







原文链接:https://www.hqxiaozou.top/post/tnep6uzrc3y
Elasticsearch7.x版本新特性
-
集群连接变化:TransportClient被废弃。
以至于,es7的java代码,只能使用restclient。对于java编程,建议采用 High-level-rest-client 的方式操作ES集群。High-level REST client 已删除接受Header参数的API方法,Cluster Health API默认为集群级别。
-
ES数据存储结构变化:简化了Type 默认使用_doc。
es6时,官方就提到了es7会逐渐删除索引type,并且es6时已经规定每一个index只能有一个type。在es7中使用默认的_doc作为type,官方说在8.x版本会彻底移除type。api请求方式也发送变化,如获得某索引的某ID的文档:GET index/_doc/id其中index和id为具体的值。
-
ES程序包默认打包jdk:以至于7.x版本的程序包大小突然增大了200MB+, 对比6.x发现,包大了200MB+, 正是JDK的大小。
-
默认配置变化:默认节点名称为主机名,默认分片数改为1,不再是5。
-
Lucene升级为lucene 8 查询相关性速度优化:Weak-AND算法。es可以看过是分布式lucene,lucene的性能直接决定es的性能。lucene8在top k及其他查询上有很大的性能提升。
weak-and算法 核心原理:取TOP N结果集,估算命中记录数。
TOP N的时候会跳过得分低于10000的文档来达到更快的性能。
-
间隔查询(Intervals queries): intervals query 允许用户精确控制查询词在文档中出现的先后关系,实现了对terms顺序、terms之间的距离以及它们之间的包含关系的灵活控制。
-
引入新的集群协调子系统,移除 minimum_master_nodes 参数,让 Elasticsearch 自己选择可以形成仲裁的节点。
-
7.0将不会再有OOM的情况,JVM引入了新的circuit breaker(熔断)机制,当查询或聚合的数据量超出单机处理的最大内存限制时会被截断。设置indices.breaker.fielddata.limit的默认值已从JVM堆大小的60%降低到40%。
-
分片搜索空闲时跳过refresh以前版本的数据插入,每一秒都会有refresh动作,这使得es能成为一个近实时的搜索引擎。但是
当没有查询需求的时候,该动作会使得es的资源得到较大的浪费。
Elasticsearch基本使用
索引操作
# 创建索引
PUT /zou-company-index
PUT /zou-employee-index

# 判断索引是否存在
HEAD /zou-company-index

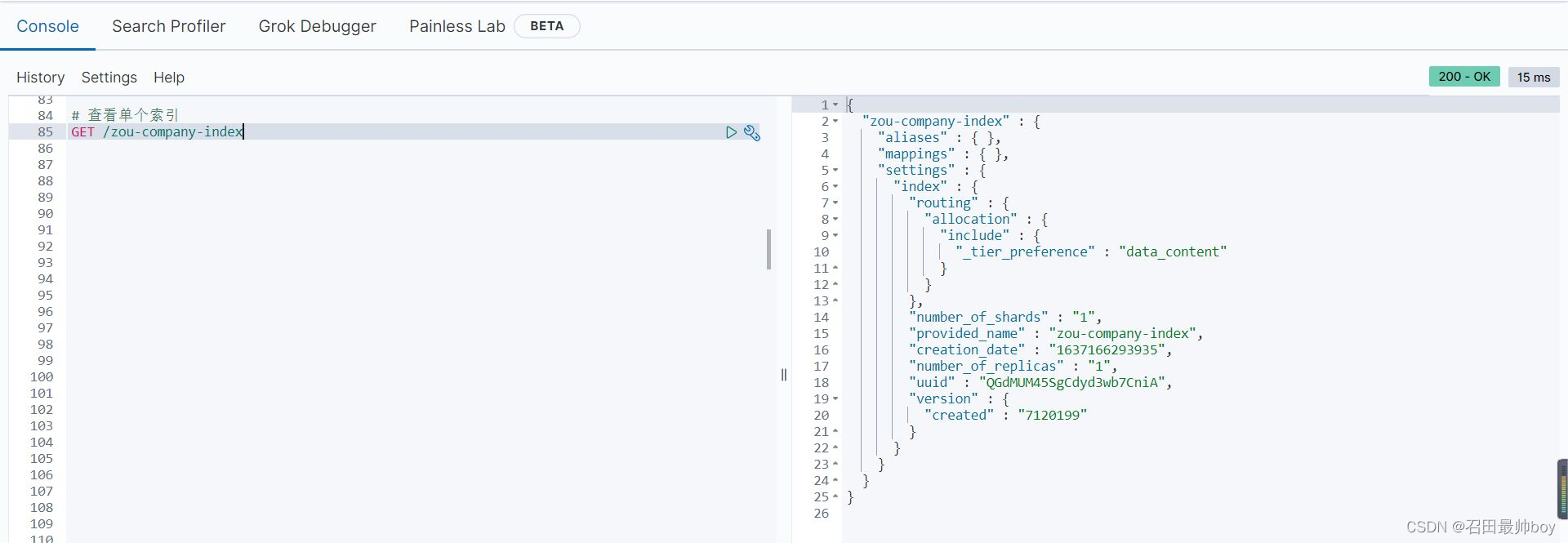
# 查看单个索引
GET /zou-company-index
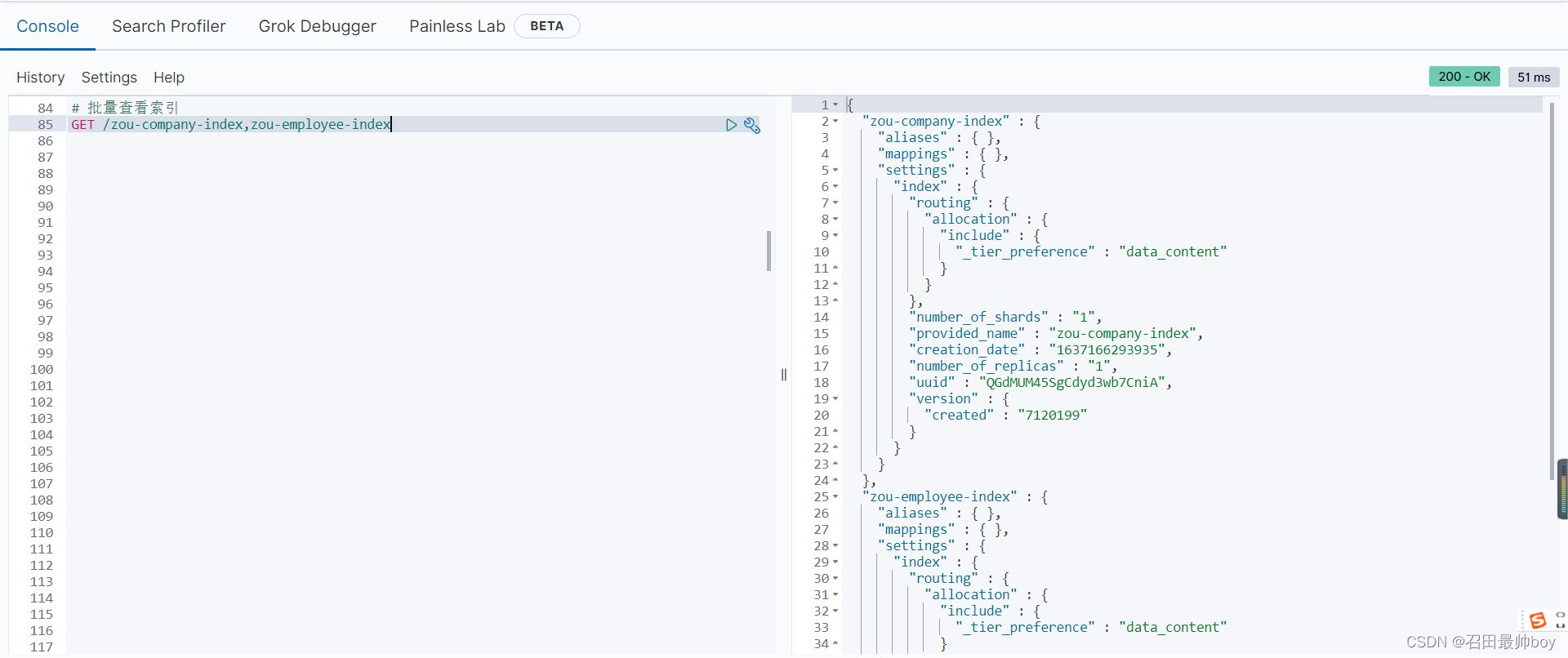
# 批量查看索引
GET /zou-company-index,zou-employee-index
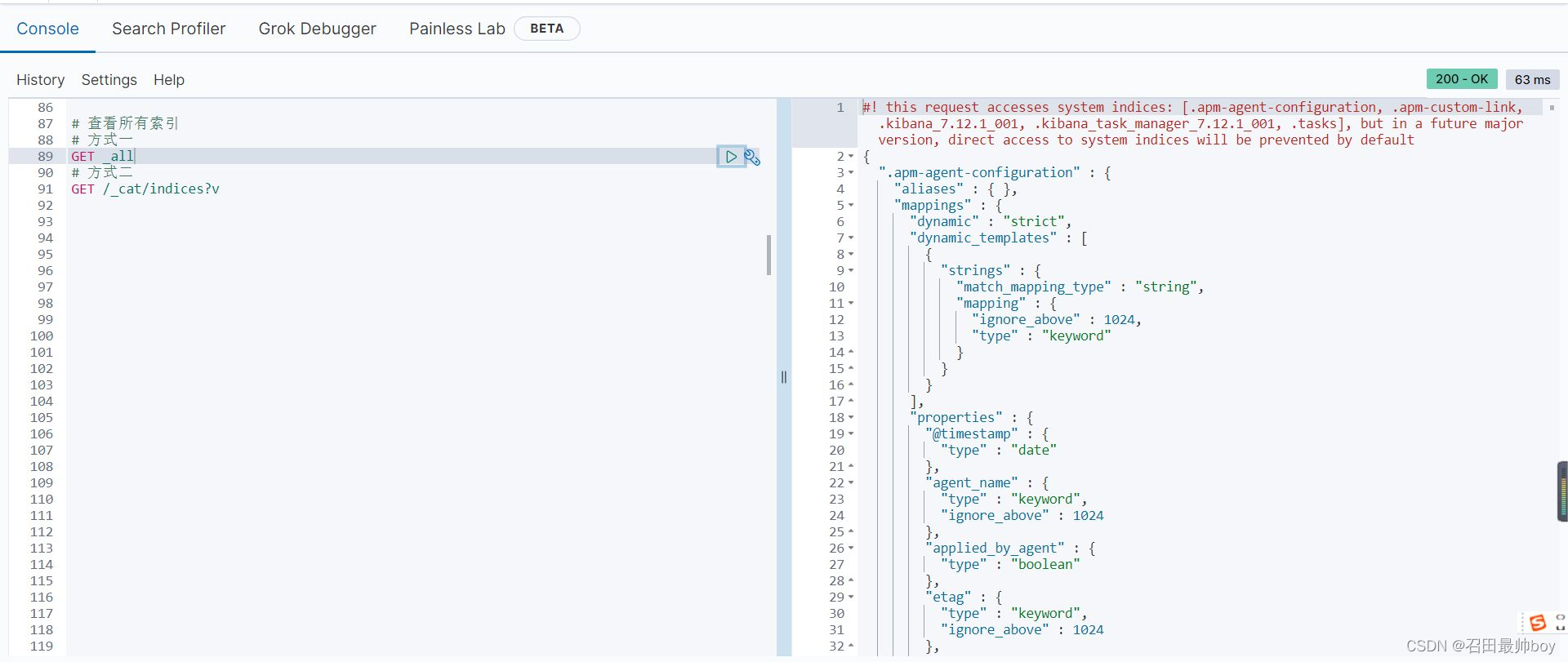
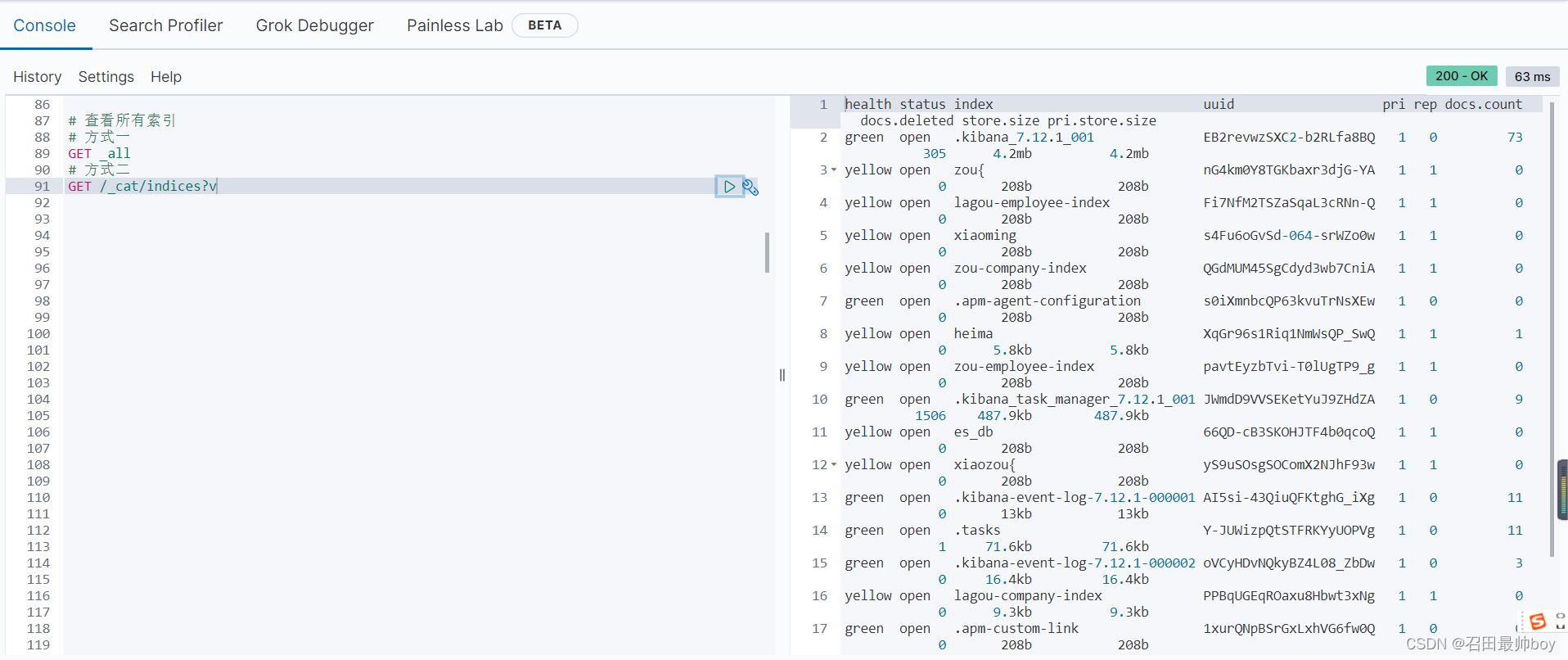
# 查看所有索引
# 方式一
GET _all
# 方式二
GET /_cat/indices?v
# 打开索引
POST /zou-company-index/_open

