









本文为 LeetCode 有关哈希表的问题。
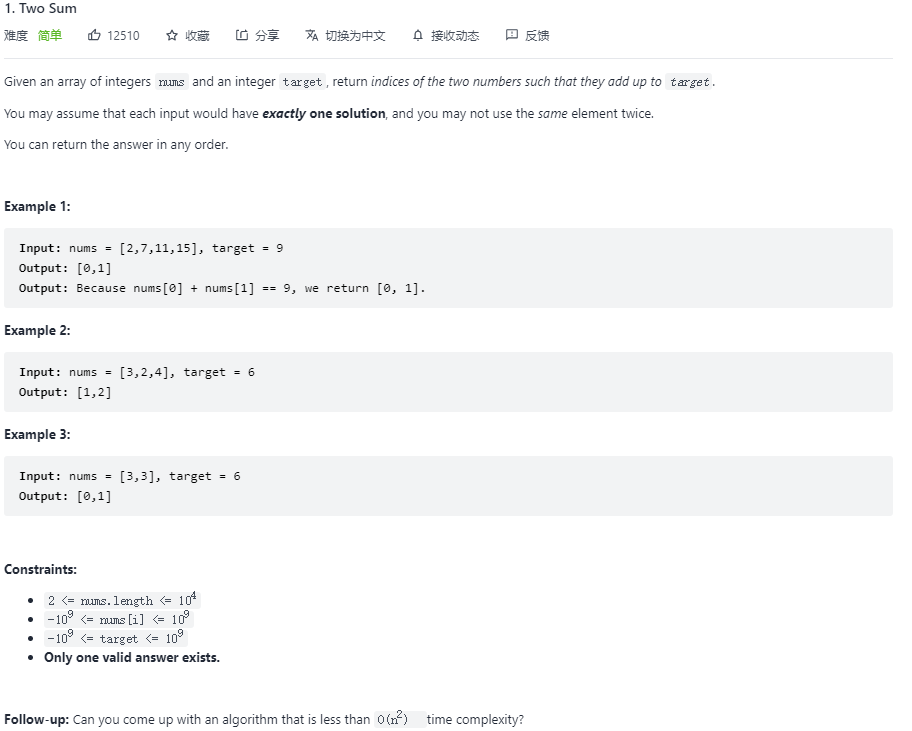
1. Two Sum(两数之和)
问题描述
思路与代码
题目中特别指出,可否找到时间复杂度低于 O ( n 2 ) O(n^2) O(n2) 的方法,答案即为哈希表。
代码如下:
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
dic = {}
for i in range(len(nums)):
if target - nums[i] in dic:
return [dic[target - nums[i]], i]
dic[nums[i]] = i
return []
运行效果:

