







树与堆
之前提到树和堆的一个定义,
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。
堆就是用数组实现的二叉树.
那么树是究竟有几种实现方式呢? 目前来说,是两种
链式存储
基于链表的树,相信大家都能比较直观的理解.
以二叉树为例,
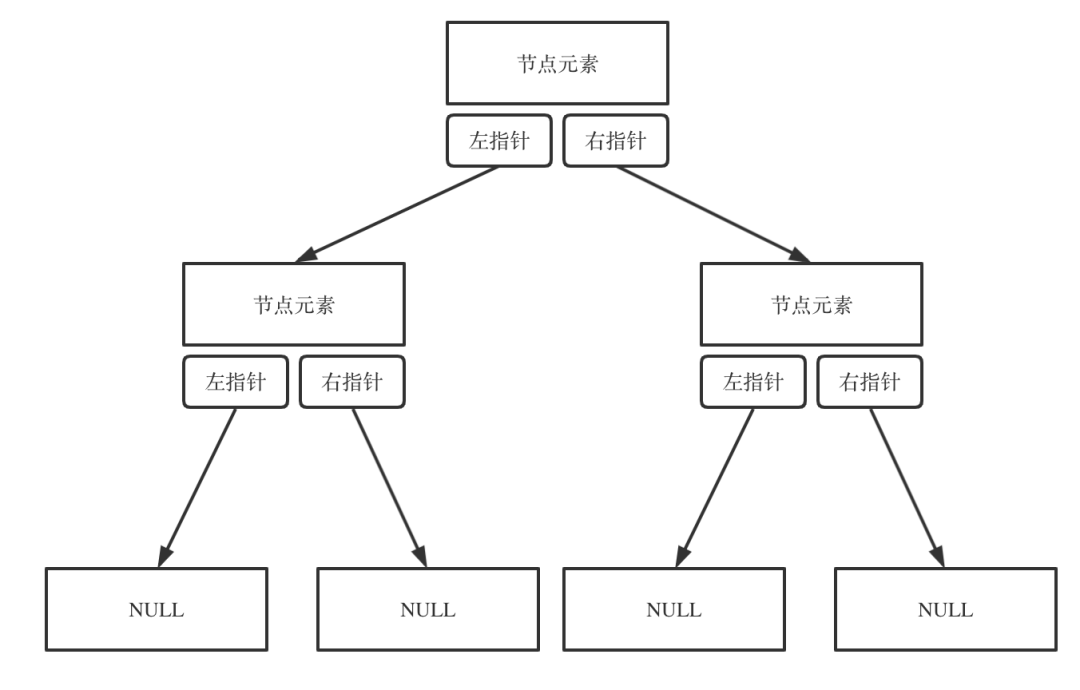
从上图可以看到,树的每个节点是由数据域和指针域构成,一个指针指向父节点,其他的指针指向子节点,根节点没有父节点指针,叶子节点没有子节点指针.
二叉树主要有两种遍历方式:
深度优先遍历:先往深走,遇到叶子节点再往回走。
广度优先遍历:一层一层的去遍历。
深度优先遍历,我们通常使用的是递归的方式,这也是最容易理解的一种,基于遍历顺序分为了,先根序遍历,中根序遍历,后根序遍历,顾名思义,就是根据根节点的遍历顺序来区分的。
arr[] = cur->val; // 中
traversal(cur->left, arr); // 左
traversal(cur->right, arr); // 右
上面的代码就简单的表达了一个先根序遍历的思想.
广度优先遍历,也就是我们常说的层序遍历,通过循环的方式对二叉树进行遍历,直到叶子节点结束。
顺序存储
树的顺序存储方式,也就是基于数组实现的树.
同样的,以二叉树为例,
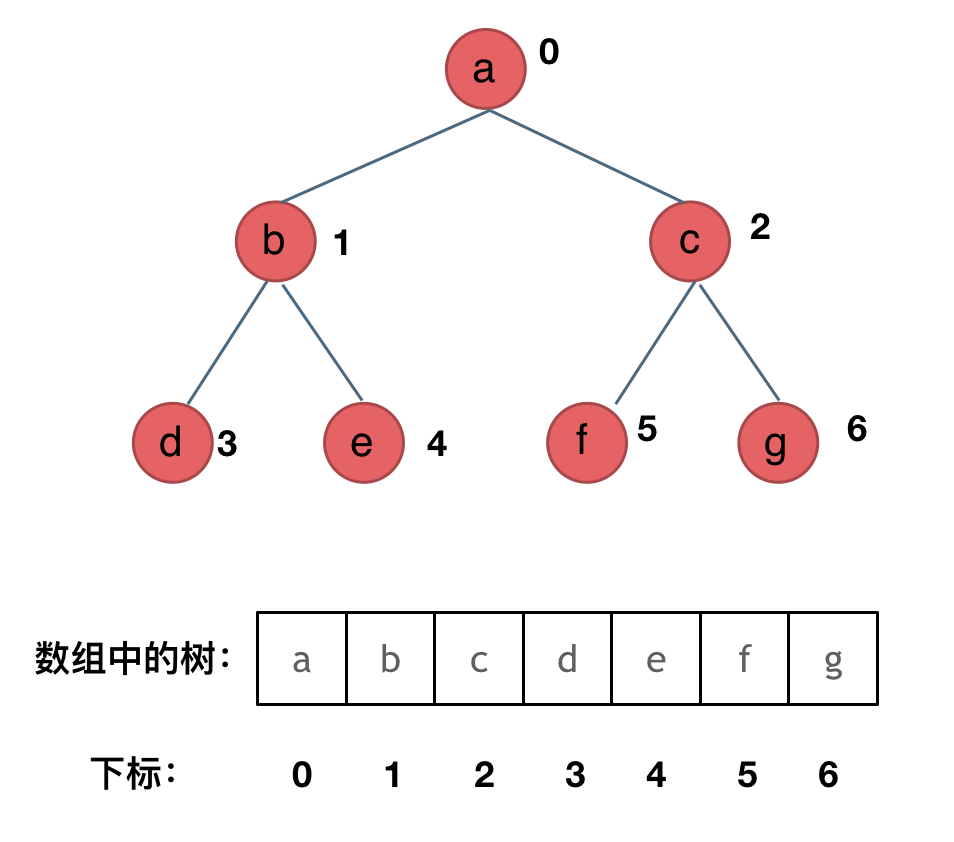
看着上面这个图,我们应该可以较为直观的理解数组实现的树的含义,就是将树的节点以一定的规则顺序存入到数组中.
以上图为例,就是以层序遍历的方式,将整个二叉树的每个节点的值存入数组中,在这个场景中,这个数组就代表了我们这一个二叉树,也就是顺序存储的二叉树.
需要注意的是,顺序存储只适用于完全二叉树。换句话说,只有完全二叉树才可以使用顺序表存储。因此,如果我们想顺序存储普通二叉树,需要提前将普通二叉树转化为完全二叉树。
怎么转换呢?
普通二叉树转完全二叉树的方法很简单,只需给二叉树额外添加一些节点,将其"拼凑"成完全二叉树即可。
