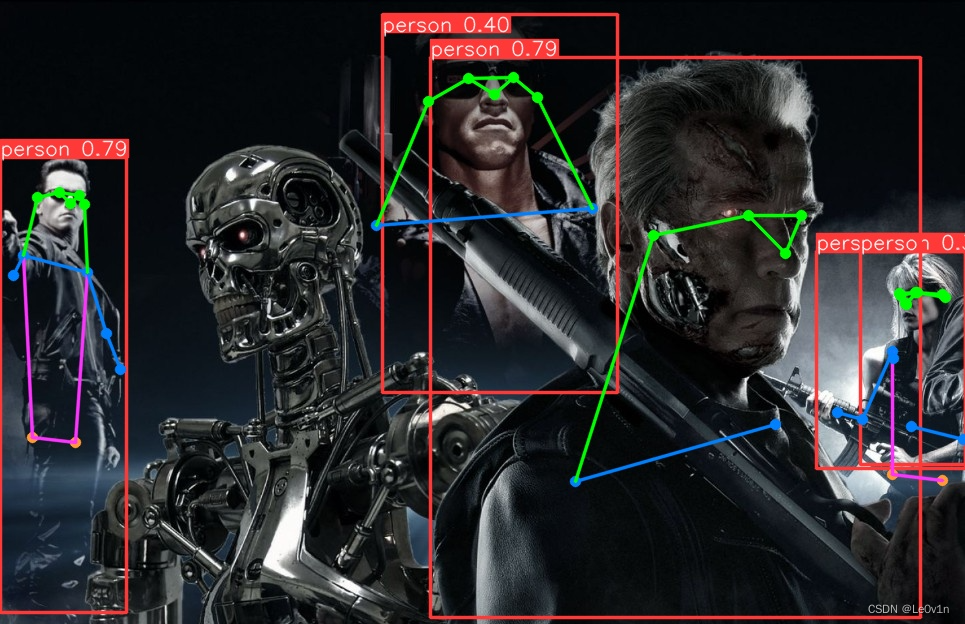
4.3.5 模型推理
image 1/1 /data/data_01/XXXX/ultralytics-20240416/quick_start/images/detect_and_pose.jpg: 416x640 5 persons, 23.3ms
Speed: 5.2ms preprocess, 23.3ms inference, 2.7ms postprocess per image at shape (1, 3, 416, 640)
Results saved to runs/pose/predict
4.4 旋转目标检测(Oriented Bounding Boxes Object Detection)
4.4.1 任务介绍
旋转目标检测进一步超越了物体检测,引入了额外的角度信息,以更准确地在图像中定位物体。旋转目标检测器的输出是一组旋转的边界框,准确地包围图像中的物体,同时还包括每个框的类别标签和置信度分数。当我们需要在场景中识别感兴趣的物体,并且需要知道物体的精确位置和形状时,旋转目标检测是一个很好的选择。

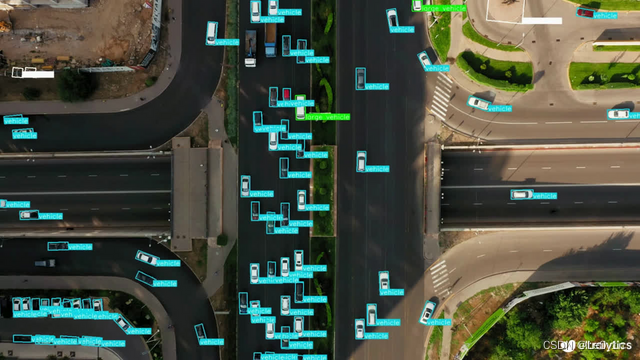
DOTA 数据集 v1.0 是一个专为航拍图像中目标检测任务设计的大规模数据集。这个数据集是目前最大的光学遥感图像数据集之一。DOTA 数据集 v1.0 共收录了 2806 张图像,每张图像的大小约为 4000×4000 像素,总共包含 188282 个目标实例。这些目标实例涵盖了各种不同的比例、方向和形状,使得数据集具有极高的真实性和挑战性。为了准确标注这些目标,数据集采用了旋转框的标记方式,即标注出每个目标的四个顶点,从而得到不规则四边形的边界框。这种标注方式相比传统的水平标注方法更为精确,能够减少大量的重叠区域。
4.4.2 模型概况
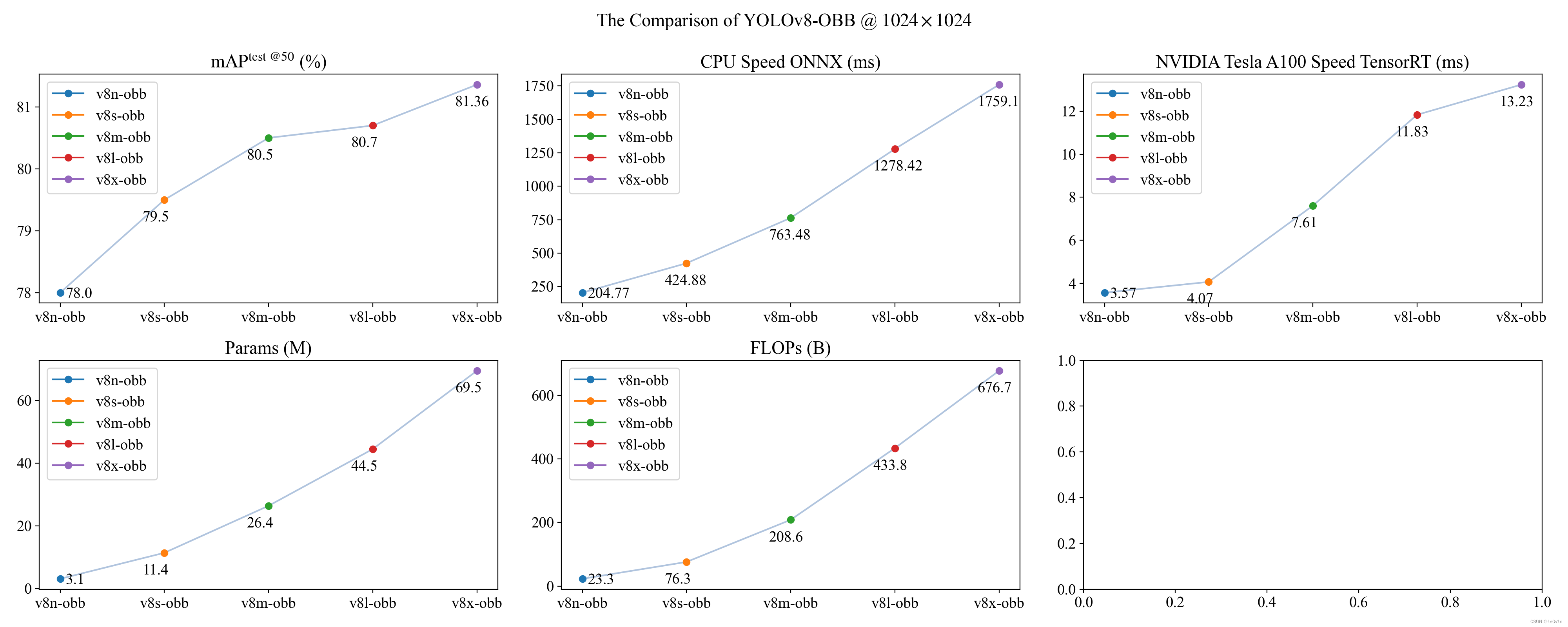
| 模型名称 | size (pixels) | mAPtest 50 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n-obb | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
| YOLOv8s-obb | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
| YOLOv8m-obb | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
| YOLOv8l-obb | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
| YOLOv8x-obb | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
4.4.3 训练情况
from ultralytics import YOLO
# ---------- 加载模型 ----------
model = YOLO('yolov8n-obb.pt') # load a pretrained model (recommended for training)
# ---------- 训练模型 ----------
results = model.train(data='dota8.yaml', epochs=100, imgsz=640)
Validating runs/obb/train/weights/best.pt...
Ultralytics YOLOv8.1.18 🚀 Python-3.8.18 torch-1.10.1 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11020MiB)
YOLOv8n-obb summary (fused): 187 layers, 3080144 parameters, 0 gradients, 8.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<00:00, 14.78it/s]
all 4 8 0.718 1 0.978 0.816
baseball diamond 4 4 0.561 1 0.945 0.794
basketball court 4 3 0.781 1 0.995 0.857
soccer ball field 4 1 0.811 1 0.995 0.796
Speed: 0.2ms preprocess, 5.5ms inference, 0.0ms loss, 2.1ms postprocess per image
Results saved to runs/obb/train
# Classes for DOTA 1.0
names:
0: plane
1: ship
2: storage tank
3: baseball diamond
4: tennis court
5: basketball court