# 关闭索引
POST /zou-company-index/_close

# 删除索引库
DELETE /zou-company-index,zou-employee-index

映射操作
# 创建映射
PUT /zou-company-index/
PUT /zou-company-index/_mapping/
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"job": {
"type": "text",
"analyzer": "ik_max_word"
},
"logo": {
"type": "keyword",
"index": "false"
},
"payment": {
"type": "float"
}
}
}
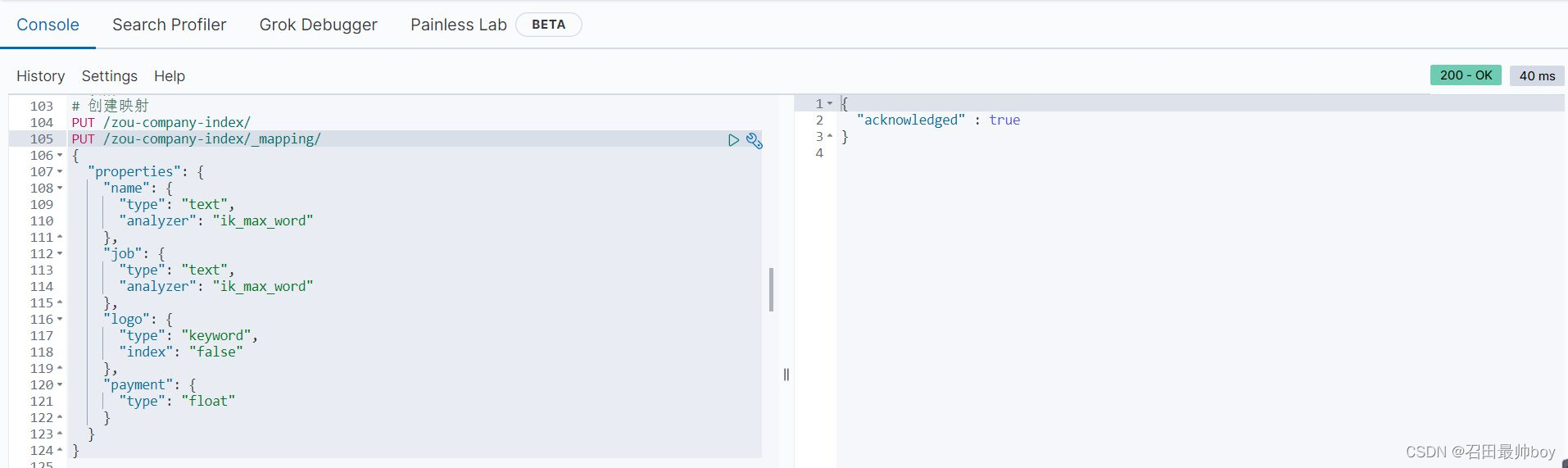
# 查看单个索引映射关系
GET /zou-company-index/_mapping
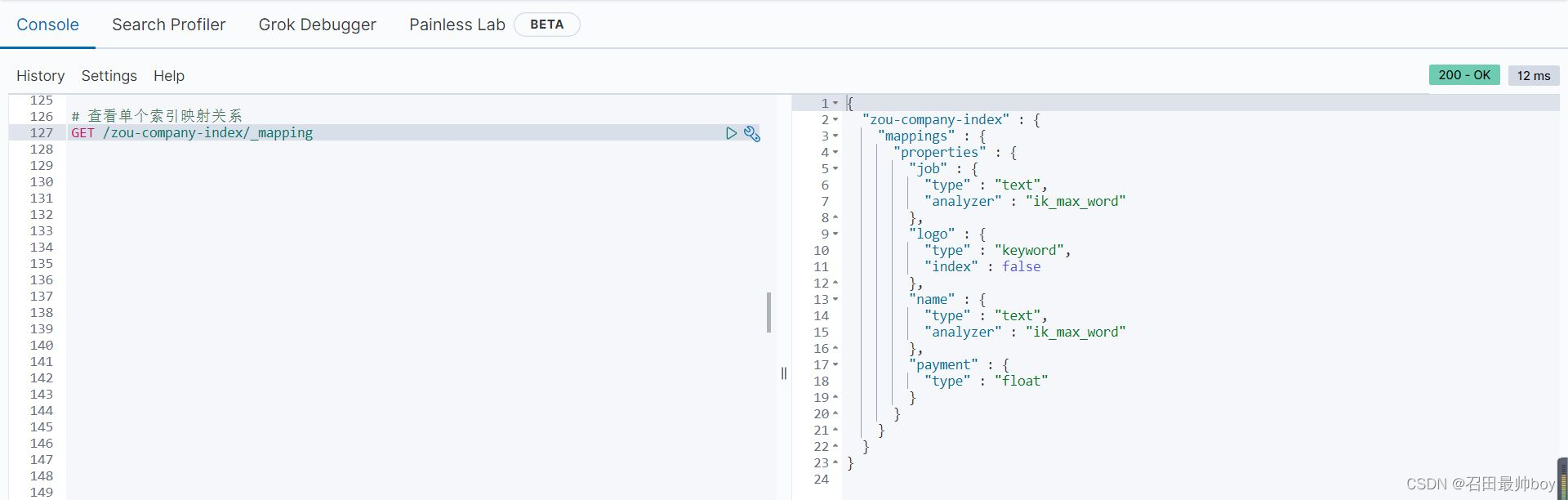
# 查看所有索引映射关系
# 方式一
GET _mapping
# 方式二
GET _all/_mapping
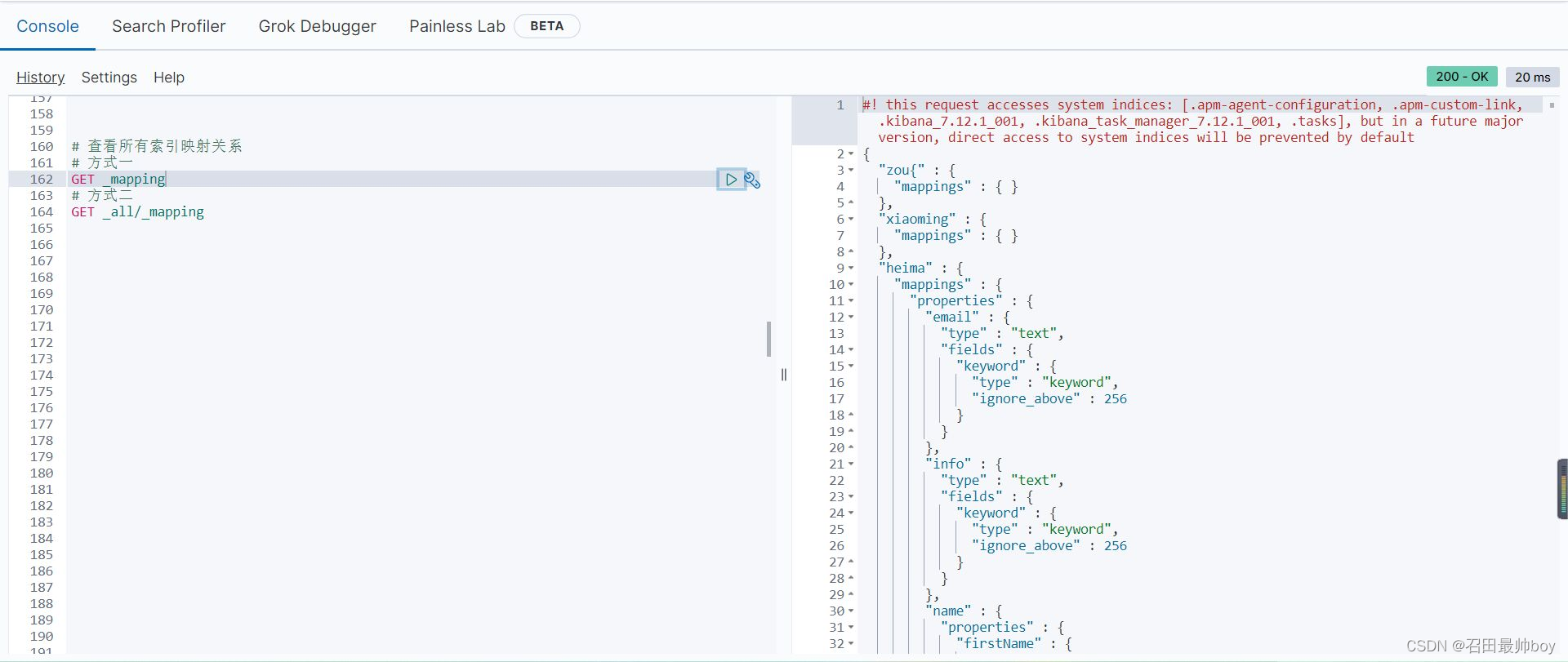
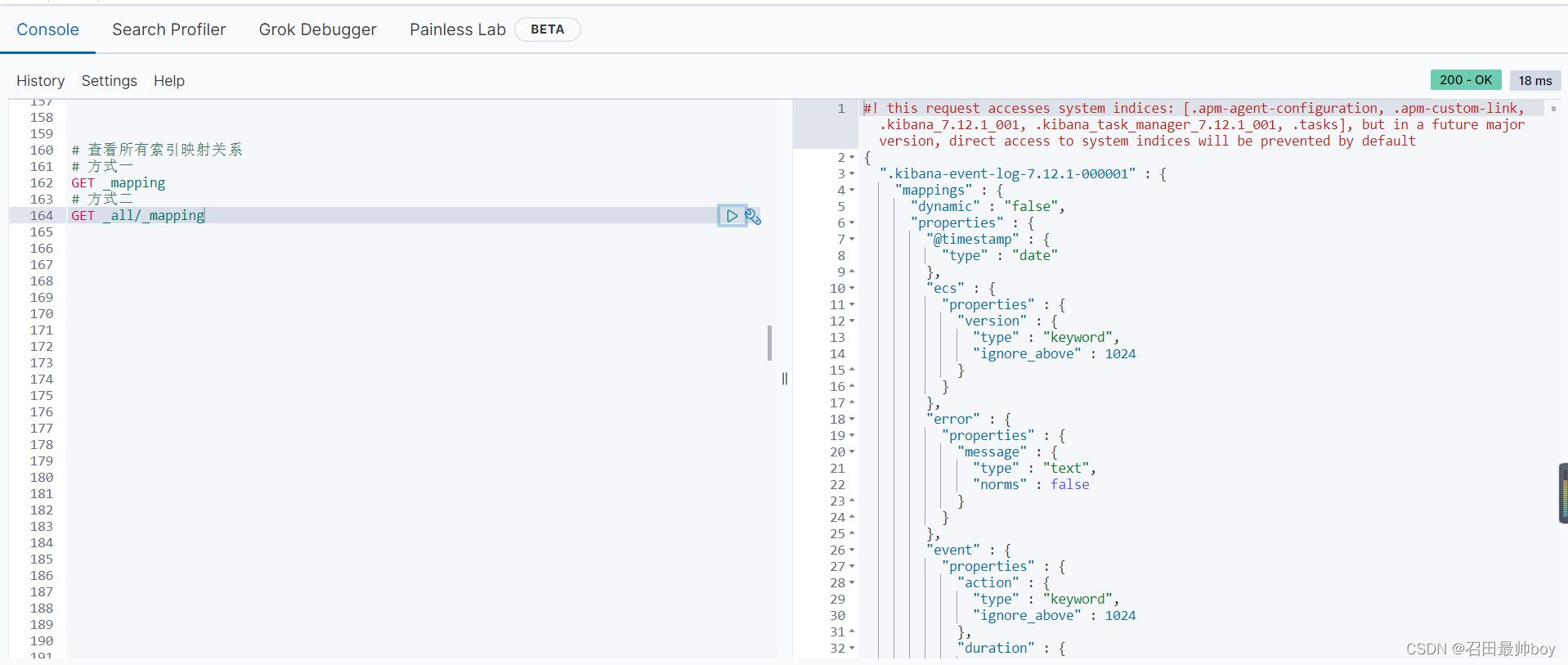
# 一次性创建索引和映射
PUT /zou-employee-index
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
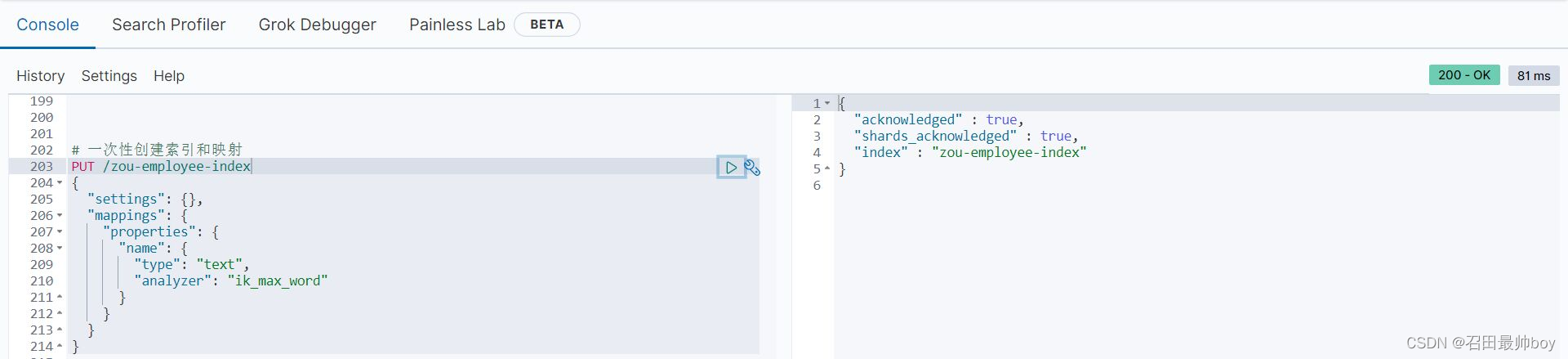
文档操作
# 新增文档
POST /zou-company-index/_doc/1
{
"name": "百度",
"job": "小度用户运营经理",
"payment": "30000",
"logo": "https://www.hqxiaozou.top/img/20211117.jpg"
}
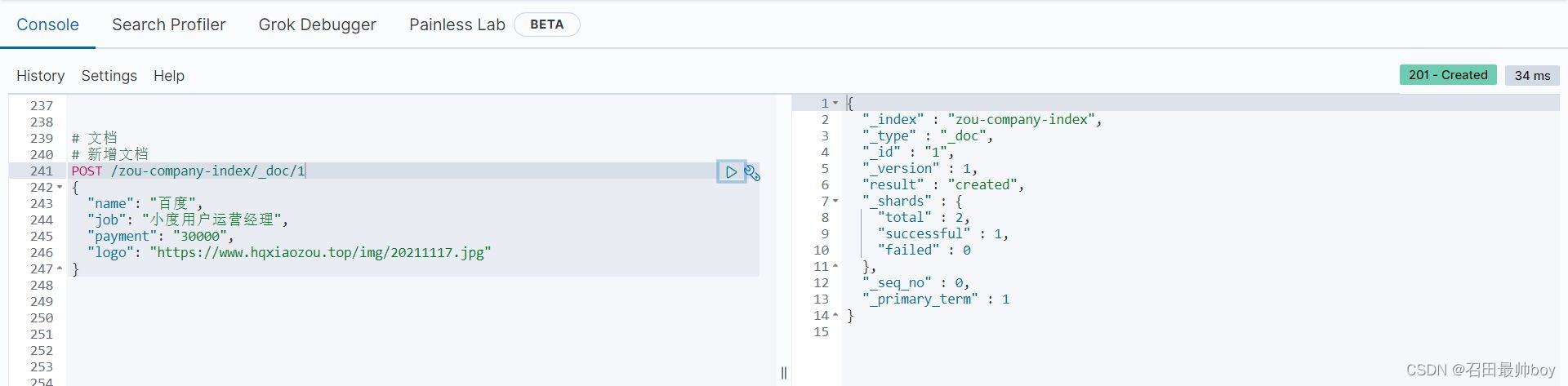
# 新增文档(自动生成id)
POST /zou-company-index/_doc
{
"name": "百度",
"job": "小度用户运营经理",
"payment": "30000",
"logo": "https://www.hqxiaozou.top/img/20211117.jpg"
}
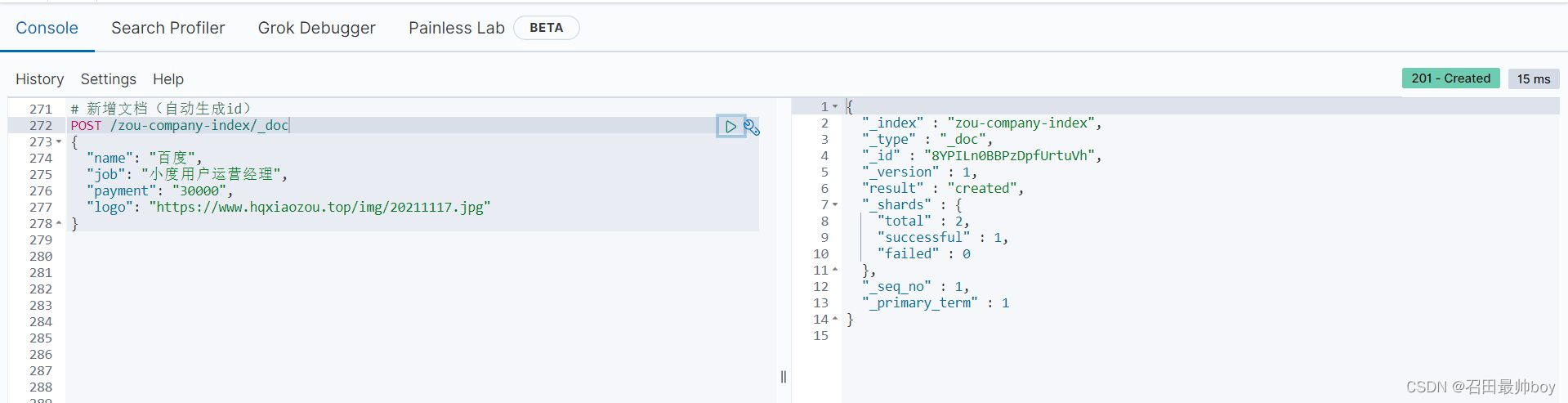
# 查看单个文档
GET /zou-company-index/_doc/1

