






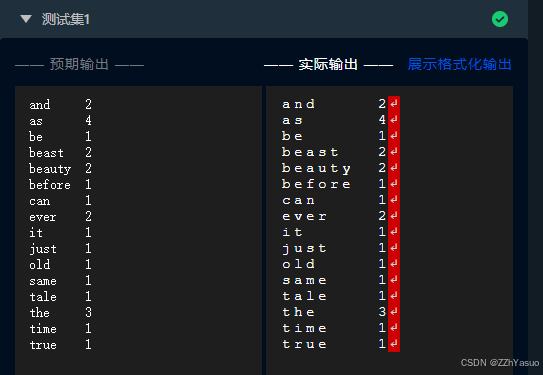
第1关:WordCount词频统计
本关任务
词频统计是最能体现MapReduce思想的程序,结构简单,上手容易。
输入文本(可以不只一个),按行提取文本文档的单词,形成行<k1,v1>键值对,具体形式很多,例如<行数,字符偏移>等;
通过Spliting将<k1,v1>细化为单词键值对<k2,v2>;
Map分发到各个节点,同时将<k2,v2>归结为list(<k2,v2>);
在进行计算统计前,先用Shuffing将相同主键k2归结在一起形成<k2,list(v2)>;
Reduce阶段直接对<k2, list(v2)> 进行合计得到list(<k3,v3>)并将结果返回主节点。
相关知识
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题。将处理过程高度抽象为两个函数:map和reduce。
编程要求
本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
在主函数main中已初始化hadoop的系统设置,包括hadoop运行环境的连接。
在main函数中,已经设置好了待处理文档路径(即input),以及结果输出路径(即output)。
在main函数中,已经声明了job对象,程序运行的工作调度已经设定好。
本关只要求在map和reduce函数的指定区域进行代码编写,其他区域请勿改动。
代码示例:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/*
* MapReduceBase类:实现Mapper和Reducer接口的基类
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类要实现此接口。
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/*
*LongWritable,IntWritable,Text是Hadoop中实现的用于封装Java数据类型的类,这些类实现了WritableComparable接口,
*都能够被串行化,便于在分布式环境中进行数据交换,可以视为long,int,String数据类型的替代。
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();//Text实现了BinaryComparable类,可以作为key值
/*
* Mapper接口中的map方法:
* void map(K1 key, V1 value, OutputCollector<K2,V2> output, Reporter reporter)
* 映射一个单个的输入<K1,V1>对到一个中间输出<K2,V2>对
* 中间输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* OutputCollector接口:收集Mapper和Reducer输出的<K,V>对。
* OutputCollector接口的collect(k, v)方法:增加一个(k,v)对到output
* Reporter 用于报告整个应用的运行进度
*/
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
/*
* 原始数据(以test1.txt为例):
* tale as old as time
true as it can be
beauty and the beast
map阶段,数据如下形式作为map的输入值:key为偏移量
<0 tale as old as time>
<21 world java hello>
<39 you me too>
*/
/**
* 解析(Spliting)后以得到键值对<K2,V2>(仅以test1.txt为例)
* 格式如下:前者是键值,后者数字是值
* tale 1
* as 1
* old 1
* as 1
* time 1
* true 1
* as 1
* it 1
* can 1
* be 1
* beauty 1
* and 1
* the 1
* beast 1
* 这些键值对作为map的输出数据
*/
//****请补全map函数内容****//
/*********begin*********/
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
/*********end**********/
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
/*
* reduce过程是对输入键值对洗牌(Shuffing)形成<K2,list(V2)>格式数据(仅以test1.txt为例):
* (tablie [1])
* (as [1,1,1])
* (old [1])
* (time [1])
* (true [1])
* (it [1])
* (can [1])
* (be [1])
* (beauty [1])
* (and [1])
* (the [1])
* (beast [1])
* 作为reduce的输入
*
*/
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
//****请补全reduce对<k2, list(v2)> 进行合计得到list(<k3,v3>)过程****//
/*********begin*********/
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
/*********end**********/
//****请将list(<k3,v3>)统计输出****//
/*********begin*********/
result.set(sum);
context.write(key, result);
/*********end**********/
}
}
public static void main(String[] args) throws Exception {
/**
* JobConf:map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作
* 构造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等
*/
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
/*
* 需要配置输入和输出的HDFS的文件路径参数
* 可以使用"Usage: wordcount <in> <out>"实现程序运行时动态指定输入输出
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");//Job(Configuration conf,String jobName)设置job名称
job.setJarByClass(WordCount.class);//为job设置Mapper类
/*********begin*********/
//****请为job设置Mapper类****//
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);//为job设置Combiner类
//****请为job设置Reduce类****//
job.setReducerClass(IntSumReducer.class);
//****请设置输出key的参数类型****//
job.setOutputKeyClass(Text.class);
//****请设置输出value的类型****//
