








1 Mapper阶段输入
1.1 输入文件 —— 切片的形成过程
- 不断迭代节点列表,逐个节点 (以数据块为单位) 形成切片(Local Split)
- 如果maxSplitSize == 0,则整个节点上的Block数据形成一个切片
- 如果maxSplitSize != 0,遍历并累加每个节点上的数据块,如果累加数据块大小 >= maxSplitSize,则将这些数据块形成一个切片。继续该过程,直到剩余数据块累加大小 < maxSplitSize 。则进行下一步
- 如果剩余数据块累加大小 >= minSplitSizeNode,则将这些剩余数据块形成一个切片。继续该过程,直到剩余数据块累加大小 < minSplitSizeNode。然后进行下一步,并这些数据块留待后续处理
- 不断迭代机架列表,逐个机架 (以数据块为单位) 形成切片(Rack Split)
- 遍历并累加这个机架上所有节点的数据块 (这些数据块即上一步遗留下来的数据块),如果累加数据块大小 >= maxSplitSize,则将这些数据块形成一个切片。继续该过程,直到剩余数据块累加大小<maxSplitSize。则进行下一步
- 如果剩余数据块累加大小 >= minSplitSizeRack,则将这些剩余数据块形成一个切片。如果剩余数据块累加大小 < minSplitSizeRack,则这些数据块留待后续处理
- 遍历并累加所有Rack上的剩余数据块,如果累加数据块大小 >= maxSplitSize,则将这些数据块形成一个切片。继续该过程,直到剩余数据块累加大小< maxSplitSize。则进行下一步
参考文献:Hive之MapReduce性能优化
若执行时,发现map阶段很慢,并且map过多,并且执行时间多数不超过1分钟,建议通过参数,划分文件的大小,合并小文件。如:

set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 将多个“小文件”合并为一个"切片"(在形成切片的过程中也考虑同一节点、同一机架的数据本地性),让每一个Mapper任务可以处理更多的数据,从而提高MR任务的执行速度。
set mapreduce.input.fileinputformat.split.minsize=516000000; -- 516M -- 切片大小最小值
set mapreduce.input.fileinputformat.split.maxsize=1280000000; -- 1280M -- 切片大小最大值
set mapreduce.input.fileinputformat.split.minsize.per.node=516000000; -- 同一节点的数据块形成切片时,切片大小的最小值。
set mapreduce.input.fileinputformat.split.minsize.per.rack=516000000; -- 同一机架的数据块形成切片时,切片大小的最小值。
这样可以减少map的个数,减少中间临时文件的产生,也减少reduce阶段的任务数和产生的文件数。
1.2 Mapper的输入 —— InputFormat类
参考文献:
[1] MapperReducer任务之Map的输入、输出
MR的数据源可以来自HDFS文件、查询数据库的输出等。文件的类型也没有规定特定的格式,例如也可以是网页。
那么MR框架是如何读出不同类型的数据,然后形成键值对并作为Mapper(map()方法)的输入呢,这就是InputFormat的作用。不同的数据源,不同的数据类型、数据格式,需要采用不同的InputFormat类型,所以InputFormat是一个抽象类。
public abstract class InputFormat<K, V> {
public abstract List<InputSplit>
getSplits(JobContext context)
throws IOException, InterruptedException;
public abstract RecordReader<K,V>
createRecordReader(InputSplit split,TaskAttemptContext context)
throws IOException,InterruptedException;
}
InputFormat描述了MR程序的输入规则,其中getSplits()返回一个InputSplit类的实例的列表,一个InputSplit一个分片对应一个Mapper。如果给定Mapper的数量,那么分片的数量也就随之确认了。但如果不给定Mapper的数量,如何进行分片就是不同类型的InputFormat需要考虑的问题了。InputSplit是一个接口:
public interface InputSplit extends Writable {
long getLength() throws IOException;
String[] getLocations() throws IOException;
}
InputSplit包含了以字节数描述的长度和一组存储位置(主机名)。分片并不包含数据本身,而是指向数据的引用。存储位置供MR框架使用以便将map任务尽量放在分片数据的附近,而分片大小用来排序分片,以便处理最大的分片,从而最小化作业时间。
map任务将输入分片传给InputFormat中的createRecordReader来获得这个分片的RecordReader,RecordReader即记录阅读器,所以实际上是RecordReader来将原始数据转换成输入map()方法的键值对。同样RecordReader中也不存放数据本身,而是指向数据的引用。每种InputFormat都有配套的RecordReader,Mapper中对于context.nextKeyValue()等方法的调用实际上最终是由RecordReader来实现的。
实现Inputformat抽象类的子类如下:

如果是基于对文件的操作,通常使用的是FileInputFormat子类。
