







想要精通算法和SQL的成长之路 - 超过经理收入的员工(SQL)
前言
一. 超过经理收入的员工
原题链接
我们有这么一张Employee表:
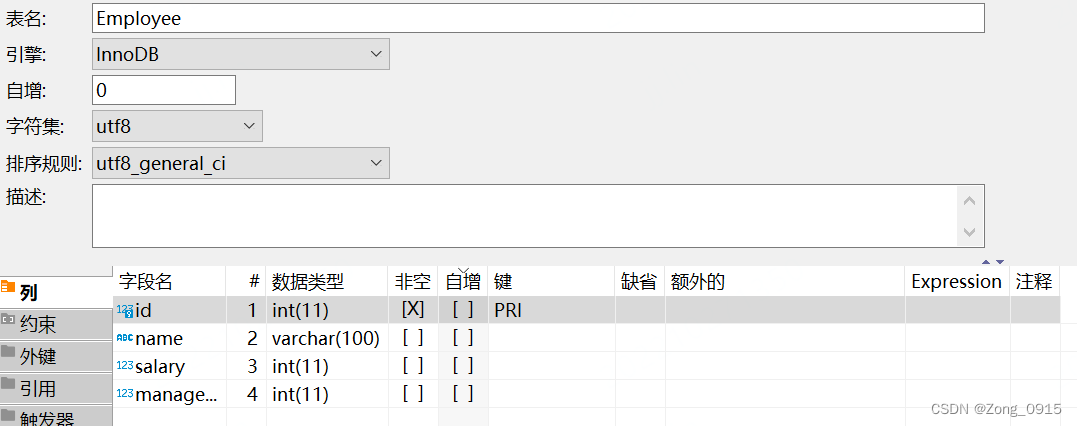
对应SQL如下:
CREATE TABLE `Employee` (
`id` int(11) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`salary` int(11) DEFAULT NULL,
`managerId` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
该表的每一行都表示雇员的ID、姓名、工资和经理的ID。编写一个SQL查询来查找收入比经理高的员工。
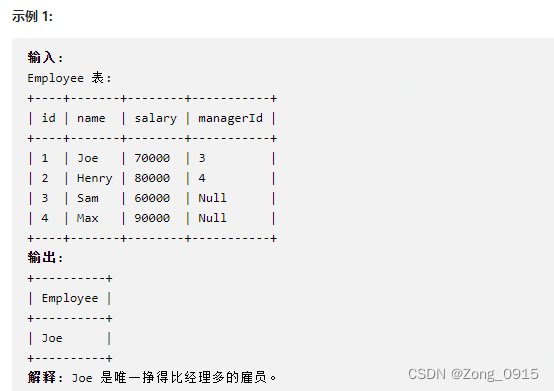
我们准备下表数据:
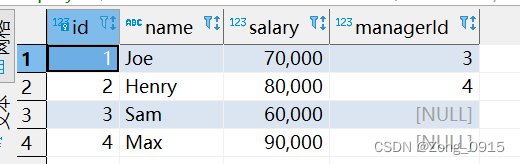
这个问题这里给出三种写法:
- 使用自连接。
- 使用子查询。
- 使用
join语句。
1.1 自连接
因为Employee表中的 id 和 managerId 存在着父子关系,因此我们需要用到两张Employee表。
SELECT
e.name as Employee
from
Employee e , Employee e2
where
e.managerId = e2.id and e.salary > e2.salary
1.2 子查询
子查询这种写法,其实就是相当于自连接的一种变相写法了。只不过把from中的一张表单独提取出来罢了
SELECT
e.name as Employee
from
Employee e
where e.salary > (SELECT e2.salary from Employee e2 where e2.id = e.managerId)
1.3 join 语句
SELECT
e.name as Employee
from
Employee e join Employee e2
on
(e.managerId = e2.id and e.salary > e2.salary)
这里说明一下,为什么上面的SQL写的都是 e.managerId = e2.id 。
宏观角度来看,我们使用了两张一模一样的表,分别命名为e和e2。那么宏观角度来看,下面的两个SQL语句确实语义是一样的:
e.managerId = e2.ide.id = e2.managerId
不过,我们的题目里面的名称,也就是select语句的查询字段都是来自于e这张表。那么结合这一点,上面两个表达式的语义就完全不一样了:
e.managerId = e2.id:代表筛选了e这张表中,有经理的员工信息。e.id = e2.managerId:取的是e这张表中的经理数据。因为e2表中的数据有managerId的就是3和4。对应着e表中的经理数据。
因此记住一点:取的数据来自于哪张表,条件语句就以哪张表为基准来判断。
















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











