









使用tensorflow经典的深度学习框架,使用python对其进行提取数据集的数据,并训练模型后,将本次构建的模型能实现应用。(注本次实验,由于自己写的tensorflow程序出现了数据爆炸将电脑多次卡死的现象,这里参考了https://github.com/little-zhao/tensorflow2.0_lstm_poem中的代码进行改写)
(1):tensorflow学习中遇到的问题和方法
作为一名刚刚学习python和使用tensorflow的新手,记录在写程序中犯的错误。
1使用电脑跑数据发现又出现了上次一样的问题,说找不到安装的cuda的库,仔细查看了电脑安装路径发现其实是存在的,这个时候怀疑pycharm自己升级了tensorflow的版本导致GPU对不上,查看过程中发现果然有个奇怪的-ensorflow版本是2.1.0;但是我电脑适配的应该是tensorflowgpu=2.0.0版本;所以搞了一下午的卸载重装tensorflow的版本,依旧没有解决。

后来发现在命令窗口中输入nvcc -V,显示不是外部命令,这时候怀疑是环境变量没有装好。果然上一次实验装的环境变量因为电脑重启了,就失效了,而且除了上次说的安装变量的地方,还需要在PATH中安装;搞定这个就在重启电脑即可正常使用GPU运行程序。
具体步骤可见我的这两篇博客中:
https://blog.csdn.net/ZhangLH66/article/details/106655005
https://blog.csdn.net/ZhangLH66/article/details/106862609
2第二个错误就非常尴尬因为按照老师给的数据集,我读取出来,先是发现读取的data输入模型出现格式错误,随后尝试在按照pytorch的DataLoader用tensorflow写,方式如下:

在把data.Size作为LSTM的输入,就出现了数据爆炸的问题;重复多次出现了电脑卡机不动的情况;没有办法只好查看下别人怎么写的;结果发现老师给的数据集tang.npz都是在pytorch框架中使用的;最后参考了https://github.com/little-zhao/tensorflow2.0_lstm_poem
处理数据集的框架,在其基础上更改模型和参数实现最终的自动写诗输出。
(2)学习RNN-lstm-GRU网络
之前使用的CNN网络在语言处理和文本生成中有一个缺点在于,无法进行上下文联系。RNN网络则可以对序列数据进行建模,它的网络输出的后一个数和前一个数是相互关联的,隐藏层之间的节点相互关联,但是这个网络结构也有一个弱点,当输入的文本数据过多的时候会出现梯度爆炸和梯度消失的问题。

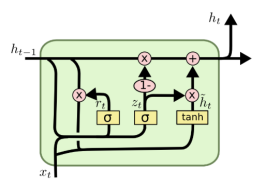
而LSTM就对RNN网络的缺点进行了改进,用于改善RNN在长时间内存储信息的困难。相对RNN只有一个保存短期的状态还增加了cell state以达到保存长期的状态。LSTM通过遗忘门决定从细胞中丢弃什么信息,通过输入门确定什么信息被放入细胞中,输出门决定输出什么。

而GRU则比较新是14年提出来的LSTM变体,将遗忘门和输入门合成一个,同时混合了细胞和隐藏状态,最终实现的模型参数更简洁。
(3)将训练好的模型进行保存,并且输入“湖光秋月两相和”作为前文,生成一首完整的诗句
三:解决方案
(一)开发环境:pycharm+python3.5
(二)整个项目需要导入的代码:
import math
import re
import numpy as np
import tensorflow as tf
from collections import Counter
import matplotlib.pyplot as plt
import time
import os
from numba import cuda
(三)函数和网络结构设计:一次训练数据设置为308(视电脑性能决定),epoch初始设置为30次,drop=0.5,利用TimeDistribute对每个step输出都用softmax激活处理,随后为了提高准确度可以对以上的参数进行更改。
网络结构使用了LSTM和GPU两种版本比较效果
损失函数使用的多分类损失函数
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[‘accuracy’]
)
对训练模型进行预测
网络结构主要使用keras提供的API进行编写使用了LSTM和GRU两个版本对照,谁的结果输出的更像人写出来的诗
#搭建网络层
#LSTM
model = tf.keras.Sequential([
# 词嵌入层
tf.keras.layers.Embedding(input_dim=tokenizer.dict_size, output_dim=125),
# 第一个LSTM层
tf.keras.layers.LSTM(125, dropout=0.5, return_sequences=True),
# 第二个LSTM层
tf.keras.layers.LSTM(125, dropout=0.5, return_sequences=True),
# 利用TimeDistributed对每个时间步的输出都做Dense操作(softmax激活)
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.dict_size, activation=‘softmax’)),
])
model.summary()
#GRU
model = tf.keras.Sequential([
# 词嵌入层
tf.keras.layers.Embedding(input_dim=tokenizer.dict_size, output_dim=125),
# 第一个LSTM层
tf.keras.layers.GRU(125, dropout=0.5, return_sequences=True),
# 第二个LSTM层
tf.keras.layers.GRU(125, dropout=0.5, return_sequences=True),
# 利用TimeDistributed对每个时间步的输出都做Dense操作(softmax激活)
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.dict_size, activation=‘softmax’)),
])
model.summary()
四:实验分析和总结
数据集介绍:在本次实验中一共尝试了两个数据集,第一个老师提供的tang.npz,因为程序编写的问题,在数据爆炸后就弃用了,换成了比较多资料参考的poetry.txt,其实两者使用的文本数据是一样的,只是前者已经分好了数据和编码的工作,后者还需要进行数据预处理和编码的工作。数据集一共包含四万多首唐诗,数据处理中对于过长过短的诗句进行屏蔽,无效的符号和题目也进行删除。

(1)实验结果分析:
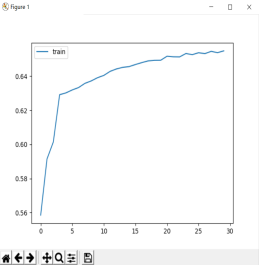
使用GPU用GRU模型跑30次后的训练的结果

输入湖光秋月两相和后的诗句结果

随便输出的五首生成的诗

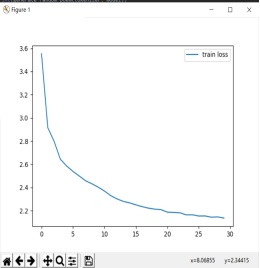
最后的损失和精确度

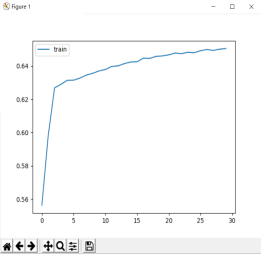
使用LSTM跑30次后的结果:

输入湖光秋月两相和后的诗句结果

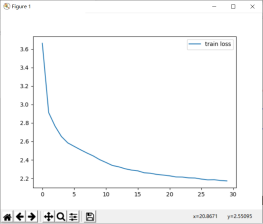
随便输出的五首生成的诗

最后的损失和精确度

(三)总结:
本实验基本完成课程设计要求,使用GRU模型跑30次的结果最后loss可以降到2.14,accuracy=0.65左右,使用LSTM跑30次后的结果最后loss可以降到2.17 , accuracy=0.65 左右,虽然两者的差别不是很大,使用GRU生成了三句,使用LSTM生成了7句,比较最后输出的诗句结果LSTM有重复字,两者都有些押韵的样子,就我个人的体会觉得GRU会更好一点点。















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