# 查看所有文档
POST /zou-company-index/_search
{
"query": {
"match_all": {
}
}
}
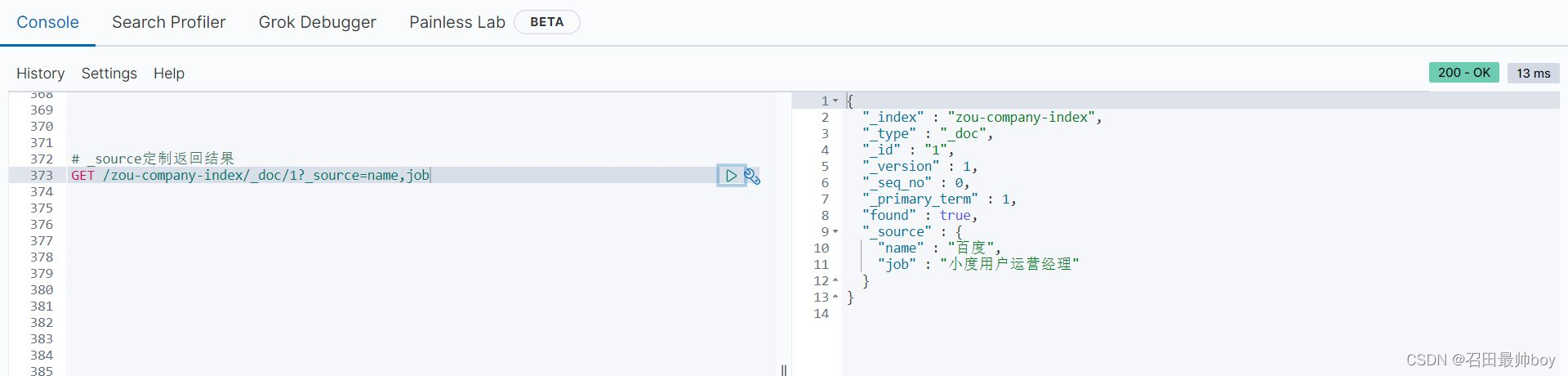
# _source定制返回结果
GET /zou-company-index/_doc/1?_source=name,job
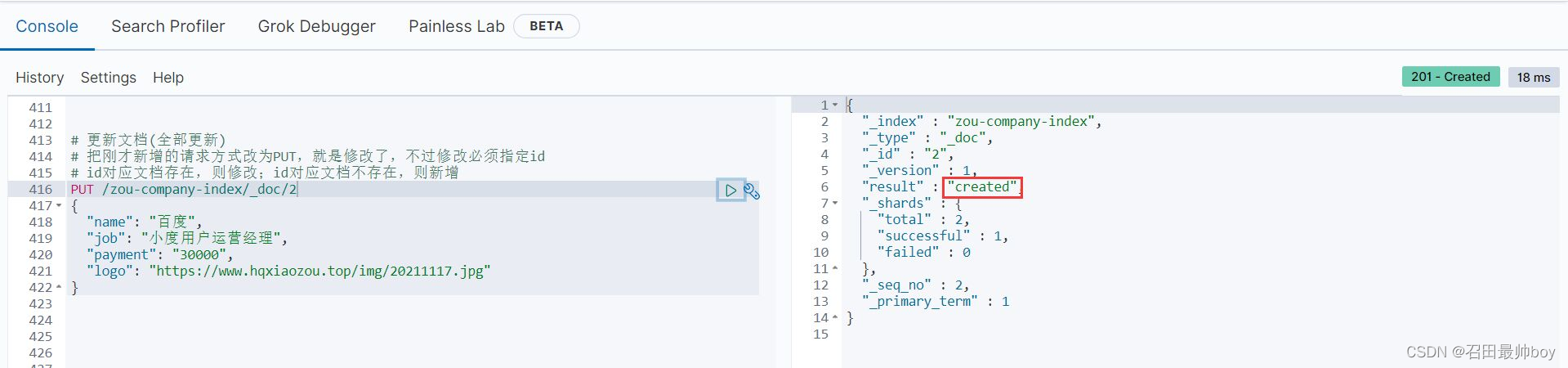
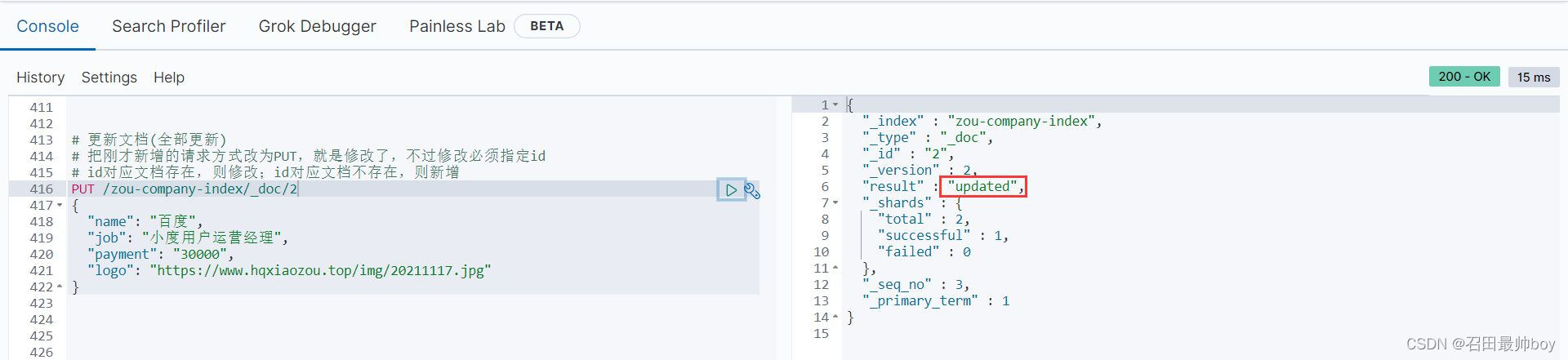
# 更新文档(全部更新)
# 把刚才新增的请求方式改为PUT,就是修改了,不过修改必须指定id
# id对应文档存在,则修改;id对应文档不存在,则新增
PUT /zou-company-index/_doc/2
{
"name": "百度",
"job": "小度用户运营经理",
"payment": "30000",
"logo": "https://www.hqxiaozou.top/img/20211117.jpg"
}
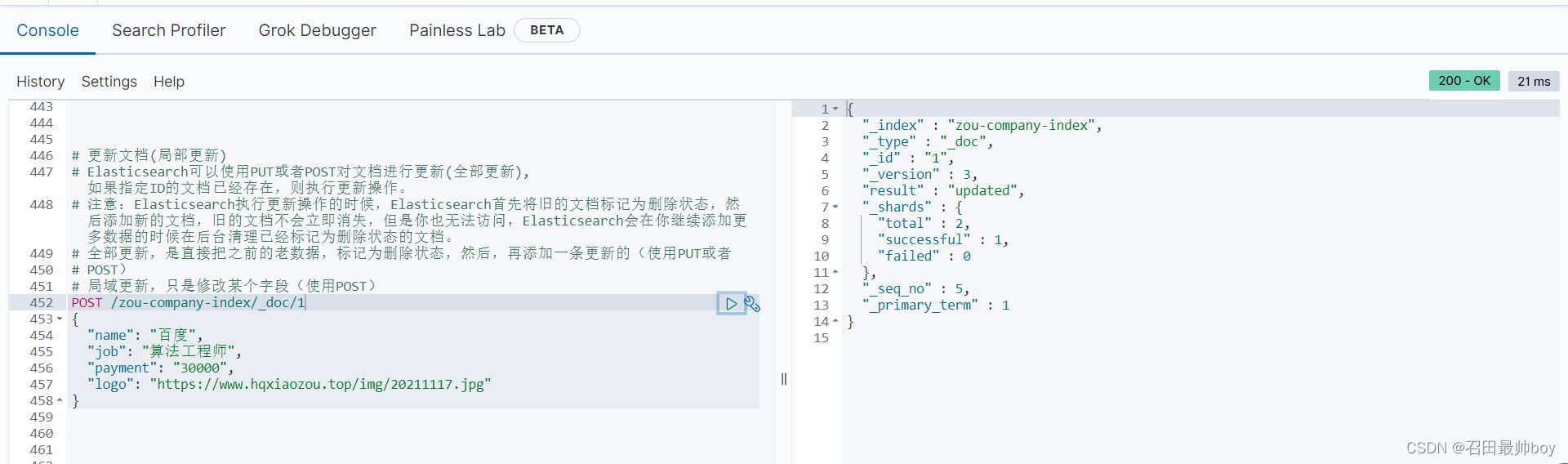
# 更新文档(局部更新)
# Elasticsearch可以使用PUT或者POST对文档进行更新(全部更新), 如果指定ID的文档已经存在,则执行更新操作。
# 注意:Elasticsearch执行更新操作的时候,Elasticsearch首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,Elasticsearch会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
# 全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的(使用PUT或者
# POST)
# 局域更新,只是修改某个字段(使用POST)
POST /zou-company-index/_doc/1
{
"name": "百度",
"job": "算法工程师",
"payment": "30000",
"logo": "https://www.hqxiaozou.top/img/20211117.jpg"
}
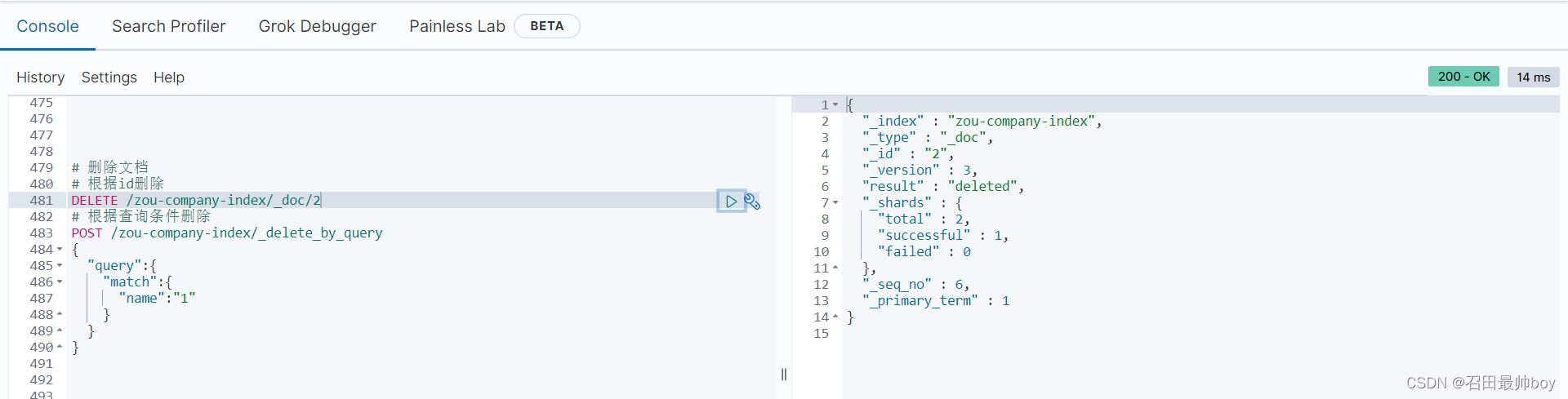
# 删除文档
# 根据id删除
DELETE /zou-company-index/_doc/2
# 根据查询条件删除
POST /zou-company-index/_delete_by_query
{
"query":{
"match":{
"name":"1"
}
}
}
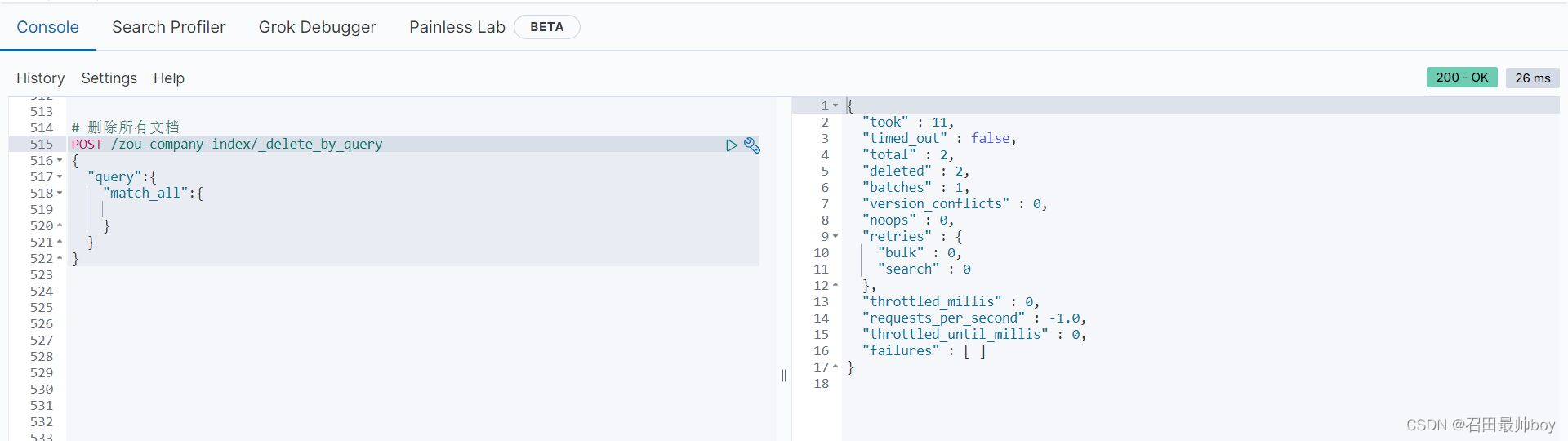
# 删除所有文档
POST /zou-company-index/_delete_by_query
{
"query":{
"match_all":{
}
}
}
Elasticsearch高级应用
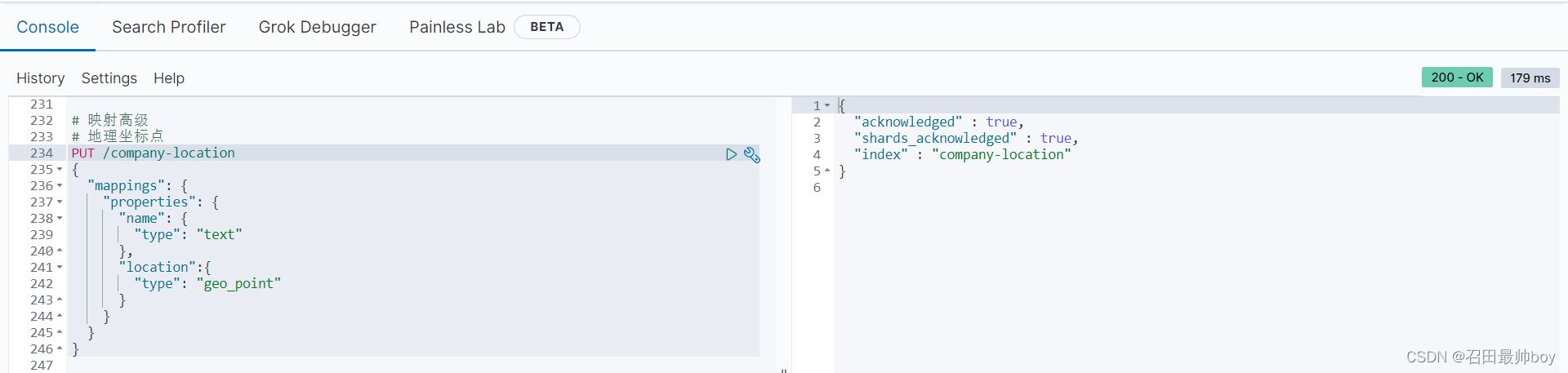
映射高级
# 地理坐标点
PUT /company-location
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"location":{
"type": "geo_point"
}
}
}
}
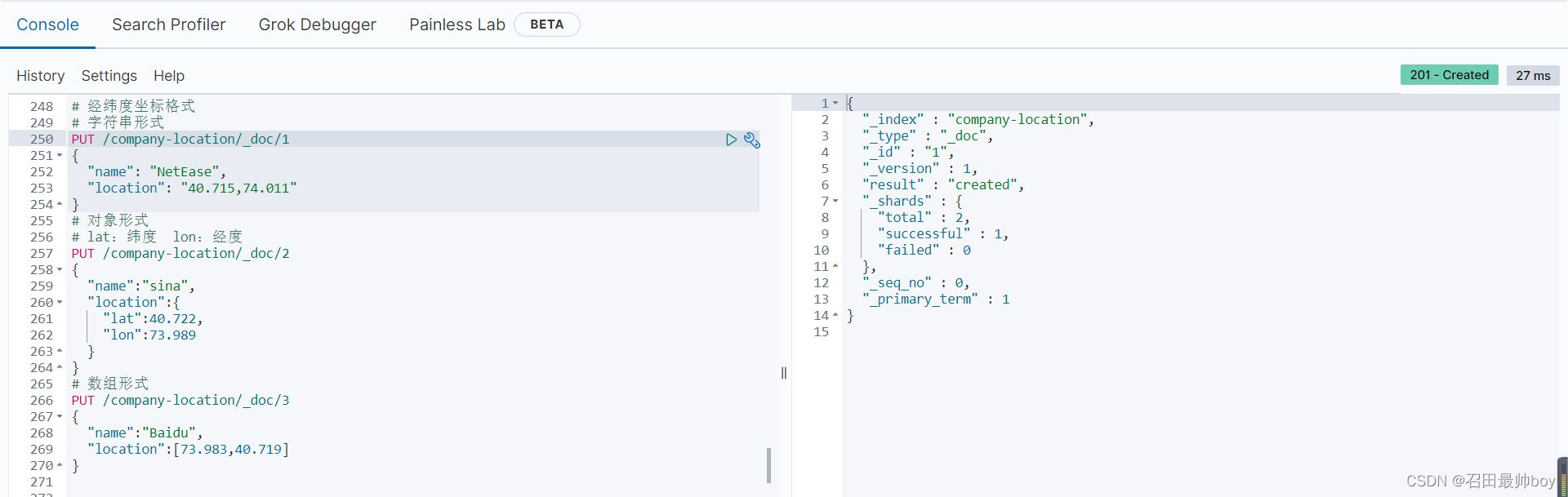
# 经纬度坐标格式
# 字符串形式
PUT /company-location/_doc/1
