







Flink 安装的教程就不在这里赘叙了,可以看一下以前的文章,这篇文章主要是把流式数据写入的OLAP(ClickHouse)中作查询分析Flink 1.13.2, ClickHouse 22.1.3.7
1、安装ClickHouse(MacOS)
这里直接使用docker安装,没有安装的同学可以使用homebreak来安装,执行下面的命令即可(已经安装了docker的可以忽略)
brew install --cask --appdir=/Applications docker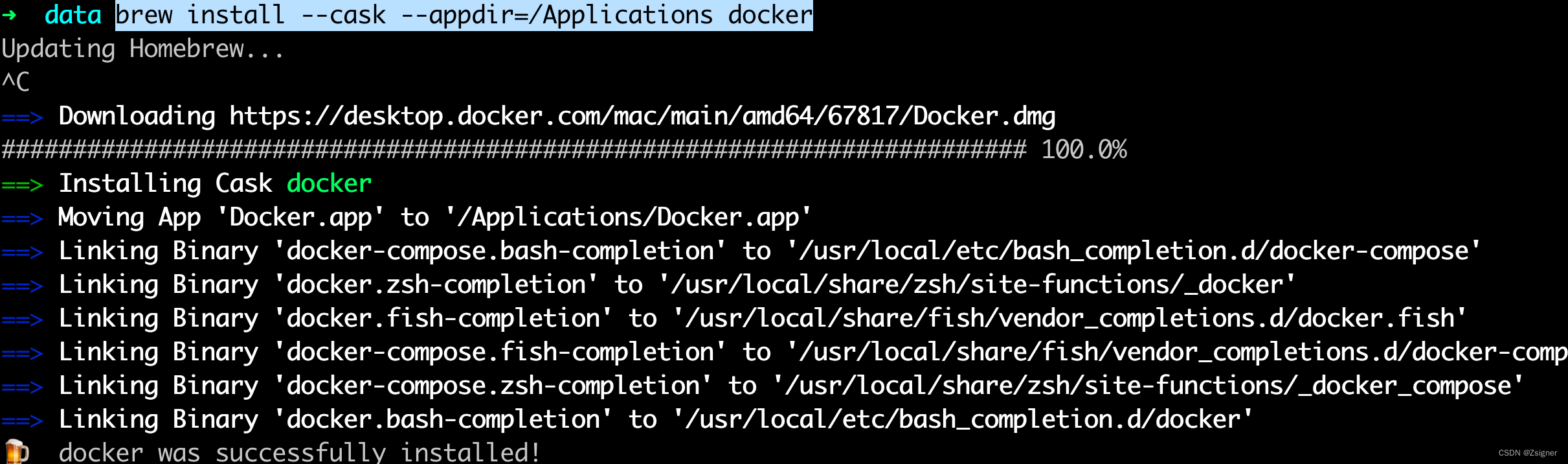
1.1 启动docker
四指进入Application ,双击Docker 图表安装,一直点击下一步即可

