







1 IDEA的Flink开发环境搭建
1.1 下载Java JDK 1.8
Mac 中默认有安装,我这里不再展示。
1.2 Flink 下载
Flink官网下载地址
随便选个下载,本文以Flink 1.13.1为例,注意链接名称“for scala 2.12”,后面在idea下载scala时必须下载scala 2.12版。
下载完成解压,一会使用。


1.3 IDEA 下载
IDEA官网下载地址
个人觉得破解麻烦,干脆用了社区版,可自行选择。

破解版链接
1.4 scala
打开idea,创建项目。
File——>ProjectStrure——>Libraries
点击“+”,选择Scala SDK,点击download,下载与Flink一致的scala版本。完成。

2 Flink WordCount
2.1建立项目,并导入相关包
参考文章:干货:Flink在IDEA上配置并且运行
1 新建maven项目,拉到最下边找到scala-archetype-simple

。。。
archetype参考文献:
Maven 三种archetype(模板原型)说明
archetype也就是原型,准确说是一个项目模板,我们可以根据该模板来生成项目。
GroupId和ArtifactId参考文献:Maven中的GroupID和ArtifactID指的是什么?
GroupId和ArtifactId被统称为“坐标”是为了保证项目唯一性而提出的,如果你要把你项目弄到maven本地仓库去,你想要找到你的项目就必须根据这两个id去查找。 GroupId一般分为多个段,这里我只说两段,第一段为域,第二段为公司名称。域又分为org、com、cn等等许多,其中org为非营利组织,com为商业组织。举个apache公司的tomcat项目例子:这个项目的GroupId是org.apache,它的域是org(因为tomcat是非营利项目),公司名称是apache,ArtifactId是tomcat。 比如我创建一个项目,我一般会将GroupId设置为cn.mht,cn表示域为中国,mht是我个人姓名缩写,ArtifactId设置为testProj,表示你这个项目的名称是testProj,依照这个设置,在你创建Maven工程后,新建包的时候,包结构最好是cn.zr.testProj打头的,如果有个StudentDao[Dao层的],它的全路径就是cn.zr.testProj.dao.StudentDao
。。。
此时我们看到我们的工程的环境和依赖包是这样的:

但是现在还不能进行开发,要进行目录的设置才行:main右键,Make Drectory As–Source Root。
2.2 在main包中创建flink程序

以WordCount为例,写入如下代码,注意导入的包名:
package scala.org.example
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object FlinkTest {
/** Main program method */
def main(args: Array[String]) : Unit = {
// get the execution environment
val env:StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
val text:DataStream[String] = env.socketTextStream("127.0.0.1",9000,'\n')
// parse the data, group it, window it, and aggregate the counts
val windowCounts = text.flatMap (_.split("\\s") )
.map((_,1))
.keyBy(0)
.sum(1)
// print the results with a single thread, rather than in parallel
windowCounts
.print()
.setParallelism(1)
env.execute("Socket Window WordCount")
}
/** Data type for words with count */
case class WordWithCount(word: String, count: Long)
}
2.3 运行Flink程序
使用终端进入Flink 解压缩后的jar包,执行bin文件夹下的start-cluster.sh命令,如下:

使用 netcat 启动一个本地server,9000是程序中使用的端口:
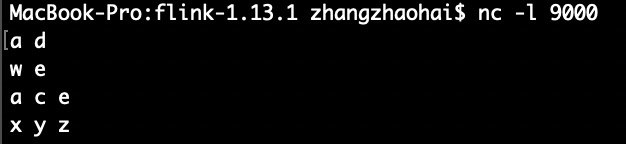
执行IDEA中的WordCount程序,边在终端中输入,flink程序会边统计。至此第一个Flink程序搭建完成。

















 2458
2458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











