







前几天,抖音弄了个算法公开日,首度把它们神秘莫测的算法公开了,还公布在自家的安全官网上,入口:
http://95152.douyin.com
这是抖音第一次敞开聊自己的「算法黑盒」。
里面很多内容,非常值得一看!
我把它们从头到尾过了一遍,虽然官方写的很清晰,但普通小伙伴想要弄懂仍然会比较吃力,于是专门调了个 Prompt,让 AI 帮忙翻译。
效果竟然出奇的好。
接下来,就让我们一起揭开抖音「算法黑盒」的神秘面纱。
一切的起点:为什么需要算法推荐?
因为:信息太多,看不过来!
我们现在生活在一个信息的“海洋”里,每天都有无数的新闻、视频、商品涌出来(文章里提到,2025年全球数据量大到一个人下载需要18亿年!)。
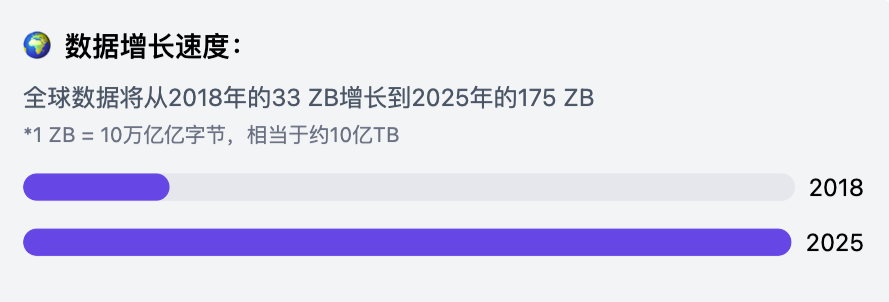
抖音这种平台,每天新增的内容也是天文数字。
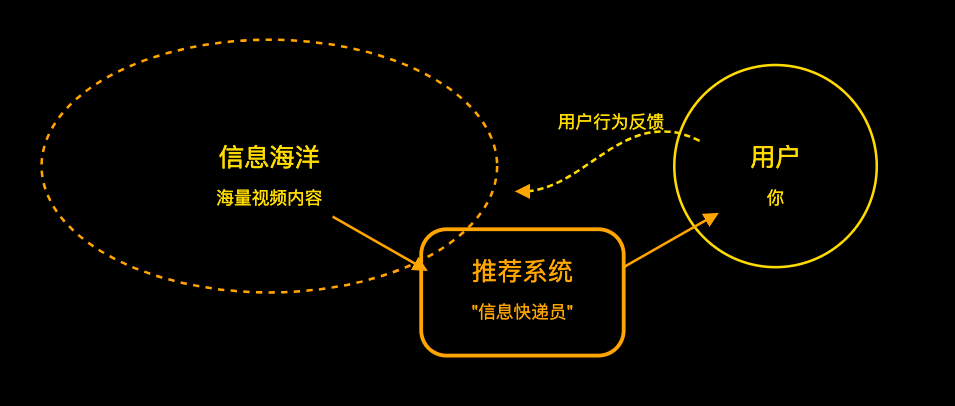
抖音面临的第一个问题:
怎么能在这个“信息海洋”里,让你(用户)不觉得无聊、迷茫,能快速、精准地找到用户可能喜欢的那几条视频,让TA刷得停不下来?
而这,就是推荐系统要干的活儿。
它就像一个为你量身定制的、超级聪明的“信息快递员”,只把“你可能感兴趣”的包裹送到你面前。
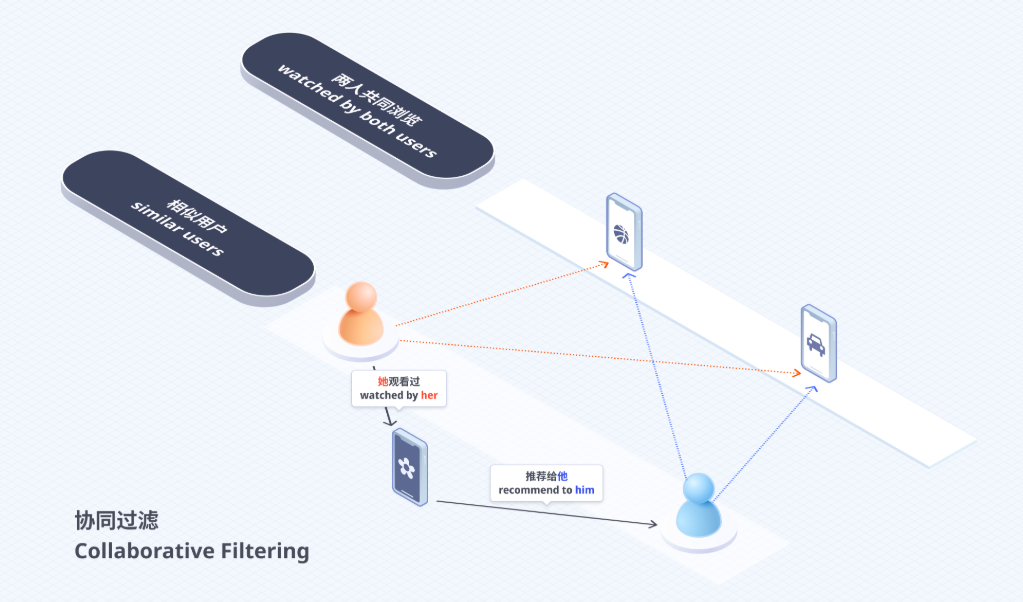
早期方法:协同过滤 (Collaborative Filtering, CF)
这是推荐算法里的“老前辈”了,思路很朴实,但很有效。
主打一个:“物以类聚,人以群分”。
用大白话讲,就是找到和你“臭味相投”的人,看看他们喜欢啥,然后推荐给你。
算法怎么操作?
⬇️ 系统扫描大量用户行为数据(比如点赞、观看时长、评论等);
⬇️ 找到那些和你行为模式很像的用户(比如你们都给同一批萌宠视频点过赞);
⬇️ 看看这些“同好”们还喜欢了哪些你没看过的视频;
➡️ 把这些视频推荐给你。
给它做一个生活化比喻
就像你去餐厅
服务员说:“点这道菜的客人,通常也喜欢我们店的XX汤。”
或者你问朋友:“咱俩口味差不多,最近有啥好剧推荐?”
关键是:这种方法不需要“理解”视频内容!
它不管视频里是猫是狗,是唱歌跳舞,它只关心“谁 (User)” 对 “什么 (Item)” 做了 “什么行为 (Action)”。纯粹基于用户行为的模式匹配。
文章里的图 (Page 2):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2102
2102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









