







我们先简单的说一下如何抓取一个网页的源代码,其实我们只需要调用Python中的Requests库中的GET方法就可以了。然后解析的话我们可以通过BeautifulSoup库来进行解析。
requests比较适合做中小型的网络爬虫开发,如果是要进行大型的网络爬虫开发那一般使用的就是Scrapy框架了。
requests.get() 这个方法其实就是请求获取指定URL位置的资源,对应的HTTP协议中的get方法
requests库的官网http://www.python-requests.org/en/master/
如下是官网上介绍的一些方法
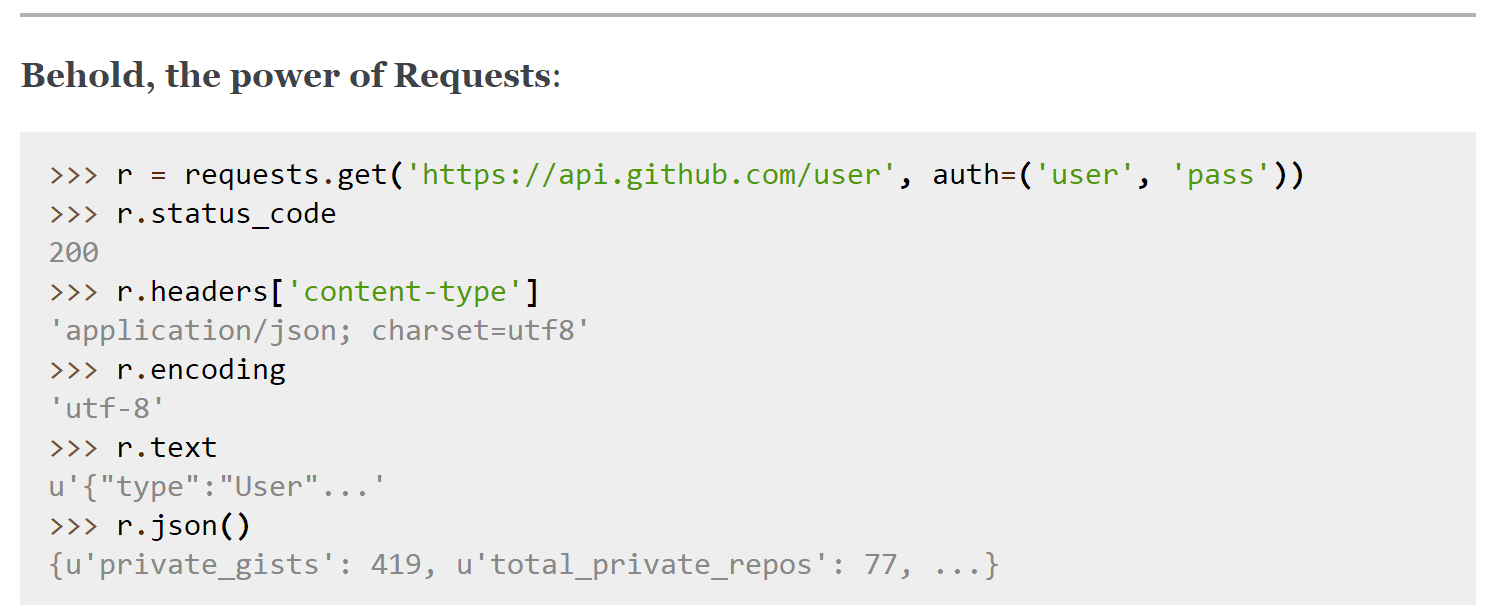
通过status_code来查看状态码,text来查看网页的内容,可以通过r.encoding去修改文件的编码
我们在抓取的时候要去看一下这个网站是不是有爬虫协议,有一些网站会提供robots.txt这么一个文件,一般来说这个文件是放在网站域名的根目录下的,里面制定的是一些规则,希望我们去遵守,如果存在的这个文件就表示它有自己的爬虫协议。这个协议中一般都有User-agent: 如果后面为*的话就表示可以允许所有的爬虫抓取.
Disallow 行列出的是要拦截的网页,以正斜线 (/) 开头,可以列出特定的网址或模式。要屏蔽整个网站,使用正斜线即可;要屏蔽某一目录以及其中的所有内容,在目录名后添加正斜线;要屏蔽某个具体的网页,就指出这个网页。就比如说屏蔽整个网站的话就是用
Disallow: /
Sitemap: 网站地图 告诉爬虫这个页面是网站地图,就比如CSDN的网站地图的网址是这个http://www.csdn.net/article/sitemap.txt,输入进去得到的界面如下所示
协议中还有可能会出现下面的这个东西
Crawl-delay:5
表示本次抓取后下一次抓取前需要等待5秒。
还有就是我们可能会看到有的协议是Allow和Disallow是一起用的,这个的含义的话,举个例子来说下吧,如下所示,这里表示的就是将拦截 qqlk目录内除file.html 之外的所有页面
User-agent: *
Allow: /qqlk/file.html
Disallow: /qqlk/
下面来看下CSDN的爬虫协议吧

抓取的代码如下,首先如果我们没有requests库的话我们要先去安装requests库,然后再去写代码
import requests
//请求url
r = requests.get('http://www.csdn.net/')
//查看状态码
print(r.status_code)
//输出内容,text可以自动的推测文本编码进行解码
print(r.text)关于网页数据的解析,我们可以通过BeautifulSoup来完成,它可以从HTML或者是XML文件中方便提取数据。下面是官方文档介绍
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
关于HTML解析器的选择我们最好都是去选择LXML,具体原因可以看文档的解释。

关于它的使用,这里就不展开了,可以去看官方文档。















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









