






天池nlp赛事之新闻文本分类学习实践
一、赛题理解
- 赛题名称:零基础入门NLP之新闻文本分类
- 赛题目标:通过这道赛题可以引导大家走入自然语言处理的世界,带大家接触NLP的预处理、模型构建和模型训练等知识点。
- 赛题任务:赛题以自然语言处理为背景,要求选手对新闻文本进行分类,这是一个典型的字符识别问题。
1.1 赛题数据
赛题以匿名处理后的新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。
赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。为了预防选手人工标注测试集的情况,我们将比赛数据的文本按照字符级别进行了匿名处理。
1.2 数据标签
处理后的赛题训练数据如下:

在数据集中标签的对应的关系如下:{‘科技’: 0, ‘股票’: 1, ‘体育’: 2, ‘娱乐’: 3, ‘时政’: 4, ‘社会’: 5, ‘教育’: 6, ‘财经’: 7, ‘家居’: 8, ‘游戏’: 9, ‘房产’: 10, ‘时尚’: 11, ‘彩票’: 12, ‘星座’: 13}
1.3 评测指标
评价标准为类别 f1_score 的均值,选手提交结果与实际测试集的类别进行对比,结果越大越好。
1.4 解题思路
赛题思路分析:赛题本质是一个文本分类问题,需要根据每句的字符进行分类。但赛题给出的数据是匿名化的,不能直接使用中文分词等操作,这个是赛题的难点。
因此本次赛题的难点是需要对匿名字符进行建模,进而完成文本分类的过程。由于文本数据是一种典型的非结构化数据,因此可能涉及到特征提取和分类模型两个部分。给出以下四个思路:
- 思路1:TF-IDF + 机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。 - 思路2:FastText FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。
- 思路3:WordVec + 深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。 - 思路4:Bert词向量 Bert是高配款的词向量,具有强大的建模学习能力。
二、数据读取与简答分析
- 读取数据并分析赛题数据的分布规律
数据样例:
df['label'].value_counts()
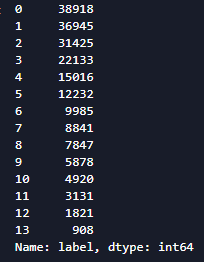
df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")

#%pylab inline 自动加载numpy和matplotlib库
%pylab inline
df['text_len'] = df['text'].apply(lambda x: len(x.split(' ')))
df.sample(5)
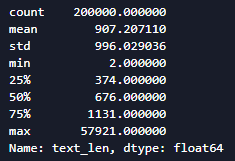
df['text_len'].describe()
_ = plt.hist(df['text_len'], bins=500)
plt.xlabel('Text char count')
plt.title("Histogram of char count")

from collections import Counter
all_lines = ' '.join(list(df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])

在训练集中总共包括6869个字,其中编号3750的字出现的次数最多,编号3133的字出现的次数最少。
这里还可以根据字在每个句子的出现情况,反推出标点符号。下面代码统计了不同字符在句子中出现的次数,其中字符3750,字符900和字符648在20w新闻的覆盖率接近99%,很有可能是标点符号。
df['text_unique'] = df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0],word_count[1],word_count[2],word_count[3],word_count[4],word_count[5],word_count[6])

通过数据分析,我们还可以得出以下结论:
- 赛题中每个新闻包含的字符个数平均为1000个,还有一些新闻字符较长
- 赛题中新闻类别分布不均匀,科技类新闻样本量接近4w,星座类新闻样本量不到1k
- 赛题总共包括7000-8000个字符
- 每个新闻平均字符个数较多,可能需要截断
- 由于类别不均衡,会严重影响模型的精度
3、ML-based 文本分类
基于sklearn的one-hot向量表示示例
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
vectorizer.fit_transform(corpus).toarray()
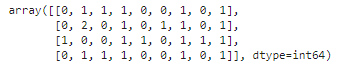
Count Vectors + RidgeClassifier文本分类
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('train_set.csv', sep='\t')
vectorizer = CountVectorizer(max_features=3000)
train_test = vectorizer.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
分类 F1值:

