







目录
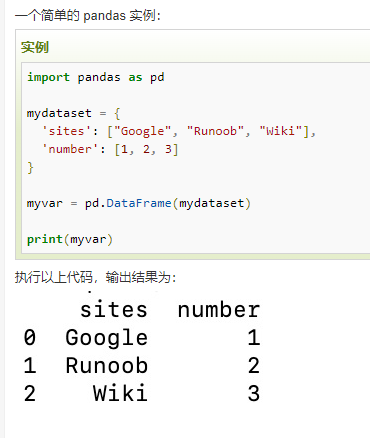
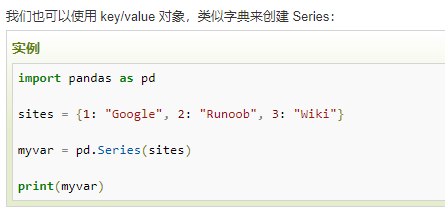
一、Pandas 数据结构 - Series
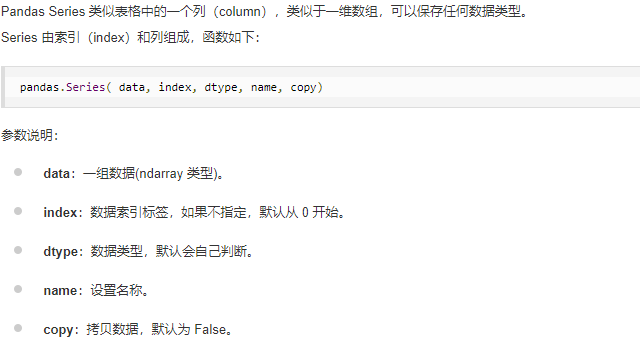
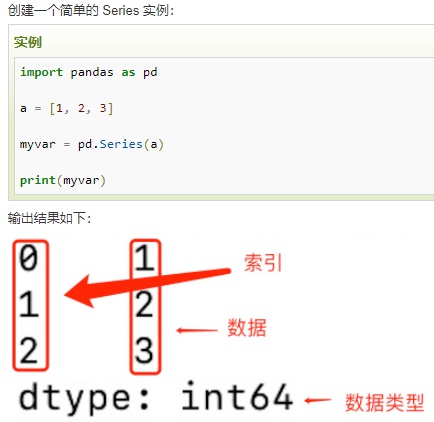
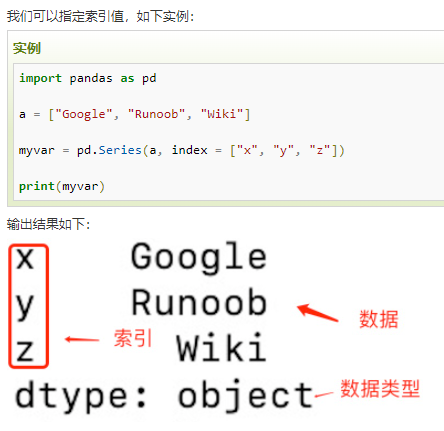
二、Pandas 数据结构 - DataFrame
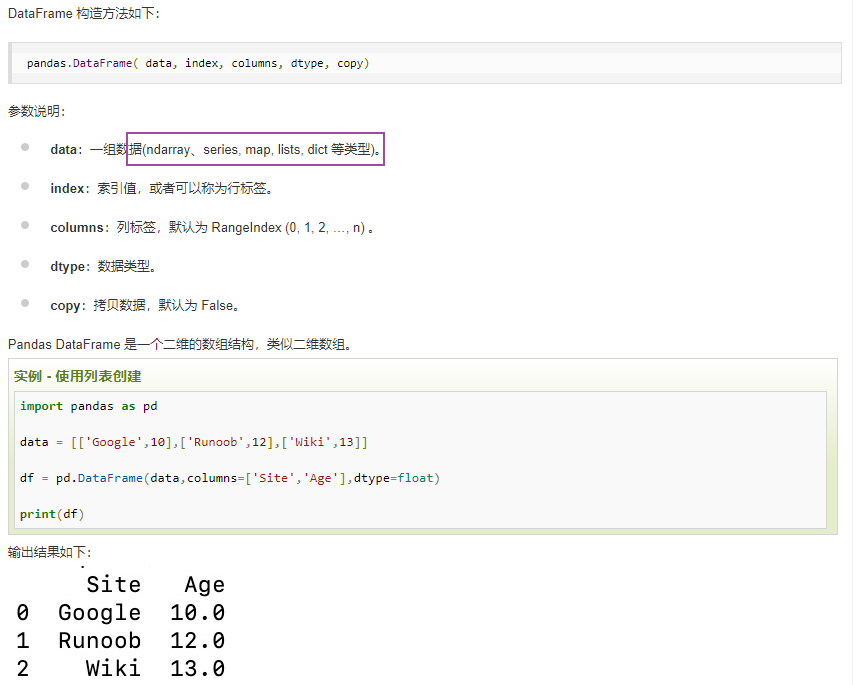
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。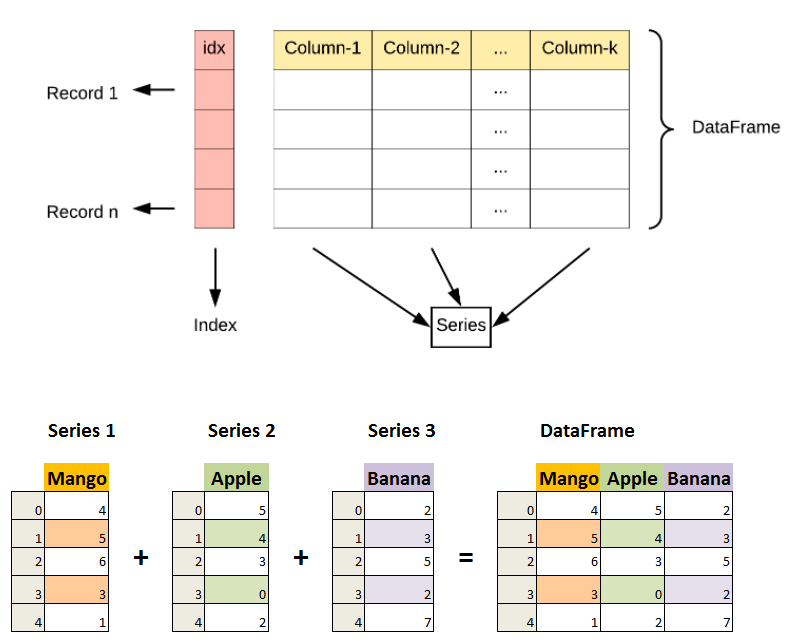
三、Pandas CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。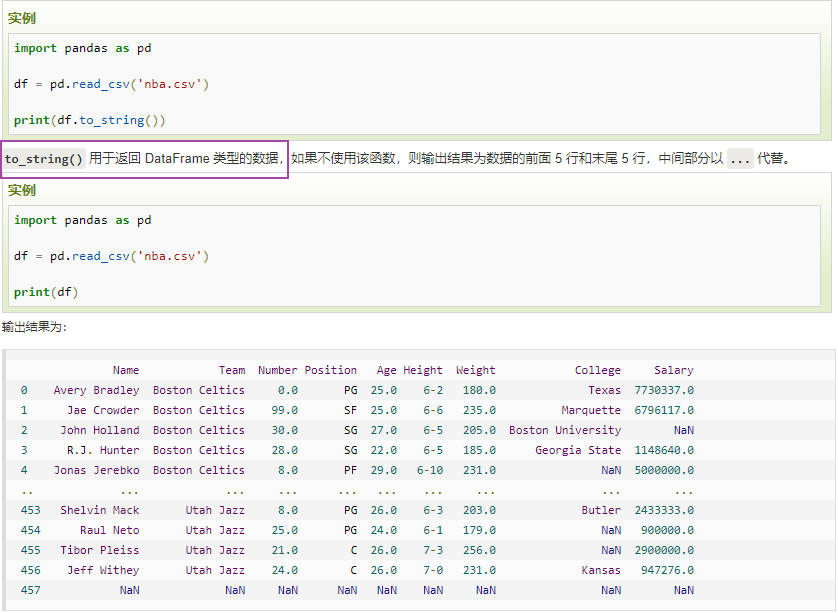
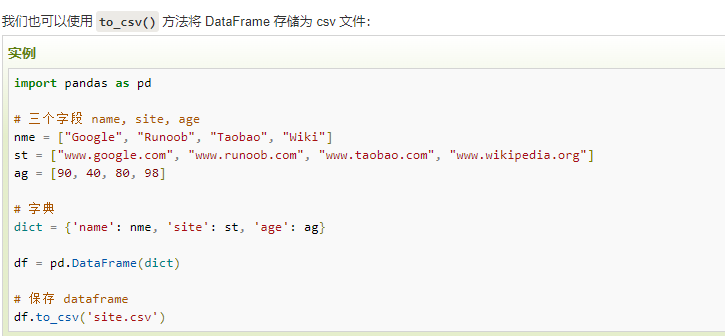
四、Pandas CSV 文件数据处理