1.2 拉取ClickHouse 镜像
--客户端
docker pull yandex/clickhouse-client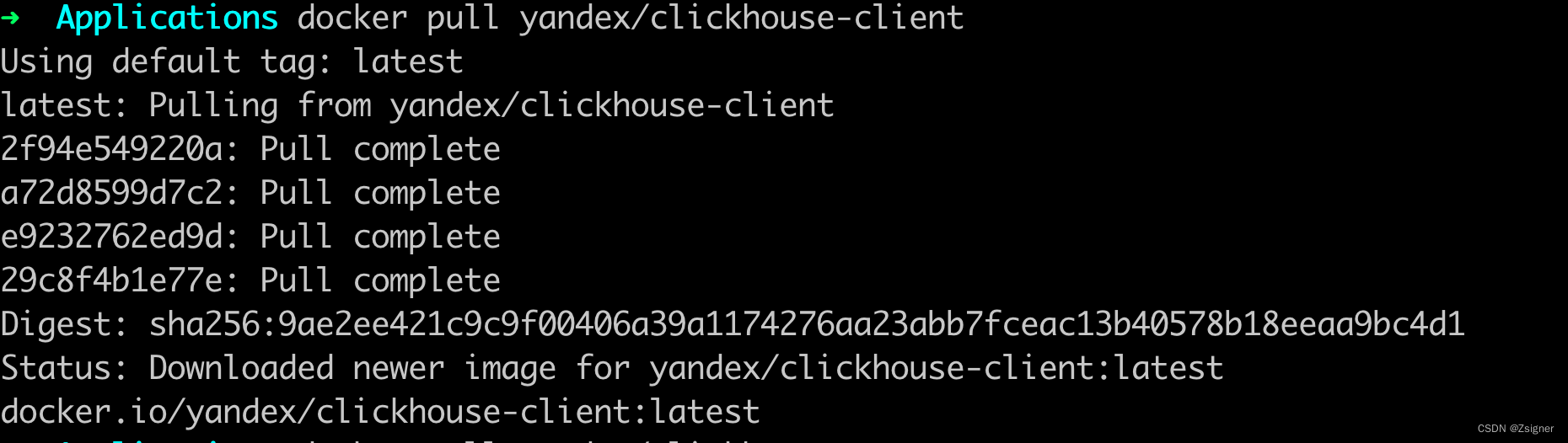
--服务端
docker pull yandex/clickhouse-server
1.3 启动ClickHouse Server
docker run -d --name ch-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 -p 9009:9009 yandex/clickhouse-server
1.4 查询是否启动成功
docker ps
1.4.1 打开web-ui 页面
http://127.0.0.1:8123/play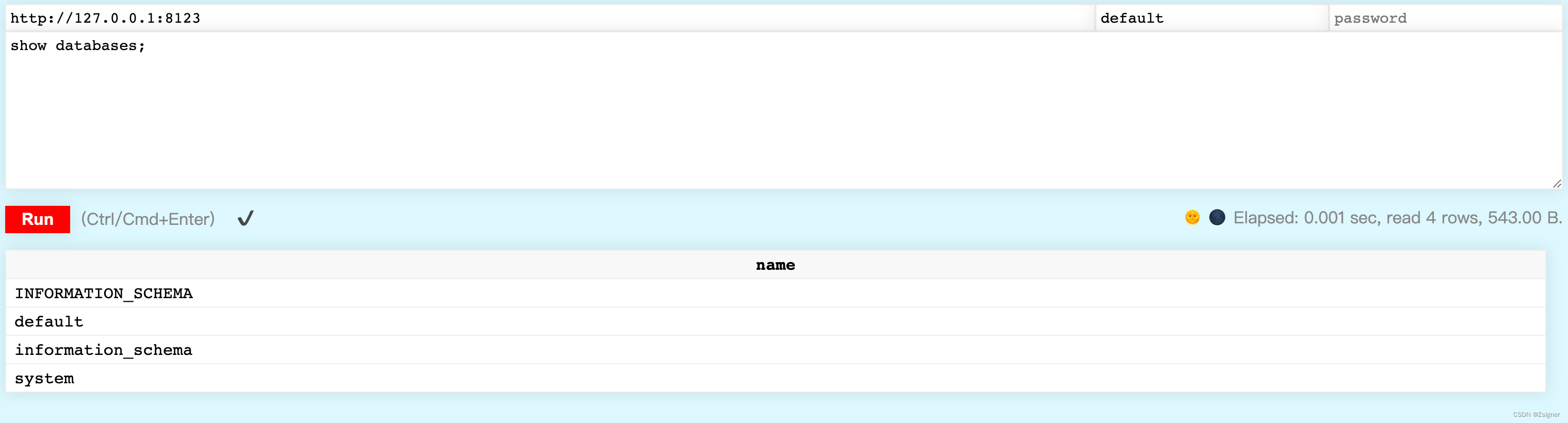
1.5 成功安装好了ClickHouse
想看更多的安装方式可以查看官网安装 | ClickHouse Docs
1.6 拓展:Client登陆方式
有些同学想等过clickhouse-client登陆,也是可以的,不过就是稍微有点麻烦,建议只是测试使用的时候用web-ui就能满足,想通过clickhouse-client登陆呢,就必须进去到镜像
1.6.1 获取镜像id
-- 获取镜像ID
docker ps
1.6.2 进入镜像
docker exec -it a7d127a4f91b /bin/bash
1.6.3 使用client 登陆(默认没有密码)
bin/clickhouse-client

2. 编码
2.1 在clickhouse中创建表
CREATE TABLE IF NOT EXISTS default.t_user(id UInt16,
name String,
age UInt16 ) ENGINE = TinyLog();

