









Explan简介
SQL
编写过程:select distinct … from … join… on …where … group by … having … order by…
解析过程:from … on … join … where … group by… having … select distinct…order by…
1 id
2 select_type
作用:表示查询类型,主要用于区别普通查询,联合查询、子查询等的复杂查询类型。
1.1 simple
简单的select查询,查询中不包含子查询、union。
3 table
当前执行的表。
4 partitions
5 type
按性能排序:system>const>eq_ref>ref>range>index>all
- system
- const
- eq_ref
- ref
- range
只检索给定范围的行,使用一个索引来选择行,key列显示使用了哪个索引。
一般在where语句中出现between、< 、>、in等的查询,这种范围扫描索引比全表扫描要好,因为它只需开始于索引的某一点,结束于另一点,不用扫描全部索引。
- index
为了找到匹配的行,遍历了整个索引树。这通常比all快,因为索引文件比整个文件小。也就是说,虽然index 和all都是读全表,但 index从索引中读取,但all是从硬盘中读取。
- all
为了找到匹配的行,遍历了整个表。
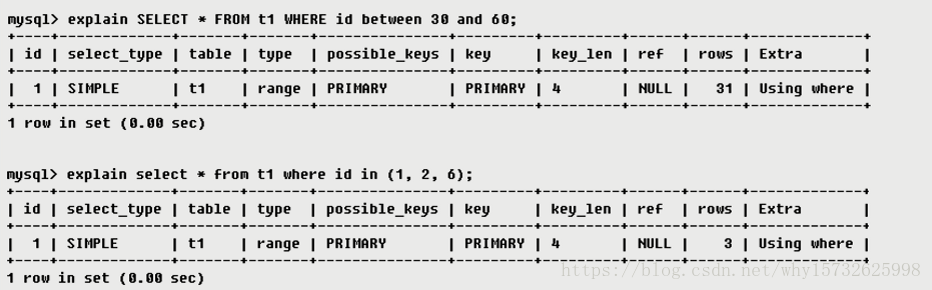


6 possible_keys
当前查询可能使用到的索引,1个或多个。
查询涉及到的字段上若存在索引,这些索引将被列出。但不一定被查询实际使用到。
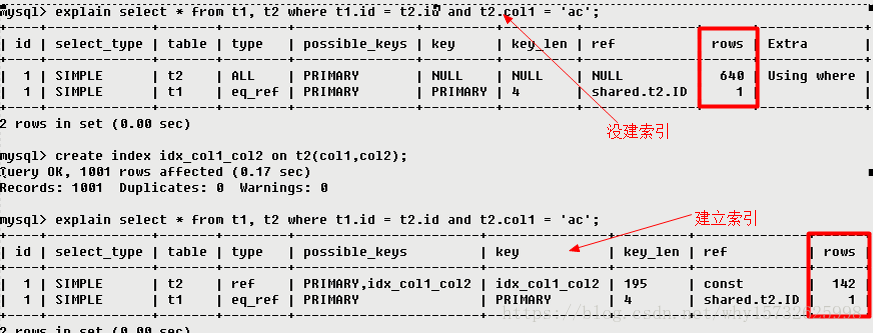
7 key
查询中实际使用到的索引。
- 如果为NULL,则没有使用到索引。(原因包括没有建立索引,或索引失效)
- 查询中若使用了
覆盖索引,select后的字段与建立的索引字段完全相同,则该索引仅出现在key列表中,不会出现在possible_keys列表中。



8 key_len
查询中使用到的索引的长度,可用于判断,索引是否被全部使用。
key_len显示的为索引字段的 最大可能长度,并非实际使用长度,即key_len的值是通过表定义计算出来,不是通过表内检索出来的。
各编码中1个字符占的字节数:
utf8:1个字符占3个字节。
gbk:1个字符占2个字节。
latin:1个字符占2个字节。
如下示例:
下面的示例采用了utf8编码,1个字符占3个字节。
我们在字段col1、col2上建立了聚合索引(col1,col2)。字段col1长度为4个字符,共占用4*3=12个字节,并且MySQL用1个字节标识“字段col1可以为null”这件事,故col1共占用12+1=13个字节。col2同理。

9 ref
若ref不是NULL ,说明explain 的key列中有索引。
ref即说明key列中的索引,具体属于哪个表的哪个列。
-
const
-
数据库名.表名.字段名
10 rows
估算找到所需记录,需要读取的行数。rows越小越好。
11 filtered
存储引擎返回的数据会经过server层的过滤。过滤后剩下的数据量占过滤前所有数据量的比例,即filtered。注意是百分比,不是具体记录数。
12 Extra
- using where
需要回表查询,表示MySQL对存储引擎提取的结果(select * from test_extra)进行过滤(where age > 30),过滤使用的条件字段 (age)上没有索引,所以需要回到原表查询,而不能只在索引文件中查询。
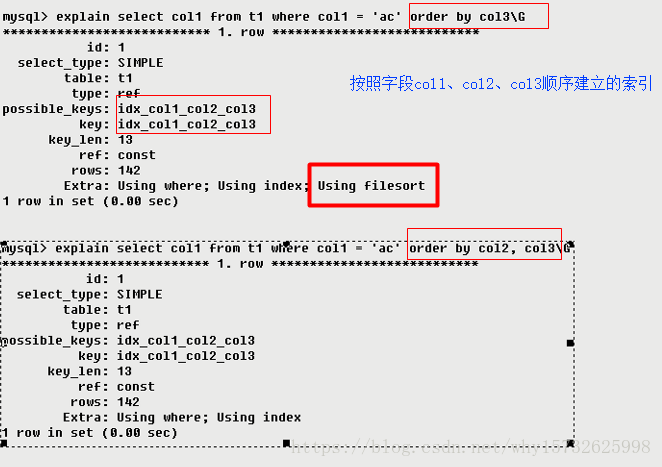
- using filesort
MySQL中无法利用索引完成排序,需要进行一次额外的排序,这称为“文件排序”。using filesort说明性能消耗巨大。
当Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Explain不会显示的告诉客户端用哪种排序。官方解释:“MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行”。
.
怎么避免出现using filesort?- 对于单列索引
如果排序(order by)和查找(where)的是同一字段,则不会出现using filesort。不是同一个字段,会出现using filesort。
.
select* from test01 where a1 = 1 order by a2 #会出现using filesort
避免:select * from test01 where a1 = 1 order by a2。where 哪些字段,就order by哪些字段。 - 对于复合索引
假设建立了复合索引(a1,a2,a3,a4)。
where 和 order by的字段拼起来后,符合复合索引的最优左前缀((a1),(a1,a2),(a1,a2,a3)),就不会出现using filesort。若出现了跨列((a1,a3),(a1,a2,a4)),就会出现using filesort。
- 对于单列索引
- using index
不需要回原表

参考文献:
[1] MySQL高级 (一) EXPLAIN的用法和结果分析















 6292
6292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