6: ground track field
7: harbor
8: bridge
9: large vehicle
10: small vehicle
11: helicopter
12: roundabout
13: soccer ball field
14: swimming pool

4.4.4 模型导出
4.4.5 模型推理
image 1/1 /data/data_01/XXXX/ultralytics-20240416/quick_start/images/obb.webp: 448x640 26.0ms
Speed: 6.4ms preprocess, 26.0ms inference, 4.4ms postprocess per image at shape (1, 3, 448, 640)
Results saved to runs/obb/predict2

4.5 分类
4.5.1 任务介绍
图像分类是这三个任务中最简单的任务之一,它涉及将整个图像分类为预定义类别之一。图像分类器的输出是一个单一的类别标签和置信度分数。图像分类在我们只需要知道图像属于哪个类别,而不需要知道该类别的物体位于何处或其确切形状时非常有用。
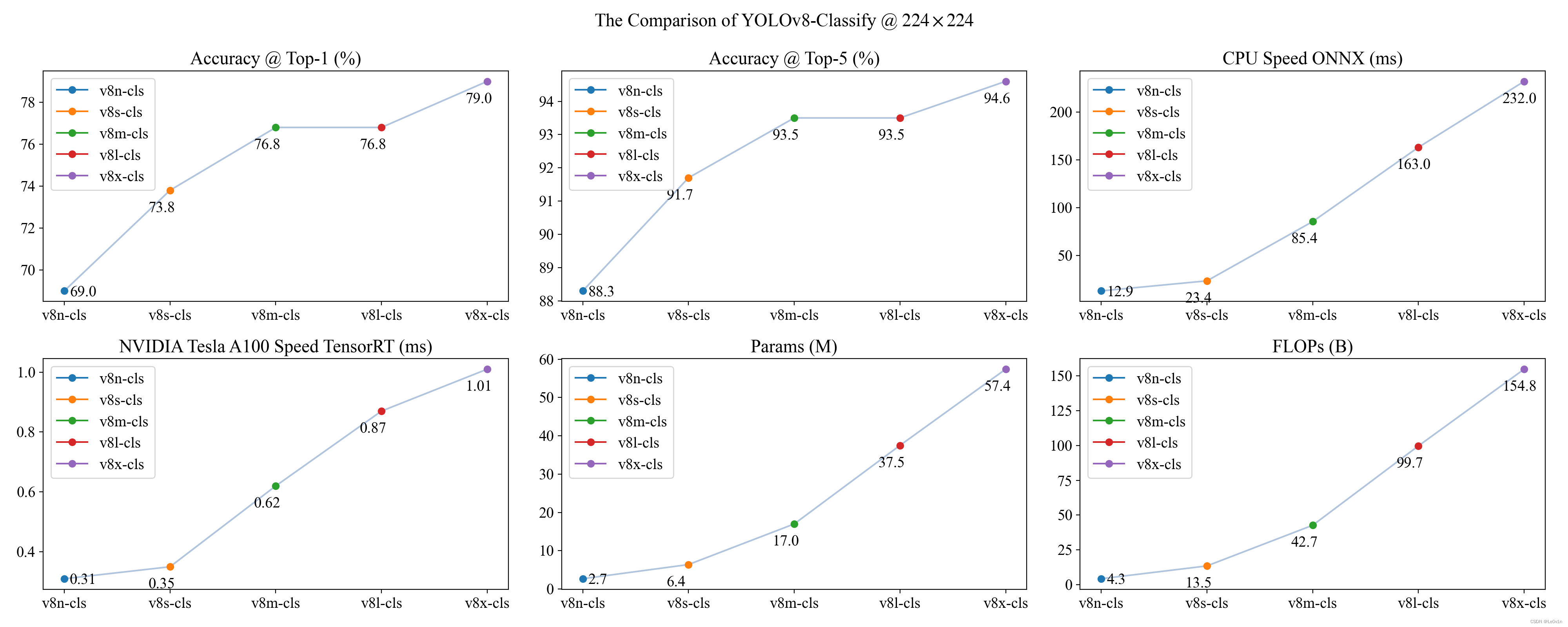
4.5.2 模型概况
| 模型名称 | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) at 640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 69.0 | 88.3 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 73.8 | 91.7 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.8 | 93.5 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 76.8 | 93.5 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 79.0 | 94.6 | 232.0 | 1.01 | 57.4 | 154.8 |
4.5.3 训练情况
from ultralytics import YOLO
# ---------- 加载模型 ----------
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
# ---------- 训练模型 ----------
results = model.train(data='../datasets/classification-mnist', epochs=100, imgsz=64)

Validating runs/classify/train4/weights/best.pt...
Ultralytics YOLOv8.1.18 🚀 Python-3.8.18 torch-1.10.1 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11020MiB)
YOLOv8n-cls summary (fused): 73 layers, 1447690 parameters, 0 gradients, 3.3 GFLOPs
train: /data/data_01/XXXX/datasets/classification-mnist/train... found 80 images in 10 classes ✅
val: /data/data_01/XXXX/datasets/classification-mnist/val... found 80 images in 10 classes ✅
test: None...
classes top1_acc top5_acc: 100%|██████████| 3/3 [00:00<00:00, 74.05it/s]
all 0.875 0.988
Speed: 0.0ms preprocess, 0.4ms inference, 0.0ms loss, 0.0ms postprocess per image
Results saved to runs/classify/train4
4.5.4 模型导出
4.5.5 模型推理
image 1/1 /data/data_01/XXXX/ultralytics-20240416/quick_start/images/classify.png: 64x64 9 0.36, 5 0.17, 8 0.15, 3 0.07, 7 0.07, 4.4ms
Speed: 3.0ms preprocess, 4.4ms inference, 0.1ms postprocess per image at shape (1, 3, 64, 64)
Results saved to runs/classify/predict2

5. YOLOv8 可以推理的格式