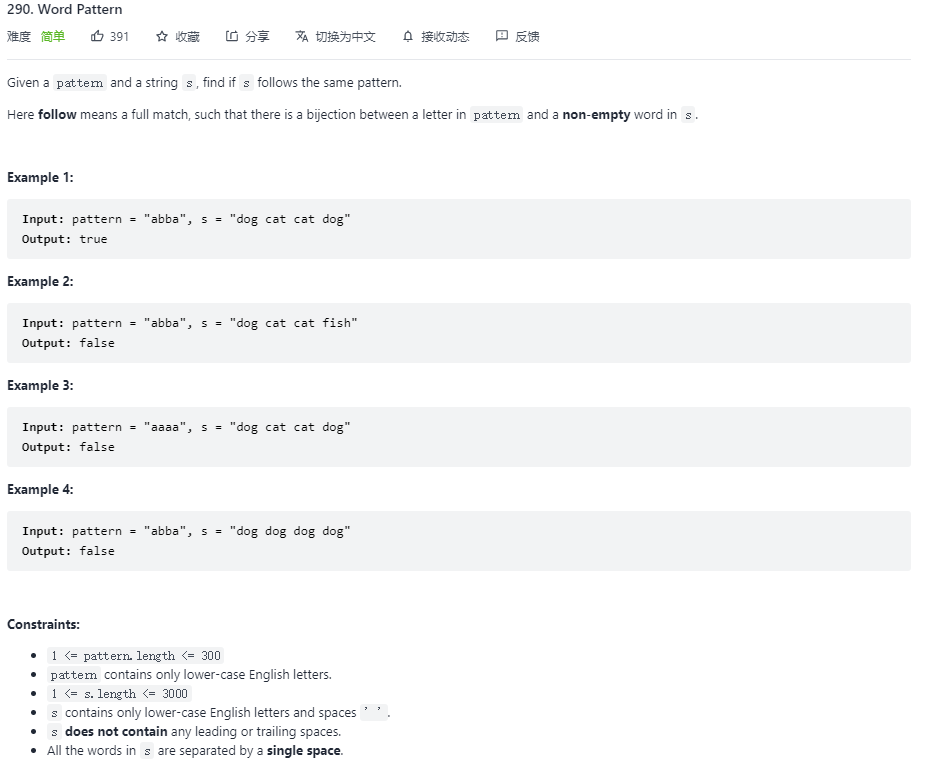
290. Word Pattern(单词规律)
问题描述
思路与代码
本题思路较为简单,只需要通过 pattern 对应单词和单词对应 pattern 两个字典,判断模式是否符合即可,由于两个字典为互逆的关系,其中一个可以简化为集合。
代码如下:
class Solution:
def wordPattern(self, pattern: str, s: str) -> bool:
list_word = s.split(' ')
if len(pattern) != len(list_word): # 长度不匹配,直接返回 False
return False
dict_pattern, set_word = {}, set()
for i in range(len(pattern)):
char, word = pattern[i], list_word[i]
if char in dict_pattern.keys():
if word != dict_pattern[char]:
return False
else:
if word in set_word:
return False
else:
dict_pattern[char] = word
set_word.add(word)
return True
运行效果:

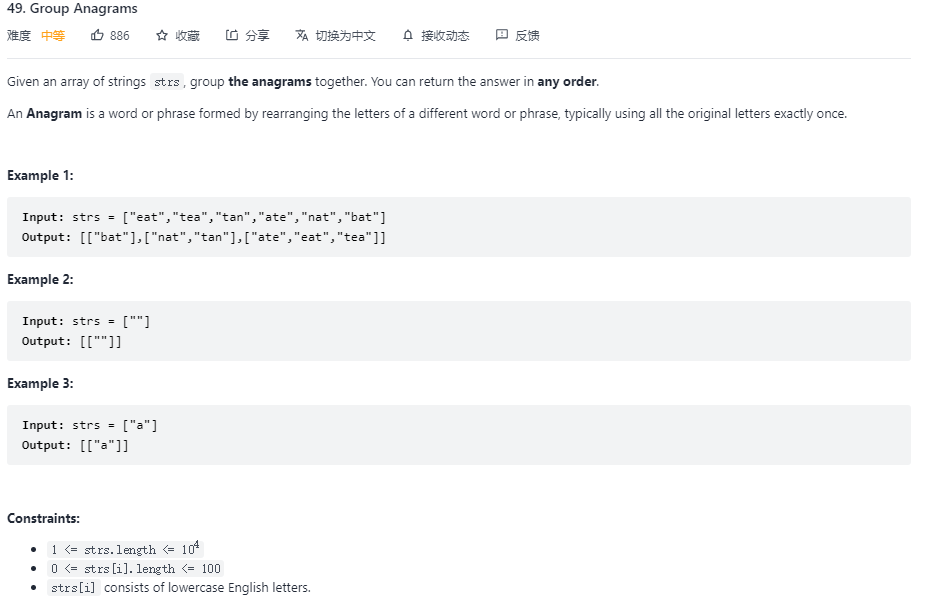
49. Group Anagrams(字母异位词分组)
问题描述
思路与代码
本题较自然的思路是,遍历每个单词,将单词的字母按字母表顺序排序,然后以排序后的字符串为 key,查询并更新类型字典,得出最终结果。
代码如下:
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
dic_type = {}
for i in range(len(strs)):
word = strs[i]
word = "".join(sorted(list(word))) # 单词按字母表顺序排序
if word not in dic_type:
list_new = [strs[i]]
dic_type[word] = list_new
else:
dic_type[word].append(strs[i])
list_group = list(dic_type.values())
return list_group
运行结果看起来还不错:

但其实,代码是有优化空间的。
由于对单词中的字母进行了排序操作,会增加算法的复杂度。这里可以通过将字母转化为自然数中的第 i i i 个素数( i i i 为字母序号)并累乘,使每种单词类型对应为一个数字(一系列素数的乘积),达到将排序算法中的 O ( n log n ) O(n \log n) O(nlogn) 的复杂度优化为 O ( n ) O(n) O(n) 的目的。
具体代码如下:
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
# 素数字典
list_prime = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101]
dict_prime = {chr(i + 97): list_prime[i] for i in range(26)}
dic_group = {}
for word in strs:
product = 1
for letter in word:
product *= dict_prime[letter]
if product in dic_group:
dic_group[product].append(word)
else:
dic_group[product] = [word]
return list(dic_group.values())
提交运行后,效果比较有趣。
编程语言选用 Python3 时,有时甚至没有明显的优化效果:

选用 Python 时,优化效果相对较为稳定:

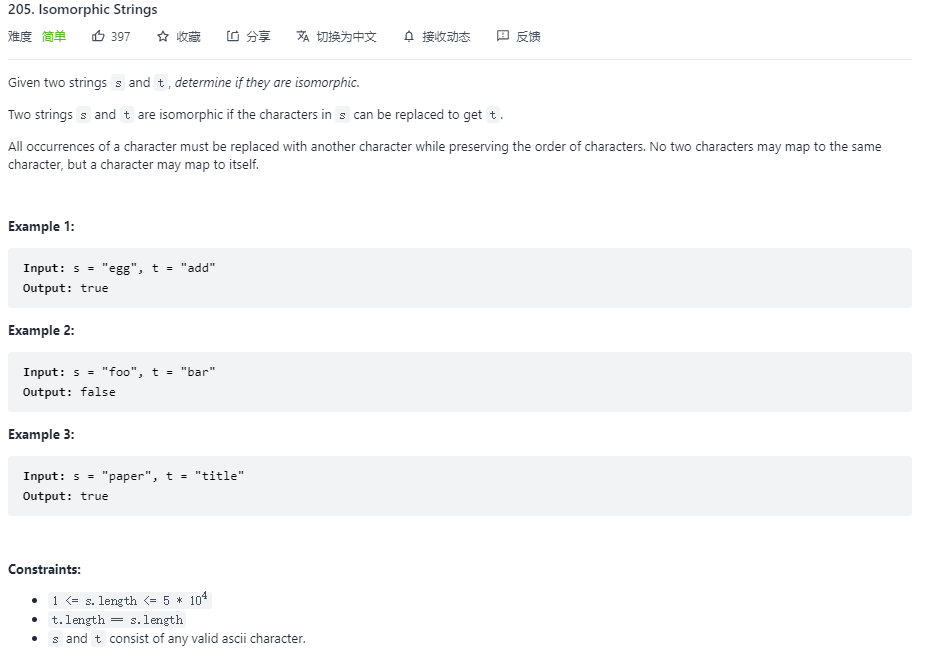
205. Isomorphic Strings(同构字符串)
问题描述
思路与代码
本题的思路也较简单,可以为两个字符串分别定义一个字母代号字典,代号即为该字母首次出现的位置,按位遍历两个字符串,只要发现某位置的字母代号不同,即为非同构,若遍历结束,则为同构。
代码如下:
class Solution:
def isIsomorphic(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
dict_letter_s, dict_letter_t = {}, {} # 字母代号字典
for i in range(len(s)):
# 更新字典
if s[i] not in dict_letter_s.keys():
dict_letter_s[s[i]] = i
if t[i] not in dict_letter_t.keys():
dict_letter_t[t[i]] = i
if dict_letter_s[s[i]] != dict_letter_t[t[i]]: # 如果当前位的字母所对应的代号不同,则输出 False
return False
return True
运行效果:

进一步,本体也可类似 290 题的方式优化,即将其中一个字典简化为集合,优化后的代码如下:

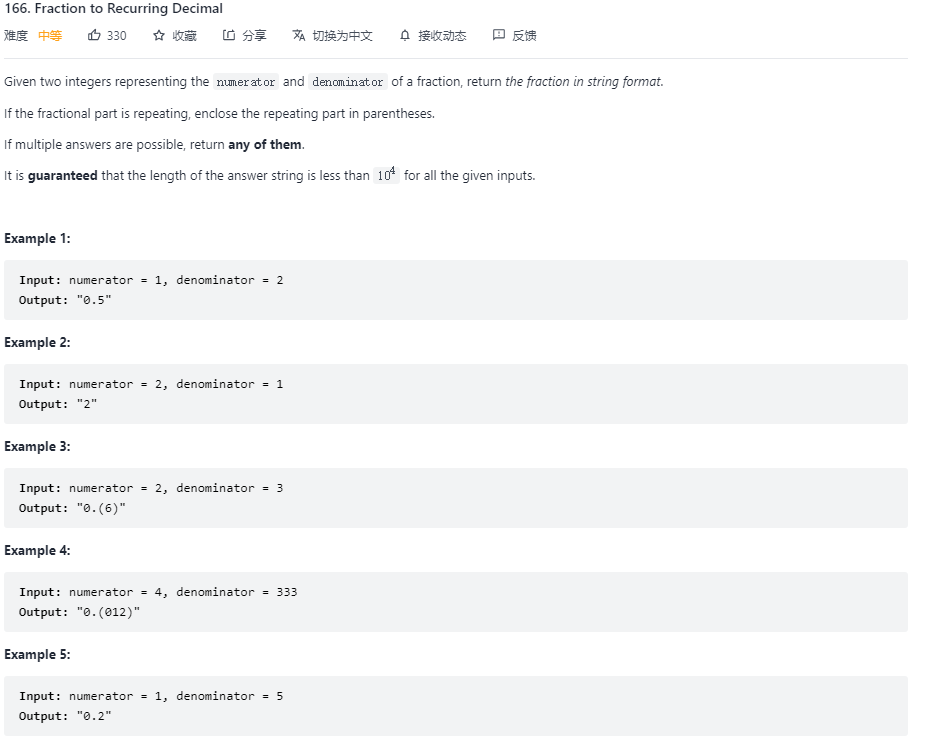
166. Fraction to Recurring Decimal(分数到小数)
问题描述

思路与代码
本题很自然的思路是,通过记录余数的再现,以确定循环节。因此,可以定义一个字典用来记录余数出现的位置。此外,需要考虑两种边界情况,一种是分子为 0 时,直接输出 ‘0’;另一种是分子或分母符号为负的情况,先记录结果的正负,再取绝对值进行计算。
具体代码如下:
class Solution:
def fractionToDecimal(self, numerator: int, denominator: int) -> str:
str_res = ""
# edge case 1: 分子为 0
if not numerator:
return '0'
# edge case 2: 正负数
if_neg = False
if numerator < 0:
if_neg = not if_neg
numerator = abs(numerator)
if denominator < 0:
if_neg = not if_neg
denominator = abs(denominator)
str_res += '-' if if_neg else ''
# 整数部分
itg = int(numerator / denominator)
rem = numerator - itg * denominator # 余数
str_res += str(itg)
str_res += '.' if rem else ''
list_fra = []
dict_rem = {rem: 0} # "余数: 位数" 字典
i = 0 # 位数
rem *= 10
if_loop, loop_period = False, [] # 是否存在循环节,循环节的位置
while rem:
i += 1 # 更新位数
if rem < denominator: # 若余数小于分母,将其扩大 10 倍
list_fra.append('0')
rem *= 10
continue
fra = int(rem / denominator) # 当前位的小数
list_fra.append(str(fra))
rem -= fra * denominator # 更新余数
if rem not in dict_rem.keys(): # case 1: 暂未发现循环节
dict_rem[rem] = i
else: # 发现循环节,将循环节的首末位记录在字典中
if_loop, loop_period = True, (dict_rem[rem], i)
break
rem *= 10 # 余数扩大 10 倍
str_fra = ''.join(list_fra[: loop_period[0]]) + '(' + ''.join(
list_fra[loop_period[0]: loop_period[1]]) + ')' if if_loop else ''.join(list_fra) # 小数部分
str_res += str_fra
return str_res
运行效果:
















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









