







是什么?
Hadoop是一种分析和处理大数据的软件平台,是一种对大量数据进行分布式处理的软件框架。
Hadoop的框架最核心的设计就是:
HDFS和MapReduce.
- HDFS为海量的数据提供了存储
- MapReduce为海量的数据提供了计算.
HDFS
是什么?
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
特点
- HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;
- 它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
- HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
- 对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。
结构设计
HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。
这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。
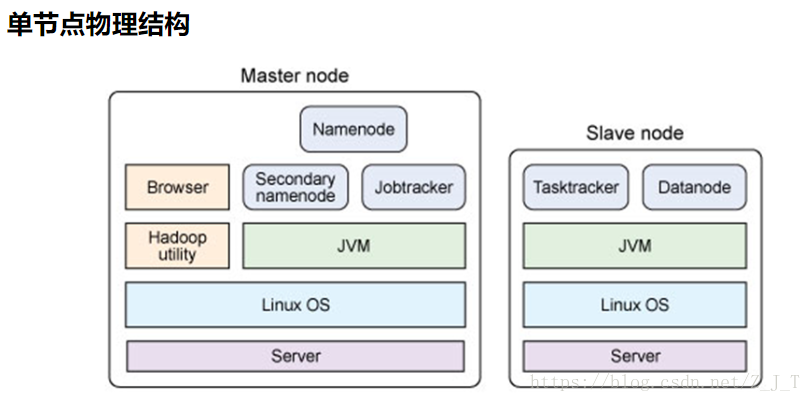
主从结构
- 主节点,只有一个: namenode
- 从节点,有很多个: datanodes
各节点功能
- namenode负责:接收用户操作请求 、维护文件系统的目录结构、管理文件与block之间关系,block与datanode之间关系。通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。
- datanode负责:存储文件文件被分成block存储在磁盘上、为保证数据安全,文件会有多个副本。
HDFS内部通信协议
HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
MapReduce
是什么?
MapReduce是处理大量半结构化数据集合的编程模型。
什么是编程模型?
编程模型是一种处理并结构化特定问题的方式。
- 例如,在一个关系数据库中,使用一种集合语言执行查询,如SQL。告诉语言想要的结果,并将它提交给系统来计算出如何产生计算。
- 还可以用更传统的语言(C++,Java),一步步地来解决问题。
这是两种不同的编程模型MapReduce就是另外一种。
MapReduce和Hadoop是相互独立的,实际上又能相互配合工作得很好。
MapReduce 的主从结构
- 主节点,只有一个: JobTracker
- 从节点,有很多个: TaskTrackers
各节点功能
- JobTracker负责:接收客户提交的计算任务、把计算任务分给TaskTrackers执行、监控TaskTracker的执行情况
- TaskTrackers负责:执行JobTracker分配的计算任务
hadoop优点:
- Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
- Hadoop 是可靠的,按位存储和处理数据的能力值得人们信赖。因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
- Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
- Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- Hadoop 还是可伸缩的,能够处理 PB 级数据。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。hadoop是开源的,项目的软件成本低。
- Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。
- Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
- Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
hadoop大数据处理的意义
- Hadoop在大数据处理中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。
- Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。
- Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
Hadoop能做什么?
- 大数据量存储:分布式存储
- 日志处理: Hadoop擅长这个
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐
- 大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高。
- 数据支持一次写入,多次读取。对于已经形成的数据的更新不支持。
- 数据不进行本地缓存(文件很大,且顺序读没有局部性)
- 任何一台服务器都有可能失效,需要通过大量的数据复制使得性能不会受到大的影响。
- 用户细分特征建模
- 个性化广告推荐
- 智能仪器推荐















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