Ultralytics 团队的代码具有非常强大的功能,因此模型可以推理几乎所有的格式,如下所示:
| Source | Argument | Type | Notes |
|---|---|---|---|
| image | ‘image.jpg’ | str or Path | 单个图像文件 |
| URL | ‘https://ultralytics.com/images/bus.jpg’ | str | 图像的URL |
| screenshot | ‘screen’ | str | 屏幕截图 |
| PIL | Image.open(‘im.jpg’) | PIL.Image | RGB通道的HWC格式 |
| OpenCV | cv2.imread(‘im.jpg’) | np.ndarray | BGR通道uint8(0-255)的HWC格式 |
| numpy | np.zeros((640,1280,3)) | np.ndarray | BGR通道uint8(0-255)的HWC格式 |
| torch | torch.zeros(16,3,320,640) | torch.Tensor | RGB通道float32(0.0-1.0)的BCHW格式 |
| CSV | ‘sources.csv’ | str or Path | 包含图像、视频或目录路径的CSV文件 |
| video ✅ | ‘video.mp4’ | str or Path | MP4、AVI等格式的视频文件 |
| directory ✅ | ‘path/’ | str or Path | 包含图像或视频的目录路径 |
| glob ✅ | ‘path/*.jpg’ | str | 匹配多个文件的Glob模式使用*字符作为通配符 |
| YouTube ✅ | ‘https://youtu.be/LNwODJXcvt4’ | str | 指向YouTube视频的URL |
| stream ✅ | ‘rtsp://example.com/media.mp4’ | str | 用于RTSP、RTMP、TCP或IP地址等流协议的URL |
| multi-stream ✅ | ‘list.streams’ | str or Path | *.streams文本文件,每行一个流URL,即8个流将以batch-size 8运行 |
glob是一种通配符模式,用于匹配指定规则的文件名。在 Linux 和 Unix 系统中,glob也被用于匹配文件名。在 Python 中,glob模块用于检索与指定模式匹配的文件/路径名。例如,glob.glob('*.txt')将返回当前目录中所有以.txt结尾的文件名。
6. YOLOv8 推理结果的使用
6.1 获取推理结果 results
在 YOLOv8 中,模型的推理结果其实是一个实例化类对象,所以它有自己的方法和属性。
from ultralytics import YOLO
# 加载模型
model = YOLO('pretrained_weights/yolov8n.pt')
# 让模型推理,我们可以得到结果
results = model(['img1.jpg', 'img2.jpg', 'img3.jpg'])
print(f"type(results): {type(results)}") # <class 'list'>
# 接下来我们就可以处理结果了
for result in results:
print(f"type(result): {type(result)}") # <class 'ultralytics.engine.results.Results'>
boxes = result.boxes # [目标检测任务] bbox outputs
masks = result.masks # [分割任务] 分割得到的 masks
keypoints = result.keypoints # [关键点检测任务] 关键点
probs = result.probs # [分类任务] 类别概率
print(f"type(boxes): {type(boxes)}") # <class 'ultralytics.engine.results.Boxes'>
print(f"type(masks): {type(masks)}") # <class 'NoneType'>
print(f"type(keypoints): {type(keypoints)}") # <class 'NoneType'>
print(f"type(probs): {type(probs)}") # <class 'NoneType'>
我们可以看到,模型推理结果得到的 results 是一个 list,我们可以对其遍历得到 result。之后查看 result 的数据类型,是 <class 'ultralytics.engine.results.Results'> 的实例化对象,所以 result 会有一下方法和属性。再对 result 取 .boxes、.masks、.keypoints以及 .probs 可以取出不同任务的结果。在 ultralytics 项目中,默认的任务是目标检测,因此我们在查看数据类型的时候发现,只有 boxes 是 <class 'ultralytics.engine.results.Boxes'> 的实例化对象,其他的都是 <class 'NoneType'> 的实例化对象(即为 None)。