{
"name": "NetEase",
"location": "40.715,74.011"
}
# 对象形式
# lat:纬度 lon:经度
PUT /company-location/_doc/2
{
"name":"sina",
"location":{
"lat":40.722,
"lon":73.989
}
}
# 数组形式
PUT /company-location/_doc/3
{
"name":"Baidu",
"location":[73.983,40.719]
}
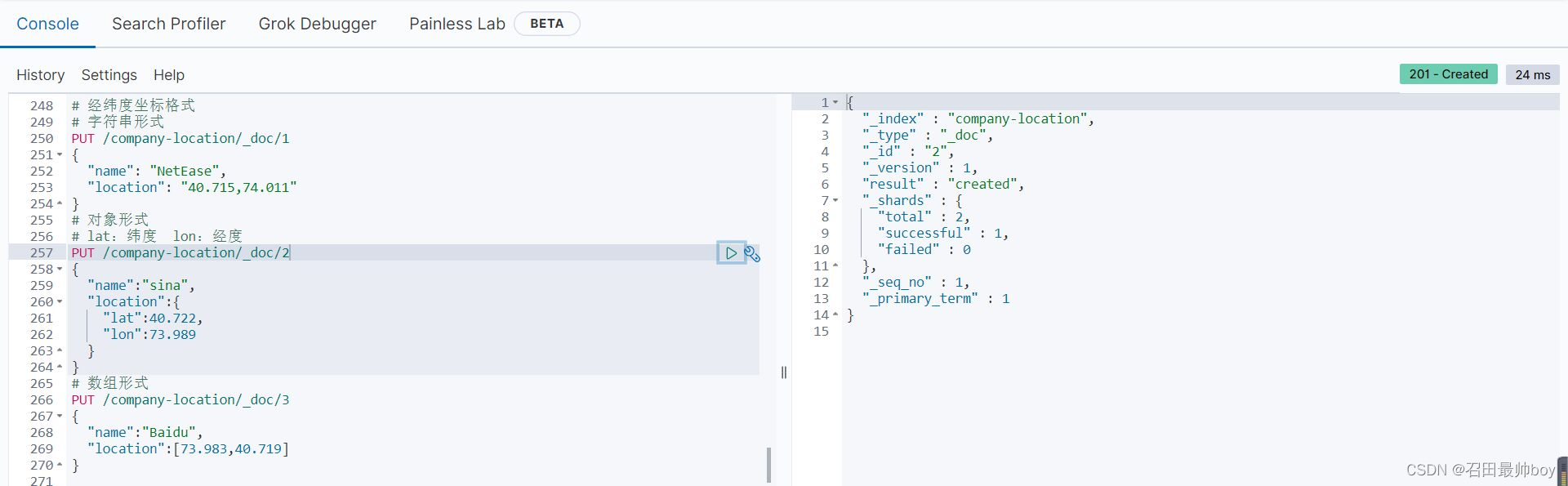
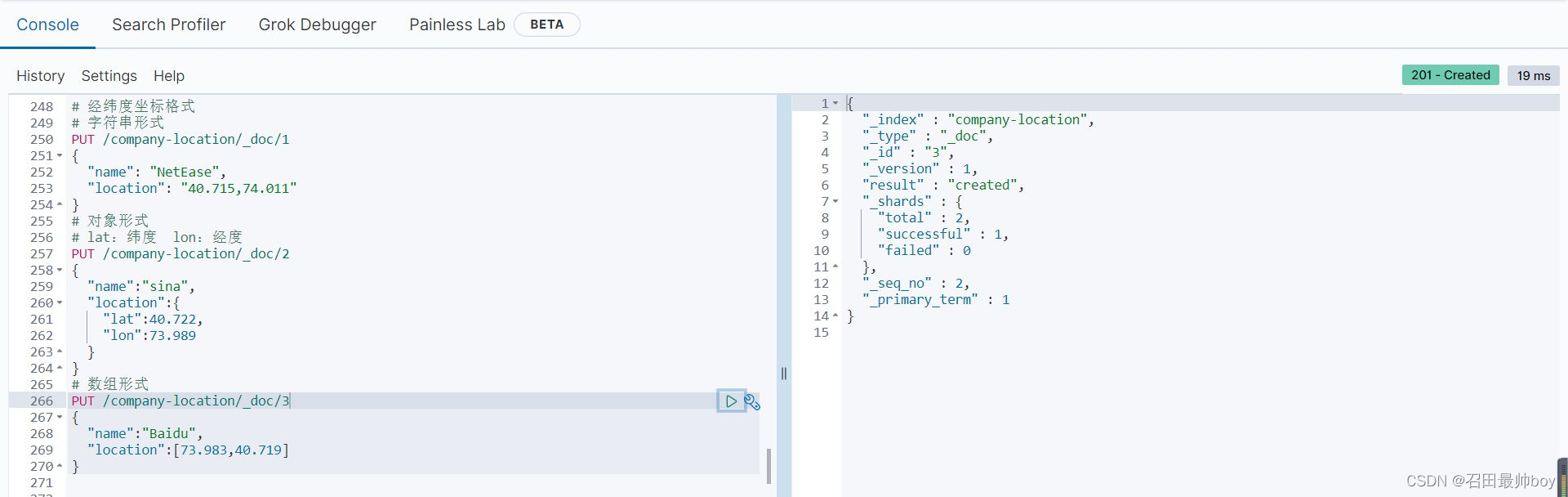
# geo_bounding_box:找出落在指定矩形框中的点
GET /company-locations/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box":{
"location":{
"top_left": {
"lat": 40.73,
"lon": 71.12
},
"bottom_right": {
"lat": 40.01,
"lon": 74.1
}
}
}
}
}
}
}
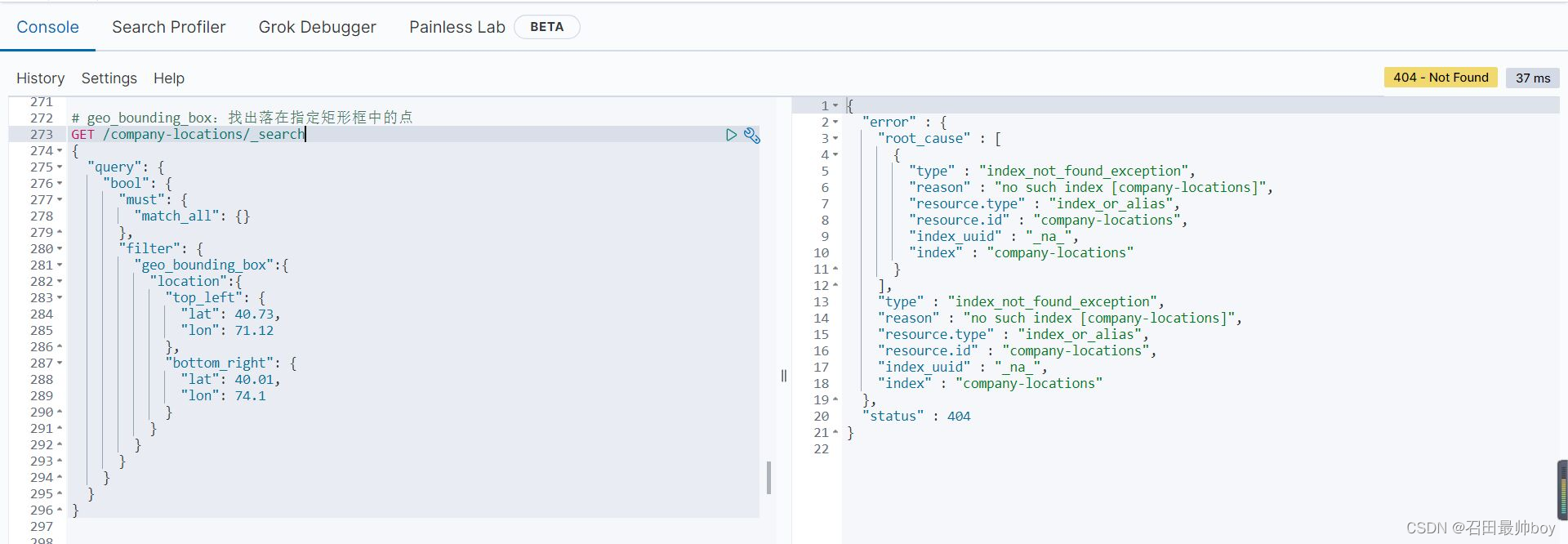
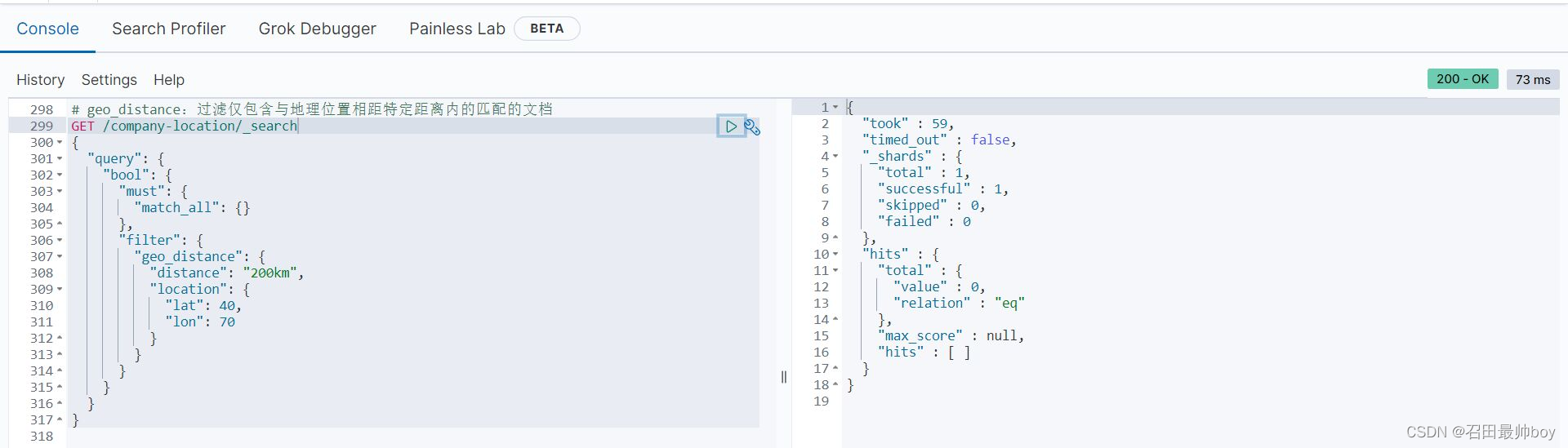
# geo_distance:过滤仅包含与地理位置相距特定距离内的匹配的文档
GET /company-location/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "200km",
"location": {
"lat": 40,
"lon": 70
}
}
}
}
}
}
动态映射
# Elastic的动态映射机制可以进行开关控制。
# 通过设置mappings的dynamic属性,dynamic有如下设置项:
# true:遇到陌生字段就执行dynamic mapping处理机制
# false:遇到陌生字段就忽略
# strict:遇到陌生字段就报错
# 设置为报错
# number_of_shards:数据分片数 | number_of_replicas :数据备份数
PUT /user
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": {
"dynamic": "strict",
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": true
}
}
}
}
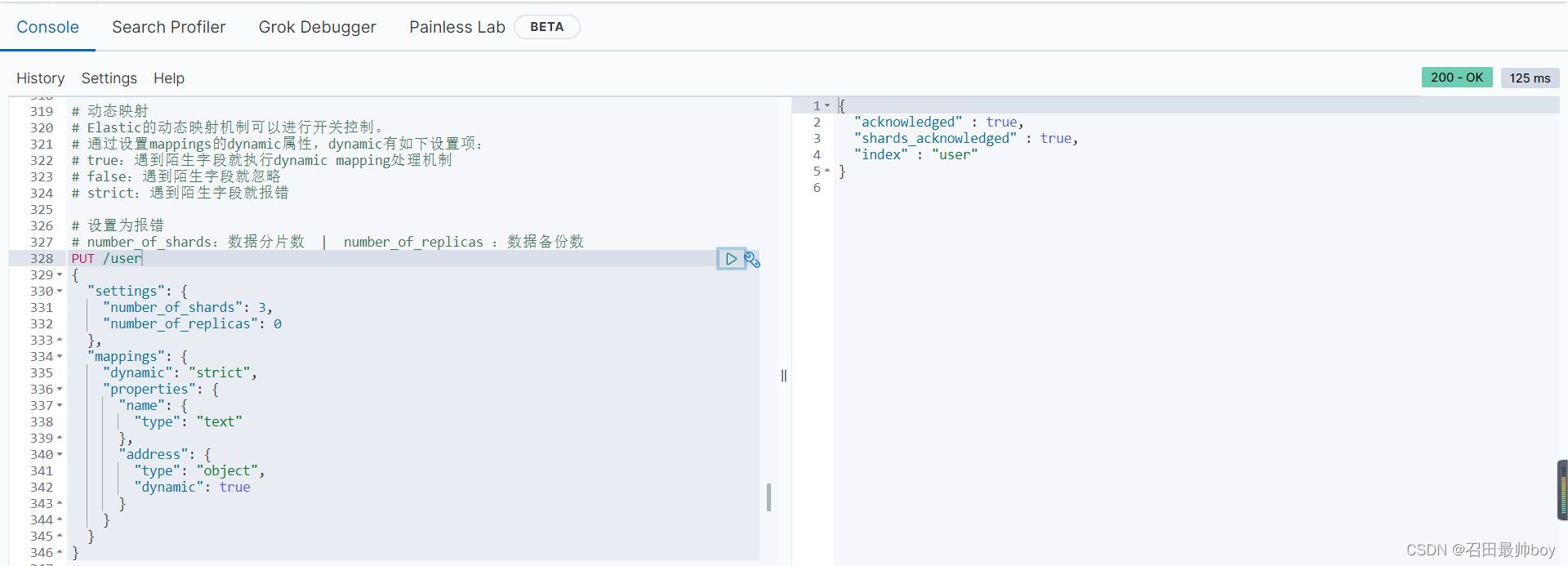
# 插入以下文档,将会报错
# user索引层设置dynamic是strict,在user层内设置age将报错
# 在address层设置dynamic是ture,将动态映射生成字段
PUT /user/_doc/1
{
"name":"lisi",
"age":"20",
"address":{
"province":"hunan",
"city":"hengyang"
}
}
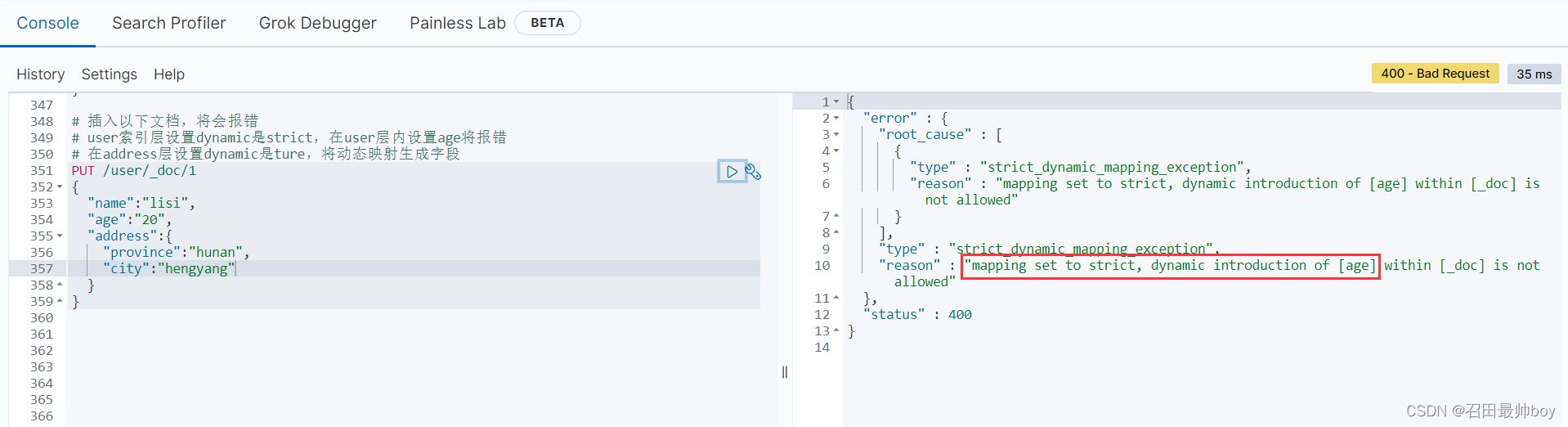
自定义动态映射
# 日期检测
# 日期检测可以通过在根对象上设置 date_detection 为 false 来关闭
PUT /my_index
{
"mappings": {
"date_detection": false
}
}