//FileInputFormat的指定泛型类型与map()的输入键值对类型一致,即与k1与v1类型一致
public abstract class FileInputFormat<K, V> implements InputFormat<K, V>
FileInputFormat会根据文件大小,进行逻辑上的切分,切分为一个个的分片,并用InputSplit记录分片的信息,默认情况下与块大小一致。在getSplit()中可见计算分片大小的部分逻辑:
//默认最小分片大小为1,可以通过mapreduce.input.fileinputformat.split.minsize设置
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
//默认最大分片大小为Long的最大值,可以通过mapreduce.input.fileinputformat.split.maxsize设置
public static final String SPLIT_MAXSIZE =
"mapreduce.input.fileinputformat.split.maxsize";
public List<InputSplit> getSplits(JobContext job) throws IOException {
//...
//若指定文件可分片
if (isSplitable(job, path)) {
//文件块大小,HDFS默认为128M
long blockSize = file.getBlockSize();
//分片大小为块大小(128M),最小分片大小(1B),最大分片大小(Long.MAX_VALUE B)的中间值,即128M
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
由上可知可知,getSplit()对文件进行逻辑切分时,分片的大小由分片最小字节数B,分片最大字节数、块大小三个参数决定,分片最终大小为三个数的中间值,这也就是一个mapper的输入文件大小。
若要增加分片大小,可以提供更大的HDFS块(通过dfs.blocksize来设置),或者使最小分片大小的值大于块大小,但代价是增加了本地操作;若要减小分片大小,可以通过使最大分片大小的值小于块大小实现。
1.3 Mapper输入阶段可能出现的问题及优化方法
1.3.1 小文件过多
表现:Hive执行任务时,发现Map端的任务过多,且执行时间多数不超过一分钟。
原因:小文件过多,又因为一个文件对应一个map任务,所以map任务过多。这种情况,map任务的启动过程,会耗费大量时间。
解决方法:合并小文件。相关参数有:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 将多个小文件打包成一个InputSplit提供给一个Map处理,另外,它会考虑数据的存储位置。(注意不是把机器上的文件合并再存储回机器上,而是读完多个小文件后交给用一个map。)
set mapred.max.split.size=256000000;
set mapreduce.input.fileinputformat.split.minsize=516000000; -- 单个文件最小 516 M
set mapreduce.input.fileinputformat.split.maxsize=1280000000; -- 单个文件最大 1280 M
set mapreduce.input.fileinputformat.split.minsize.per.node=516000000;
set mapreduce.input.fileinputformat.split.minsize.per.rack=516000000;
set mapred.max.split.size=256000000; //合并的每个map大小
Set mapred.min.split.size.per.node=256000000 //控制一个节点上split的至少的大小,按mapred.max.split.size大小切分文件后,剩余大小如果超过mapred.min.split.size.per.node则作为一个分片,否则保留等待rack层处理
Set mapred.min.split.size.per.rack=256000000 // 控制一个交换机下split至少的大小,合并碎片文件,按mapred.max.split.size分割,最后若剩余大小超过 Mapred.min.split.size.per.rack则作为单独的一分片
最后合并不同rack下的碎片,按mapred.max.split.size分割,剩下的碎片无论大小作为一个split
HDFS的默认文件块大小是128M,如果在Hive执行任务时,发现Map端的任务过多,且执行时间多数不超过一分钟,建议通过参数,划分(split)文件的大小,合并小文件。
1.3.2 单个文件过大
2 Mapper阶段计算
3 Mapper阶段输出
参考文献:
[1] Mapper阶段的输出之MapOutputBuffer、环形缓冲区工作原理
[2] Hive之MapReduce性能优化
[3] MapperReducer任务之Map的输入、输出
Mapper的输出中有两个重要部分:一是collector,负责收集Mapper输出并将其交付给Reducer;二是partitioner,决定了应该将具体的输出交付给哪一个Reducer。
3.1 collector
mr程序ReduceTask的数量默认是1个,可以通过job.setNumReduceTasks(num)修改个数。
输出记录在发送给reducer之前,会被MR框架进行排序,其实是通过collector中的缓冲输出流MapOutputBuffer实现排序的,MapOutputBuffer是MapTask的一个内部类。
Mapper的输出是通过其RecordWriter写出去的,此RecordWriter就是一个负责收集Mapper输出的Collector,而MapOutputBuffer就是一种对流经键值对排序的Collector。