基于TF-IDF——RidgeClassifier的文本分类
- TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数¶
- IDF(t)= log_e(文档总数 / 出现该词语的文档总数)
from sklearn.feature_extraction.text import TfidfVectorizer
train_df = pd.read_csv('train_set.csv', sep='\t',)
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
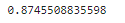
四、DL-Based文本分类
4.1基于fasttext
FastText:
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。所以FastText是一个三层的神经网络,输入层、隐含层和输出层。
keras实现FastText的网络结构:
from __future__ import unicode_literals
from keras.models import Sequential
from keras.layers import Embedding
from keras.layers import GlobalAveragePooling1D
from keras.layers import Dense
VOCAB_SIZE = 2000
EMBEDDING_DIM = 100
MAX_WORDS = 500
CLASS_NUM = 5
def build_fastText():
model = Sequential()
# 通过embedding层将词汇映射成EMBEDDING_DIM维向量
model.add(Embedding(VOCAB_SIZE,EMBEDDING_DIM,input_length=MAX_WORDS))
# 通过GlobalAveragePooling1D,平均文档中所有词的embedding
model.add(GlobalAveragePooling1D())
# 通过Softmax分类(真实的fastText这里分层Softmax),得到类别概率分布
model.add(Dense(CLASS_NUM,activation='softmax'))
# 定义损失函数、优化器、分类度量指标
model.compile(loss='categorical_crossentropy',optimizer='SGD',metrics=['accuracy'])
return model
model = build_fastText()
print(model.summary())

FastText在文本分类任务上,是优于TF-IDF的:
- FastText用单词的Embedding叠加获得的文档向量,将相似的句子分为一类
- FastText学习到的Embedding空间维度比较低,可以快速进行训练
from sklearn.metrics import f1_score
# 转换为FastText需要的格式
train_df = pd.read_csv('train_set.csv', sep='\t',nrows = 15000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('train.csv', index=None, header=None, sep='\t')
import fasttext
# wordNgrams:n-gram个数;minCount:词频阈值, 小于该值在初始化时会过滤掉;
model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2,
verbose=2, minCount=1, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str), val_pred, average='macro'))
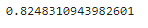
此时数据量比较小得分为0.82,当不断增加训练集数量时,FastText的精度也会不断增加5w条训练样本时,验证集得分可以到0.89-0.90左右。
后续注意参数选择及模型验证
4.1 word2vec的使用、TextCNN及TextRNN文本表示、HAN网络结构
4.1.1word2vec词向量
word2vec模型背后的基本思想是对出现在上下文环境里的词进行预测。对于每一条输入文本,我们选取一个上下文窗口和一个中心词,并基于这个中心词去预测窗口里其他词出现的概率。因此,word2vec模型可以方便地从新增语料中学习到新增词的向量表达,是一种高效的在线学习算法(online learning)。
word2vec的主要思路:通过单词和上下文彼此预测,对应的两个算法分别为:
- Skip-grams (SG):预测上下文
- Continuous Bag of Words (CBOW):预测目标单词
另外提出两种更加高效的训练方法:
- Hierarchical softmax
- Negative sampling
Word2Vec模型是一个超级大的神经网络(权重矩阵规模非常大)。例如:我们拥有10000个单词的词汇表,我们如果想嵌入300维的词向量,那么我们的输入-隐层权重矩阵和隐层-输出层的权重矩阵都会有 10000 x 300 = 300万个权重,在如此庞大的神经网络中进行梯度下降是相当慢的。更糟糕的是,你需要大量的训练数据来调整这些权重并且避免过拟合。百万数量级的权重矩阵和亿万数量级的训练样本意味着训练这个模型将会是个灾难。
常见解决方案:
- 将常见的单词组合(word pairs)或者词组作为单个“words”来处理
- 对高频次单词进行抽样来减少训练样本的个数
- 对优化目标采用“negative sampling”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担
负采样
训练一个神经网络意味着要输入训练样本并且不断调整神经元的权重,从而不断提高对目标的准确预测。每当神经网络经过一个训练样本的训练,它的权重就会进行一次调整。所以,词典的大小决定了我们的Skip-Gram神经网络将会拥有大规模的权重矩阵,所有的这些权重需要通过数以亿计的训练样本来进行调整,这是非常消耗计算资源的,并且实际中训练起来会非常慢。
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
如one-hot向量中的‘0’所对应的单词即为negative word,当使用负采样时,我们将随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的“positive” word进行权重更新,PS: 在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。
使用“一元模型分布(unigram distribution)”来选择“negative words”。个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。

