






给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab" 输出: true 解释: 可由子串 "ab" 重复两次构成。
这个题看上去是真的不难。作为一个算法小白,我只会用很朴素的想法去做。
第一个反应你可以想到暴力求解,这没问题。但是我自己暴力求解都没有过leetcode,因为超出了时间限制。
朴素暴力求解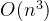
我的暴力求解很朴素。那就是全局匹配。比如 为a 我就找后面是否都是a, 第二轮,为ab,我就后面是否全是ab,如果满足了条件了,那就 退出。不满 直接break,让ab再继续走 变成aba。代码如下。
def repeatedSubstringPattern(s: str) -> bool:
res = list(s)
for i in range(len(res)):
match_str = ''.join(res[0:i+1]) # a
for j in range(i+1, len(res), i+1):
next_str = "".join(res[j: j+i+1]) # b
if match_str != next_str:
break
if j + i >= len(res) -1 : # 如果已经匹配到最后还能相等,那就说明是重复的
return True
return False
暴力求解剪枝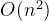
优化点1,我们之前的暴力是遍历所有长度的字串,但是如果你的字串长度>整体串长度的一半的话,其实就没必要往下走了。因此第一层遍历不需要那么多
优化点2,当我们获取要match的字串,我们是和后面字串长度相等的一一比较。但其实没必要,因为如果真匹配,mathch_str 和后面的str是一样的,将match_str复制成s的长度,比较就可以了
优化点3,整除的剪枝。如果你的字串长度是 i, s长度是n,如果n不能整除i,那么其实也不匹配了。比如长度为7 你的字串长度为2 或为3 是不能重复的字串长度是2,是3的。
优化的代码如下。
def repeatedSubstringPattern(s: str) -> bool:
n = len(s)
if n<=1:
return False
substr = ''
for i in range(1, n // 2 + 1):
if (n % i == 0):
substr = s[:i]
if substr * (n//i) == s:
return True
return False字符匹配的思路(O(m+n))
判断字符串s是否由重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是由重复子串组成。 这个是个比较不好想到的想法。判断 s + s 拼接的字符串里是否出现一个s的的时候,要刨除 s + s 的首字符和尾字符,这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。
这里就回到一个字符匹配的问题。你的文本串是s+s并掐头去尾,模式串是s,看能否匹配到。如果用kmp算法,那就是(O(m+n))
class Solution:
def repeatedSubstringPattern(self, s: str) -> bool:
n = len(s)
if n <= 1:
return False
ss = s[1:] + s[:-1]
print(ss.find(s))
return ss.find(s) != -1我觉得这个思路更加表现一个更加正常的写法。















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









