






PyCaret 是由 Moez Ali 创建并于2020年4月发布的 python 开源低代码机器学习库。它只需要使用很少的代码就可以创建整个机器学习管道。
与其他开源机器学习库相比,PyCaret 是一个低代码库,它可以使项目快速而高效完成。从本质上讲,PyCaret 是 Python 的包装器,它围绕着多个机器学习库和框架,例如scikit-learn,XGBoost,LightGBM,spaCy,Hyperopt,Ray等。
安装
pip install pycaret
为了让大家更好的了解 PyCaret ,我将以电信客户客户流失数据集为例子进行讲解,数据集文末可以下载,字段含义如下:

导入数据
import numpy as np
import pandas as pd
df = pd.read_csv("Telco-Customer-Churn.csv")
print(df.shape)
print(df.columns)
------- result----------
(7043, 21)
Index(['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents',
'tenure', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport',
'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling',
'PaymentMethod', 'MonthlyCharges', 'TotalCharges', 'Churn'],
dtype='object')
"CustomerID"没有任何信息,它只是分配给每个客户的随机记录,我们也不需要总费用,删除这两列:
df.drop(['customerID','TotalCharges'], axis=1, inplace=True)
让我们从导入 PyCaret 的模块开始
from pycaret.classification import *
设置
PyCaret 是从机器学习准备环境开始。它必须在任何其他函数之前执行 setup。
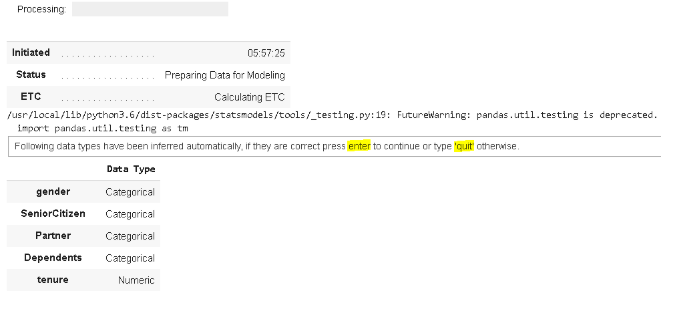
有一个重要点需要说明,setup 函数推断数据类型,如果推断的数据类型正确,它会提示你点击输入。如果推断的数据类型有错误,则键入"quit"。有两个方法来确定正确的数据类型:
- 使用 Pandas 函数和手动更改数据类型;
- 使用numeric_features 和 categorical_features设置参数;
exp_clf = setup(data = df, target = 'Churn', session_id=111)
模型比较
执行了 setup 后,我们就可以简要评估 PyCaret 模型库中所有模型的性能。compare_models 函数训练所有模型并根据 6 种常见分类指标评估它们的性能。
