









- 读取文件usa_election.txt
- 查看文件样式及基本信息
- 指定数据截取,将如下字段的数据进行提取,其他数据舍去:
- cand_nm :候选人姓名
- contbr_nm :捐赠人姓名
- contbr_st :捐赠人所在州
- contbr_employer :捐赠人所在公司
- contbr_occupation :捐赠人职业
- contb_receipt_amt :捐赠金额
- contb_receipt_dt :捐赠日期
- 使用统计学指标快速扫描数值型属性的概要
- 空值处理。可能因为忘记填写或者保密等等原因,相关 字段出现了空值,将其填充为NOT PROVIDE
- 异常值处理。将捐款金额<=0的数据删除
- 新建一列为各个候选人所在党派party
- 查看party这一列中有哪些不同的元素
- 统计party列中各个元素出现次数
- 查看各个党派收到的政治献金总数contb_receipt_amt
- 查看具体每天各个党派收到的政治献金总数contb_receipt_amt
- 将表中日期格式转换为’yyyy-mm-dd’。
- 查看老兵(捐献者职业)DISABLED VETERAN主要支持谁
附件下载地址:usa_election.txt - 蓝奏云
绪言:这个数据分析题目数据量够大,考察了pandas对于数据分析的很多基本用法,个人认为非常适合初期练习使用
- 读取文件usa_election.txt:
- 查看文件样式及基本信息:
这个不用多说,上来导包导入文件,看一下文件的开头

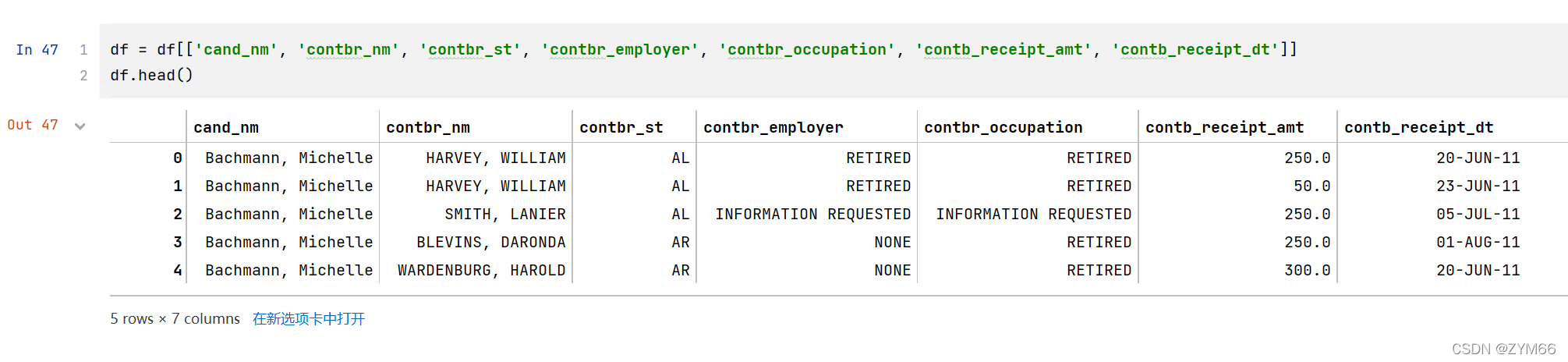
3.指定数据截取,将如下字段的数据进行提取,其他数据舍去:
- cand_nm :候选人姓名
- contbr_nm :捐赠人姓名
- contbr_st :捐赠人所在州
