





 本文通过对比Gaussianprocess和Chemprop模型在四个公开数据集上的性能,详细研究了主动学习策略对样本选择、批量大小和标签噪声的影响,结果显示在数据稀疏时,GP模型表现优于Chemprop,且合适的初始批量和噪声处理对模型性能至关重要。
本文通过对比Gaussianprocess和Chemprop模型在四个公开数据集上的性能,详细研究了主动学习策略对样本选择、批量大小和标签噪声的影响,结果显示在数据稀疏时,GP模型表现优于Chemprop,且合适的初始批量和噪声处理对模型性能至关重要。
论文解读:《Benchmarking Active Learning Protocols for Ligand-Binding Affinity Prediction》
Prediction》)
文章地址:https://pubs.acs.org/doi/10.1021/acs.jcim.4c00220
DOI:https://doi.org/10.1021/acs.jcim.4c00220
期刊:Journal of Chemical Information and Modeling
数据:https://github.com/meyresearch/ActiveLearning_BindingAffinity
2022年影响因子/分区:5.6/二区
发布时间:2024年3月6日
1.文章概述
- 主动学习(Active learning,AL)已成为计算药物发现的强大工具,能够从庞大的分子库中识别顶级结合剂。
- 作者使用不同目标的四个亲和力数据集(TYK2、USP7、D2R、Mpro)来系统评估机器学习模型[高斯过程(Gaussian process,GP)模型和Chemprop(CP)模型]、样本选择协议的性能,以及基于描述模型总体预测能力的指标(R2、Spearman秩、均方根误差)以及前2%/5%粘合剂的准确识别(Recall,F1得分)的批量大小。
- GP模型和Chemprop模型在大数据集上都有类似的顶部绑定回忆,但当训练数据稀疏时,GP模型超过了Chemprop模型。
- 在不同的数据集上,更大的初始批量增加了两个模型的召回率以及整体相关性指标。但20或30种化合物的较小批量被证明是合乎需要的。
- 将人工高斯噪声添加到数据中,直到达到一定的阈值,仍然允许该模型识别具有最高得分化合物的聚类,过大的噪声(<1σ)会影响了模型的预测和开发能力。
2.背景
以前的 AL 研究使用相对结合自由能(Relative binding free energy, RBFE)作为他们选择的标记工具,并且只研究了单个靶标的配体。大型公共 RBFE 数据集的稀缺性以及生成它们的成本和难度也是一个障碍,上述研究都没有将成本视为选择协议的一个因素,从而导致初始批次或探索阶段非常大。
本研究的目的是通过使用四个公开可用的数据集进行基准测试,以严格的方式评估 AL 协议,主要关注的是 AL 设计,而不是用于标记数据的方法。作者主要目标是研究数据集的多样性和大小如何影响 AL 的功效,使用广泛的指标来获得整体视角,从传统的回归指标(例如 R2)来评估 ML 模型的整体性能,到前 2%/5% 绑定者的 Recall 和 F1 分数来评估模型的开发能力和活性化学空间的耗尽程度。
3.数据

在图 1B 中,TYK2 数据集的 UMAP 显示了清晰的簇,捕获了附加到核心支架的 R 基团的变化,可以看到大多数活性化合物位于上面的两个簇内。D2R 数据集似乎包含多种不同的化合物,每个化合物都有大量同属系列,每个系列有 10−20 个化合物。