MapOutputBuffer是MapTask的一个内部类,重要属性如下:
class MapOutputBuffer<K extends Object, V extends Object>
implements MapOutputCollector<K, V>, IndexedSortable {
private int partitions; //输出数据的分区数,即Reducer数
byte[] kvbuffer; //键值对缓冲区
private IndexedSorter sorter; //用于排序的Sorter对象
final BlockingBuffer bb = new BlockingBuffer(); //实际上是一个输出流,提供将缓冲区对键值对的序列化和写入的操作方法,核心是Buffer类
final SpillThread spillThread = new SpillThread(); //专门将缓冲区内容写入Spill文件的线程
private FileSystem rfs; //存放spill文件的文件系统
(1) 输出键值对到环形缓冲区
MapOutputBuffer的核心就在于其内部定义的Buffer类(new BlockingBuffer()返回的是Buffer类)和一个充当缓冲区存储介质的字节数组kvbuffer。前者提供了对缓冲区进行的操作,而后者是物理意义上的缓冲区。
在之前新建Collector时,有对collector.init()的调用,其实底层就是对MapOutputBuffer.init()的调用,在这个方法中可了解到输出缓冲区的大致构成。
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
partitions = job.getNumReduceTasks(); //分区数=Reducer数
rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw(); //spill文件所在目录
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8); //Spill"门槛值",默认80%
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100); //用于排序的缓冲区大小,默认100M
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job); //用于排序的算法,默认为QuickSort
int maxMemUsage = sortmb << 20;
maxMemUsage -= maxMemUsage % METASIZE; //METASIZE为元数据长度,为16。maxMemUsage是16的倍数
kvbuffer = new byte[maxMemUsage]; //创建物理缓冲区,默认大小为100M
bufvoid = kvbuffer.length;
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer(); //先将kvbuffer包装成一个字节缓冲区ByteBuffer,并设置此缓冲区中存储证书时的字节顺序
//并建立了一个用于整数缓冲区IntBuffer的视图
setEquator(0); //将分割点设置在0位上
bufstart = bufend = bufindex = equator; //ByteBuffer视图为空
kvstart = kvend = kvindex; //IntBuffer视图为空
maxRec = kvmeta.capacity() / NMETA; //最大记录数是IntBuffer容量/16
//Mapper输出的kv都是内存中的对象,所以需要序列化
serializationFactory = new SerializationFactory(job); //用于对键值对的序列化
keySerializer = serializationFactory.getSerializer(keyClass); //对Key序列化
keySerializer.open(bb); //通过bb,即BlockingBuffer用于key序列化后的输出
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
spillThread.setDaemon(true); //Spill线程是一个守护线程
spillThread.start()
Mapper每次调用map()方法锁输出的键值对首先就存放在kvbuffer中,不过除了kv对,还要存放它们的元数据:key在缓冲区中的起点,value的起点,value的长度以及kv对所属的partition(分区,对应后续传输给哪个reducer)。其中kv的值是按字节存放的,而元数据是作为整数存放的,所以会有一个字节缓冲区ByteBuffer还有整数缓冲区IntBuffer。为了方便整数操作,这里为kvbuffer创建了一个作为IntBuffer的视图。
(2) 缓冲区写满80%,排序后溢出(spill)到文件系统
Spill线程SpillThread专门负责在缓冲区被写满后将其内容spill(溅出)到文件系统的spill文件中,一个Mapper的输出可能会形成多个spill文件。
Spill线程spillThread一经创建并启动就在run()方法中进入循环,一有通知就从spillReady.await()中被唤醒,进行一次sortAndSpill(),**把缓冲区的内容排序(按照分区partition和k值)**并溅到Spill文件中,以腾出缓冲区空间,每个Spill文件中都是经过排序后的kv对。
protected class SpillThread extends Thread {
public void run() {
while (true) {
while (!spillInProgress) {
spillReady.await();
}
try {
sortAndSpill();
}
//...
