







声明
本文仅供学习参考,请勿用于其他途径,违者后果自负!
前言
参考:https://blog.csdn.net/m0_51159233/article/details/123910391、
https://www.bilibili.com/video/BV1eK411R7m4/?spm_id_from=333.788.top_right_bar_window_history.content.click&vd_source=10c884d9220b52b21952d6916facf586
目标网站:aHR0cHM6Ly9tb2JpbGUueWFuZ2tlZHVvLmNvbS8=
目标参数: anti_content
参数分析
打开F12开始抓包,我们将首页中的推荐商品一直向下翻,直到找到如下接口,里面就有我们需要逆向的参数anti_content
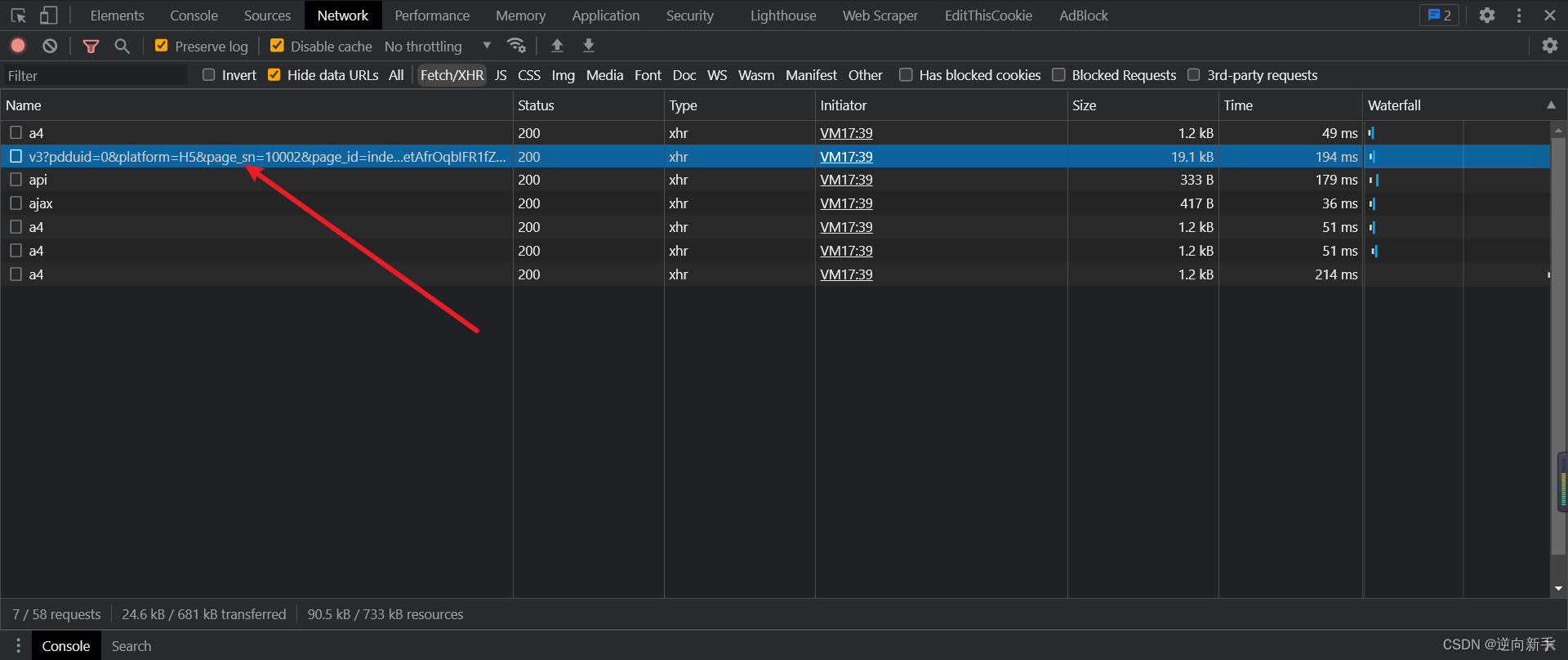