- contbr_employer :捐赠人所在公司
- contbr_occupation :捐赠人职业
- contb_receipt_amt :捐赠金额
- contb_receipt_dt :捐赠日期
传统手艺不能忘,取多列的基本操作
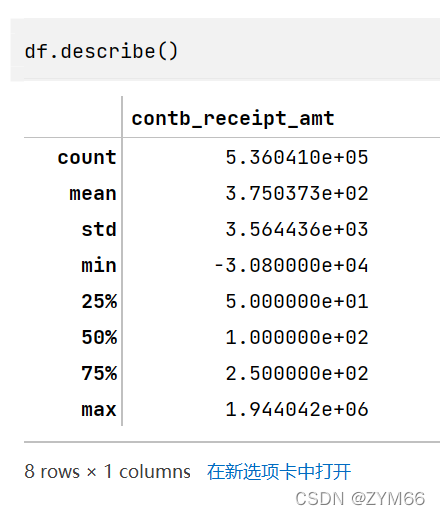
4.使用统计学指标快速扫描数值型属性的概要
一个方法搞定
5.空值处理。可能因为忘记填写或者保密等等原因,相关 字段出现了空值,将其填充为NOT PROVIDE
在行上创立一个规则,为有空值的行返回True
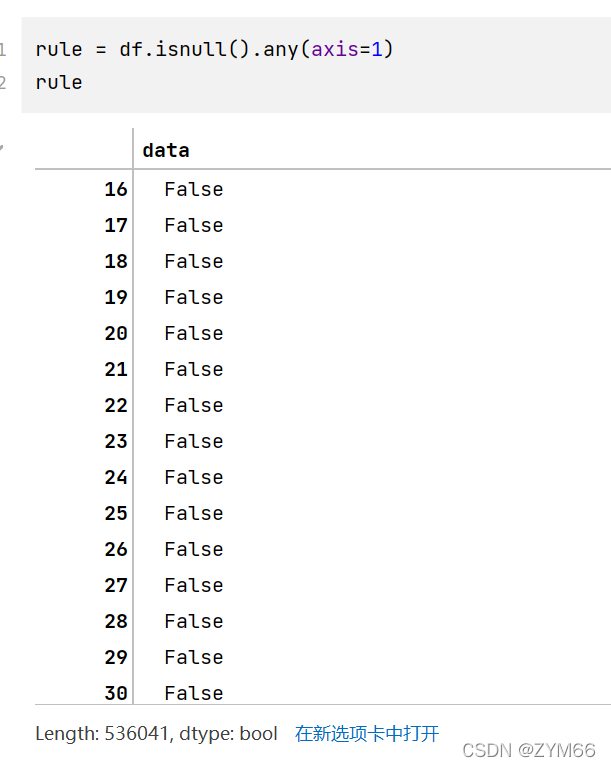
把空行的索引取出来

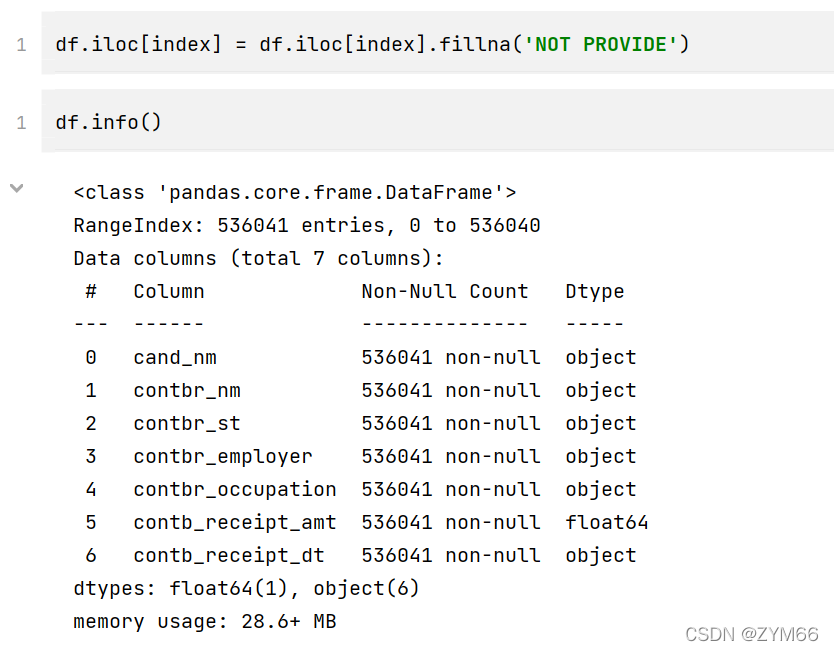
利用先前建立的规则批量取行,并填充为指定信息。这里的知识点是取行的方法和取行的规则还有就是nan值的填充