# 自定义动态映射
PUT /my_index1
{
"mappings": {
"dynamic_date_formats": "MM/dd/yyyy"
}
}
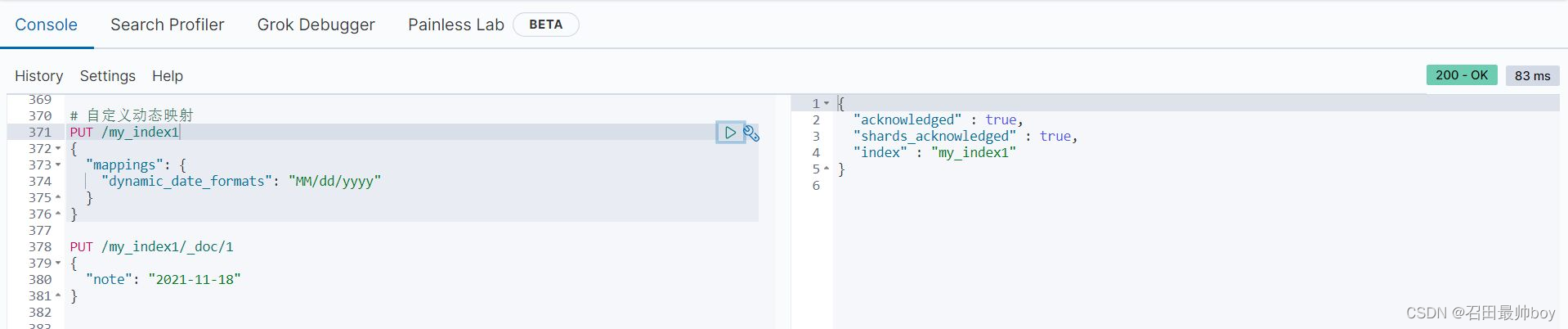
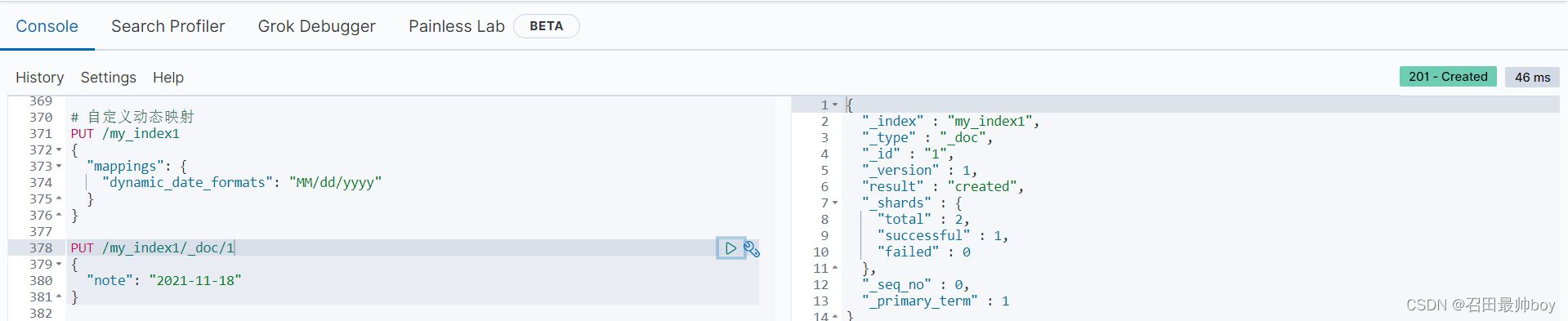
PUT /my_index1/_doc/1
{
"note": "2021-11-18"
}
PUT /my_index1/_doc/1
{
"note": "11/18/2021"
}
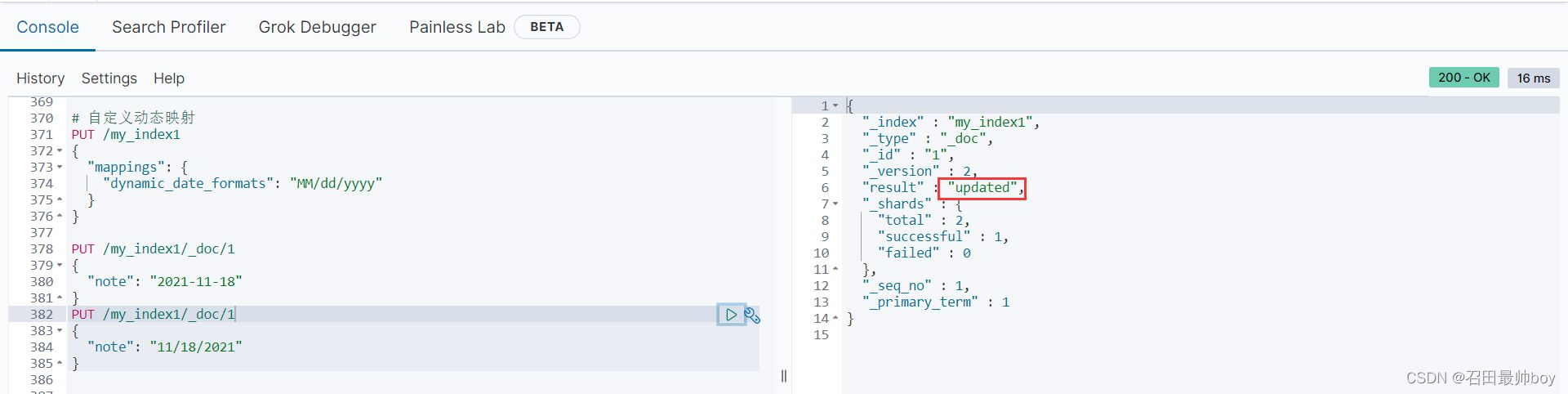
# dynamic_templates
# 使用dynamic_templates可以完全控制新生成字段的映射,甚至可以通过字段名称或数据类型来应用不同的映射。
PUT /my_index2
{
"mappings": {
"dynamic_templates": [
{
"es": {
"match": "*_es",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"analyzer": "spanish"
}
}
},
{
"en": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"analyzer": "english"
}
}
}
]
}
}
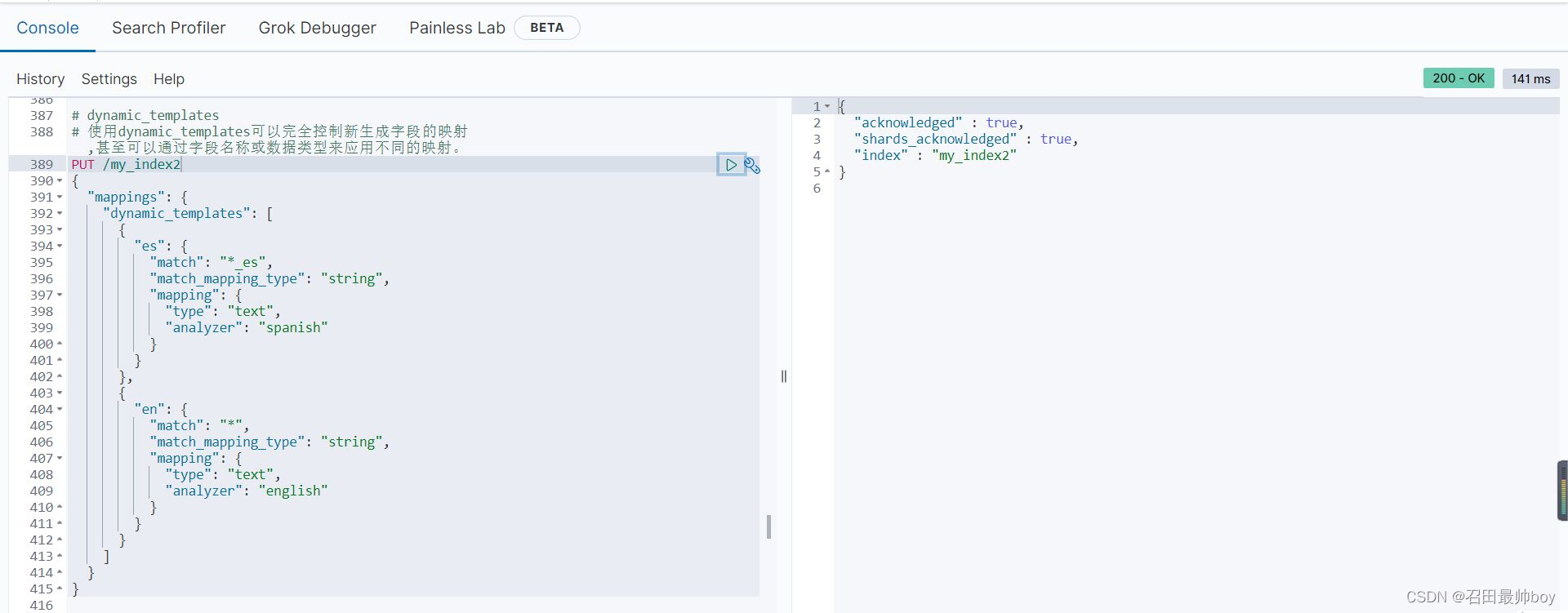
PUT /my_index2/_doc/1
{
"name_es": "testes",
"name": "es"
}
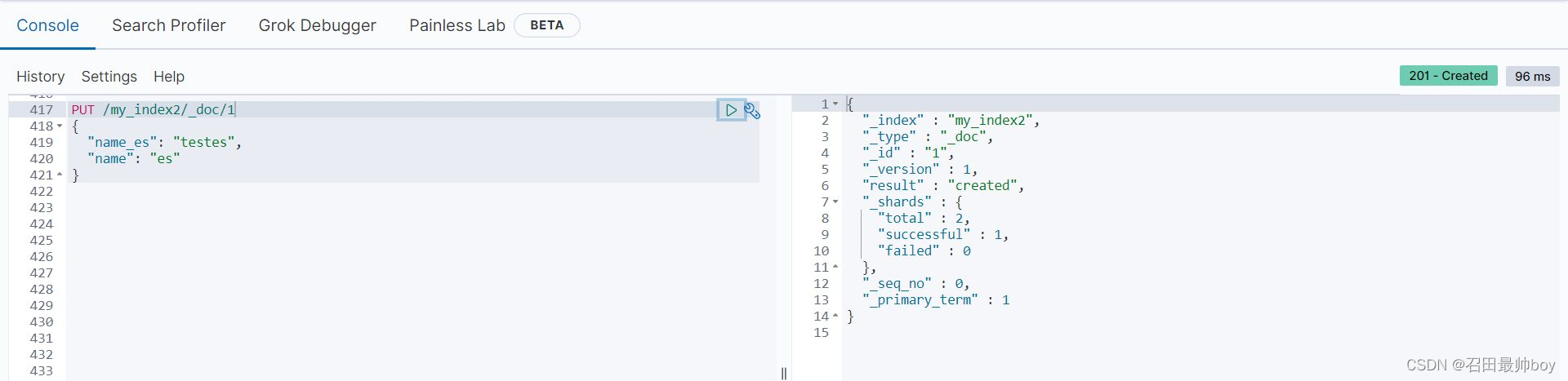
Query DSL
# 查询所有(match_all query)
POST /zou-company-index/_search
{
"query": {
"match_all": {}
}
}
# 全文搜索(full-text query)
# 1.匹配搜索(match query)
PUT /zou-property
{
"settings": {},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword"
},
"price": {
"type": "float"