//计算环形缓冲区中数据的长度,并加上每一个分区的头长度150字节
final long size = distanceTo(bufstart, bufend, bufvoid) + partitions * APPROX_HEADER_LENGTH;
//用于创建溢写文件的数据流
FSDataOutputStream out = null;
try {
//溢写索引块,多次Spill需要记录上一次溢写的相关索引
final SpillRecord spillRec = new SpillRecord(partitions)
// 创建小的溢写文件
final Path filename = mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename);
//计算共有几项元数据
final int mstart = kvend / NMETA;
//计算第一项元数据在整个缓冲区中的下标
final int mend = 1 + // kvend is a valid record(kvstart >= kvend? kvstart: kvmeta.capacity() + kvstart) / NMETA;
//对元数据进行排序,底层为QuickSort.sort()。**按照分区索引从小到大,key值从小到大排序**
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
for (int i = 0; i < partitions; ++i) {
//接下来就是对每一个分区进行写入到溢写文件中的操作,其中会判断是否需要加密和**是否运行combiner**
}
}
在逐项写出kv对时,如果有需要有Combiner,还可以插入Combiner环节。最后在Spill过程中会产生一个索引块,如果索引块太大,还需要创建并写入Spill索引文件,否则索引信息留在内存中。
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// 创建spill索引文件
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
// 否则索引信息留在内存中
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
++numSpills;
}
(3) Spill文件的合并
参考文献:MapReduce:shuffle阶段之Mapper输出
当Mapper中不再有数据产出时,会关闭输入和输出通道。也就意味中会关闭Collector,也就是MapOutputBuffer,关闭前需要冲刷一下。当缓冲区已空,即所有数据都已在小的溢写文件中,接下来就需要把所有spill文件的归并(Merge,各spill文件内部都是排好序的,此处再进行一次归并排序)到单个大的溢写文件中,以备分发给各个Reducer,这就是一个MapTask在整个Map阶段的输出。
MapOutputBuffer.mergeParts():
//每次Spill都有个小的溢写文件,所以数组大小为spill的次数
final Path[] filename = new Path[numSpills];
//统计所有这些文件合并后的大小
for(int i = 0; i < numSpills; i++) {
filename[i] = mapOutputFile.getSpillFile(i);
finalOutFileSize += rfs.getFileStatus(filename[i]).getLen();
}
//如果只有一次Spill
if (numSpills == 1) {
//直接更名,在原名上加上后缀file.out
sameVolRename(filename[0],
mapOutputFile.getOutputFileForWriteInVolume(filename[0]));
//索引块缓存已空
if (indexCacheList.size() == 0) {
//spill索引文件改名
sameVolRename(mapOutputFile.getSpillIndexFile(0),
