







内容原文:https://morvanzhou.github.io/tutorials/machine-learning/torch/
利用PyTorch搭建神经网络
神经网络可以使用PyTorch的torch.nn包来构建。
autograd实现了反向传播的功能,但是直接用来深度学习的代码在很多情况下还是稍显复杂。
torch.nn是专门为神经网络设计的模块化接口,nn构建于autograd之上,可以用来定义和运行神经网络。nn.Moudle是nn中最重要的类,可把它看成是一个网络的封装,包含网络各层定义以及forward方法,调用forward(input)方法,可返回前向传播的结果。
一个典型的神经网络训练过程如下:
- 定义具有一些可学习参数(或权重)的神经网络
- 迭代输入数据集
- 通过网络处理输入
- 计算损失(输出的预测值于实际值之间的距离)
- 将梯度传播回网络
- 更新网络的权重,通常使用一个简单的更新规则:weight = weight - learning_rate * gradient
1、Variable变量
在神经网络里,数据都是Variable变量的形式,是把tensor的数据放入神经网络的variable变量中,来慢慢更新神经网络中的参数。
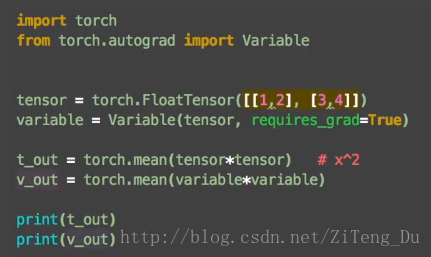
import torch
from torch.autograd import Variable
tensor = torch.FloatTensor([[1,2],[3,4]])
variable = Variable(tensor,requires_grad=True) #用Variable将tensor放入variable变量中
运行结果:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