}
}
}
}
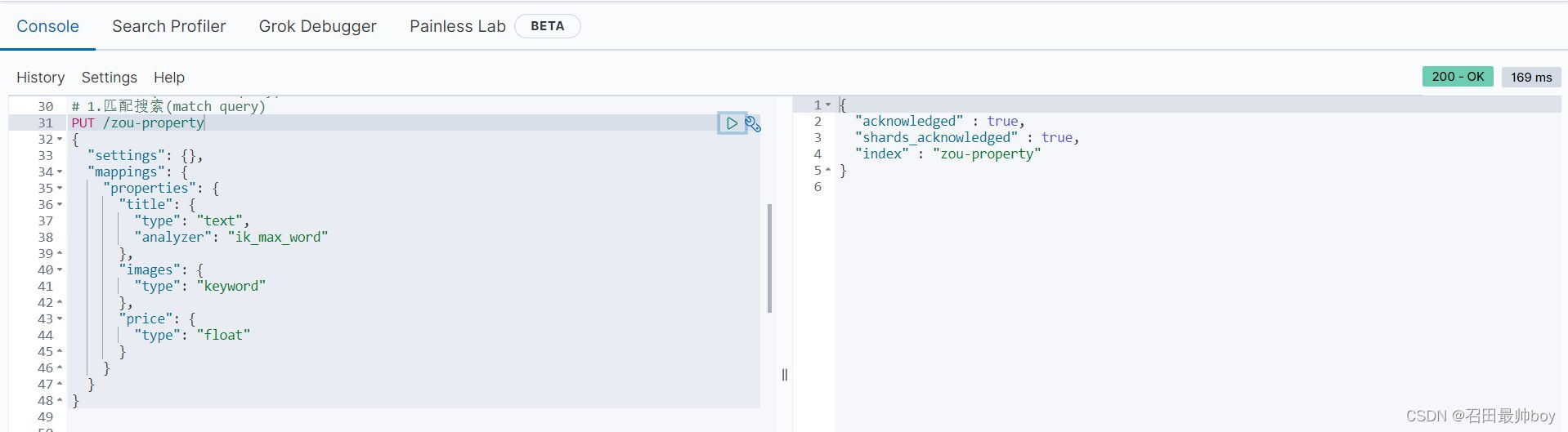
POST /zou-property/_doc/
{
"title": "小米电视4A",
"images": "https://www.hqxiaozou.top/img/20211116.jpg",
"price": 4288
}
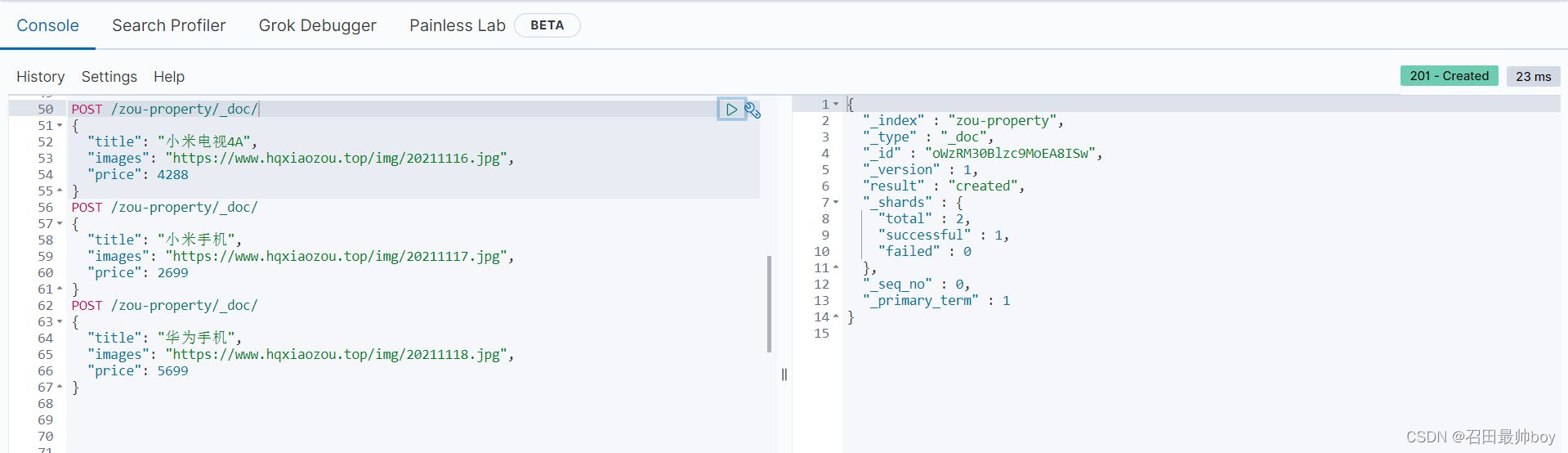
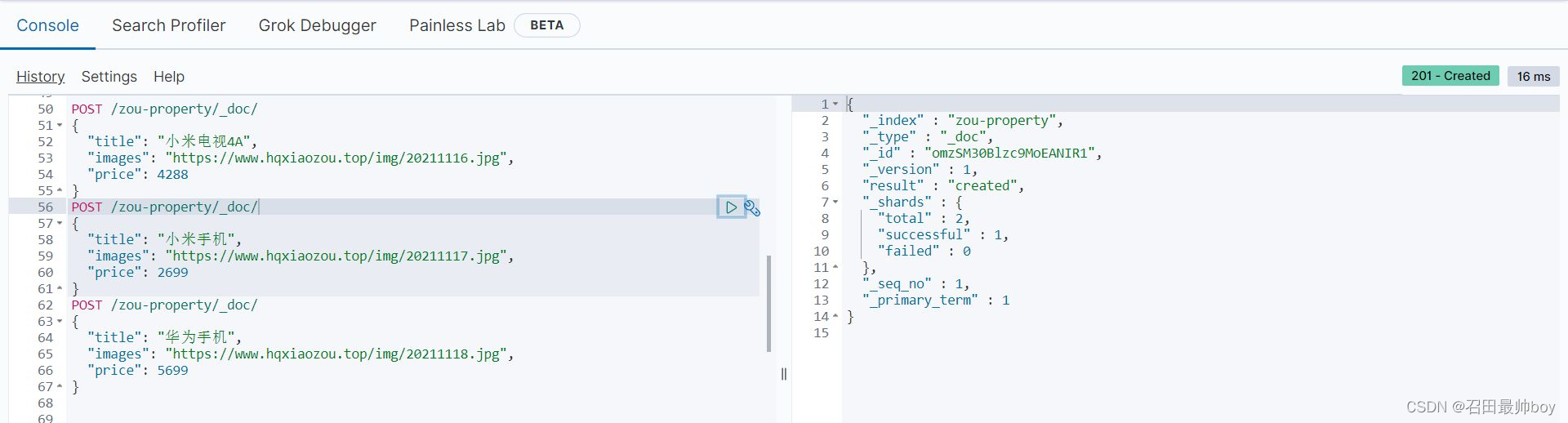
POST /zou-property/_doc/
{
"title": "小米手机",
"images": "https://www.hqxiaozou.top/img/20211117.jpg",
"price": 2699
}
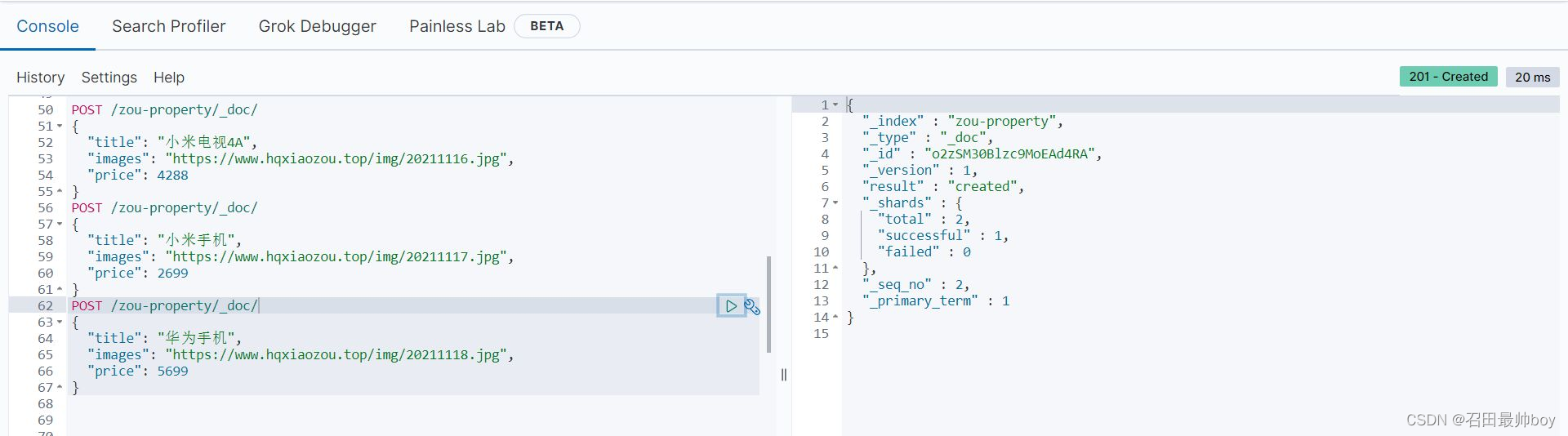
POST /zou-property/_doc/
{
"title": "华为手机",
"images": "https://www.hqxiaozou.top/img/20211118.jpg",
"price": 5699
}
# match 类型查询:会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
# 不仅会查询到电视,而且与小米相关的都会查询到,多个词之间是 or 的关系。
POST /zou-property/_search
{
"query": {
"match": {
"title": "小米电视4A"
}
}
}
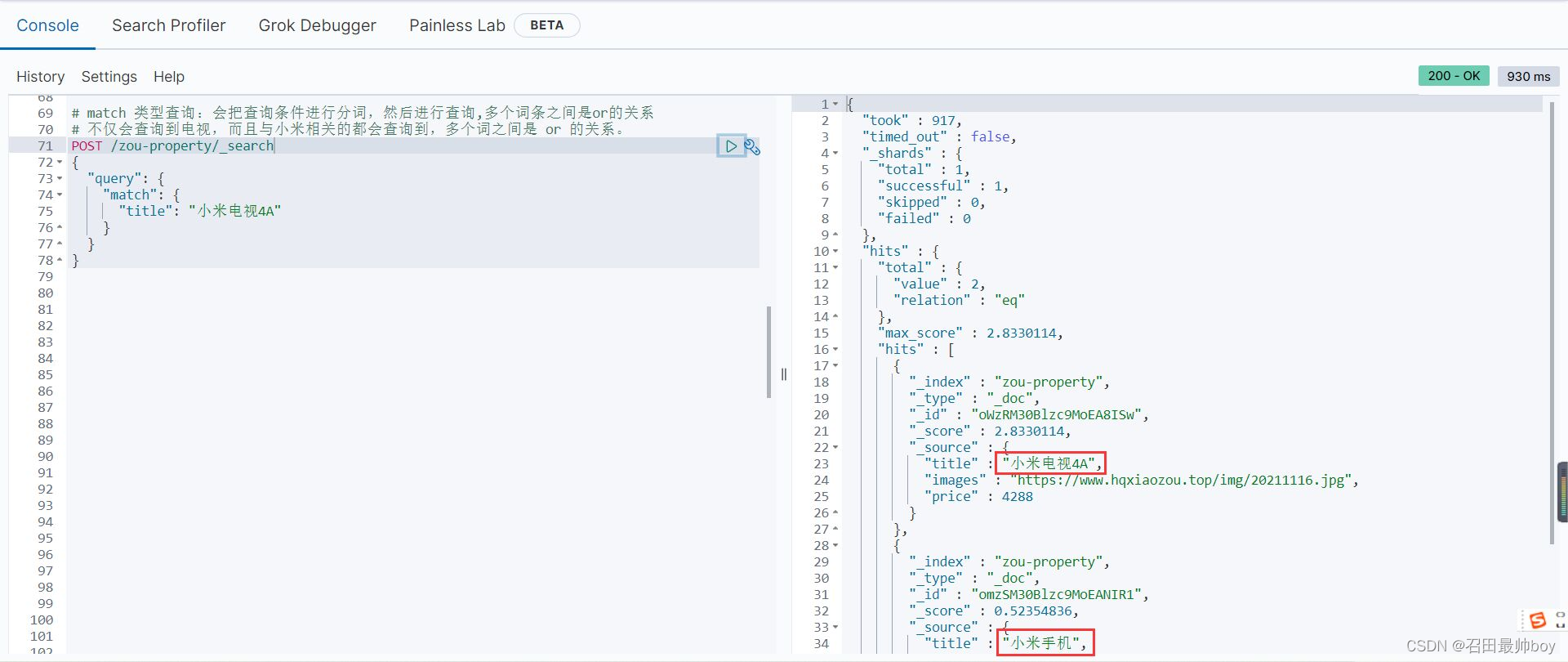
# and关系:某些情况下,我们需要更精确查找,我们希望这个关系变成 and
# 只有同时包含 小米 和 电视 的词条才会被搜索到
POST /zou-property/_search
{
"query": {
"match": {
"title": {
"query": "小米电视4A",
"operator": "and"
}
}
}
}
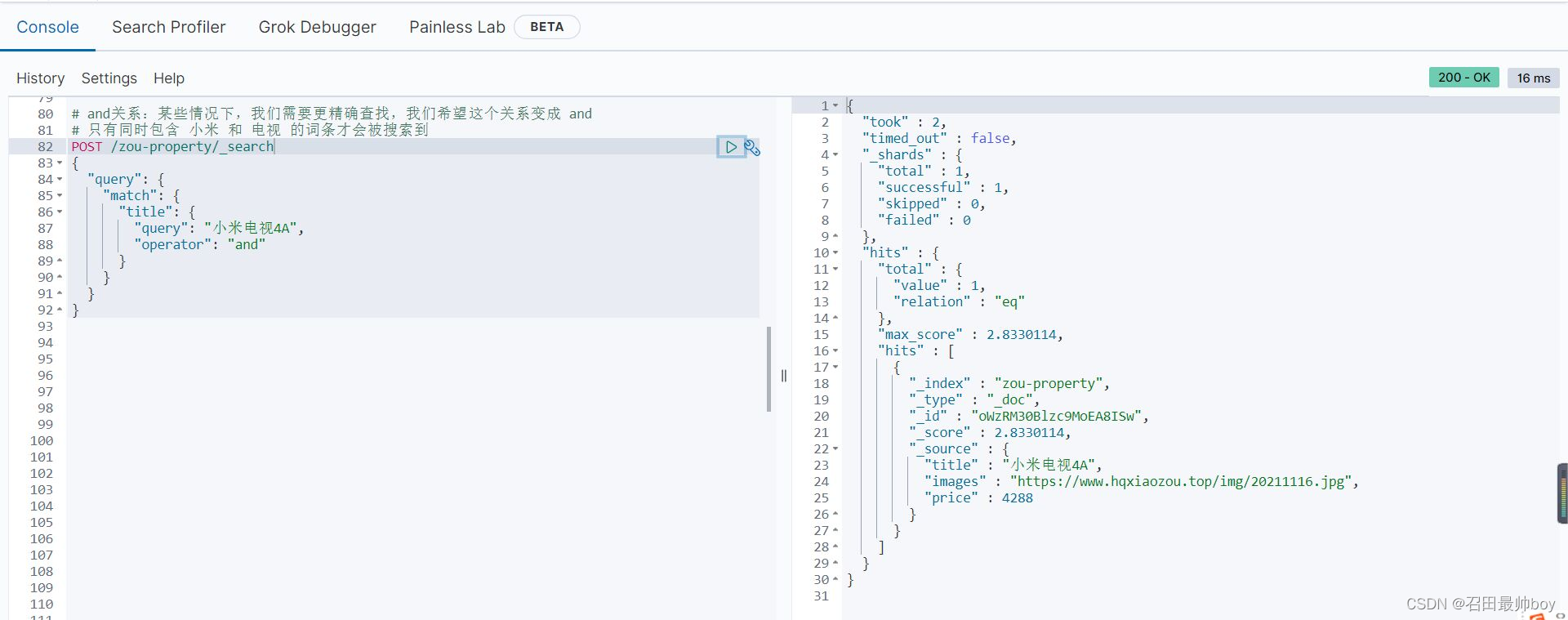
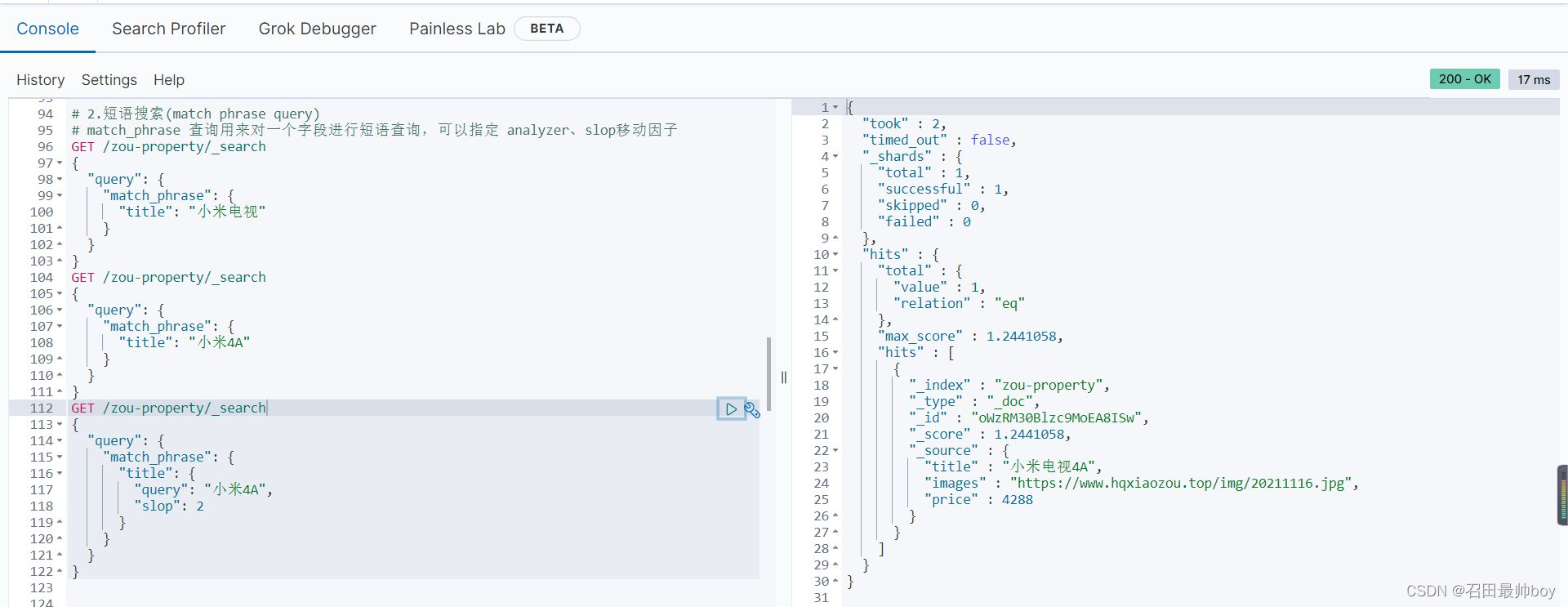