4.方法
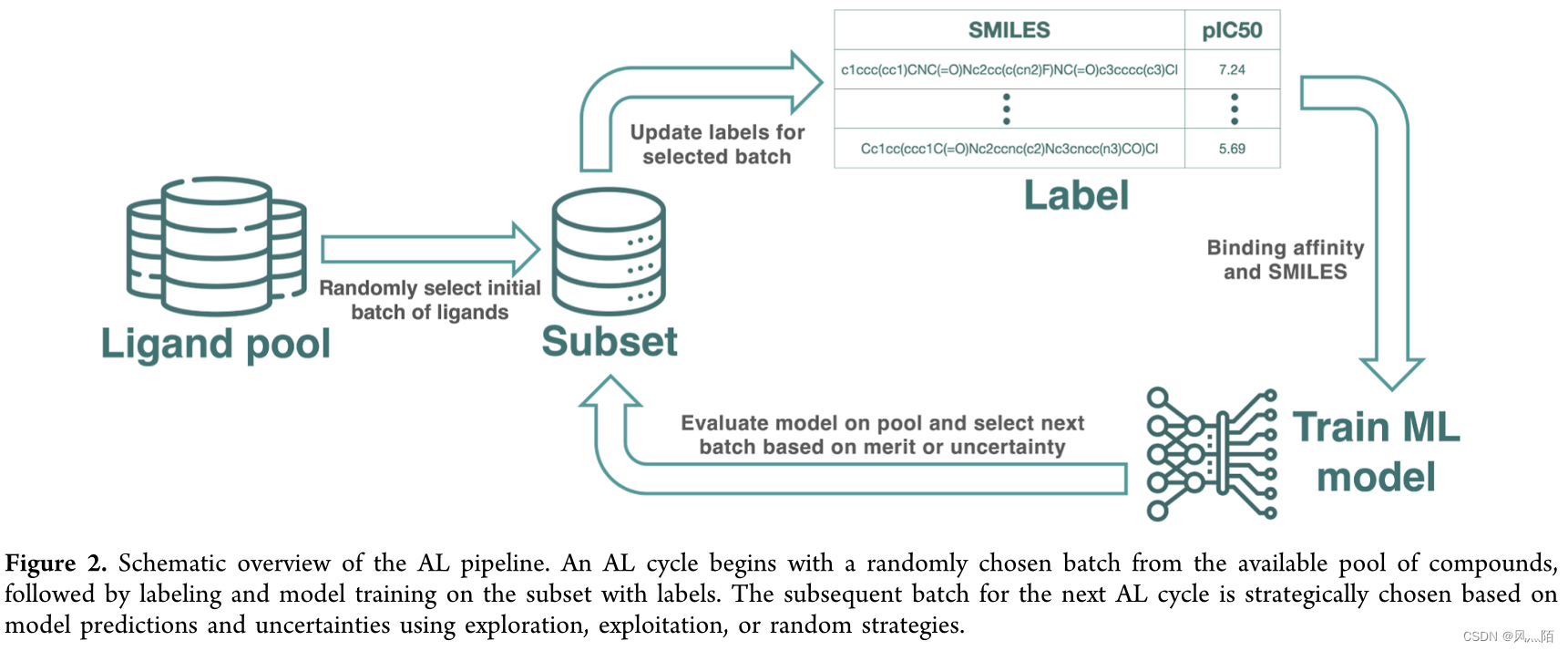
最初的一批化合物是随机选择的,通过 RBFE 计算获取所选化合物的标签。然后,在标记样本的子集上训练模型,并用于对未标记的数据进行预测。根据这些预测,选择一个战略性的样本子集进行标记,然后将这些新标记的样本合并到下一个 AL 周期的训练集中。
为确保对不同靶标的公平评估,作者始终在整个 AL 过程中获取总共 360 种化合物进行标记,无论数据集、模型或选择方案如何。
- GP Regression 基于 GPyTorch(1.10)实现。
- 配体是使用 OpenEye 的 OEChem 工具包(3.4.0.0)中的 ECFP0 指纹来特征化。
- 为了评估手性描述符对 GP 模型性能的影响,还使用 RDkit 生成了 Morgan 指纹,半径为 4。
- CP 是一种消息传递神经网络,专为分子特性预测而设计。该模型的运行方式是通过消息传递层迭代更新分子的原子和键特征(因此不依赖于分子指纹,例如 GP)。这使得模型能够捕获局部和全局结构信息。
- 评价指标:召回率和 F1 分数。
5.结果
5.1 模型基准测试
训练集由 20% 的数据组成,测试集由 80% 的数据组成。误差线代表这些折叠的 95% 置信区间。计算出的指标包括决定系数 R2 (A)、Spearman ρ (B) 以及测试集中前 2% © 和 5% (D) 样本的召回率。

5.2 AL策略影响
作者研究了模拟 AL 场景中批量大小、样本获取策略以及探索与利用权衡的影响。总是获取总共 360 种化合物进行标记,以公平地评估批次大小不同的选择方案。
5.2.1 初始样本的选择
初始选择后都会获取 60 多种化合物,目的是提高化学空间的覆盖范围,从而使有效的初始批量大小为 120。所有这些都是从随机选择的 60 个样本开始,并使用 30 种化合物的批量大小进行开发。
使用不同的 AL 协议在四个目标数据集中进行初始样本选择时,可实现前 2% 的召回率。(图4)
(1)“随机-利用”协议在切换到开发之前随机获取 60 种化合物;
(2)“随机-探索-利用”使用随机选择的初始批次后的预测不确定性获取另外 60 种化合物;
(3)“随机-随机-利用”从随机选择的 120 种化合物开始。

图 5A 显示了在所有 360 种选定化合物上训练的最终模型的相应 Spearman ρ 值。图 5B、C 显示了 UMAP,其中每个数据集中前 2% 的化合物分别使用 GP 或 CP 根据其采集频率(对不同协议和初始化的随机种子进行平均)进行着色。每个数据集的协议细分也可以在图 S8-S11 中找到,