6.2 Results 实例化对象的属性和方法介绍
除了上述的属性外,<class 'ultralytics.engine.results.Results'> 的实例化对象 result 所有的属性如下所示:
| 属性 | Type | 描述 |
|---|---|---|
| orig_img | numpy.ndarray | 原始图像的 numpy 数组 |
| orig_shape | tuple | 以 (高度,宽度) 格式表示的原始图像形状 |
| boxes | Boxes, optional | 包含检测边界框的 Boxes 对象 |
| masks | Masks, optional | 包含检测掩模的 Masks 对象 |
| probs | Probs, optional | 包含分类任务每个类别的概率的 Probs 对象 |
| keypoints | Keypoints, optional | 包含每个对象检测到的关键点的 Keypoints 对象 |
| speed | dict | 每张图像的预处理、推理和后处理速度的字典,以毫秒为单位 |
| names | dict | 类别名称的字典 |
| path | str | 图像文件的路径 |
因为 result 是一个类对象,所以它也有方法,所有方法如下:
| 方法 | 返回值类型 | 描述 |
|---|---|---|
__getitem__() | Results | 返回指定索引的 Results 对象 |
__len__() | int | 返回 Results 对象中检测结果的数量 |
update() | None | 更新 Results 对象的 boxes、masks 和 probs 属性 |
cpu() | Results | 返回所有 Tensor 都在 CPU 内存上的 Results 对象的副本 |
numpy() | Results | 返回所有 Tensor 都作为 numpy 数组的 Results 对象的副本 |
cuda() | Results | 返回所有 Tensor 都在 GPU 内存上的 Results 对象的副本 |
to() | Results | 返回具有指定设备和 dtype 的 Tensor 的 Results 对象的副本 |
new() | Results | 返回具有相同图像、路径和名称的新 Results 对象 |
keys() | List[str] | 返回非空属性名称的列表 |
plot() | numpy.ndarray | 绘制检测结果。返回带注释的图像的 numpy 数组 |
verbose() | str | 返回每个任务的日志字符串 |
save_txt() | None | 将预测保存到 txt 文件中 |
save_crop() | None | 将裁剪的预测保存到 save_dir/cls/file_name.jpg 中 |
tojson() | None | 将对象转换为 JSON 格式 |
💡 Tips:对于得到的结果,我们也可以将它们转移到任意的设备中,详情如下:
results = results.cuda()
results = results.cpu()
results = results.to('cpu')
results = results.numpy()
6.3 目标检测任务的 Boxes 实例化对象的属性和方法
接下来我们看看 <class 'ultralytics.engine.results.Boxes'> 的实例化对象 boxes 还有哪些操作。
以下是 Boxes 类的方法和属性的表格,包括它们的名称、类型和描述:
| 名称 | Type | 描述 |
|---|---|---|
cpu() | 方法 | 将对象移动到 CPU 内存 |
numpy() | 方法 | 将对象转换为 numpy 数组 |
cuda() | 方法 | 将对象移动到 CUDA 内存 |
to() | 方法 | 将对象移动到指定的设备 |
xyxy | 属性 (torch.Tensor) | 以 xyxy 格式返回边界框 |
conf | 属性 (torch.Tensor) | 返回边界框的置信度值 |
cls | 属性 (torch.Tensor) | 返回边界框的类别值 |
id | 属性 (torch.Tensor) | 返回边界框的跟踪 ID(如果有) |
xywh | 属性 (torch.Tensor) | 以 xywh 格式返回边界框 |
xyxyn | 属性 (torch.Tensor) | 以原始图像大小归一化的 xyxy 格式返回边界框 |
xywhn | 属性 (torch.Tensor) | 以原始图像大小归一化的 xywh 格式返回边界框 |
Question:什么是 xyxy 格式、什么又是 xywh 格式?