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]));
//索引块缓存中还有索引记录,需要写到索引文件中
} else {
indexCacheList.get(0).writeToFile(
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]), job);
}
//sort阶段结束
sortPhase.complete();
return;
}
//Spill文件数>1,需要进行合并
for (int i = indexCacheList.size(); i < numSpills; ++i) {
Path indexFileName = mapOutputFile.getSpillIndexFile(i);
//先将所有spill索引文件收集在一起
indexCacheList.add(new SpillRecord(indexFileName, job));
}
//最终spill文件
Path finalOutputFile =
mapOutputFile.getOutputFileForWrite(finalOutFileSize);
//最终索引文件
Path finalIndexFile =
mapOutputFile.getOutputIndexFileForWrite(finalIndexFileSize);
//创建通向最终溢写文件的输出流
FSDataOutputStream finalOut = rfs.create(finalOutputFile, true, 4096);
if (numSpills == 0) {
//如果没有生成溢写文件,也要创建空文件
}
//sort阶段按照分区数划分子阶段,所以最终的大的溢写文件也是按照分区和key值排完序的
sortPhase.addPhases(partitions);
//对于每一个分区
for (int parts = 0; parts < partitions; parts++) {
//创建片段列表存放每个spill文件的信息以便最终合并
List<Segment<K,V>> segmentList =
new ArrayList<Segment<K, V>>(numSpills);
//合并所有spill文件中的当前分区
for(int i = 0; i < numSpills; i++) {
IndexRecord indexRecord = indexCacheList.get(i).getIndex(parts);
Segment<K,V> s =
new Segment<K,V>(job, rfs, filename[i], indexRecord.startOffset,
indexRecord.partLength, codec, true);
segmentList.add(i, s);
}
//同时可以对100个文件进行合并
int mergeFactor = job.getInt(JobContext.IO_SORT_FACTOR, 100);
//仅当存在中间合并时,才对段进行排序
boolean sortSegments = segmentList.size() > mergeFactor;
//合并同一分区在所有spill文件中的内容,可能会需要进行sort,合并结果是序列kv对迭代器
RawKeyValueIterator kvIter = Merger.merge(job, rfs,
keyClass, valClass, codec,
segmentList, mergeFactor,
new Path(mapId.toString()),
job.getOutputKeyComparator(), reporter, sortSegments,
null, spilledRecordsCounter, sortPhase.phase(),
TaskType.MAP);
//接下来将kv迭代器中的内容写到磁盘上
//当无combiner或spill文件数<3(minSpillsForCombine)时,由属性MAP_COMBINE_MIN_SPILLS控制