2.2 引入flink-sink-clickhouse jar包
<!-- clickhouse -->
<dependency>
<groupId>ru.ivi.opensource</groupId>
<artifactId>flink-clickhouse-sink</artifactId>
<version>1.3.3</version>
<dependency>2.3 读取流式数据
DataStream<String> inputStream = env.socketTextStream("localhost", 18888);2.4 Transform 部分
//transform
SingleOutputStreamOperator<String> userStream = sourceStream
.map(v -> new UserTest(v))
.setParallelism(1)
.name("convert_user_map")
.map(v -> UserTest.convertToCsv(v))
.setParallelism(1)
.name("convert_csv_map");public class UserTest {
public int id;
public String name;
public int age;
public UserTest(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public UserTest(String v) {
String[] split = v.split(",");
this.id = Integer.valueOf(split[0]);
this.name = split[1];
this.age = Integer.valueOf(split[2]);
}
public UserTest of(int id, String name, int age) {
return new UserTest(id, name, age);
}
// 构造Value 部分(1,'李四',20)
public static String convertToCsv(UserTest user) {
StringBuilder sb = new StringBuilder("(");
// add user.id
sb.append(user.id);
sb.append(", ");
// add user.name
sb.append("'");
sb.append(String.valueOf(user.name));
sb.append("', ");
// add user.age
sb.append(user.age);
sb.append(" )");
return sb.toString();
}
}2.5 sink
// create props for sink
Properties props = new Properties();
props.put(ClickHouseSinkConst.TARGET_TABLE_NAME, "default.t_user");
props.put(ClickHouseSinkConst.MAX_BUFFER_SIZE, "10000");
ClickHouseSink sink = new ClickHouseSink(props);
dataStream.addSink(sink);
dataStream.print();2.6 测试
2.6.1 启动18888端口
nc -l 18888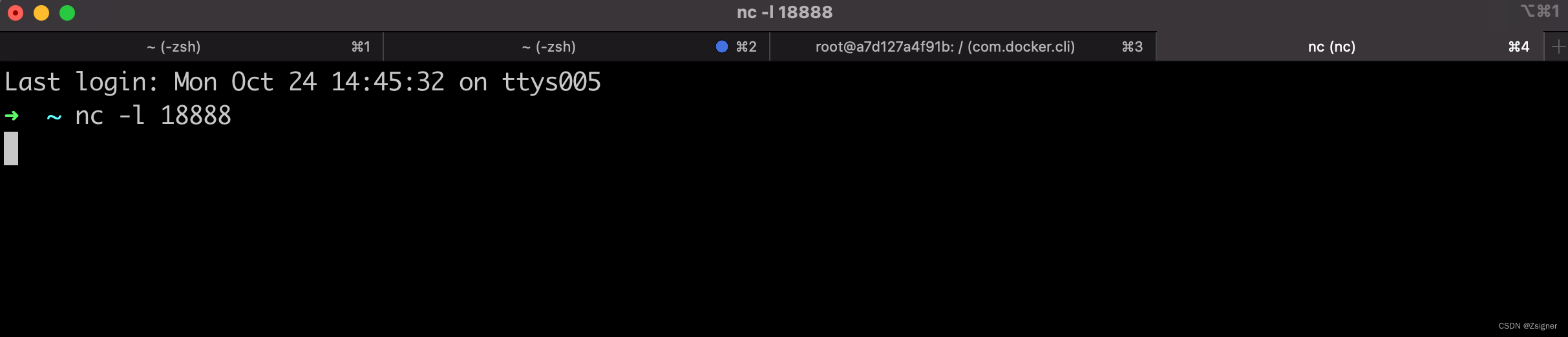
2.6.2 启动程序