# 2.短语搜索(match phrase query)
# match_phrase 查询用来对一个字段进行短语查询,可以指定 analyzer、slop移动因子
GET /zou-property/_search
{
"query": {
"match_phrase": {
"title": "小米电视"
}
}
}
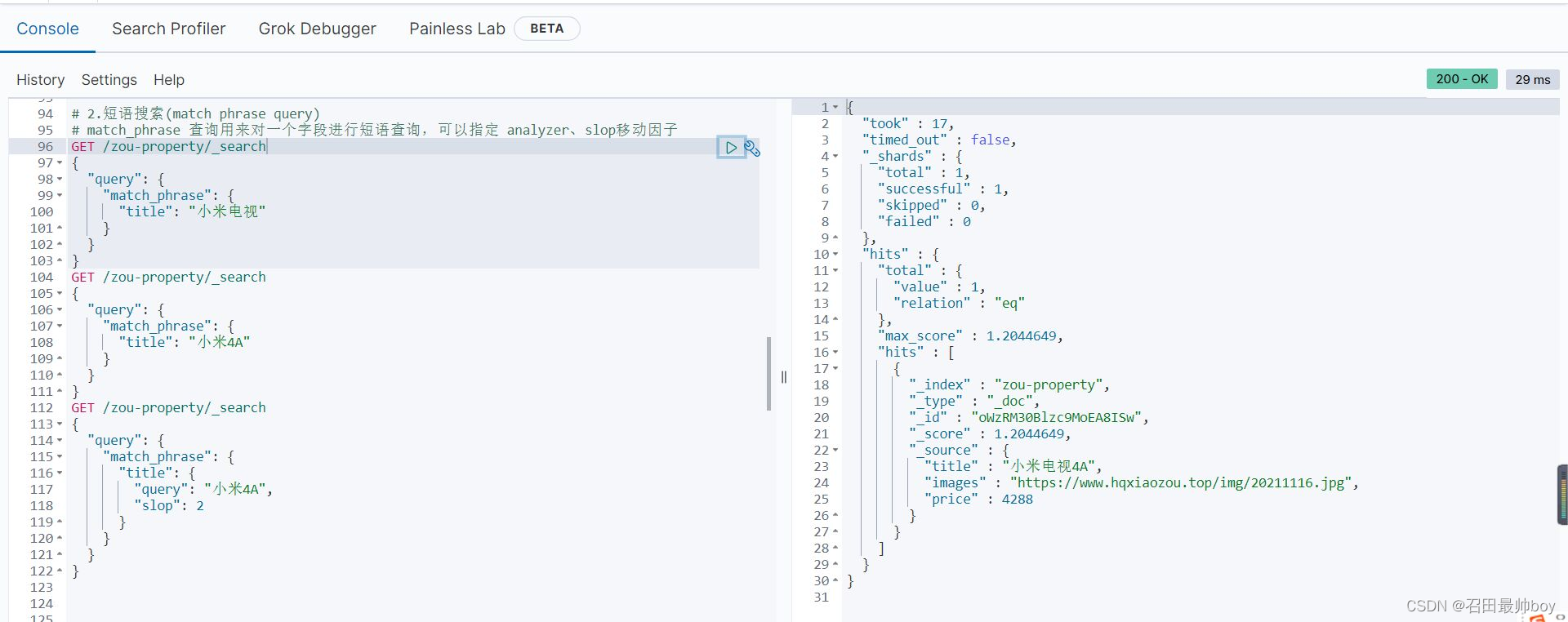
GET /zou-property/_search
{
"query": {
"match_phrase": {
"title": "小米4A"
}
}
}
GET /zou-property/_search
{
"query": {
"match_phrase": {
"title": {
"query": "小米4A",
"slop": 2
}
}
}
}
# query_string 查询:提供了无需指定某字段而对文档全文进行匹配查询的一个高级查询,同时可以指定在哪些字段上进行匹配。
# 指定字段 和 默认
GET /zou-property/_search
{
"query": {
"query_string": {
"query": "2699"
}
}
}
GET /zou-property/_search
{
"query": {
"query_string": {
"query": "2699",
"default_field": "title"
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pYZmgvP5-1653391981053)(http://47.100.15.29/1117/50.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xwf7FVAZ-1653391981053)(http://47.100.15.29/1117/51.jpg)]
# 逻辑查询
GET /zou-property/_search
{
"query": {
"query_string": {
"query": "手机 OR 小米",
"default_field": "title"
}
}
}
GET /zou-property/_search
{
"query": {
"query_string": {
"query": "手机 AND 小米",
"default_field": "title"
}
}
}