Answer:在 YOLO 中,xyxy 格式和 xywh 格式都是用于表示物体边界框的两种常见格式。其中:
xyxy格式指的是物体边界框的左上角和右下角的坐标,即(x1, y1, x2, y2);xywh格式则指的是物体边界框的中心点坐标、宽度和高度,即(x, y, w, h)。
如果我们有一个边界框的 xyxy 坐标,我们可以使用以下公式将其转换为 xywh 格式:
x = x 1 + x 2 2 y = y 1 + y 2 2 w = x 2 − x 1 h = y 2 − y 1 \begin{aligned} x &= \frac{x_1 + x_2}{2} \\ y &= \frac{y_1 + y_2}{2} \\ w &= x_2 - x_1 \\ h &= y_2 - y_1 \end{aligned} xywh=2x1+x2=2y1+y2=x2−x1=y2−y1
反之,如果我们有一个边界框的 xywh 坐标,我们可以使用以下公式将其转换为 xyxy 格式:
x 1 = x − w 2 y 1 = y − h 2 x 2 = x + w 2 y 2 = y + h 2 \begin{aligned} x_1 &= x - \frac{w}{2} \\ y_1 &= y - \frac{h}{2} \\ x_2 &= x + \frac{w}{2} \\ y_2 &= y + \frac{h}{2} \end{aligned} x1y1x2y2=x−2w=y−2h=x+2w=y+2h
6.4 语义分割任务的 Masks 实例化对象的属性和方法
from ultralytics import YOLO
# Load a pretrained YOLOv8n-seg Segment model
model = YOLO('yolov8n-seg.pt')
# Run inference on an image
results = model('bus.jpg') # results list
# View results
for r in results:
print(r.masks) # print the Masks object containing the detected instance masks
| Name | 类型 | 描述 |
|---|---|---|
| cpu() | Method | 返回位于 CPU 内存上的 masks tensor。 |
| numpy() | Method | 返回位于 CPU 内存上的 masks tensor 的 NumPy 数组。 |
| cuda() | Method | 返回位于 GPU 内存上的 masks tensor 。 |
| to() | Method | 返回具有指定设备和数据类型的 masks tensor 。 |
| xyn | Property (torch.Tensor) | 一组归一化的 segments,由 tensor 表示。 |
| xy | Property (torch.Tensor) | 一组像素坐标的 segments,由 tensor 表示。 |
7. YOLOv8 模式说明
7.1 训练模式
7.1.1 训练代码示意
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
# Train the model with 2 GPUs
results = model.train(data='coco8.yaml', epochs=100, imgsz=640, device=[0, 1])
7.1.2 训练参数设置
| 参数 | 默认值 | 描述 |
|---|---|---|
| model | None | 指定训练模型文件。接受一个路径,可以是一个 .pt 预训练模型文件或一个 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
| data | None | 数据集配置文件的路径(例如,coco8.yaml)。这个文件包含特定于数据集的参数,包括训练和验证数据的路径、类名和类的数量。 |
| epochs | 100 | 训练的总轮数。每个轮次代表对整个数据集的一次完整遍历。调整这个值可以影响训练持续时间和模型性能。 |
| time | None | 最大训练时间,以小时为单位。如果设置了此参数,这将覆盖轮数参数,允许在指定持续时间后自动停止训练。对于时间受限的训练场景非常有用。 |
| patience | 100 | 在验证指标没有改善的情况下,停止训练之前的轮数。通过在性能达到平台期时停止训练,有助于防止过拟合。 |
| batch | 16 | 训练的批量大小,表示在更新模型的内部参数之前处理多少图像。AutoBatch(batch=-1)根据 GPU 内存可用性动态调整批量大小。 |
| imgsz | 640 | 训练的目标图像大小。所有图像在输入模型之前都会被调整到这个尺寸。影响模型准确性和计算复杂度。 |
| save | True | 启用训练检查点和最终模型权重的保存。对于恢复训练或模型部署非常有用。 |
| save_period | -1 | 保存模型检查点的频率,以轮数为单位指定。值为 -1 将禁用此功能。在长时间训练会话中保存中间模型时非常有用。 |
| cache | False | 启用将数据集图像缓存到内存(True/ram),到磁盘(disk),或禁用(False)。通过减少磁盘 I/O 来提高训练速度,但会增加内存使用。 |
| device | None | 指定训练的计算设备:单个 GPU(device=0),多个 GPU(device=0,1),CPU(device=cpu),或用于苹果硅的 MPS(device=mps)。 |
| workers | 8 | 用于数据加载的工作线程数(如果多 GPU 训练,则每个 RANK)。影响数据预处理和送入模型的速度,特别是在多 GPU 设置中非常有用。 |
| project | None | 项目目录的名称,其中保存训练输出。允许对不同实验进行有组织的存储。 |
| name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,其中保存训练日志和输出。 |
| exist_ok | False | 如果为 True,则允许覆盖现有的项目 / 名称目录。在进行迭代实验时非常有用,无需手动清除以前的输出。 |
| pretrained | True | 确定是否从预训练模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