2.6.3 输入测试数据
1,lisi,20
5,wangwu,30
6,zz,100
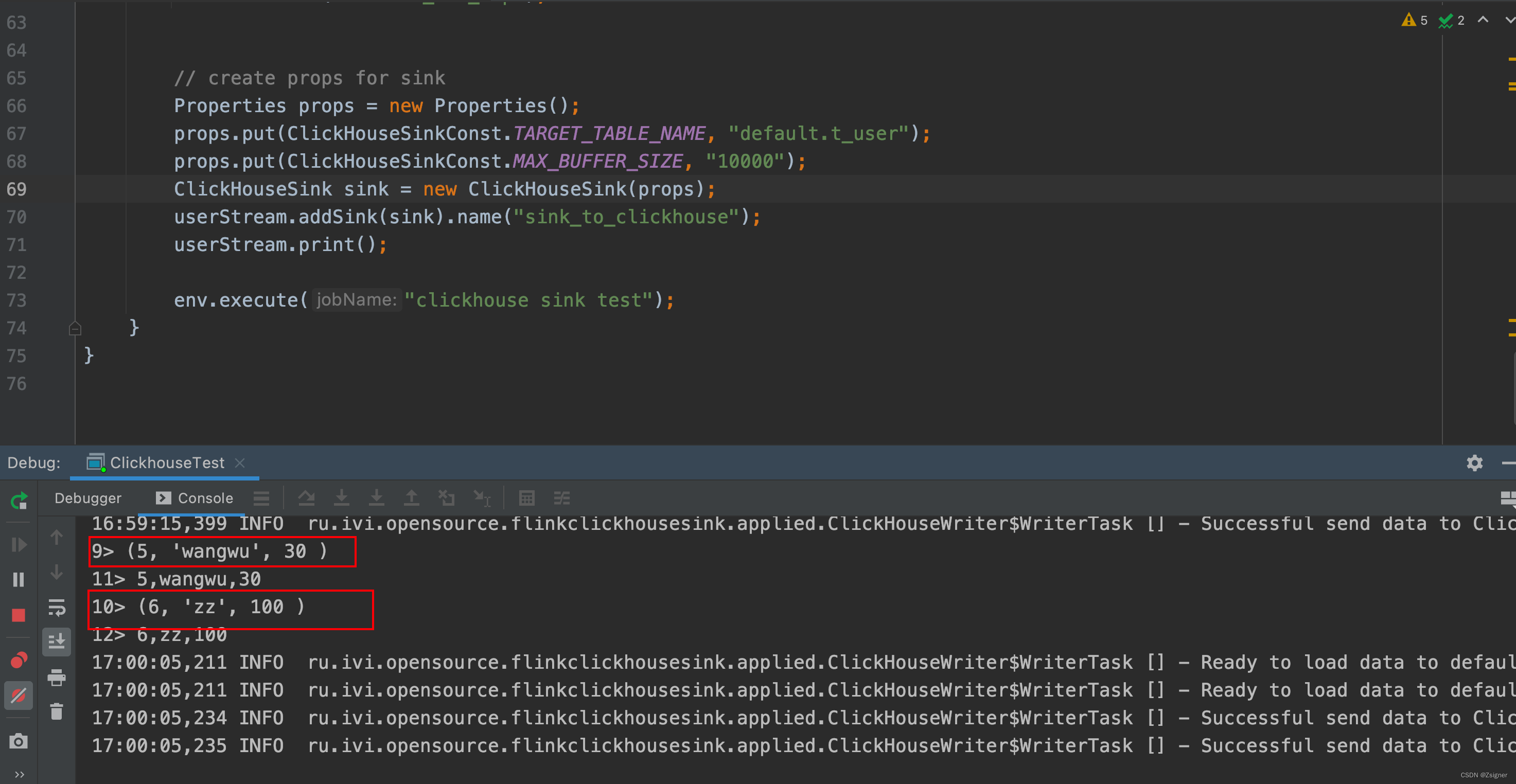
2.6.4 查看数据是否成功写入
select * from default.t_user;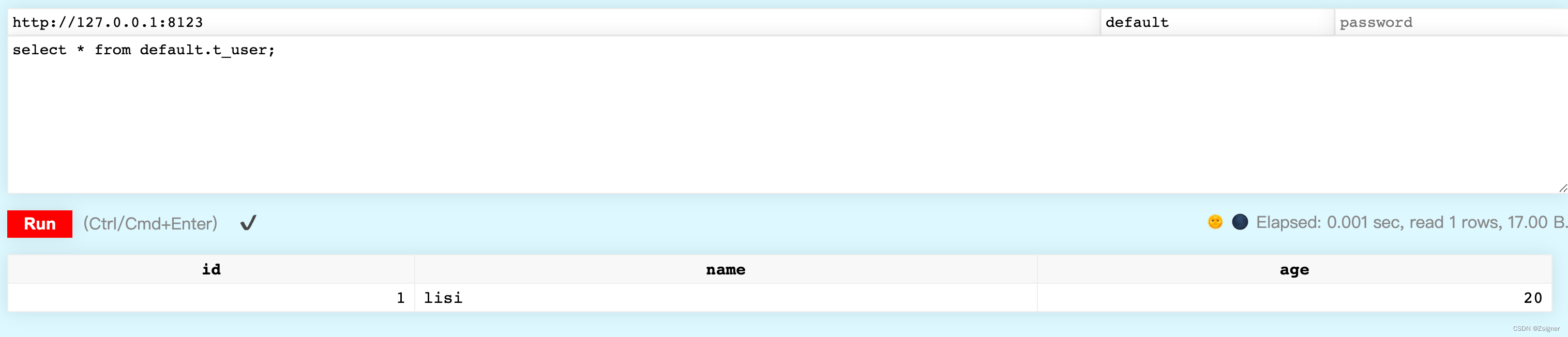

发现所有数据都成功写入到ClickHouse中了,WellDone!!!
3.拓展
3.1 完整的代码(包括SQL,测试数据)
都上传到github上了
(如果可以,请点一下star⭐️,谢谢支持):
Github:https://github.com/BiGsuw/flink-learning/blob/main/src/main/java/com/flink/demo/sink/ClickHouseTest.java
















 4136
4136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