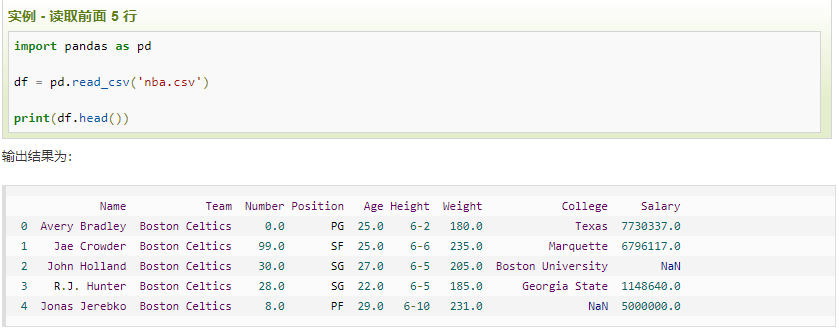
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
info() 方法返回表格的一些基本信息。
五、Pandas JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
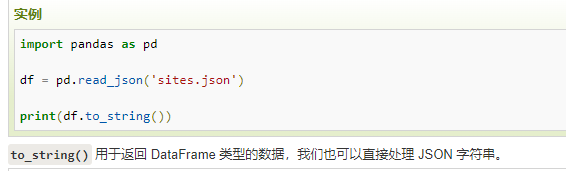
JSON 对象与 Python 字典具有相同的格式,所以我们可以直接将 Python 字典转化为 DataFrame 数据:
import pandas as pd
# 字典格式的 JSON
s = {
"col1":{"row1":1,"row2":2,"row3":3},
"col2":{"row1":"x","row2":"y","row3":"z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
#从 URL 中读取 JSON 数据
import pandas as pd
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL)
print(df)使用 json_normalize() 方法将内嵌的数据完整的解析出来:。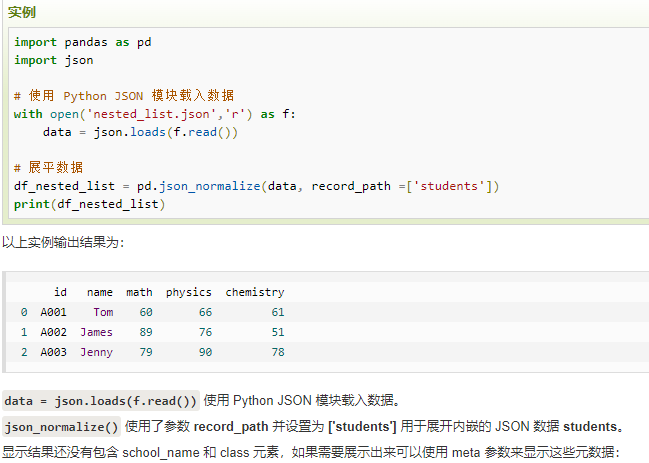
六、Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。
Pandas 清洗缺失数据
- 如果我们要删除包含空字段的行,可以使用 dropna() 方法;
- 可以通过 isnull() 判断各个单元格是否为空;
- 可以用 fillna() 方法来替换一些空字段;
替换空单元格的常用方法是计算列的均值、中位数值或众数。Pandas使用 mean()、median() 和 mode() 方法计算列的均值、中位数值和众数;
Pandas 清洗格式错误数据
我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
Pandas 清洗错误数据
对错误的数据进行替换或移除。可以通过条件语句等等,没有特殊函数。
Pandas 清洗重复数据
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
删除重复数据,可以直接使用drop_duplicates() 方法。















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