if (combinerRunner == null || numSpills < minSpillsForCombine) {
//将合并内容直接写入文件
Merger.writeFile(kvIter, writer, reporter, job);
} else {
//将合并内容经过combiner后写入文件
combineCollector.setWriter(writer);
combinerRunner.combine(kvIter, combineCollector);
}
writer.close();
//进入下一个子阶段,也就是写入写一个分区
sortPhase.startNextPhase();
//最后写入到索引文件
spillRec.writeToFile(finalIndexFile, job);
//删除所有小的spill文件
for(int i = 0; i < numSpills; i++) {
rfs.delete(filename[i],true);
}
最终的溢写文件和之前单个溢写文件的格局是一样的,按照分区分成若干区段,每个分区都有个头部,然后就是排序好的kv对。这个Merge操作结合原先为各个spill文件进行的Sort,构成了MergeSort(归并排序),不过这一阶段的MergeSort是针对同一Mapper的多个spill文件。而在Reducer阶段的merge是针对多个Mapper的MergeSort。
3.1.1 环形缓冲区的工作原理
缓冲区的工作机制很简单,逐次将输出数据写入缓冲区,当缓冲区中的剩余空间已不足以容纳本次输出时,就将整个缓冲区的内容Spill到文件中,腾出缓冲区空间,再继续往里面写。但是,在将缓冲区内容Spill到文件中的过程中,对于缓冲区的写入就被阻塞了,会导致Mapper只能工作一段时间,停顿一段时间。
为了避免这样的全同步方式,另外有一个Spill线程。Mapper线程源源不断地往缓冲区中写,Spill线程把缓冲区的内容写入文件。这样Mapper的输出就编程了不阻塞的异步方式。但是为了不让Mapper对缓冲区的写入与Spill线程从缓冲区的读出互相干扰。所以,一般缓冲区都是环形缓冲区,让写入者在前面跑,读出者在后面追,如果写入者跑得太快,跑了一圈追上了读者者,就让写入者停一下;如果读出者追得太快,追上了写入者就让读出者停一下。可以想象成读和写是两名在跑道上跑步的运动员,但是读不能超过写,写不能超读一圈。
环形缓冲区只适合用于写入和读出的内容保持顺序的条件下,而Mapper输出的数据写入Spill文件之前是需要排序的,这个排序并不是对缓冲区的这些kv对挪来挪去,而是改变它们写入Spill文件时的顺序。
kv对经过序列化写入缓冲区后,需要确定它们的边界和位置,这就需要另外存储元数据。每个kv对的元数据中有4个32位的整数,共16字节,元数据包括了V值起点字节的下标,K值起点字节的下标,kv对所属Partition(分区),V值的长度。注意:这里的分区,就决定了该kv对后续传输给哪个reducer。
数据和元数据都存放在环形缓冲区中,它们之间通过分割点(quator)来区分。

如上图就是字节数组的缓冲区kvbuffer,起点下标为0,终点下标为kvbuffer.length。分割点可以在缓冲区的任何位置上,分割点的位置确定后,数据都位于其右侧,元数据都位于其左侧。所有元数据合在一起就是一个元数据块,相当于一个“反向数组”,通过下标即可找到某个kv对的元数据,再按照元数据信息就可找到kv对。
初始化的时候,分割点设置在缓冲区的起点,即下标为0的地方。

此时数据位于缓冲区底部,自底向上伸展;元数据位于顶部,自顶向下伸展
对于数据:bufstart指向数据块的起点,bufindex指向现有数据块的末尾,有新的数据到来时就从这个位置开始写;
对于元数据:kvstart指向元数据块中的第一份元数据,kvend指向元数据中最后一份元数据,kvindex指向准备写入下一份元数据的位置,因为环形缓冲区其实是下标沿顺时针增大的数组,所以每写入一份元数据,kvindex会减4,所以kvend和kvindex始终保持一份元数据的距离。