job.setOutputValueClass(IntWritable.class);
/*********end**********/
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//为map-reduce任务设置InputFormat实现类,设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为map-reduce任务设置OutputFormat实现类,设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
第2关:HDFS文件读写
本关任务:利用HDFS文件系统开放的API对HDFS系统进行文件的创建和读写
要求:
在HDFS的路径/user/hadoop/下新建文件myfile,并且写入内容“china cstor cstor cstor china”;
输出HDFS系统中刚写入的文件myfile的内容HDFS文件流操作
HDFS文件还提供文件数据流操作API,利用这些可以将文件读取简化为三大步骤。
获取文件系统实例化创建文件
通过获取数据流进行写入,完成后关闭数据流
通过输出数据流将文件内容输出
编程要求
在主函数main中已获取hadoop的系统设置,并在其中创建HDFS文件。在main函数中,指定创建文档路径(必须设置为/user/hadoop/myfile才能评测),输入内容必须是本关要求内容才能评测。
添加读取文件输出部分
本关只要求在指定区域进行代码编写,其他区域仅供参考请勿改动。
代码示例:
import java.io.IOException;
import java.sql.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class hdfs {
public static void main(String[] args) throws IOException {
//throws IOException捕获异常声明
//****请根据提示补全文件创建过程****//
/*********begin*********/
Configuration conf = new Configuration(); //实例化设置文件,configuration类实现hadoop各模块之间值的传递
FileSystem fs = FileSystem.get(conf); //是hadoop访问系统的抽象类,获取文件系统, FileSystem的get()方法得到实例fs,然后fs调动create()创建文件,open()打开文件
System.out.println(fs.getUri());
//实现文件读写主要包含以下步骤:
//读取hadoop文件系统配置
//实例化设置文件,configuration类实现hadoop各模块之间值的传递
//FileSystem是hadoop访问系统的抽象类,获取文件系统, FileSystem的get()方法得到实例fs,然后fs调动create()创建文件,调用open()打开文件,调用close()关闭文件
//*****请按照题目填写要创建的路径,其他路径及文件名无法被识别******//
Path file = new Path("/user/hadoop/myfile");
/*********end**********/
if (fs.exists(file)) {
System.out.println("File exists.");
} else
{
//****请补全使用文件流将字符写入文件过程,使用outStream.writeUTF()函数****//
/*********begin*********/
FSDataOutputStream outStream = fs.create(file); //获取文件流
outStream.writeUTF("china cstor cstor cstor china"); //使用文件流写入文件内容
/*********end**********/
}
//****请补全读取文件内容****//
/*********begin*********/
// 提示:FSDataInputStream实现接口,使Hadoop中的文件输入流具有流式搜索和流式定位读取的功能
FSDataInputStream inStream = fs.open(file);
String data = inStream.readUTF();
/*********end**********/
//输出文件状态
//FileStatus对象封装了文件的和目录的元数据,包括文件长度、块大小、权限等信息
FileSystem hdfs = file.getFileSystem(conf);
FileStatus[] fileStatus = hdfs.listStatus(file);
for(FileStatus status:fileStatus)
{
System.out.println("FileOwer:"+status.getOwner());//所有者
System.out.println("FileReplication:"+status.getReplication());//备份数
System.out.println("FileModificationTime:"+new Date(status.getModificationTime()));//目录修改时间
System.out.println("FileBlockSize:"+status.getBlockSize());//块大小
}
System.out.println(data);
System.out.println("Filename:"+file.getName());
inStream.close();
fs.close();
}
}
第3关:倒排索引
相关知识
文本特征
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再在本关后续内容,很多情况下会使用文档来表征文本信息。
文档集合(Document Collection):由若干文档构成的集合称之为文档集合。
文档编号(Document ID):在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
编程要求
本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
在主函数main中已初始化hadoop的系统设置,包括hadoop运行环境的连接。
在main函数中,已经设置好了待处理文档路径(即input),以及结果输出路径(即output)。
在main函数中,已经声明了job对象,程序运行的工作调度已经设定好。
本关只要求在map和reduce函数的指定区域进行代码编写,其他区域请勿改动。
import java.io.IOException;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.util.Iterator;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
public class InvertedIndex {
public static class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text>
{
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String fileName = fileSplit.getPath().getName();
String word;
IntWritable frequence=new IntWritable();