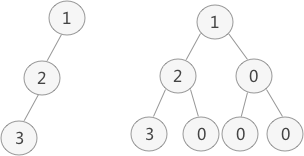
为什么是层序遍历呢?
从数组无法得知树的高度,所以如果通过深度优先遍历的方式来生成顺序存储的树,我们无法通过这个数组还原二叉树.
思考
通过深度优先遍历生成的数组能否还原成树的结构呢?
首先答案是肯定的.可以通过中根序遍历结果+先根序/后根序遍历结果还原二叉树,至于具体的方式,可以自己思索一下.
堆
堆就是用数组实现的二叉树,所以它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置。
堆分为两种:最大堆和最小堆,两者的差别在于节点的排序方式。
在最大堆中,父节点的值比每一个子节点的值都要大。在最小堆中,父节点的值比每一个子节点的值都要小。这就是所谓的“堆属性”,并且这个属性对堆中的每一个节点都成立。
用一种关系式的方式说明,
在含有 n 个元素的序列中,如果序列中的元素满足下面其中一种关系时,此序列可以称之为堆
- ki ≤ k2i 且 ki ≤ k2i+1(在 n 个记录的范围内,第 i 个关键字的值小于第 2i 个关键字,同时也小于第 2i+1 个关键字)
- ki ≥ k2i 且 ki ≥ k2i+1(在 n 个记录的范围内,第 i 个关键字的值大于第 2i 个关键字,同时也大于第 2i+1 个关键字)
使用完全二叉树来解释,因为在完全二叉树中第 i 个结点的左孩子恰好是第 2i 个结点,右孩子恰好是 2i+1 个结点。如果该序列可以被称为堆,则使用该序列构建的完全二叉树中,每个根结点的值都必须不小于(或者不大于)左右孩子结点的值。
我们可以以一个堆排序来深入学习堆,了解堆这个结构具体用处
堆排序思路:
通过将无序表转化为堆,可以直接找到表中最大值或者最小值,然后将其提取出来,令剩余的记录再重建一个堆,取出次大值或者次小值,如此反复执行就可以得到一个有序序列,此过程为堆排序。
无序表{49,38,65,97,76,13,27,49}来讲,其对应的堆用完全二叉树来表示为