在写入时我们把缓冲区视为字节数组,bufstart,bufindex是字节数组内的下标;而在写入元数据时则把缓冲区视为整数数组,kvstart,kvend,kvindex都是整数数组内的下标。
随着数据的到来,缓冲区的空闲部分会越来越小,实际上Spill操作应该在缓冲区空间耗尽之前就开始,这样Mapper还能继续往缓冲区中写入。在MapOutputBuffer.init()中有个启动Spill的门槛值spiller,默认为80%,对应配置文件mapred-default.xml中的属性mapreduce.map.sort.spill.percent。当缓冲区达到80%满时就开始排序和Spill。排序只需要调整元数据项的位置即可,数据块的内容无需变动。
由于Spill线程和Mapper线程是并发进行的,所以当Spill完成后,原先的kvend到bufindex之间的区间就被释放了,而原先空闲的区间则可能已经有了一些内容;那么新写入的数据和元数据并不是背靠背相连而是以equator分隔,两者中间隔开了因Spill而腾出来的空闲区间。
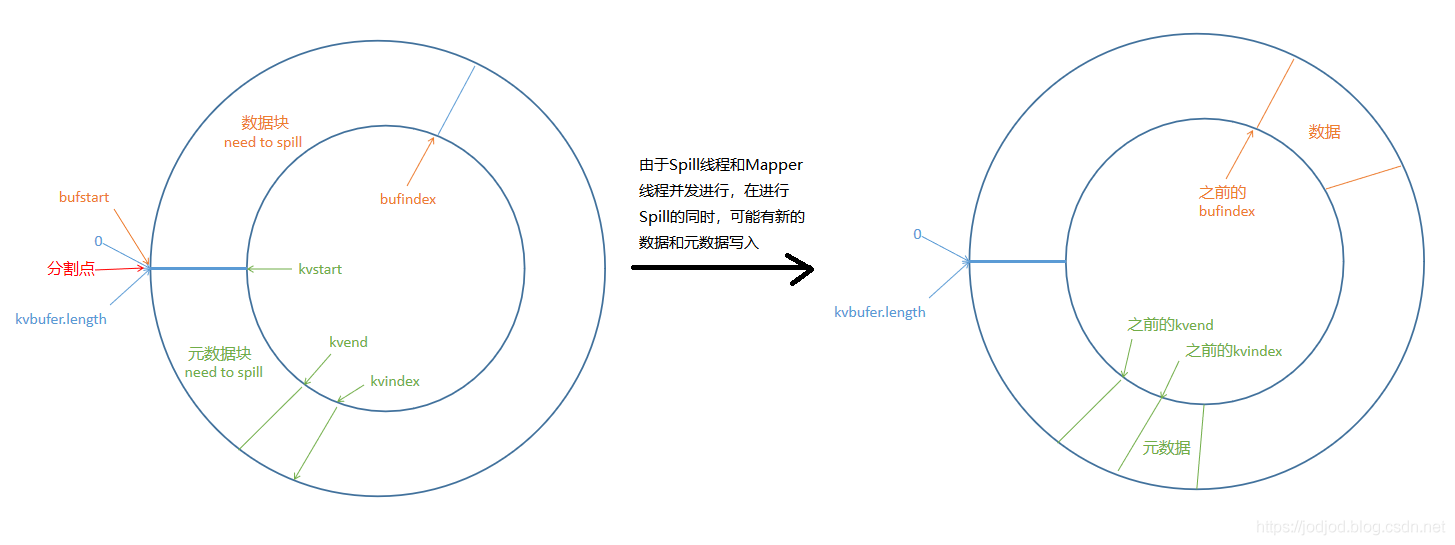
此时就需要搬动元数据使两者可以背靠背地相连,两者中间就是新的分割点。但是此时新的数据块的起点,也就是之前的bufindex所指的位置未必是与整数边界对齐的,而新的元数据块的起点必须与整数边界对齐。所以经过Spill后,数据块和元数据块未必是无缝地连接在一起了,中间可能会有一个小于4字节大小的空隙
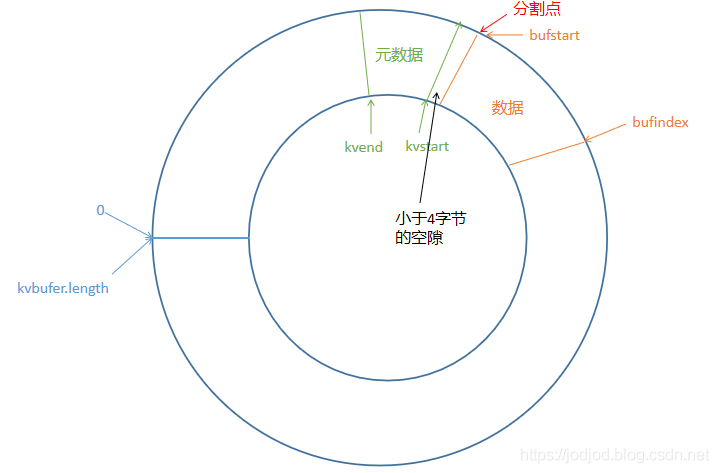
新的数据块起点作为分割点,其右侧为数据块,左侧为元数据块
3.2 partitioner
如果Reducer的数量设置为0,那就没有Reducer阶段,Mapper的输出就是整个MR框架的输出。如果有Reducer则使用的是NewOutputCollector,它是MapTask的一个内部类,其中有另一重要成分:分区器。可以说collector负责收集Mapper输出并将其交付给Reducer,而partitioner决定了将输出具体交付给哪一个Reducer。
默认情况ReduceTask的个数为1,默认partitioner是HashPartitioner。每个分区由一个reducer处理,所以分区数默认等于作业的reducer数。比如有5个ReduceTask,即numReduceTasks=5,通过HashPartitioner可能会有5个返回值,即5个分区,分区号分别为0,1,2,3,4。
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
由于我们可以手动设置reducer的数量,当分区数>ReduceTask数时,程序会报错;当分区数<ReduceTask数时,输出结果会有空文件生成;默认情况下分区数=ReduceTask,则没有空文件,且文件名为part-r-xxxx,其中r表示完成了reduce阶段;
优化点:
map阶段输出时,若输出数据量非常大,可以对输出文件进行压缩处理,降低带宽的限制。
set hive.exec.compress.intermediate = true; -- 在中间数据上启用压缩
set mapreduce.map.output.compress=true; -- 是否启动压缩(true/false)
set mapreduce.map.output.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; -- 指定Snappy压缩格式
因为在下一阶段,即reduce的copy阶段,需要从map阶段所在的机器(非本地机器)copy数据,这个过程依赖网络带宽。若map输出数据量非常大,reduce的copy阶段将非常慢。
当然在开启Map压缩,会有一定的CPU消耗,但MapReduce任务是IO型的任务,消耗掉CPU也不是很要求,如果是计算密集型的计算,不建议开启CPU(计算资源宝贵呀)。
















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