int one=1;
Hashtable<String,Integer> hashmap=new Hashtable();//key关键字设置为String
StringTokenizer itr = new StringTokenizer(value.toString());
//****请用hashmap定义的方法统计每一行中相同单词的个数,key为行值是每一行对应的偏移****//
/*********begin*********/
for(;itr.hasMoreTokens(); )
{
word=itr.nextToken();
if(hashmap.containsKey(word)){
hashmap.put(word,hashmap.get(word)+1);
}else{
hashmap.put(word, one);
}
}
/*********end**********/
for(Iterator<String> it=hashmap.keySet().iterator();it.hasNext();){
word=it.next();
frequence=new IntWritable(hashmap.get(word));
Text fileName_frequence = new Text(fileName+"@"+frequence.toString());//以<K2,“单词 文件名@出现频次”> 的格式输出
context.write(new Text(word),fileName_frequence);
}
}
}
public static class InvertedIndexCombiner extends Reducer<Text,Text,Text,Text>{
protected void reduce(Text key,Iterable<Text> values,Context context)
throws IOException ,InterruptedException{
//****请合并mapper函数的输出,并提取“文件@1”中‘@’后面的词频,以<K2,list(“单词 文件名@出现频次”)>的格式输出****//
/*********begin*********/
String fileName="";
int sum=0;
String num;
String s;
for (Text val : values) {
s= val.toString();
fileName=s.substring(0, val.find("@"));
num=s.substring(val.find("@")+1, val.getLength()); //提取“doc1@1”中‘@’后面的词频
sum+=Integer.parseInt(num);
}
IntWritable frequence=new IntWritable(sum);
context.write(key,new Text(fileName+"@"+frequence.toString()));
/*********end**********/
}
}
public static class InvertedIndexReducer extends Reducer<Text, Text, Text, Text>
{ @Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException
{ Iterator<Text> it = values.iterator();
StringBuilder all = new StringBuilder();
if(it.hasNext()) all.append(it.next().toString());
for(;it.hasNext();) {
all.append(";");
all.append(it.next().toString());
}
//****请输出最终键值对list(K3,“单词", “文件1@频次; 文件2@频次;...")****//
/*********begin*********/
context.write(key, new Text(all.toString()));
/*********end**********/
}
}
public static void main(String[] args)
{
if(args.length!=2){
System.err.println("Usage: InvertedIndex <in> <out>");
System.exit(2);
}
try {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = new Job(conf, "invertedindex");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(InvertedIndexMapper.class);
//****请为job设置Combiner类****//
/*********begin*********/
job.setCombinerClass(InvertedIndexCombiner.class);
/*********end**********/
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
//****请设置输出value的类型****//
/*********begin*********/
job.setOutputValueClass(Text.class);
/*********end**********/
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
第4关: 网页排序——PageRank算法
本关任务
要求:编写实现网页数据集PageRank算法的程序,对网页数据集进行处理得到网页权重排序。
相关知识
PageRank算法原理
1. 基本思想:
如果网页T存在一个指向网页A的连接,则表明T的所有者认为A比较重要,从而把T的一部分重要性得分赋予A。这个重要性得分值为:PR(T)/L(T)
其中PR(T)为T的PageRank值,L(T)为T的出链数。则A的PageRank值为一系列类似于T的页面重要性得分值的累加。
即一个页面的得票数由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(链入页面)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
2.PageRank简单计算:
假设一个由只有4个页面组成的集合:A,B,C和D。如图所示,如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。
继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
换句话说,根据链出总数平分一个页面的PR值。
完整PageRank计算公式
由于存在一些出链为0不链接任何其他网页的网页,因此需要对 PageRank公式进行修正,即在简单公式的基础上增加了阻尼系数(damping factor)q, q一般取值q=0.85
更加准确的表达为:
P1,P2,...,Pn是被研究的页面,M(Pi)是Pi链入页面的数量,L(Pj)是Pj链出页面的数量,而N是所有页面的数量。PageRank值是一个特殊矩阵中的特征向量。这个特征向量为:
R是如下等式的一个解:
如果网页i有指向网页j的一个链接,则
否则=0.
PageRank计算过程
PageRank 公式可以转换为求解的值,
其中矩阵为 A = q × P + ( 1 一 q) * 。 P 为概率转移矩阵,为 n 维的全 1 行.
