






复杂网络中常常需要将得到的关系对(图一)转换为邻接矩阵,并存储为csv格式。本文将介绍两方法来进行处理:方法一是构建数据框赋予值。方法二是利用pivot () 函数将一维表转换为二维表。本文所采用的例子为有向加权网络。
首先我们的原始数据为关系对(图一):
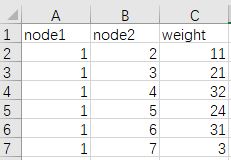
因此可以看到节点列为node1和node2,权重列为weight。接下来转换为邻接矩阵。
方法一:构建数据框并赋予值
原理:这个方法是提取出列作为节点,然后进行对应的值输入,形成邻接矩阵。
代码:
import pandas as pd
import numpy as np
#导入你的数据
data = pd.read_csv('./yourdata.csv')
vals = np.unique(data[['origin_x', 'origin_y']]) # 同时取出两列,作为节点
df = pd.DataFrame(0, index=vals, columns=vals)
f = df.index.get_indexer
df.values[f(data.origin_x), f(data.origin_y)] = 1
print(df)输出结果:

方法二:pivot函数
原理:pivot()函数是python中自带的函数,可以直接使用,非常容易理解。函数的三个参数为:
index:转换后邻接矩阵的行索引。在本例中为node1。
columns:转换后邻接矩阵的列。在本例中为node2.
values:邻接矩阵的权重。如果没有权重时可以不写这个参数。在本例中为weight。
代码:
import pandas as pd
import numpy as np
#导入你的数据
data = pd.read_csv('./yourdata.csv')
#转换为邻接矩阵用pivot()
df = data.pivot(index='node1',columns='node2',values='weight')
#index为行索引,columns为列索引,values是矩阵中填充的值
df = df.reset_index()
df.fillna(0,inplace=True)
print(df)得到的结果:

对于此方法来说,它是根据节点的值形状变化的,第一种方法一定会形成一个对称的邻接矩阵。而第二种方法则是相当于将一维表转换为二维表。因此当节点2和其他节点无交流时,则直接不会显示。














 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