在代码负采样的代码实现中,unigram table有一个包含了一亿个元素的数组,这个数组是由词汇表中每个单词的索引号填充的,并且这个数组中有重复,也就是说有些单词会出现多次。那么每个单词的索引在这个数组中出现的次数该如何决定呢,有公式,也就是说计算出的负采样概率*1亿=单词在表中出现的次数。
有了这张表以后,每次去我们进行负采样时,只需要在0-1亿范围内生成一个随机数,然后选择表中索引号为这个随机数的那个单词作为我们的negative word即可。一个单词的负采样概率越大,那么它在这个表中出现的次数就越多,它被选中的概率就越大。
Hierarchical Softmax过程:
为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射。
具体:略
4.1.1使用gensim训练word2vec
import logging # 引入logging模块
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)-15s %(levelname)s: %(message)s') # logging.basicConfig函数对日志的输出格式及方式做相关配置
# 由于日志基本配置中级别设置为DEBUG,所以一下打印信息将会全部显示在控制台上
logging.info('this is a loggging info message')
logging.debug('this is a loggging debug message')
logging.warning('this is loggging a warning message')
logging.error('this is an loggging error message')
logging.critical('this is a loggging critical message')
# set seed
seed = 666
random.seed(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed)
torch.manual_seed(seed)
# split data to 10 fold
fold_num = 10
data_file = 'train_set.csv'
import pandas as pd
def all_data2fold(fold_num):
fold_data = []
f = pd.read_csv(data_file, sep='\t', encoding='UTF-8')
texts = f['text'].tolist()
labels = f['label'].tolist()
total = len(labels)
#np.random,shuffle作用就是重新排序返回一个随机序列作用类似洗牌
index = list(range(total))
np.random.shuffle(index)
all_texts = []
all_labels = []
for i in index:
all_texts.append(texts[i])
all_labels.append(labels[i])
label2id = {}
for i in range(total):
label = str(all_labels[i])
if label not in label2id:
label2id[label] = [i]
else:
label2id[label].append(i)
all_index = [[] for _ in range(fold_num)]
for label, data in label2id.items():
# print(label, len(data))
batch_size = int(len(data) / fold_num)
other = len(data) - batch_size * fold_num
for i in range(fold_num):
cur_batch_size = batch_size + 1 if i < other else batch_size
# print(cur_batch_size)
batch_data = [data[i * batch_size + b] for b in range(cur_batch_size)]
all_index[i].extend(batch_data)
batch_size = int(total / fold_num)
other_texts = []
other_labels = []
other_num = 0
start = 0
for fold in range(fold_num):
num = len(all_index[fold])
texts = [all_texts[i] for i in all_index[fold]]
labels = [all_labels[i] for i in all_index[fold]]
if num > batch_size:
fold_texts = texts[:batch_size]
other_texts.extend(texts[batch_size:])
fold_labels = labels[:batch_size]
other_labels.extend(labels[batch_size:])
other_num += num - batch_size
elif num < batch_size:
end = start + batch_size - num
fold_texts = texts + other_texts[start: end]
fold_labels = labels + other_labels[start: end]
start = end
else:
fold_texts = texts
fold_labels = labels
assert batch_size == len(fold_labels)
# shuffle
index = list(range(batch_size))
np.random.shuffle(index)
shuffle_fold_texts = []
shuffle_fold_labels = []
for i in index:
shuffle_fold_texts.append(fold_texts[i])
shuffle_fold_labels.append(fold_labels[i])
data = {'label': shuffle_fold_labels, 'text': shuffle_fold_texts}
fold_data.append(data)
logging.info("Fold lens %s", str([len(data['label']) for data in fold_data]))
return fold_data
fold_data = all_data2fold(10)
# build train data for word2vec
fold_id = 9
train_texts = []
for i in range(0, fold_id):
data = fold_data[i]
train_texts.extend(data['text']) #append整体添加,extend整体打碎后添加
logging.info('Total %d docs.' % len(train_texts))
logging.info('Start training...')
from gensim.models.word2vec import Word2Vec
num_features = 100 # Word vector dimensionality
num_workers = 8 # Number of threads to run in parallel
# train_texts = list(map(lambda x: list(x.split()), train_texts))
model = Word2Vec(train_texts, workers=num_workers, size=num_features)
model.init_sims(replace=True)
# save model
model.save("./word2vec.bin")
# load model
model = Word2Vec.load("./word2vec.bin")
# convert format
model.wv.save_word2vec_format('./word2vec.txt', binary=False)
4.1.2 TextCNN及TextRNN
TextCNN利用CNN(卷积神经网络)进行文本特征抽取,不同大小的卷积核分别抽取n-gram特征,卷积计算出的特征图经过MaxPooling保留最大的特征值,然后将拼接成一个向量作为文本的表示。

TextRNN利用RNN(循环神经网络)进行文本特征抽取,由于文本本身是一种序列,而LSTM天然适合建模序列数据。TextRNN将句子中每个词的词向量依次输入到双向双层LSTM,分别将两个方向最后一个有效位置的隐藏层拼接成一个向量作为文本的表示。