6.异常值处理。将捐款金额<=0的数据删除
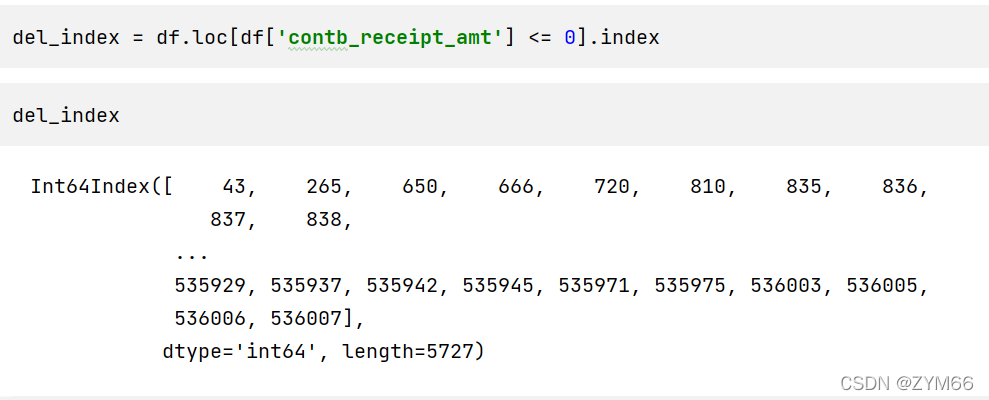
如法炮制,还是根据规则把索引取出

删除使用drop方法,删完后注意检查空行
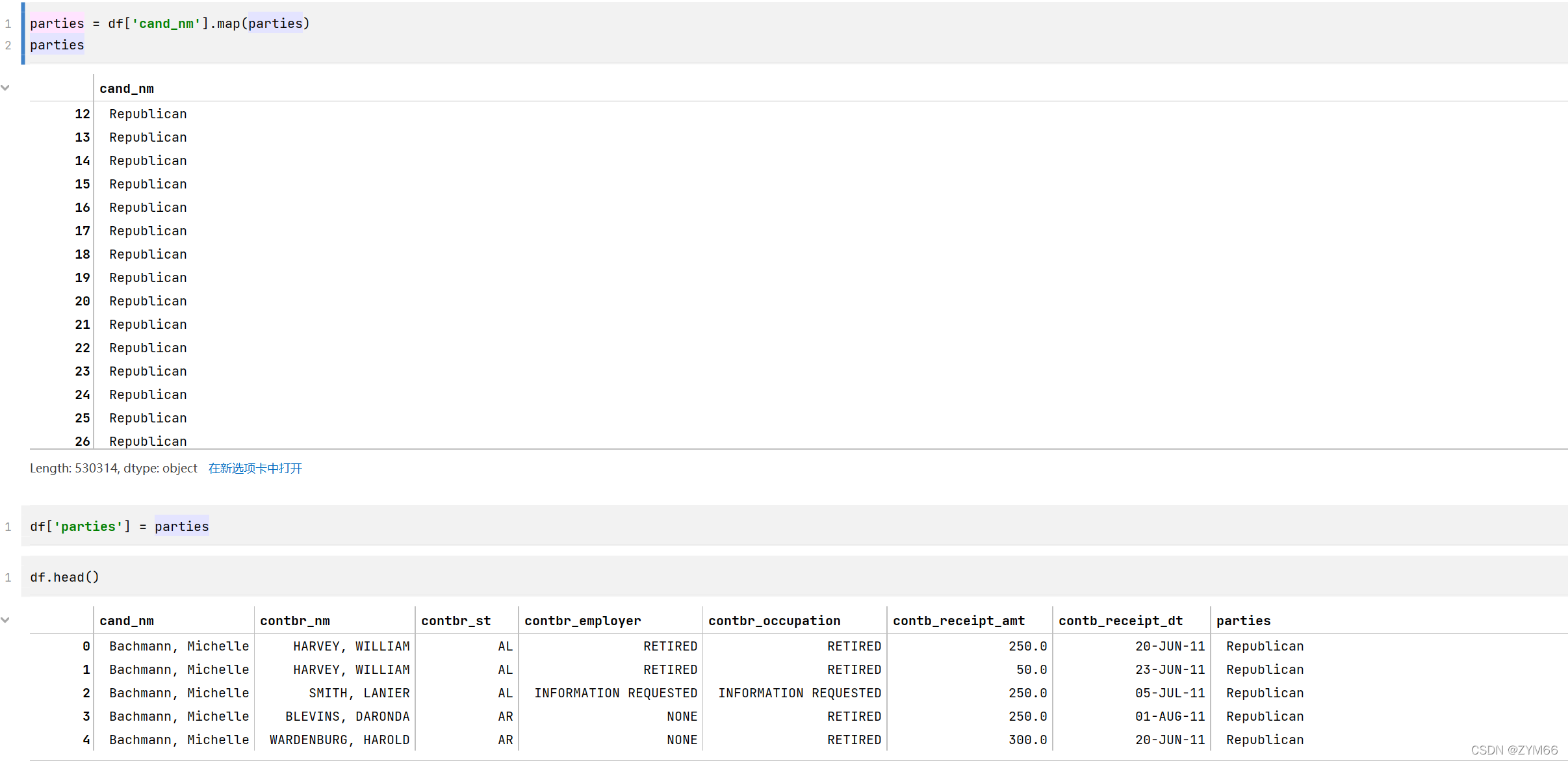
7.新建一列为各个候选人所在党派party
这个考察映射
parties = {
'Bachmann, Michelle': 'Republican',
'Romney, Mitt': 'Republican',
'Obama, Barack': 'Democrat',
"Roemer, Charles E. 'Buddy' III": 'Reform',
'Pawlenty, Timothy': 'Republican',
'Johnson, Gary Earl': 'Libertarian',