| optimizer | ‘auto’ | 训练的优化器选择。选项包括 SGD、Adam、AdamW、NAdam、RAdam、RMSProp 等,或 auto 用于基于模型配置自动选择。影响收敛速度和稳定性。 |
| verbose | False | 启用训练期间的详细输出,提供详细的日志和进度更新。对于调试和密切监控训练过程非常有用。 |
| seed | 0 | 设置训练的随机种子,确保在具有相同配置的多次运行中结果的复现性。 |
| deterministic | True | 强制使用确定性算法,确保复现性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
| single_cls | False | 在多类数据集训练期间将所有类视为单个类。对于二分类任务或在关注对象存在而不是分类时非常有用。 |
| rect | False | 启用矩形训练,优化批量组合以最小化填充。可以提高效率和速度,但可能会影响模型准确性。 |
| cos_lr | False | 利用余弦学习率调度器,根据余弦曲线调整学习率。有助于更好地管理学习率以实现更好的收敛。 |
| close_mosaic | 10 | 在最后 N 轮中禁用马赛克数据增强,以在训练完成前稳定训练。设置为 0 将禁用此功能。 |
| resume | False | 从最后一个保存的检查点恢复训练。自动加载模型权重、优化器状态和轮次计数,无缝继续训练。 |
| amp | True | 启用自动混合精度(AMP)训练,减少内存使用,并可能在最小影响准确性的情况下加速训练。 |
| fraction | 1.0 | 指定用于训练的数据集的比例。允许在完整数据集的子集上进行训练,在实验或资源有限时非常有用。 |
| profile | False | 启用训练期间 ONNX 和 TensorRT 速度的剖析,对于优化模型部署非常有用。 |
| freeze | None | 冻结模型的第一个 N 层或指定的层索引,减少可训练参数的数量。对于微调或迁移学习非常有用。 |
| lr0 | 0.01 | lr0 |
| lrf | 0.01 | 最终学习率作为初始速率的分数 = (lr0 * lrf),与调度器结合使用以随时间调整学习率。 |
| momentum | 0.937 | SGD 的动量因子或 Adam 优化器的 beta1,影响当前更新中过去梯度的融入。 |
| weight_decay | 0.0005 | L2 正则化项,对大权重进行惩罚以防止过拟合。 |
| warmup_epochs | 3.0 | 学习率预热轮数,从低值逐渐增加到初始学习率,以在训练初期稳定训练。 |
| warmup_momentum | 0.8 | 预热阶段的初始动量,在预热期间逐渐调整到设定的动量。 |
| warmup_bias_lr | 0.1 | 预热阶段偏置参数的学习率,帮助在初始轮次稳定模型训练。 |
| box | 7.5 | 损失函数中框损失组件的权重,影响对边界框坐标准确预测的重视程度。 |
| cls | 0.5 | 总损失函数中分类损失的权重,影响正确类别预测相对于其他组件的重要性。 |
| dfl | 1.5 | 分布焦点损失的权重,用于某些 YOLO 版本进行细粒度分类。 |
| pose | 12.0 | 在训练姿态估计模型时姿态损失的权重,影响对准确预测姿态关键点的重视程度。 |
| kobj | 2.0 | 姿态估计模型中关键点目标性损失的权重,平衡检测置信度与姿态准确度。 |
| label_smoothing | 0.0 | 应用标签平滑,将硬标签软化为目标标签与标签的均匀分布的混合,可以提高泛化能力。 |
| nbs | 64 | 用于损失标准化的名义批量大小。 |
| overlap_mask | True | 确定在训练期间分割掩码是否应该重叠,适用于实例分割任务。 |
| mask_ratio | 4 | 分割掩码的下采样比率,影响训练期间使用的掩码分辨率。 |
| dropout | 0.0 | 分类任务中用于正则化的 dropout 率,通过在训练期间随机省略单元来防止过拟合。 |
| val | True | 启用训练期间的验证,允许定期评估模型在单独数据集上的性能。 |
| plots | False | 生成并保存训练和验证指标以及预测示例的图表,提供模型性能和学习进度的视觉洞察。 |
7.1.3 数据增强参数设置
| 参数 | 类型 | 默认值 | 范围 | 描述 |
|---|---|---|---|---|
| hsv_h | float | 0.015 | 0.0 - 1.0 | 通过色轮的一部分调整图像的色调,引入颜色可变性。帮助模型在不同光照条件下泛化。 |
| hsv_s | float | 0.7 | 0.0 - 1.0 | 通过一部分调整图像的饱和度,影响颜色的强度。对于模拟不同的环境条件很有用。 |
| hsv_v | float | 0.4 | 0.0 - 1.0 | 通过一部分调整图像的值(亮度),帮助模型在各种光照条件下表现良好。 |
| degrees | float | 0.0 | -180 - +180 | 在指定的度数范围内随机旋转图像,提高模型识别不同方向对象的能力。 |
| translate | float | 0.1 | 0.0 - 1.0 | 通过图像尺寸的一部分在水平和垂直方向上平移图像,有助于学习检测部分可见对象。 |
| scale | float | 0.5 | >=0.0 | 通过增益因子缩放图像,模拟相机不同距离处的对象。 |
| shear | float | 0.0 | -180 - +180 | 按指定的度数剪切图像,模仿从不同角度观察对象的效果。 |
| perspective | float | 0.0 | 0.0 - 0.001 | 对图像应用随机的透视变换,增强模型理解 3D 空间中对象的能力。 |
| flipud | float | 0.0 | 0.0 - 1.0 | 以指定的概率将图像上下翻转,增加数据可变性而不影响对象的特性。 |
| fliplr | float | 0.5 | 0.0 - 1.0 | 以指定的概率将图像左右翻转,有助于学习对称对象和增加数据集多样性。 |
| bgr | float | 0.0 | 0.0 - 1.0 | 以指定的概率将图像通道从 RGB 翻转至 BGR,有助于增加对错误通道排序的鲁棒性。 |