# 模糊查询
GET /zou-property/_search
{
"query": {
"query_string": {
"query": "大米~1",
"default_field": "title"
}
}
}

# 多字段支持
GET /zou-property/_search
{
"query": {
"query_string": {
"query": "2699",
"fields": [
"title",
"price"
]
}
}
}

# 多字段匹配搜索(multi match query)
# 如果你需要在多个字段上进行文本搜索,可用multi_match 。
GET /zou-property/_search
{
"query": {
"multi_match": {
"query": "2699",
"fields": [
"title",
"price"
]
}
}
}

# 还可以使用*匹配多个字段
GET /zou-property/_search
{
"query": {
"multi_match": {
"query": "https://www.hqxiaozou.top/img/20211118.jpg",
"fields": [
"title",
"ima*"
]
}
}
}

# 词条级搜索(term-level queries)
# 可以使用term-level queries根据结构化数据中的精确值查找文档。与全文查询不同,term-level queries不分析搜索词
PUT /book
{
"settings": {},
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "ik_max_word"
},
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"price": {
"type": "float"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}

PUT /book/_doc/1
{
"name":"lucene",
"description":"Lucene Core is a Java library providing powerful indexing and search features, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities. The PyLucene sub project provides Python bindings for Lucene Core.",
"price":100.45,
"timestamp":"2021-11-19 10:10:10"
}
PUT /book/_doc/2
{
"name": "solr",
"description": "Solr is highly scalable, providing fully fault tolerant distributed indexing, search and analytics. It exposes Lucenes features through easy to use JSON/HTTP interfaces or native clients for Java and other languages.",
"price": 320.45,
"timestamp": "2021-10-19 11:10:10"
}
PUT /book/_doc/3
{
"name": "Hadoop",
"description": "The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.",
"price": 620.45,
"timestamp": "2021-09-19 12:10:10"
}
PUT /book/_doc/4
{
"name":"ElasticSearch",
"description":"Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、ApacheGroovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。",
"price":999.99,
"timestamp":"2021-08-19 13:10:10"
}

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qInJ8blA-1653391981056)(http://47.100.15.29/1117/60.jpg)]

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mhzePTCz-1653391981056)(http://47.100.15.29/1117/62.jpg)]
# 词条搜索(term query):term 查询用于查询指定字段包含某个词项的文档
POST /book/_search
{
"query": {
"term": {
"name": "solr"
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pgSW2kI6-1653391981057)(http://47.100.15.29/1117/63.jpg)]
# 词条集合搜索(terms query):terms 查询用于查询指定字段包含某些词项的文档
GET /book/_search
{
"query": {
"terms": {
"name": [
"solr",
"elasticsearch"
]
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UcgDtIqC-1653391981057)(http://47.100.15.29/1117/64.jpg)]
# 范围搜索(range query):gte:大于等于、gt:大于、lte:小于等于、lt:小于、boost:查询权重
GET /book/_search
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 200,
"boost": 2
}
}
}
}
GET /book/_search
{
"query": {
"range": {
"timestamp": {
"gte": "now-2d/d",
"lt": "now/d"
}
}
}
}
GET /book/_search
{
"query": {
"range": {
"timestamp": {
"gte": "19/09/2021",
"lte": "2022",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MhNdVsYS-1653391981057)(http://47.100.15.29/1117/65.jpg)]

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oLwbzqKq-1653391981058)(http://47.100.15.29/1117/67.jpg)]
# 不为空搜索(exists query):查询指定字段值不为空的文档。相当 SQL 中的 is not null
GET /book/_search
{
"query": {
"exists": {"field": "price"}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YNGAD5s0-1653391981058)(http://47.100.15.29/1117/68.jpg)]
# 词项前缀搜索(prefix query)
GET /book/_search
{
"query": {
"prefix": {"name": "el"}
}
}

# 通配符搜索(wildcard query)
GET /book/_search
{
"query": {
"wildcard": {"name": "so*r"}
}
}
GET /book/_search
{
"query": {
"wildcard": {
"name": {
"value": "lu*",
"boost": 2
}
}
}
}

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GuzVzYjU-1653391981059)(http://47.100.15.29/1117/71.jpg)]
# 正则搜索(regexp query)
# regexp允许使用正则表达式进行term查询。注意regexp如果使用不正确,会给服务器带来很严重的性能压力。比如.*开头的查询,将会匹配所有的倒排索引中的关键字,这几乎相当于全表扫描,会很慢。因此如果可以的话,最好在使用正则前,加上匹配的前缀。
GET /book/_search
{
"query": {
"regexp": {
"name": "s.*"
}
}
}
GET /book/_search
{
"query": {
"regexp": {
"name": {
"value": "s.*",
"boost": 1.2
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ICqfL656-1653391981059)(http://47.100.15.29/1117/72.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pFDGoINy-1653391981060)(http://47.100.15.29/1117/73.jpg)]
# 模糊搜索(fuzzy query)
GET /book/_search
{
"query": {
"fuzzy": {
"name": "so"
}
}
}
GET /book/_search
{
"query": {
"fuzzy": {
"name": {
"value": "so",
"boost": 1.0,
"fuzziness": 2
}
}
}
}
GET /book/_search
{
"query": {
"fuzzy": {
"name": {
"value": "sorl",
"boost": 1.0,
"fuzziness": 2
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n34tg80G-1653391981060)(http://47.100.15.29/1117/74.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rerwKuFB-1653391981060)(http://47.100.15.29/1117/75.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tvezX1Pi-1653391981061)(http://47.100.15.29/1117/76.jpg)]
# ids搜索(id集合查询)
GET /book/_search
{
"query": {
"ids": {
"type": "_doc",
"values": ["1","3"]
}
}
}

# 复合搜索(compound query)
# constant_score query:用来包装另一个查询,将查询匹配的文档的评分设为一个常值
GET /book/_search
{
"query": {
"term": {
"description": "solr"
}
}
}
GET /book/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"description": "solr"
}
},
"boost": 1.2
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eiOya4aE-1653391981061)(http://47.100.15.29/1117/78.jpg)]

# 布尔搜索(bool query)
# bool 查询用bool操作来组合多个查询字句为一个查询。
# 可用的关键字:must:必须满足、filter:必须满足,但执行的是filter上下文,不参与、不影响评分、should:或、must_not:必须不满足,在filter上下文中执行,不参与、不影响评分
# minimum_should_match代表了最小匹配精度,如果设置minimum_should_match=1,那么should
# 语句中至少需要有一个条件满足
POST /book/_search
{
"query": {
"bool": {
"must": {
"match": {
"description": "java"
}
},
"filter": {
"term": {
"name": "solr"
}
},
"must_not": {
"range": {
"price": {
"gte": 200,
"lte": 300
}
}
},
"minimum_should_match": 1,
"boost": 1
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YDqWtOZ0-1653391981062)(http://47.100.15.29/1117/80.jpg)]
# 排序
# 相关性评分排序
# 为了按照相关性来排序,需要将相关性表示为一个数值。在 Elasticsearch 中, 相关性得分 由一个浮点数进行表示,并在搜索结果中通过 _score 参数返回, 默认排序是 _score 降序,按照相关性评分升序排序如下
POST /book/_search
{
"query": {
"match": {
"description": "solr"
}
}
}
POST /book/_search
{
"query": {
"match": {
"description": "solr"
}
},
"sort": [
{
"_score": {
"order": "asc"
}
}
]
}


# 字段值排序
POST /book/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}

# 多级排序:假定我们想要结合使用 price和 _score(得分) 进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序。
POST /book/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
},
{
"timestamp": {
"order": "desc"
}
}
]
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VgntlabS-1653391981063)(http://47.100.15.29/1117/84.jpg)]
# 分页
POST /book/_search
{
"query": {
"match_all": {}
},
"size": 2,
"from": 0
}
POST /book/_search
{
"query": {
"match_all": {}
},
"sort": [
{"price": {"order":"desc"}}
],
"size": 2,
"from": 0
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r0kdb2yO-1653391981063)(http://47.100.15.29/1117/85.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hEXbyOS3-1653391981064)(http://47.100.15.29/1117/86.jpg)]
# 高亮
POST /book/_search
{
"query": {
"match": {
"name": "elasticsearch"
}
},
"highlight": {
"pre_tags": "<font color='pink'>",
"post_tags": "</font>",
"fields": [{"name":{}}]
}
}
POST /book/_search
{
"query": {
"match": {
"name": "elasticsearch"
}
},
"highlight": {
"pre_tags": "<font color='pink'>",
"post_tags": "</font>",
"fields": [{"name":{}},{"description":{}}]
}
}
POST /book/_search
{
"query": {
"query_string": {
"query": "elasticsearch"
}
},
"highlight": {
"pre_tags": "<font color='pink'>",
"post_tags": "</font>",
"fields": [{"name":{}},{"description":{}}]
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jmxkKFbh-1653391981064)(http://47.100.15.29/1117/87.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-48soFxi1-1653391981064)(http://47.100.15.29/1117/88.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r6P4WMEP-1653391981065)(http://47.100.15.29/1117/89.jpg)]
# 文档批量操作(bulk 和 mget)
# mget 批量查询
# 单条查询 GET /test_index/_doc/1,如果查询多个id的文档一条一条查询,网络开销太大。
GET /_mget
{
"docs": [
{
"_index": "book",
"_id": 1
},
{
"_index": "book",
"_id": 2
}
]
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sTNcq5ZE-1653391981065)(http://47.100.15.29/1117/90.jpg)]
# 同一索引下批量查询
GET /book/_mget
{
"docs": [
{
"_id": 2
},
{
"_id": 3
}
]
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NsAEpkcF-1653391981065)(http://47.100.15.29/1117/91.jpg)]
# 搜索简化写法
POST /book/_search
{
"query": {
"ids": {
"values": ["1","4"]
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E4AeArfw-1653391981065)(http://47.100.15.29/1117/92.jpg)]
# bulk 批量增删改
# Bulk 操作解释将文档的增删改查一些列操作,通过一次请求全都做完。减少网络传输次数。
# 格式:每个json不能换行。相邻json必须换行。
# 隔离:每个操作互不影响。操作失败的行会返回其失败信息。
# 实际用法:bulk请求一次不要太大,否则一下积压到内存中,性能会下降。所以,一次请求几千个操作、大小在几M正好。bulk会将要处理的数据载入内存中,所以数据量是有限的,最佳的数据两不是一个确定的数据,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。一般建议是1000-5000个文档,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(ES的config下的elasticsearch.yml)中配置。 http.max_content_length: 10mb
# 如下操作,删除1,新增5,修改2。
POST /_bulk
{"delete":{"_index":"book","_id":"1"}}
{"create":{"_index":"book","_id":"5"}}
{"name":"test_bulk","price":100.99}
{"update":{"_index":"book","_id":"2"}}
{"doc":{"name":"test"}}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yASzLSUd-1653391981066)(http://47.100.15.29/1117/93.jpg)]
Filter DSL
# Elasticsearch中的所有的查询都会触发相关度得分的计算。对于那些我们不需要相关度得分的场景下,Elasticsearch以过滤器的形式提供了另一种查询功能,过滤器在概念上类似于查询,但是它们有非常快的执行速度,执行速度快主要有以下两个原因
# 1.过滤器不会计算相关度的得分,所以它们在计算上更快一些。
# 2.过滤器可以被缓存到内存中,这使得在重复的搜索查询上,其要比相应的查询快出许多。
POST /book/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"range": {
"price": {
"gte": 200,
"lte": 1000
}
}
}
}
}
}

定位非法搜索及原因
# 在开发的时候,我们可能会写到上百行的查询语句,如果出错的话,找起来很麻烦,Elasticsearch提供了帮助开发人员定位不合法的查询的api:_validate
# _validate
# 在查询时,不小心把 match 写成了 match1 ,通过 validate api 可以清楚的看到错误原因
GET /book/_validate/query?explain
{
"query": {
"match1": {
"name": "test"
}
}
}

聚合分析
对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合 metric。而关系型数据库中除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行指标聚合。在 ES 中group by 称为分桶,桶聚合 bucketing
在查询请求体中以aggregations节点按如下语法定义聚合分析:
"aggregations" : {
"<aggregation_name>" : { <!--聚合的名字 -->
“<aggregation_type>" : { <!--聚合的类型 -->
<aggregation_body> <!--聚合体:对哪些字段进行聚合 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!--元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!--在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { ... } ]*<!--聚合的名字 -->
}
说明:aggregations 也可简写为 aggs
# 查询所有书中最贵的
# max
POST /book/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}

# 统计price大于100的文档数量
POST /book/_search
{
"query": {
"range": {
"price": {
"gt": 100
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1PzUyxdH-1653391981067)(http://47.100.15.29/1117/97.jpg)]
# value_count 统计某字段有值的文档数
POST /book/_search?size=0
{
"aggs": {
"price_count": {
"value_count": {
"field": "price"
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PIiEgngm-1653391981067)(http://47.100.15.29/1117/98.jpg)]
# cardinality值去重计数 基数
POST /book/_search?size=0
{
"aggs": {
"_id_count": {
"cardinality": {
"field": "id"
}
},
"price_count": {
"cardinality": {
"field": "price"
}
}
}
}

# stats 统计 count max min avg sum 5个值
POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zxafzd5g-1653391981068)(http://47.100.15.29/1117/100.jpg)]
# Extended stats
# 高级统计,比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间
POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"extended_stats": {
"field": "price"
}
}
}
}

# Percentiles 占比百分位对应的值统计
POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price"
}
}
}
}
# 指定分位值
POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price",
"percents": [
75,
99,
99.9
]
}
}
}
}

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vliRBcj0-1653391981069)(http://47.100.15.29/1117/103.jpg)]
# Percentiles rank 统计值小于等于指定值的文档占比
# 统计price小于100和200的文档的占比
POST /book/_search?size=0
{
"aggs": {
"gge_perc_rank": {
"percentile_ranks": {
"field": "price",
"values": [
100,
200
]
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UmLDuOyo-1653391981069)(http://47.100.15.29/1117/104.jpg)]















 4791
4791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