'Paul, Ron': 'Republican',
'Santorum, Rick': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Huntsman, Jon': 'Republican',
'Perry, Rick': 'Republican'
}先建立一个映射表确定映射关系,然后用map函数确立映射关系,直接在原有的数据后边加一列。
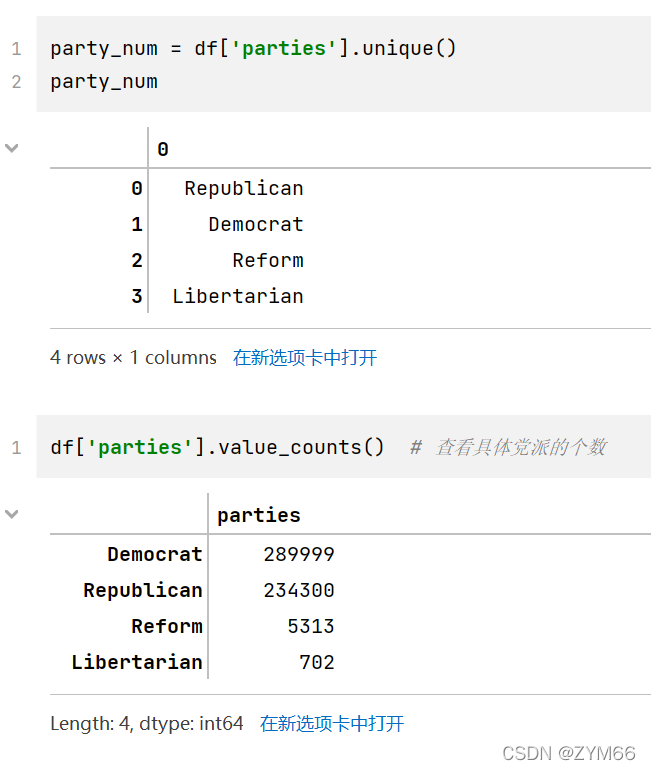
- 查看party这一列中有哪些不同的元素
- 统计party列中各个元素出现次数
这两个操作用两个方法就可以解决,考察方法的使用
- 查看各个党派收到的政治献金总数contb_receipt_amt
- 查看具体每天各个党派收到的政治献金总数contb_receipt_amt
