









空降助手
Kubernetes集群部署踩坑记录
部署的时候遇到了问题,顺便记录一下
kubelet cgroup driver: “systemd” is different from docker cgroup driver:
场景复现
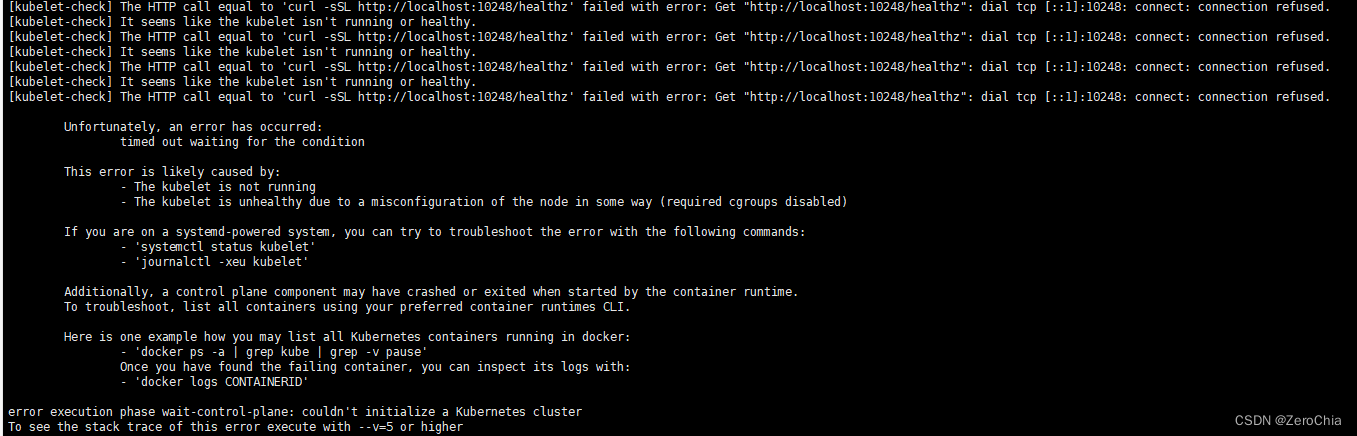
init主节点的时候失败,报错信息:
问题排查
根据提示查kubelet日志,报错信息是:
"Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"
很明显可以看出,kubelet启动失败,原因是kubelet cgroup驱动程序“ cgroupfs”与docker cgroup驱动程序不一致。
这是一个很重要的坑,docker的cgroup必须与kubelet一致!!!
解决方案
既然是保持Cgroup Driver配置一致,那就是有两种改法,一种是让docker与kubelet一致,另一种是让kubelet与docker一致。
首先回滚init操作,《Kubernetes集群部署实录》这篇里有讲,不再赘述,然后就是修改配置,以下两种任选其一(或者说看选哪种能生效吧)
1. 修改docker的Cgroup Driver步骤
- 编辑
/etc/docker/daemon.json文件,加入exec-opts配置,改成这样:
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
- 重启docker
[root@k8s-master ~] systemctl daemon-reload # 非常重要
[root@k8s-master ~] systemctl enable docker & systemctl start docker
[1] 3009
[root@k8s-master ~] docker version
docker version
Client: Docker Engine - Community
Version: 20.10.16
API version: 1.41
Go version: go1.17.10
Git commit: aa7e414
Built: Thu May 12 09:19:45 2022
OS/Arch: linux/amd64
Context: default
Experimental: true
Server: Docker Engine - Community
Engine:
Version: 20.10.16
API version: 1.41 (minimum version 1.12)
Go version: go1.17.10
Git commit: f756502
Built: Thu May 12 09:18:08 2022
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.8
GitCommit: 9cd3357b7fd7218e4aec3eae239db1f68a5a6ec6
runc:
Version: 1.1.4
GitCommit: v1.1.4-0-g5fd4c4d
docker-init:
Version: 0.19.0
GitCommit: de40ad0
[1]+ Done systemctl enable docker
2. 修改kubelet的Cgroup Driver步骤
- 编辑
/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf文件,增加--cgroup-driver=cgroupfs配置,改成这样:
1 # Note: This dropin only works with kubeadm and kubelet v1.11+
2 [Service]
3 Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --cgroup-driver=cgroupfs"
4 Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
5 # This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
6 EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
7 # This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
8 # the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
9 EnvironmentFile=-/etc/sysconfig/kubelet
10 ExecStart=
11 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
- 重启kubelet
[root@k8s-master ~] systemctl daemon-reload
[root@k8s-master ~] systemctl restart kubelet
kubelet与docker的cgroup-driver配置一致后,再重新初始化master节点,即可解决该问题。
k8s-node1 NotReady
场景复现
node1节点加入集群后,在master上一直显示NotReady:

问题排查
查看kubelet日志,发现kubelet停了

解决方案
需要重置一下node节点的kubelet,先删除 node节点上的/etc/kubernetes文件夹,然后重启kubelet
[root@wnccqo6a k8s_install] rm -rf /etc/kubernetes
[root@wnccqo6a k8s_install] systemctl stop kubelet
[root@wnccqo6a k8s_install] systemctl start kubelet
重新执行加入集群命令,即可解决
token过期,加入集群失败
场景复现
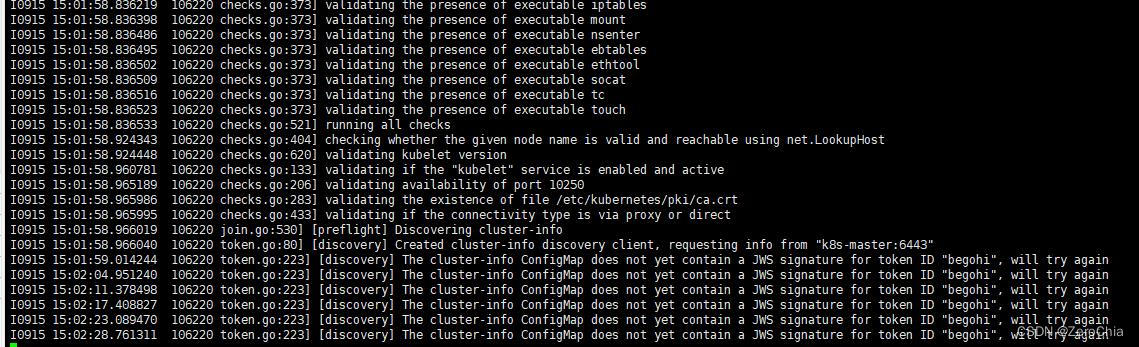
token过期时,会报错token无响应:
问题排查
k8s的token默认有效期是24小时,过期需要手动重新生成
解决方案
在master上重新生成token
[root@gfaa3wjs k8s_install] kubeadm token create
kz1mni.7qfgwce89wqdeb
未记录的token也可以在master上重新找回,参考命令:
[root@gfaa3wjs k8s_install]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
kz1mni.7qfgwce89wqdeb 23h 2022-09-16T07:08:18Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
Nameserver limits exceeded
场景复现
node加入集群时遇到一个报错,显示:“Nameserver limits exceeded” err=“Nameserver limits were exceeded, some nameservers have been omitted, the applied nameserver line is: 223.5.5.5 223.6.6.6 202.99.96.68”

问题排查
意思应该是 nameserver 超出限制,超出的被忽略,去对应的node节点查看/etc/resolv.conf:
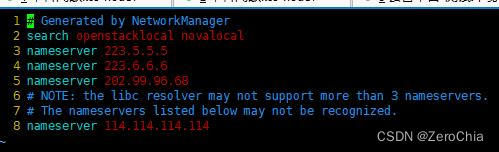
果然超过了3条记录
解决方案
随便删掉两条nameserver,重启docker:
[root@ghe7gea0 ~] systemctl restart docker
再去master上查看节点,已经正常
[root@gfaa3wjs k8s_install] kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 25h v1.23.6
k8s-node1 Ready <none> 134m v1.23.6
k8s-node2 Ready <none> 15m v1.23.6

















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