##TextCNN模型搭建
self.filter_sizes = [2, 3, 4] # n-gram window
self.out_channel = 100
self.convs = nn.ModuleList([nn.Conv2d(1, self.out_channel, (filter_size, input_size), bias=True) for filter_size in self.filter_sizes])
##TextCNN前向传播
pooled_outputs = []
for i in range(len(self.filter_sizes)):
filter_height = sent_len - self.filter_sizes[i] + 1
conv = self.convs[i](batch_embed)
hidden = F.relu(conv) # sen_num x out_channel x filter_height x 1
mp = nn.MaxPool2d((filter_height, 1)) # (filter_height, filter_width)
# sen_num x out_channel x 1 x 1 -> sen_num x out_channel
pooled = mp(hidden).reshape(sen_num, self.out_channel)
pooled_outputs.append(pooled)
##TextRNN模型搭建
input_size = config.word_dims
self.word_lstm = LSTM(
input_size=input_size,
hidden_size=config.word_hidden_size,
num_layers=config.word_num_layers,
batch_first=True,
bidirectional=True,
dropout_in=config.dropout_input,
dropout_out=config.dropout_hidden,
)
##TextRNN前向传播
hiddens, _ = self.word_lstm(batch_embed, batch_masks) # sent_len x sen_num x hidden*2
hiddens.transpose_(1, 0) # sen_num x sent_len x hidden*2
if self.training:
hiddens = drop_sequence_sharedmask(hiddens, self.dropout_mlp)
4.1.3 使用HAN用于文本分类
Hierarchical Attention Network for Document Classification(HAN)基于层级注意力,在单词和句子级别分别编码并基于注意力获得文档的表示,然后经过Softmax进行分类。其中word encoder的作用是获得句子的表示,可以替换为上节提到的TextCNN和TextRNN,也可以替换为下节中的BERT。

4.2 基于bert进行分类
BERT拥有一个深而窄的神经网络。transformer的中间层有2048,BERT只有1024,但却有12层。因此,它可以在无需大幅架构修改的前提下进行双向训练。由于是无监督学习,因此不需要人工干预和标注,让低成本地训练超大规模语料成为可能。
BERT模型能够联合神经网络所有层中的上下文来进行训练。这样训练出来的模型在处理问答或语言推理任务时,能够结合上下文理解语义,并且实现更精准的文本预测生成。
预训练过程使用了Google基于Tensorflow发布的BERT源代码。首先从原始文本中创建训练数据,由于本次比赛的数据都是ID,这里重新建立了词表,并且建立了基于空格的分词器。
class WhitespaceTokenizer(object):
"""WhitespaceTokenizer with vocab."""
def __init__(self, vocab_file):
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
def tokenize(self, text):
split_tokens = whitespace_tokenize(text)
output_tokens = []
for token in split_tokens:
if token in self.vocab:
output_tokens.append(token)
else:
output_tokens.append("[UNK]")
return output_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
预训练由于去除了NSP预训练任务,因此将文档处理多个最大长度为256的段,如果最后一个段的长度小于256/2则丢弃。每一个段执行按照BERT原文中执行掩码语言模型,然后处理成tfrecord格式。
def create_segments_from_document(document, max_segment_length):
"""Split single document to segments according to max_segment_length."""
assert len(document) == 1
document = document[0]
document_len = len(document)
index = list(range(0, document_len, max_segment_length))
other_len = document_len % max_segment_length
if other_len > max_segment_length / 2:
index.append(document_len)
segments = []
for i in range(len(index) - 1):
segment = document[index[i]: index[i+1]]
segments.append(segment)
return segments
在预训练过程中,也只执行掩码语言模型任务,因此不再计算下一句预测任务的loss。
(masked_lm_loss, masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
total_loss = masked_lm_loss
为了适配句子的长度,以及减小模型的训练时间,我们采取了BERT-mini模型,详细配置如下。
{
"hidden_size": 256,
"hidden_act": "gelu",
"initializer_range": 0.02,
"vocab_size": 5981,
"hidden_dropout_prob": 0.1,
"num_attention_heads": 4,
"type_vocab_size": 2,
"max_position_embeddings": 256,
"num_hidden_layers": 4,
"intermediate_size": 1024,
"attention_probs_dropout_prob": 0.1
}
由于我们的整体框架使用Pytorch,因此需要将最后一个检查点转换成Pytorch的权重。
def convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, bert_config_file, pytorch_dump_path):
# Initialise PyTorch model
config = BertConfig.from_json_file(bert_config_file)
print("Building PyTorch model from configuration: {}".format(str(config)))
model = BertForPreTraining(config)
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
# Save pytorch-model
print("Save PyTorch model to {}".format(pytorch_dump_path))
torch.save(model.state_dict(), pytorch_dump_path)
fine-tune:
微调将最后一层的第一个token即[CLS]的隐藏向量作为句子的表示,然后输入到softmax层进行分类。
sequence_output, pooled_output = \
self.bert(input_ids=input_ids, token_type_ids=token_type_ids)
if self.pooled:
reps = pooled_output
else:
reps = sequence_output[:, 0, :] # sen_num x 256
if self.training:
reps = self.dropout(reps)
基于bert分类的简单示例结果:















 2445
2445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