| mosaic | float | 1.0 | 0.0 - 1.0 | 将四个训练图像组合成一个,模拟不同的场景组合和对象交互。对于复杂场景理解非常有效。 |
| mixup | float | 0.0 | 0.0 - 1.0 | 混合两张图像及其标签,创建一个复合图像。通过引入标签噪声和视觉可变性,增强模型的泛化能力。 |
| copy_paste | float | 0.0 | 0.0 - 1.0 | 从一个图像中复制对象并将其粘贴到另一个图像上,有助于增加对象实例和学习对象遮挡。 |
| auto_augment | 字符串 | randaugment | - | 自动应用预定义的增强策略(randaugment, autoaugment, augmix),通过多样化视觉特征,为分类任务优化。 |
| erasing | float | 0.4 | 0.0 - 0.9 | 在分类训练期间随机擦除图像的一部分,鼓励模型专注于不那么明显的特征进行识别。 |
| crop_fraction | float | 1.0 | 0.1 - 1.0 | 将分类图像裁剪到其尺寸的一部分,以强调中心特征并适应对象尺度,减少背景干扰。 |
7.2 验证模式(评估模式)
7.2.1 代码示例
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt')
# Customize validation settings
validation_results = model.val(data='coco8.yaml',
imgsz=640,
batch=16,
conf=0.25,
iou=0.6,
device='0')
7.2.2 验证参数设置
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| data | str | None | 指定数据集配置文件的路径(例如,coco8.yaml)。这个文件包括验证数据的路径、类名和类的数量。 |
| imgsz | int | 640 | 定义输入图像的大小。所有图像在处理前都调整到这个尺寸。 |
| batch | int | 16 | 设置每个批次的图像数量。使用 -1 表示自动批量(AutoBatch),它会根据 GPU 内存可用性自动调整。 |
| save_json | bool | False | 如果为 True,将结果保存到 JSON 文件中,以便进一步分析或与其他工具集成。 |
| save_hybrid | bool | False | 如果为 True,保存标签的混合版本,将原始注释与额外的模型预测相结合。 |
| conf | float | 0.001 | 设置检测的最小置信阈值。丢弃置信度低于这个阈值的检测。 |
| iou | float | 0.6 | 设置非极大值抑制(NMS)的交并比(IoU)阈值。有助于减少重复检测。 |
| max_det | int | 300 | 限制每张图像的最大检测数量。在密集场景中用于防止过度检测。 |
| half | bool | True | 启用半精度(FP16)计算,减少内存使用,并可能在最小影响准确性的情况下提高速度。 |
| device | str | None | 指定验证的设备(cpu, cuda:0 等)。允许灵活使用 CPU 或 GPU 资源。 |
| dnn | bool | False | 如果为 True,使用 OpenCV DNN 模块进行 ONNX 模型推理,作为 PyTorch 推理方法的替代。 |
| plots | bool | False | 当设置为 True 时,生成并保存预测与真实值的对比图,以便直观评估模型的性能。 |
| rect | bool | False | 如果为 True,使用矩形推理进行批处理,减少填充,可能提高速度和效率。 |
| split | str | val | 确定用于验证的数据集划分(val, test, 或 train)。允许灵活选择用于性能评估的数据段。 |
7.3 推理模式(预测)
7.3.1 支持的输入
YOLOv8 可以处理不同类型的输入源进行推理,如下表所示。这些输入源包括静态图像、视频流和各种数据格式。表格还指示了每种源是否可以使用参数 stream=True ✅以流模式使用。流模式对于处理视频或实时流非常有用,因为它创建了一个结果生成器,而不是将所有帧加载到内存中。
💡 提示:对于处理长视频或大型数据集,为了有效地管理内存,请使用 stream=True。当 stream=False 时,所有帧或数据点的结果都存储在内存中,这对于大型输入来说会迅速增加并可能导致内存不足错误。相比之下,stream=True 使用生成器,它只保留当前帧或数据点的结果在内存中,显著减少内存消耗并防止内存不足问题。
| 源 | 参数 | 类型 | 备注 |
|---|---|---|---|
| 图像 | ‘image.jpg’ | str 或 Path | 单个图像文件。 |
| URL | ‘https://ultralytics.com/images/bus.jpg’ | str | 图像的 URL。 |
| 🌟 屏幕截图 | ‘screen’ | str | 捕获屏幕截图。 |
| PIL | Image.open(‘im.jpg’) | PIL.Image | HWC 格式,带有 RGB 通道。 |
| OpenCV | cv2.imread(‘im.jpg’) | np.ndarray | HWC 格式,带有 BGR 通道,uint8 (0-255)。 |
| numpy | np.zeros((640,1280,3)) | np.ndarray | HWC 格式,带有 BGR 通道,uint8 (0-255)。 |
| torch | torch.zeros(16,3,320,640) | torch.Tensor | BCHW 格式,带有 RGB 通道,float32 (0.0-1.0)。 |
| CSV | ‘sources.csv’ | str 或 Path | 包含图像、视频或目录路径的 CSV 文件。 |
| 视频 ✅ | ‘video.mp4’ | str 或 Path | MP4、AVI 等格式的视频文件。 |
| 目录 ✅ | ‘path/’ | str 或 Path | 包含图像或视频的目录路径。 |
| glob ✅ | ‘path/*.jpg’ | str | 匹配多个文件的 Glob 模式。使用 * 字符作为通配符。 |
| YouTube ✅ | ‘https://youtu.be/LNwODJXcvt4’ | str | YouTube 视频的 URL。 |