则=
幂法计算过程如下:
X 设任意一个初始向量, 即设置初始每个网页的 PageRank值均。一般为1。R = AX。
while (1){
if ( |X - R| < e)
return R; //如果最后两次的结果近似或者相同,返回R
else {
X =R;
R = AX;
}
}
MapReduce计算PageRank
上面的演算过程,采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决
对于如下图所示的相互链接网页关系
可以利用转移矩阵进行表示。转移矩阵是一个多维的稀疏矩阵,把web图中的每一个网页及其链出的网页作为一行,这样第四节中的web图结构用如下方式表示:
1. A B C D
2. B A D
3. C C
4. D B C
可以看A有三条出链,分布指向A、B、C,实际上爬取的网页结构数据就是这样的。
1.Map阶段
Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出<B,1/31/4>,<C,1/3*1/4>,<D,1/3*1/4>;
2、Reduce阶段
Reduce操作收集网页id相同的值,累加并按权重计算,pj=a(p1+p2+…Pm)+(1-a)*1/n,其中m是指向网页j的网页j数,n所有网页数。
思路就是这么简单,但是实践的时候,怎样在Map阶段知道当前行网页的概率值,需要一个单独的文件专门保存上一轮的概率分布值,先进行一次排序,让出链行与概率值按网页id出现在同一Mapper里面,整个流程如下:
这样进行一次迭代相当于需要两次MapReduce,但第一次的MapReduce只是简单的排序,不需要任何操作,用java调用Hadoop的Streaming.
####编程要求
本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
在主函数main中已初始化hadoop的系统设置,包括hadoop运行环境的连接。
在main函数中,已经设置好了待处理文档路径(即input),在评测中设置了结果输出路径(即output),不要修改循环输出路径即可保证完成。
在main函数中,已经声明了job对象,程序运行的工作调度已经设定好。
原则上循环迭代次数越多越精准,但是为了保证平台资源,只允许运行5次迭代,多余过程被忽略无法展示,请勿增加循环次数。
本关只要求在map和reduce函数的指定区域进行代码编写,其他区域请勿改动。
测试说明
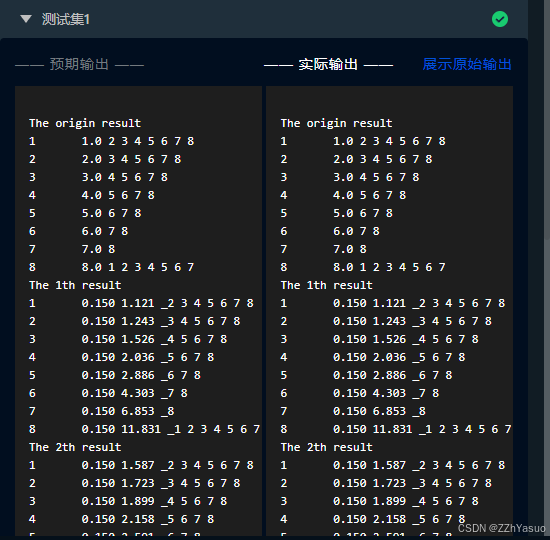
输入文件格式如下:
1 1.0 2 3 4 5 6 7 8
2 2.0 3 4 5 6 7 8
3 3.0 4 5 6 7 8
4 4.0 5 6 7 8
5 5.0 6 7 8
6 6.0 7 8
7 7.0 8
8 8.0 1 2 3 4 5 6 7
注:为了简化运算,已经对网页集关系进行了规整,并且给出了相应的初始PR值。
以第一行为例: 1表示网址(以tab键隔开),1.0为给予的初始pr值,2,3,4,5,6,7,8为从网址1指向的网址。
输出文件格式:
The origin result
1 1.0 2 3 4 5 6 7 8
2 2.0 3 4 5 6 7 8
3 3.0 4 5 6 7 8
4 4.0 5 6 7 8
5 5.0 6 7 8
6 6.0 7 8
7 7.0 8
8 8.0 1 2 3 4 5 6 7
The 1th result
1 0.150 1.121 _2 3 4 5 6 7 8
2 0.150 1.243 _3 4 5 6 7 8
3 0.150 1.526 _4 5 6 7 8
4 0.150 2.036 _5 6 7 8
5 0.150 2.886 _6 7 8
6 0.150 4.303 _7 8
7 0.150 6.853 _8
8 0.150 11.831 _1 2 3 4 5 6 7
The 2th result
1 0.150 1.587 _2 3 4 5 6 7 8
2 0.150 1.723 _3 4 5 6 7 8
3 0.150 1.899 _4 5 6 7 8
4 0.150 2.158 _5 6 7 8
5 0.150 2.591 _6 7 8
6 0.150 3.409 _7 8
7 0.150 5.237 _8
8 0.150 9.626 _1 2 3 4 5 6 7
The 3th result
1 0.150 1.319 _2 3 4 5 6 7 8
2 0.150 1.512 _3 4 5 6 7 8
3 0.150 1.756 _4 5 6 7 8
4 0.150 2.079 _5 6 7 8
5 0.150 2.537 _6 7 8
6 0.150 3.271 _7 8
7 0.150 4.720 _8
8 0.150 8.003 _1 2 3 4 5 6 7
The 4th result
1 0.150 1.122 _2 3 4 5 6 7 8
2 0.150 1.282 _3 4 5 6 7 8
3 0.150 1.496 _4 5 6 7 8
4 0.150 1.795 _5 6 7 8
5 0.150 2.236 _6 7 8
6 0.150 2.955 _7 8
7 0.150 4.345 _8
8 0.150 7.386 _1 2 3 4 5 6 7
The 5th result
1 0.150 1.047 _2 3 4 5 6 7 8
2 0.150 1.183 _3 4 5 6 7 8
3 0.150 1.365 _4 5 6 7 8
4 0.150 1.619 _5 6 7 8
5 0.150 2.000 _6 7 8
6 0.150 2.634 _7 8
7 0.150 3.890 _8
8 0.150 6.686 _1 2 3 4 5 6 7
注:迭代方法和次数不同会对结果产生影响,不必完全与答案匹配,只需运行结果趋于合理即可。(第二列为多余值)
