





numpy简介
numpy(Numerical Python)是python语言的扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供了大量的数学函数库
作用
Numpy是一个运行速度非常快的数学库,主要用于数组计算
安装
可以使用如下命令在命令行安装即可
pip install numpy 或 conda install numpy
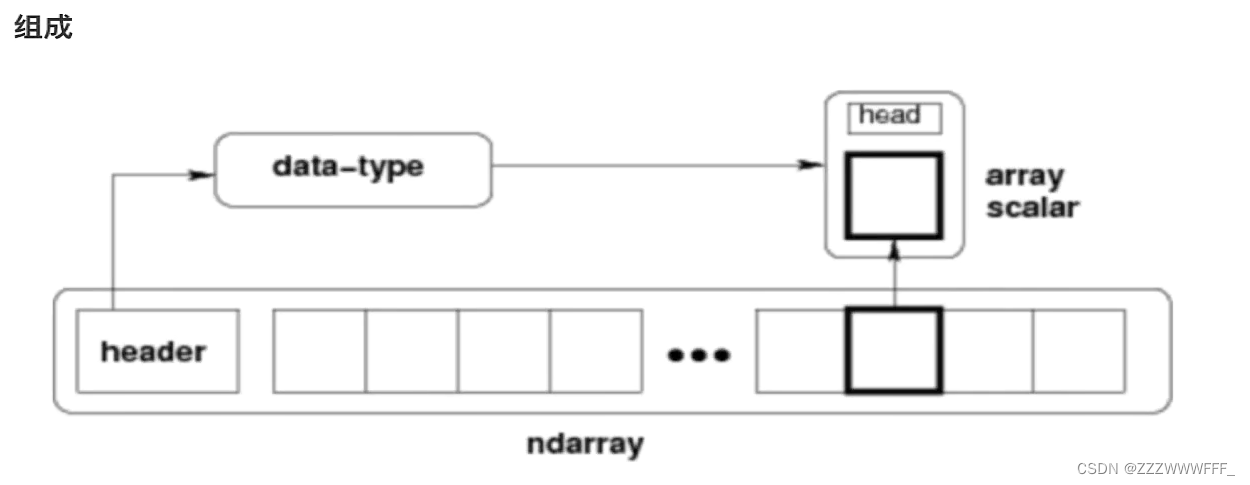
Ndarray简介
- Numpy最重要的一个特点是其N维数组对象ndarray,它是一系列同类型数据的集合,以0开始为集合中元素的索引
- Ndarray对象是用于存放同类型元素的多维数组
- Ndarray中的每一个元素在内存中都有相同存储大小的区域
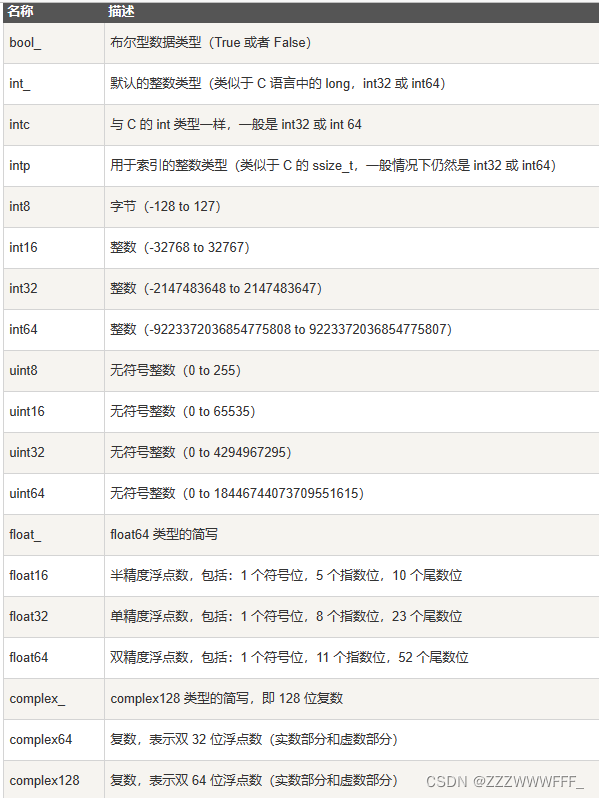
numpy数据类型
numpy支持的数据类型要比python内置的数据类型要多很多,基本上可以与C语言的数据类型对应上,其中部分类型对应为python内置类型
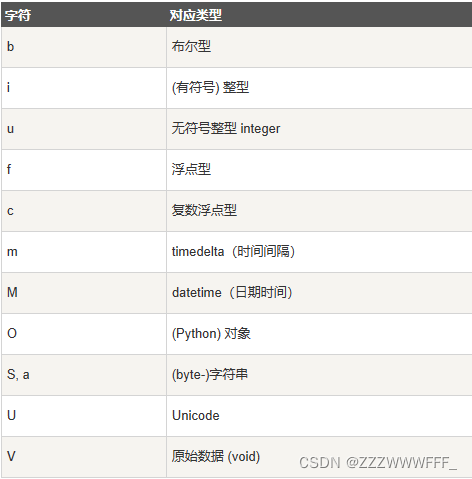
numpy的数据类型实际上是dtype对象的实例,并对应唯一的字符,包括np.float32,np.bool_等等
创建对象
numpy默认ndarray的所有元素类型是相同的,如果传入的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
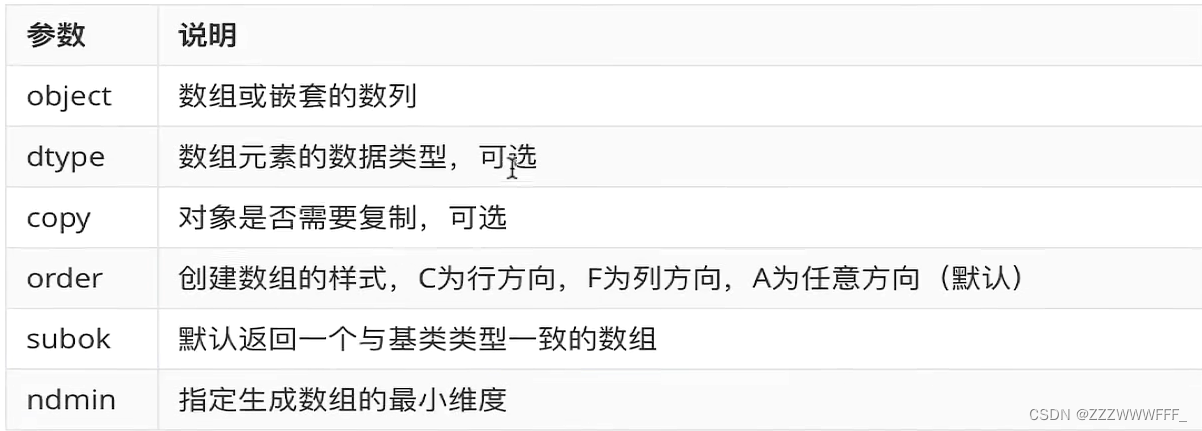
1. array()函数
创建一个一维数组
输出如下
如果输入类型不同
则会根据优先级更新数据类型
更多例子如下图所示
2. asarray()函数
该函数作用与array()函数类似,只不过参数只有三个
具体例子如下图所示
python数据分析与可视化学习简记(更新中)
最新推荐文章于 2024-07-21 23:25:11 发布



































 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











