








一.集群基础环境
1. centos6.5 64 位 Hadoop 完全分布(http://blog.csdn.net/u011414200/article/details/47681711)
2. 集群说明
主节点 master4 10.6.3.40
数据节点 slave41 10.6.3.45
3.安装包
1.hadoop-2.2.0.tar.gz(http://pan.baidu.com/s/1slaoEbb)
2.spark-2.0.1-bin-hadoop2.4.tar.gz(http://pan.baidu.com/s/1c2sqfp2)
2.scala-2.10.6.tar.tgz(http://pan.baidu.com/s/1gfNYcmB)
二. scala 安装
1.将scala-2.10.6.tar.tgz 包解压 (本文是解压在/home/zl 下)
tar -zcvf scala-2.10.6.tar.gz2.修改环境变量
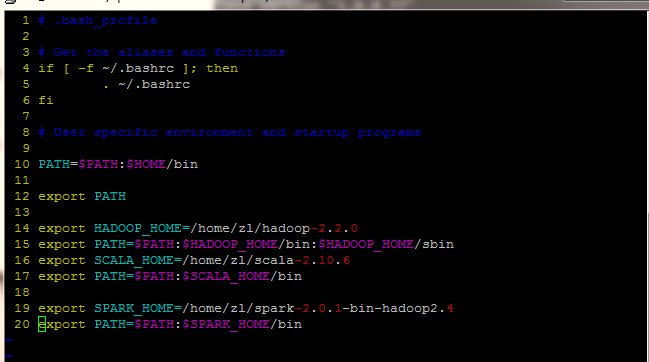
添加上图的16,17两行
注:此处环境变量是指当前用户下的环境变量
vim ~/.bash_profile 16 export SCALA_HOME=/home/zl/scala-2.10.6
17 export PATH=$PATH:$SCALA_HOME/bin
3.使环境变量生效
source ~/bash_profile4.验证是否安装成功
scala-version如下图,则表示安装成功

三.安装配置spark
1.将spark-2.0.1-bin-hadoop2.4.tar.gz 安装包放入指定目录(本文是在/home/zl下),并解压到当前用户目录下
tar -zcvf spark-2.0.1-bin-hadoop2.4.tar.gz -C ~/2.进入 spark-2.0.1-bin-hadoop2.4/conf 下
cd /home/zl/spark-2.0.1-bin-hadoop2.4/conf 3.配置 spark-env.sh
1.将 spark-env.sh.template 文件复制并重命名为spark-env.sh
cp spark-env.sh.template spark-env.sh2.编辑 spark-env.sh 文件
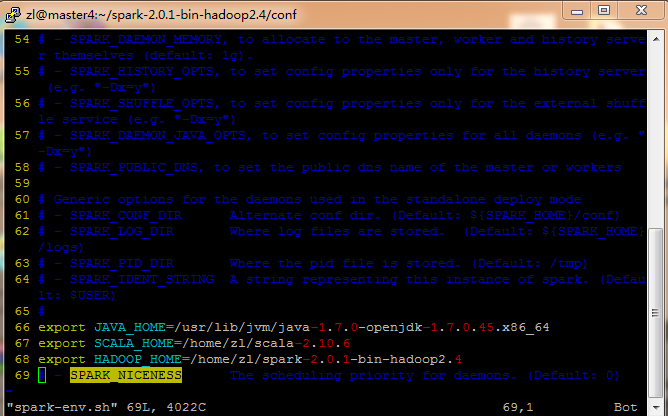
vim spark-env.sh加入如下代码
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64//java路径
export SCALA_HOME=/home/zl/scala-2.10.6//scala路径
export HADOOP_HOME=/home/zl/spark-2.0.1-bin-hadoop2.4//spark 路径
``
3.编辑 worker 节点的主机
vim slaves
添加 slave41
4.将配置好的spark分发到点据节点
scp -r spark-2.0.1-bin-hadoop2.4 master4@slave41:/home/zl
5.在主节点 master4 上 sbin 目录下启动 spark
sh start-all.sh

master4 看到 master 进程
slave 看到 worke进程

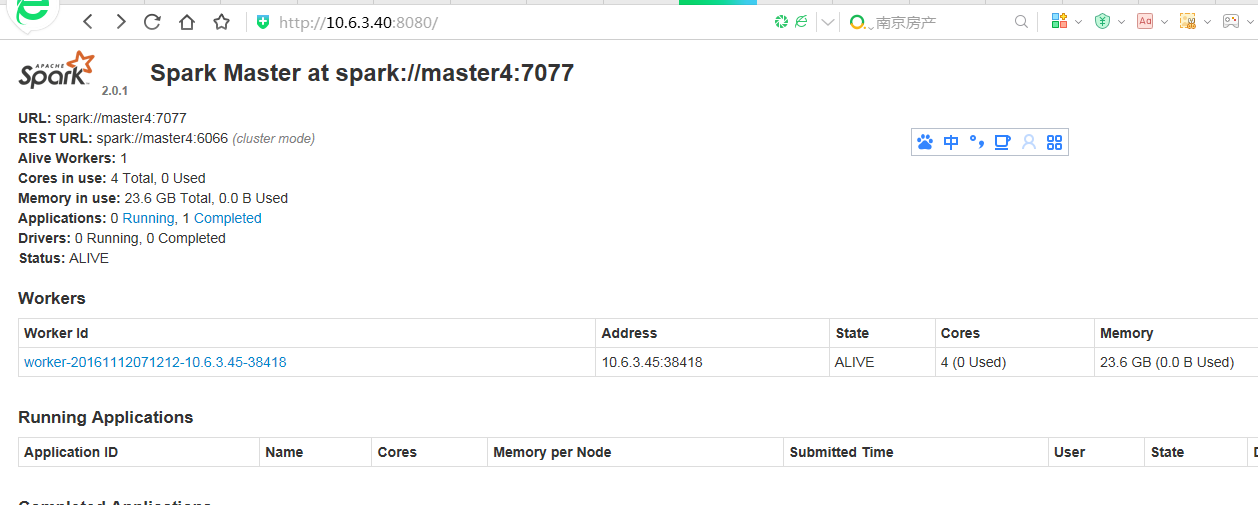
在10.6.3.40:8080界面
ok,基于 yarn 的 spark 安装成功!















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