堆排序过程的代码实现需要解决两个问题:
- 如何将得到的无序序列转化为一个堆?
- 在输出堆顶元素之后(完全二叉树的树根结点),如何调整剩余元素构建一个新的堆?
首先解决第 2 个问题,
去除堆顶元素时,即删除二叉树的树根结点,使用二叉树中最后一个结点 97 代替根节点,也就是放到堆顶.

此时由于结点 97 比左右孩子结点的值都大,破坏了堆的结构,所以需要进行调整:首先以 堆顶元素 97 同左右子树比较,同值最小的结点交换位置,即 27 和 97 交换位置
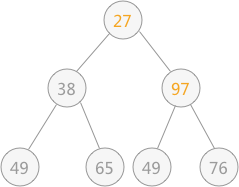
由于替代之后破坏了根结点右子树的堆结构,所以需要进行和上述一样的调整,即令 97 同 49 进行交换位置
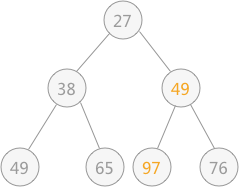
通过上述的调整,之前被破坏的堆结构又重新建立。从根结点到叶子结点的整个调整的过程,被称为“筛选”
解决第 1 个问题
使用的也是筛选的方式.
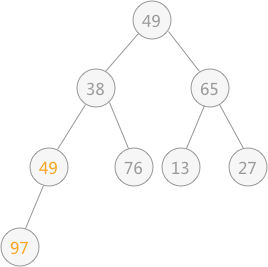
首先,无序表{49,38,65,97,76,13,27,49}初步建立的完全二叉树,如下图

筛选上面这个无序二叉树时,是从底层结点开始,一直筛选到根结点。对于具有 n 个结点的完全二叉树,筛选工作开始的结点为第 ⌊n/2⌋个结点(此结点后序都是叶子结点,无需筛选)。
http://c.biancheng.net/uploads/allimg/190427/1051104459-5.png
例子中共8个节点,根据我们方法,也就是从第四个节点开始, 第四个节点的值与他的子节点进行比较,将第四个节点的值与值最小的节点的值交换。
然后,筛选第三个子节点。
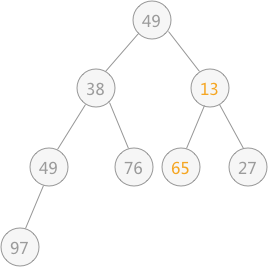
最后得到结果,

解决了这两个问题过后,堆排序的问题也就解决了,流程就是首先根据无序集合通过筛选,生成一个最大或者最小堆,每次取出堆顶元素,取出堆顶元素后,重新筛选,构建新的堆结构。
堆排序在最坏的情况下,其时间复杂度仍为 O(nlogn)。这是相对于快速排序的优点所在。同时堆排序相对于树形选择排序,其只需要一个用于记录交换(rc)的辅助存储空间,比树形选择排序的运行空间更小。
参考
http://c.biancheng.net/view/3448.html















 1916
1916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









