









声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
本文已在微信公众号发布
目标
网站
aHR0cHM6Ly9tb2JpbGUucGluZHVvZHVvLmNvbS8=
任务
获取商品列表接口中的内容
接口参数分析
我们获取的接口。可能在web端出不来。所以我们切换成手机端。

然后刷新网页。

然后我们跟栈一步一步去找这个anti_content

从第一个栈慢慢进就行了。
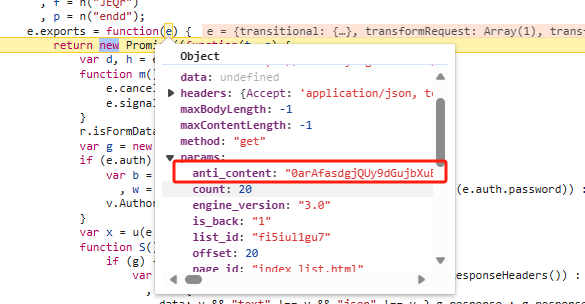
断点到这里 就能看到 anti_content的值了 但是这个值好像并不是生成值的地方。继续往上找。
走到异步方法里面。
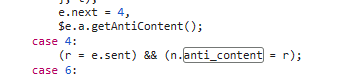
然后找到这个方法。
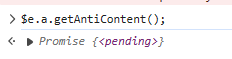
发现这个方法只是个实例对象 没办法调用,但是我们因此知道了 这个方法。我们搜下这个方法试试

看到一共有五个。我们去最后这个方法里面看看。不要问为什么只看最后一个。

一步一步打断点 进入这个 n.getRiskControlInfoAsync()方法里面。
然后再一步一步打断点(这是个过程,需要很有耐心 一步一追踪)


最终发现anti_content的值。
其实这个时候不难发现。这是个ob混淆啊。
生成逻辑分析
我们先不着急去扣代码。或者是干别的。我们先来看看他的生成逻辑。
我们进入ne这个方法去看看里面的生成。

这个方法 前面都是一些逻辑层的移位与混淆还有定义变量。这里就不分析了。
这里我简单脱了一下混淆
function ne() {
function n(e, t) {
return B(t, e - 1064)
}
var r = t["CTxCC"]
,
a = (e = [])["concat"].apply(e, [W[r](), P[r](), C[r](), E[r](), I[r](), D[r](), T[r](), N[r](), R[r](), A[r](), L[r](), M[r](), z[r]()].concat(function (e) {
if (Array.isArray(e)) {
for (var t = 0, n = Array(e.length); t < e.length; t++)
n[t] = e[t];
return n
}
return Array.from(e)
}(q[r]()), [F[r](), G[r](), Q[r](), H[r](), U[r](), V[r](), Y[r](), J[r](), X[r]()]));
t["npRBP"](setTimeout, (function () {
t["JSeyi"](ee)
}
), 0);
for (var c = a["length"]["toString"](2)["split"](""),
s = 0;
t["iSDtI"](c["length"], 16); s += 1)
c["unshift"]("0");
c = c["join"]("");
var u = [];
t["hNmVQ"](a["length"], 0) ? u["push"](0, 0) : t["xfDub"](a["length"], 0) && t["HvucD"](a["length"], t["kbnzE"](t["YrazO"](1, 8), 1)) ? u["push"](0, a["length"]) : t["fBcAN"](a['length'], t["kbnzE"](t["YrazO"](1, 8), 1)) && u["push"](d["parseInt"](c["substring"](0, 8), 2), d["parseInt"](c["substring"](8, 16), 2)),
a = []["concat"]([1], [1, 0, 0], u, a);
var l = o["deflate"](a)
, p = []["map"]["call"](l, (function (e) {
return String["fromCharCode"](e)
}
));
function h(e, t) {
return B(t, e - 1797)
}
return t["dhItA"](t["yQQNR"], i["encode"](t["dhItA"](p["join"](""), f["join"]("")), i["budget"]))
}
其实可以看到
- r获取a的切片值。 通过合并多个数组(其实这里都是cookie和一些指纹。),从而让a获取qr展开后的内容再次合并形成一个新的数组。
- 之前获得的新数组重新展开生成一个二进制的新字符串。并且添加了补长度功能。
- 根据a 和 u判断从而继续生成新数组
- 再根据新数组 重新添加某些值。并且进行了压缩操作。
- 压缩并且再生成字符串 然后进行编码生成anti_content。
解决方案
其实这个有两种思路。根据刚刚我提供的思路
第一种:硬扣代码。
难度较大
第二种就是使用webpack去扣。其实也说不上来扣 全都抓取下来 然后补环境就行。
至于为什么是webpack。往上翻就行了。

首先这是一个一个模块。这就不多说了。
再次再往上滑。看到加载器.

然后把加载器和后面的列表全扣下来就行。
然后全部扣下来之后。我们不要放到代码中运行。
我们利用浏览器的这个片段。直接运行看看。

ok 也能直接出结果 感觉长度的话也像那么回事。现在我们搞到代码里面慢慢补就行了。
补环境

这里呢首先第一个错就是Cannot use 'in' operator to search for 'ontouchstart' in undefined
这还是个移动端事件
手指触摸屏幕时触发,即使已经有手指在屏幕上也会触发。但是我们的代码中没有这个事件。所以就会报错。
这是个监听事件。我们先加上监听事件。看看然后会不会报错
document = {};
document.addEventListener = function addEventListener(type, listener, options, useCapture){};
然后发现就不报这个错了。

然后就开始报另一个错
根据网页API中所写 https://developer.mozilla.org/zh-CN/docs/Web/API/Screen/availWidth
这个方法是返回浏览器窗口可占用的水平宽度(单位:像素)。
但是这个是个方法 所以不能直接赋值 需要用方法的方式。
window.screen = Screen = function () {
return {
availHeight: 1032,
availLeft: 0,
availTop: 0,
availWidth: 1920,
colorDepth: 24,
height: 1080,
isExtended: false,
}
}
这个补完之后还有个报错。

报错 Element 没有被定义。
这里呢,官方解释是这样的:
Element 是最通用的基类,Document 中的所有元素对象(即表示元素的对象)都继承自它。它只具有各种元素共有的方法和属性。更具体的类则继承自 Element。
这个方法要补的其实不少。但是我们可以简单定义一个对象。后期需要什么就补什么
Element = function(){}
剩下的其实也就是一样。缺什么补什么 可以挂个proxy框架。很简单。大家可以自己试试,
结果

结语
有问题的同学记得私信。平台上回复有可能不及时。最好加一下公众号。
最近和小伙伴新建了个微信公众号和星球。有兴趣的小伙伴可以加一下。
公众号链接
星球链接















 2154
2154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