5.2.2 批量大小的选择
作者评估了后续 AL 循环的四种不同批次大小,即 20、30、60 和 120。考虑到我们总共获取 360 种化合物的限制,较小的批次大小需要更多数量的 AL 循环才能达到此总数。比较表明,两种模型的所有数据集的召回率都会随着批量大小的减小而提高。

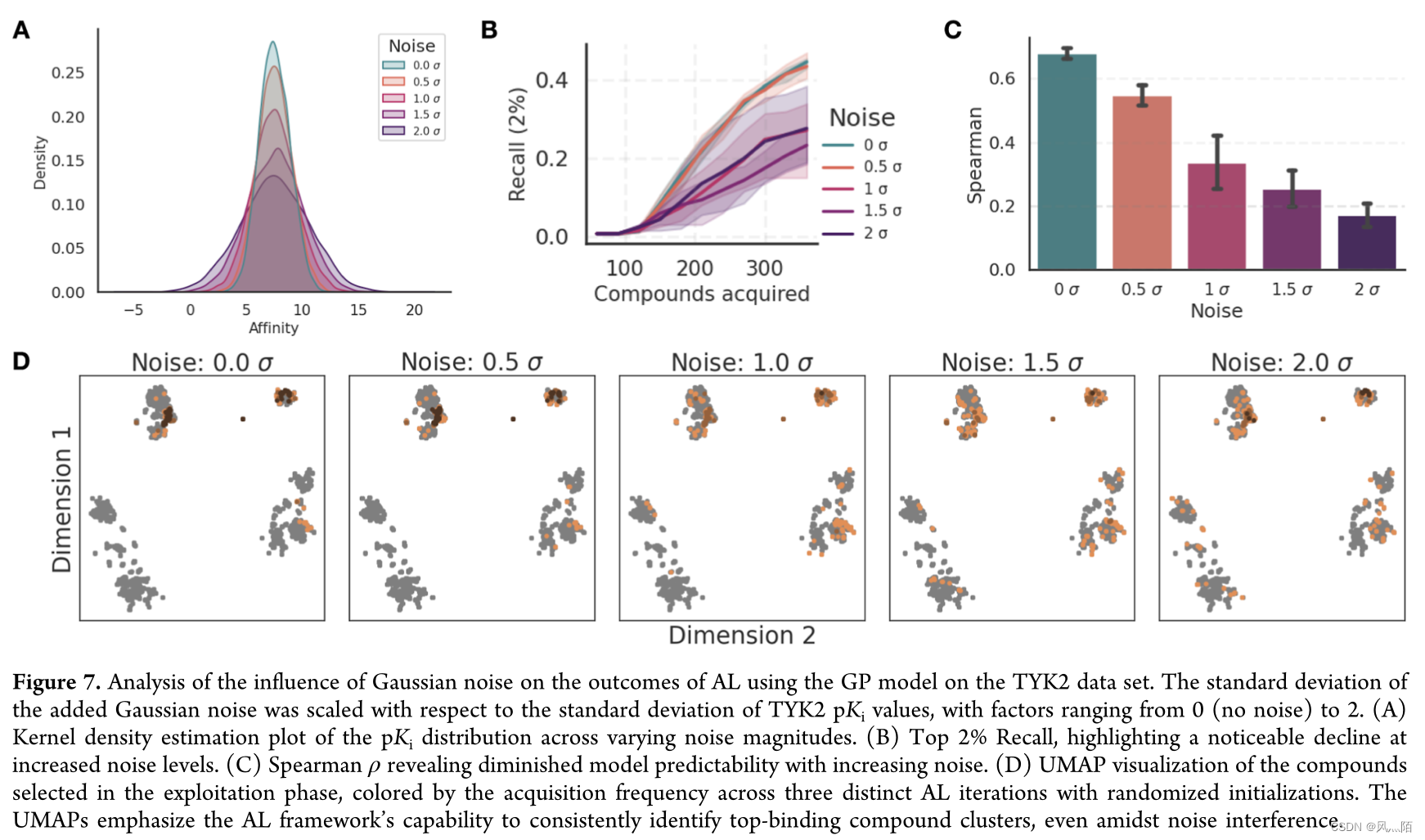
5.2.3 标签上的噪声建模
在TYK2数据集上使用GP模型分析高斯噪声对AL结果的影响。添加的高斯噪声的标准偏差相对于 TYK2 pKi 值的标准偏差进行缩放,因子范围从 0(无噪声)到 2。
UMAP 强调了 AL 框架即使在噪声干扰下也能一致识别顶部结合化合物簇的能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









