







本文介绍 Python 语言调用 sklearn 包中 K-Means 算法实现聚类的方法。
在 sklearn 包中,常用的 K-Means 方法有两种:KMeans 和 MiniBatchKMeans
两种方法的参数相似,常用参数如下:
n_clusters:聚类数量,即 k 值,默认为 8
init:初始化聚类中心的方法,如需自定义设置,则传入 ndarray 格式的参数
n_init:用不同的初始化聚类中心运行算法的次数,默认为 10,如自定义设置初始聚类中心,则置为 1
max_iter:最大迭代次数,默认为 300
batch_size:(仅 MiniBatchKMeans)批次大小,默认为 100
verbose:是否打印日志,默认为否
注:自定义设置初始聚类中心的一个用处是去除算法的随机性,即防止每次运行结果不一样。
随机生成一组算例,给出代码和可视化结果作为示例:
基本参数:
NUM_POINT = 500 # 点的总数
RAN_COO = (0, 100) # 坐标范围
NUM_CLUSTER = 20 # 聚类数量
MAX_ITERATION = 5000 # 最大迭代次数
NUM_BATCH = 10 # 批次数量
随机生成算例:
import random
import pandas as pd
edge_width= 1 # 坐标边界宽度
random.seed(612)
list_coo_x = [random.randint(RAN_COO[0] + edge_width, RAN_COO[1] - edge_width) for _ in range(NUM_POINT)]
list_coo_y = [random.randint(RAN_COO[0] + edge_width, RAN_COO[1] - edge_width) for _ in range(NUM_POINT)]
df_point = pd.DataFrame({'x': list_coo_x, 'y': list_coo_y})
模型初始化:
from sklearn.cluster import KMeans, MiniBatchKMeans
# 方式 1: KMeans 方法;初始聚类中心的生成方式为默认
model = KMeans(n_clusters=NUM_CLUSTER, max_iter=MAX_ITERATION, verbose=True)
# 方式 2: MiniBatchKMeans 方法;初始聚类中心的生成方式为默认
model = MiniBatchKMeans(n_clusters=NUM_CLUSTER, max_iter=MAX_ITERATION, batch_size=round(NUM_POINT / NUM_BATCH), verbose=True)
# 方式 3: KMeans 方法;自定义初始聚类中心
model = KMeans(n_clusters=num_cluster_adjust, init=init, n_init=1, max_iter=MAX_ITERATION, verbose=True)
# 方式 4: MiniBatchKMeans 方法;自定义初始聚类中心
model = MiniBatchKMeans(n_clusters=NUM_CLUSTER, init=init, n_init=1, max_iter=MAX_ITERATION, batch_size=round(NUM_POINT / NUM_BATCH), verbose=True)
(附)一种自定义初始聚类中心的方法:
思路:将点集所在的矩形区域划分为格子,取每个小格的中心作为初始聚类中心
from typing import Tuple, List
import math
def get_init_centres(num_cluster: int, ran_x: Tuple[float, float], ran_y: Tuple[float, float],
per_adjust_n: float = 0.05) -> Tuple[int, List[Tuple[float, float]]]:
"""
获取初始聚类中心的坐标
:param num_cluster: 聚类数量
:param ran_x: 区域的横坐标范围
:param ran_y: 区域的纵坐标范围
:param per_adjust_n: 聚类数量允许调整的百分比,默认0.05
:return: num_cluster_adjust: 调整后的聚类数量
:return: list_pos_centres: 初始聚类中心的坐标列表
"""
print(">> 获取初始聚类中心的坐标,开始")
def get_nearest_divisors(number: int) -> Tuple[int, int]:
"""
获取一个整数最相邻的两个约数
:param number: 一个大的整数
:return: a: 较小的约数
:return: b: 较大的约数
"""
init_value = int(math.sqrt(number))
a, b = init_value, init_value
while (a * b != number) and (a > 0):
if a * b < number:
b += 1
else:
a -= 1
return a, b
# 横坐标范围和纵坐标范围,哪一个为长边
if_len_x = True if ran_x[1] - ran_x[0] >= ran_y[1] - ran_y[0] else False
len_x_y = ran_x[1] - ran_x[0] if if_len_x else ran_y[1] - ran_y[0]
wid_x_y = ran_y[1] - ran_y[0] if if_len_x else ran_x[1] - ran_x[0]
# 聚类数量的可调整范围
lb_num_cluster = math.ceil((1 - per_adjust_n) * num_cluster)
ub_num_cluster = math.floor((1 + per_adjust_n) * num_cluster)
# 调整聚类数量,使其尽可能符合坐标范围的长宽比
len_cluster, wid_cluster = num_cluster, 1
diff = 1
for n in range(lb_num_cluster, ub_num_cluster + 1):
tmp_wid, tmp_len = get_nearest_divisors(n)
tmp_diff = abs(tmp_wid / tmp_len - wid_x_y / len_x_y)
if tmp_diff < diff:
len_cluster, wid_cluster = tmp_len, tmp_wid
diff = tmp_diff
# 结果输出:调整后的聚类数量
num_cluster_adjust = len_cluster * wid_cluster
# 结果输出:初始聚类中心的坐标列表
if if_len_x:
list_x_centres = [ran_x[0] + len_x_y / (2 * len_cluster) + len_x_y / len_cluster * i
for i in range(len_cluster)]
list_y_centres = [ran_y[0] + wid_x_y / (2 * wid_cluster) + wid_x_y / wid_cluster * j
for j in range(wid_cluster)]
else:
list_x_centres = [ran_x[0] + wid_x_y / (2 * wid_cluster) + wid_x_y / wid_cluster * j
for j in range(wid_cluster)]
list_y_centres = [ran_y[0] + len_x_y / (2 * len_cluster) + len_x_y / len_cluster * i
for i in range(len_cluster)]