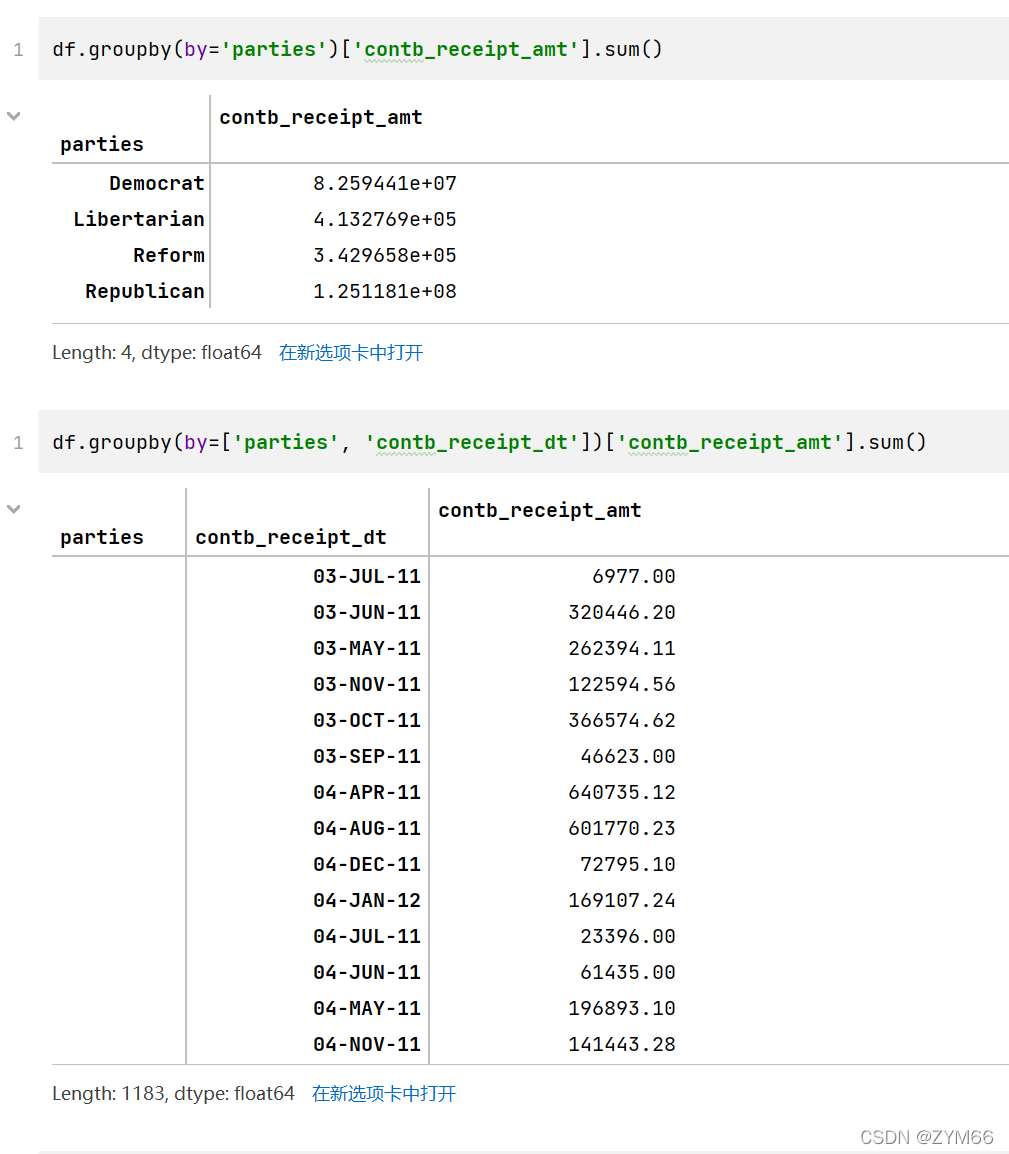
这两题考察分组,使用groupby函数可以轻松解决
- 将表中日期格式转换为’yyyy-mm-dd’。
这个就是一个日期的转换,pandas中有对应的方法
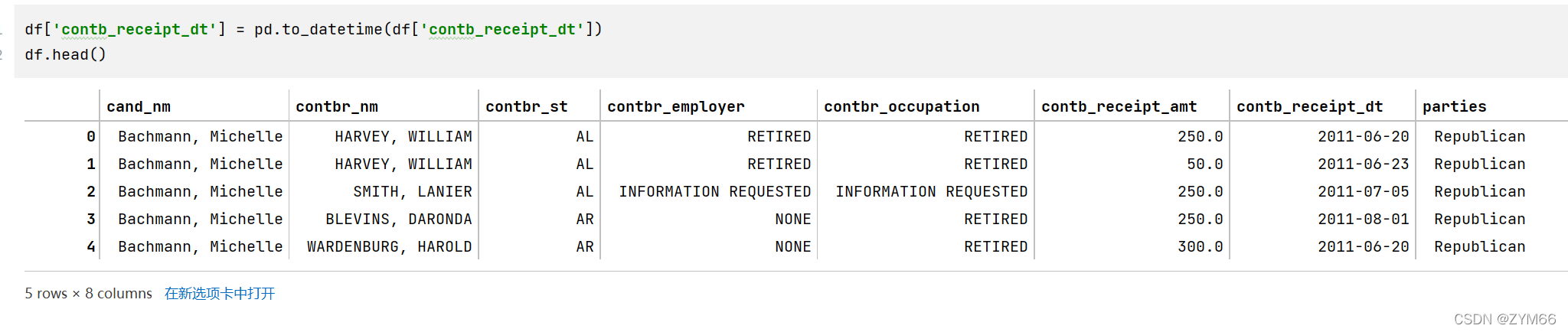
- 查看老兵(捐献者职业)DISABLED VETERAN主要支持谁
最后一题,咱们先把老兵挑出来
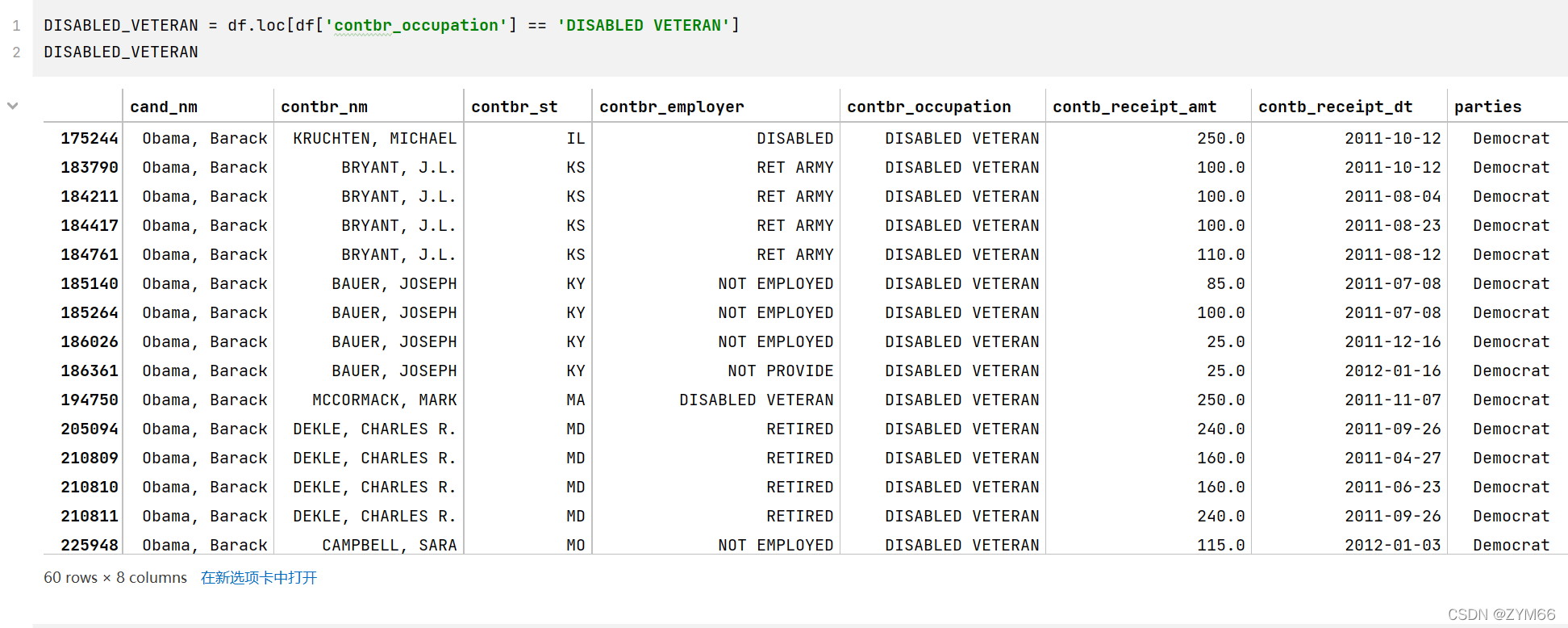
挑出来后,再利用分组的知识进行金额叠加即可
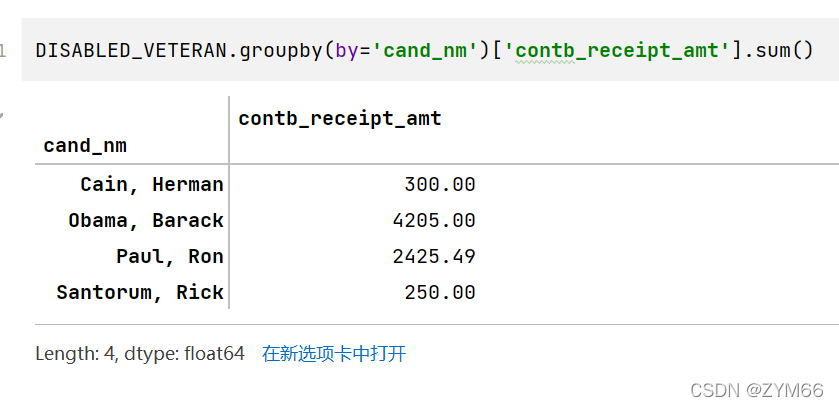
可以看出最支持的是:Obama, Barack


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