| 流 ✅ | ‘rtsp://example.com/media.mp4’ | str | 流媒体协议的 URL,如 RTSP、RTMP、TCP 或 IP 地址。 |
| 多流 ✅ | ‘list.streams’ | str 或 Path | *.streams 文本文件,每行一个流 URL,例如 8 个流将以批大小 8 运行。 |
7.3.2 推理参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| source | str | ‘ultralytics/assets’ | 指定推理的数据源。可以是图像路径、视频文件、目录、URL 或实时流的设备 ID。支持多种格式和来源,使不同类型的输入都能灵活应用。 |
| conf | float | 0.25 | 设置检测的最小置信度阈值。低于此阈值的检测对象将被忽略。调整此值有助于减少误报。 |
| iou | float | 0.7 | 非极大值抑制(NMS)的交并比(IoU)阈值。较低的值会通过消除重叠的框来减少检测数量,对于减少重复检测很有用。 |
| imgsz | int 或 tuple | 640 | 定义推理的图像大小。可以是一个整数 640,用于方形缩放,也可以是一个(高度,宽度)元组。适当的尺寸可以提高检测准确性和处理速度。 |
| half | bool | False | 启用半精度(FP16)推理,可以在支持 GPU 上加速模型推理,同时对准确度的影响最小。 |
| device | str | None | 指定推理的设备(例如,cpu, cuda:0 或 0)。允许用户在 CPU、特定 GPU 或其他计算设备之间选择模型执行。 |
| max_det | int | 300 | 每张图像允许的最大检测数量。限制模型在单个推理中可以检测到的总对象数量,以防止在密集场景中产生过多的输出。 |
| vid_stride | int | 1 | 视频输入的帧间跳过。允许在视频中跳过帧以提高处理速度,但代价是时间分辨率。值为 1 时处理每个帧,更高的值跳过帧。 |
| stream_buffer | bool | False | 确定在处理视频流时是否应缓冲所有帧(True),或者模型是否应返回最新的帧(False)。对于实时应用很有用。 |
| visualize | bool | False | 激活推理期间模型特征的可视化,提供模型“看到”的洞察。对于调试和模型解释非常有用。 |
| augment | bool | False | 启用预测的测试时间增强(TTA),可能会提高检测的鲁棒性,但代价是推理速度。 |
| agnostic_nms | bool | False | 启用类无关的非极大值抑制(NMS),合并不同类的重叠框。在多类检测场景中,当类之间经常有重叠时非常有用。 |
| classes | list [int] | None | 过滤预测到一组类 ID。只有属于指定类的检测结果才会被返回。对于在多类检测任务中关注相关对象非常有用。 |
| retina_masks | bool | False | 如果模型中可用,则使用高分辨率的分割掩码。这可以增强分割任务的掩码质量,提供更细的细节。 |
| embed | list [int] | None | 指定要从哪些层提取特征向量或嵌入。对于下游任务,如聚类或相似度搜索非常有用。 |
其中:TTA 是测试时间增强(Test Time Augmentation)的缩写。在目标检测和图像分类任务中,TTA 是一种技术,它通过对测试图像进行一系列变换和增强来改善模型的性能。
通常,在测试阶段,模型在输入图像上进行预测,然后根据预测结果进行分类或目标框的生成。而在使用 TTA 时,会对输入图像进行多次变换和增强,生成一组扩充的图像。然后,对这组扩充的图像分别进行预测,并对预测结果进行集成。
通过对输入图像进行多个变换和增强,TTA 可以提供更多样化和鲁棒性的预测。这有助于减轻模型在输入图像上的局限性,并增加模型对不同视角、尺度、光照条件等变化的适应能力。通过集成多个预测结果,例如取平均值或投票,可以进一步提高模型的性能和稳定性。
需要注意的是,TTA 会增加推理时间,因为需要对每个扩充的图像进行预测。然而,对于一些对准确性要求较高的任务,如竞赛或关键应用,TTA 可以是一种有效的技术来提高模型的性能。
7.3.3 可视化参数
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| show | bool | False | 如果为 True,则在窗口中显示标注的图像或视频。在开发或测试期间,这对于立即获得视觉反馈非常有用。 |
| save | bool | False | 启用将标注的图像或视频保存到文件。这对于文档、进一步分析或分享结果非常有用。 |
| save_frames | bool | False | 在处理视频时,将单独的帧保存为图像。这对于提取特定帧或进行详细的逐帧分析非常有用。 |
| save_txt | bool | False | 将检测结果保存为文本文件,格式为 [class] [x_center] [y_center] [width] [height] [confidence]。这对于与其他分析工具集成非常有用。 |
| save_conf | bool | False | 在保存的文本文件中包含置信度分数。增强了可用于后处理和分析的详细信息。 |
| save_crop | bool | False | 保存检测的裁剪图像。这对于数据增强、分析或创建特定对象的聚焦数据集非常有用。 |
| show_labels | bool | True | 在视觉输出中显示每个检测的标签。提供了对检测到的对象立即的理解。 |
| show_conf | bool | True | 在标签旁边显示每个检测的置信度分数。为每个检测提供了模型确定性的洞察。 |
| show_boxes | bool | True | 在图像或视频帧中检测到的对象周围绘制边界框。这对于视觉识别和定位图像或视频帧中的对象至关重要。 |
| line_width | None 或 int | None | 指定边界框的线条宽度。如果为 None,线条宽度将根据图像大小自动调整。为清晰度提供了视觉定制。 |


















 5897
5897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