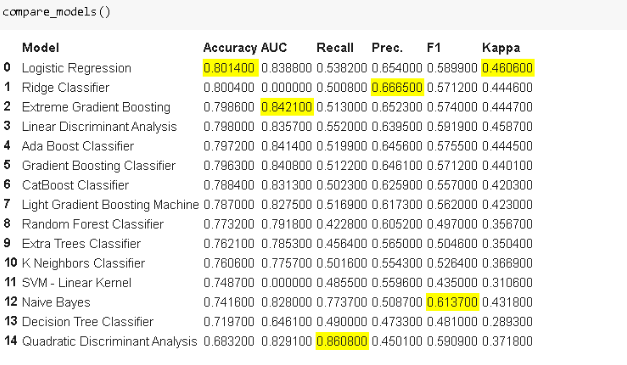
通过一行代码,我们可以比较 6 个不同指标下的 18 个模型。上图以准确率指标进行排序,显示最好的 15 个。
我们刚才做了一个粗略的评估。下一步是从该列表中选择一些算法,以进一步改进。我们选择什么模型取决于任务的需要。为了简单起见,我将选取以准确率最好的逻辑回归模型
logreg = create_model('lr')
模型性能的一个关键因素是超参数。在 PyCaret 中 tune_model 可在预定义的搜索空间中调谐超参数。使用需要注意两点:
Tune_model 模型名称作为输入,它不需要你先训练一个模型,然后调整它。
默认情况下,tune_model 尝试优化精度指标,但可以使用优化参数对其进行更改。
可创建优化逻辑回归模型
tuned_logreg = tune_model('lr')
模型分析
Plot_model 函数提供了进一步分析模型性能的工具。它将训练模型作为输入并返回指定的绘图。让我们来举一些例子。
plot_model(logreg, plot='auc')
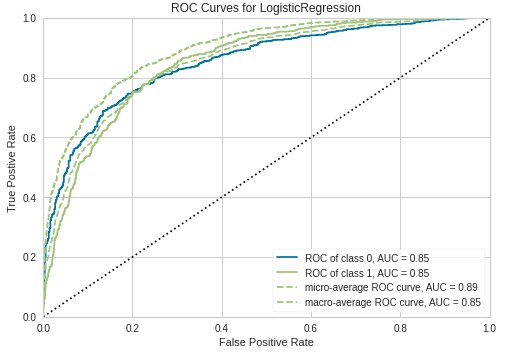
这是一个 ROC 曲线,它通过合并所有阈值的混淆矩阵来汇总模型在不同阈值下的性能。
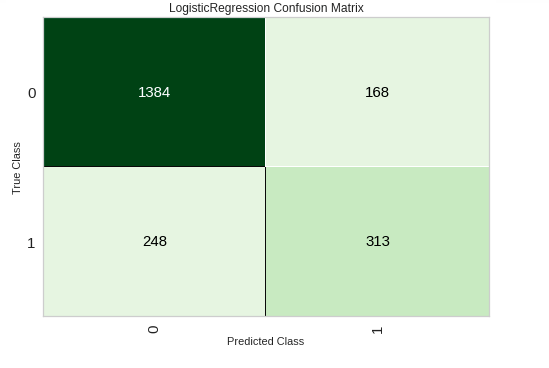
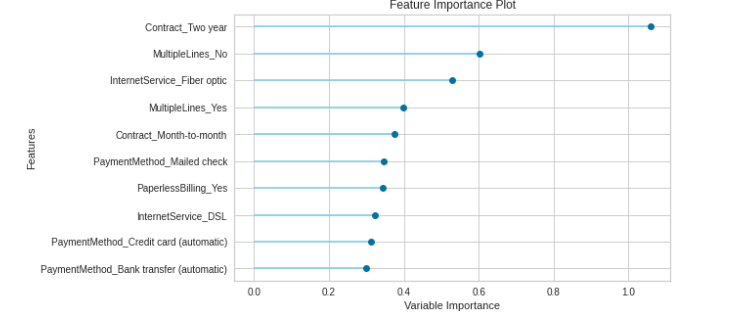
我们还可以使用 plot_model 创建混淆矩阵和特征重要性:
plot_model(logreg, plot='confusion_matrix')
plot_model(logreg, plot='feature')
预测和最终确定模型
Predict_model 函数用于对测试集进行预测。
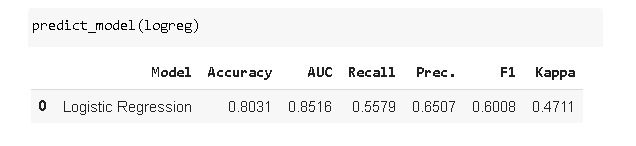
除了在测试集上的评估指标外,还返回包含两个新列的数据帧:predict_model
标签:预测
成绩:预测概率
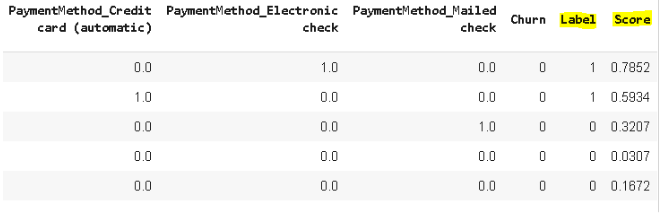
默认情况下,在测试集上进行预测,当然我们也可以用自己指定的数据来预测。
predict_model(logreg, data=new_data)
一旦我们对训练和测试集的结果满意,我们就可以使用具有一个 finalize_model 函数用全部数据重新模型。
final_logreg = finalize_model(logreg)
保存和加载模型
使用 Save_model 道保存训练模型图片我们可以使用函数加载保存load_model模型。图片
结论
我们已完成了整个机器学习的过程,从创建到完成大约使用了 10 行代码。正如前面所说,PyCaret 的确是一个低代码库。如















 1195
1195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