list_pos_centres = [(x, y) for x in list_x_centres for y in list_y_centres]
print("<< 获取初始聚类中心的坐标,结束")
return num_cluster_adjust, list_pos_centres
import numpy as np
ran_x, ran_y = (min(df_point['x']), max(df_point['x'])), (min(df_point['y']), max(df_point['y']))
num_cluster_adjust, list_centre_initial = get_init_centres(num_cluster=NUM_CLUSTER, ran_x=ran_x, ran_y=ran_y)
if num_cluster_adjust != NUM_CLUSTER:
print("聚类数量由 {0} 调整为 {1}".format(NUM_CLUSTER, num_cluster_adjust), '\n')
init = np.array(list_centre_initial, dtype=np.float64) # 自定义聚类中心的格式
算法运行:
model.fit(df_point)
结果处理:
df_centre = pd.DataFrame(model.cluster_centers_, columns=['x', 'y']).reset_index()
se_category = pd.Series(model.labels_, index=df_point.index)
df_res = pd.concat([df_point, se_category], axis=1)
df_res.rename(columns={0: "category"}, inplace=True)
print("最终聚类数量: {}".format(len(set(df_res["category"]))), '\n')
结果可视化:
from matplotlib import pyplot as plt
list_color = ["red", "green", "blue", "orange", "purple", 'darkorange', 'deepskyblue', 'lime', 'fuchsia', "grey"]
list_marker = ['.', 'o', 's', 'x', '+', '*', 'p', 'v', '^', '<', '>', '1', '2', '3', '4']
i = 0
for c, df in df_res.groupby("category"):
x, y = df['x'], df['y']
plt.scatter(x=x, y=y, c=list_color[i % len(list_color)], marker=list_marker[i % len(list_marker)], alpha=1)
i += 1
plt.xlim(RAN_COO[0], RAN_COO[1])
plt.ylim(RAN_COO[0], RAN_COO[1])
上述算例的可视化结果:
方式 1: KMeans 方法;初始聚类中心的生成方式为默认
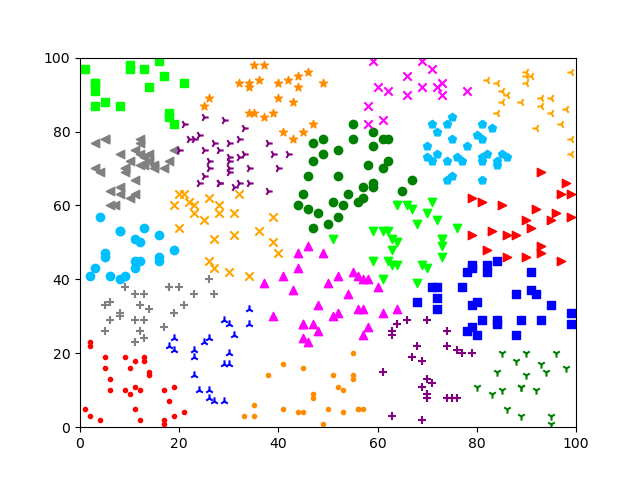
方式 2:MiniBatchKMeans 方法;初始聚类中心的生成方式为默认
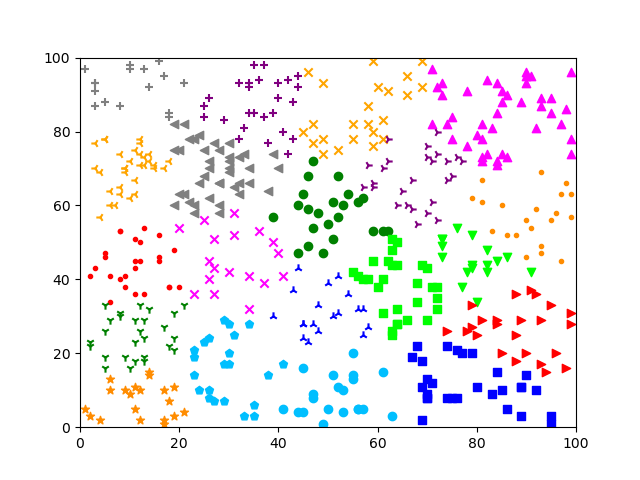
方式 3: KMeans 方法;自定义初始聚类中心
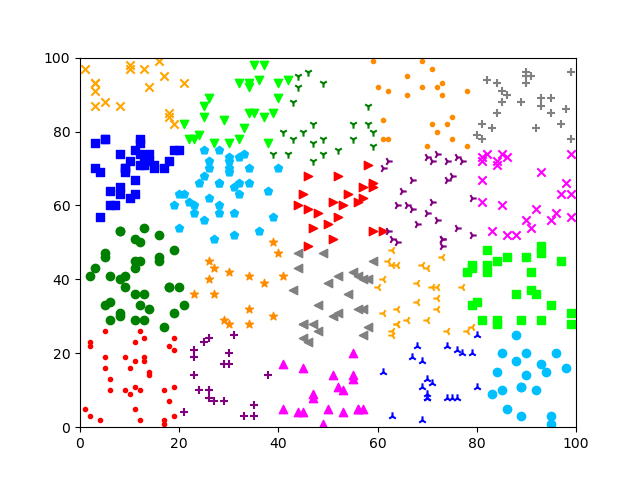
方式 4: MiniBatchKMeans 方法;自定义初始聚类中心
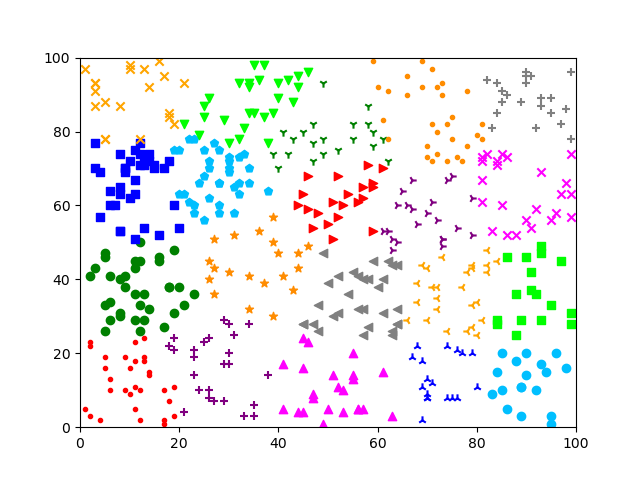















 1719
1719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