import java.io.IOException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
import java.util.StringTokenizer;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class PageRank {
public static class MyMapper extends Mapper<Object, Text, Text, Text>
{
private Text id = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException
{
String line = value.toString();
//判断是否为输入文件
if(line.substring(0,1).matches("[0-9]{1}"))
{
boolean flag = false;
if(line.contains("_"))
{
line = line.replace("_","");
flag = true;
}
//对输入文件进行处理
String[] values = line.split("\t");
Text t = new Text(values[0]);
String[] vals = values[1].split(" ");
String url="_";//保存url,用作下次计算
double pr = 0;
int i = 0;
int num = 0;
if(flag)
{
i=2;
pr=Double.valueOf(vals[1]);
num=vals.length-2;
}
else
{
i=1;
pr=Double.valueOf(vals[0]);
num=vals.length-1;
}
for(;i<vals.length;i++)
{
url=url+vals[i]+" ";
id.set(vals[i]);
Text prt = new Text(String.valueOf(pr/num));
context.write(id,prt);
}
context.write(t,new Text(url));
}
}
}
public static class MyReducer extends Reducer<Text,Text,Text,Text>
{
private Text result = new Text();
private Double pr = new Double(0);
public void reduce(Text key, Iterable<Text> values, Context context ) throws IOException, InterruptedException
{
double sum=0;
String url="";
//****请通过url判断否则是外链pr,作计算前预处理****//
/*********begin*********/
for(Text val:values)
{
//发现_标记则表明是url,否则是外链pr,要参与计算
if(!val.toString().contains("_"))
{
sum=sum+Double.valueOf(val.toString());
}
else
{
url=val.toString();
}
}
pr=0.15+0.85*sum;
String str=String.format("%.3f",pr);
result.set(new Text(str+" "+url));
context.write(key,result);
/*********end**********/
//****请补全用完整PageRank计算公式计算输出过程,q取0.85****//
/*********begin*********/
/*********end**********/
}
}
public static void main(String[] args) throws Exception
{
String paths="file:///tmp/input/Wiki0";//输入文件路径,不要改动
String path1=paths;
String path2="";
for(int i=1;i<=5;i++)//迭代5次
{
System.out.println("This is the "+i+"th job!");
System.out.println("path1:"+path1);
System.out.println("path2:"+path2);
Configuration conf = new Configuration();
Job job = new Job(conf, "PageRank");
path2=paths+i;
job.setJarByClass(PageRank.class);
job.setMapperClass(MyMapper.class);
//****请为job设置Combiner类****//
/*********begin*********/
job.setCombinerClass(MyReducer.class);
/*********end**********/
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(path1));
FileOutputFormat.setOutputPath(job, new Path(path2));
path1=path2;
job.waitForCompletion(true);
System.out.println(i+"th end!");
}
}
}

















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