确定过目标后,直接搜索。
逆向分析
结果不多直接点进去,搜索得出五个结果。因为不确定哪个是需要的,都打上断点,然后继续往下翻页面。
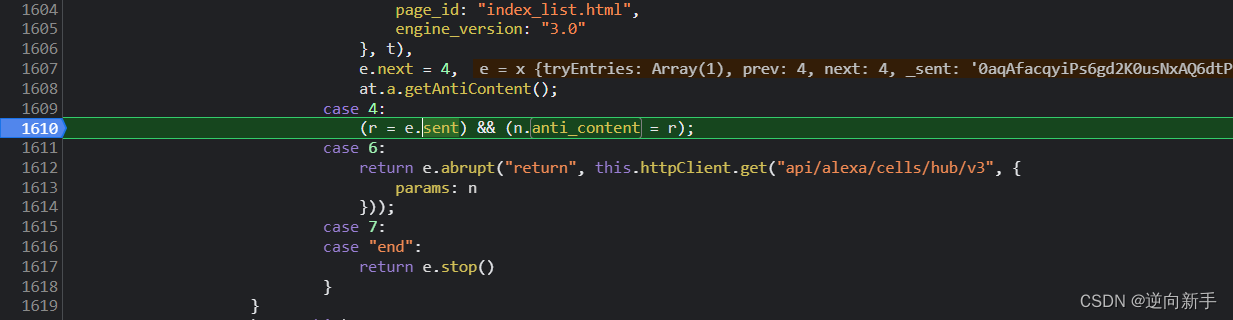
在这里断下来了,为了不必要的干扰可以把其他的断点都清除掉。
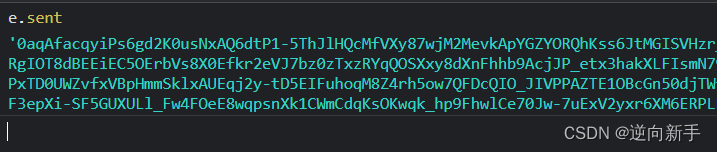
r = e.sent。而e.sent就是anti_content,通过分析这一行代码可以看到将e.sent赋值给r,然后又将r赋值给anti_content,这样就得出了结果。
在寻找e.sent的生成的时候发现了at.a.getAntiContent这个函数,通过函数名就知道这个函数生成了我们需要的参数,在这里打下断点,重新断下。
F11单步跟栈。
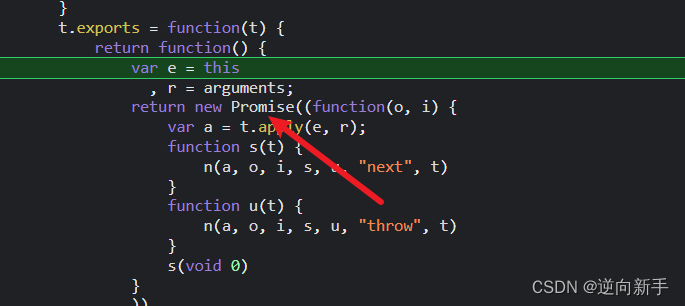
这里用了较多的promise,所以跟栈的时候需要耐心一些。
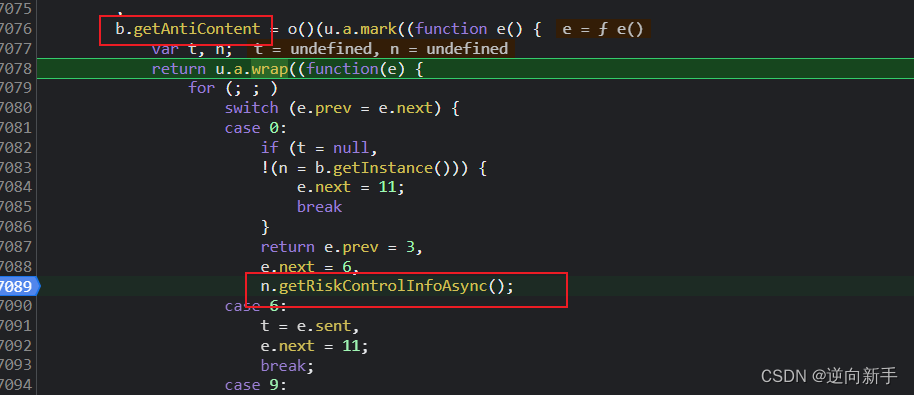
在跟到这一步的时候发现给了很多明文的提示,在关键的地方打下断点继续跟进。
在漫长的跟栈过程中,直到这个地方才得到我们所需要的结果。

需要的部分简化出来如下:
e[n(558, "[k*i")](Le)
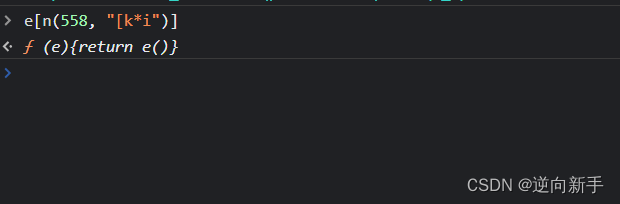
通过console输出发现返回的是参数函数,也就是Le()函数。
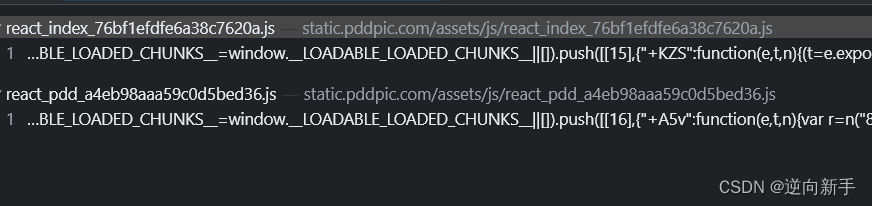
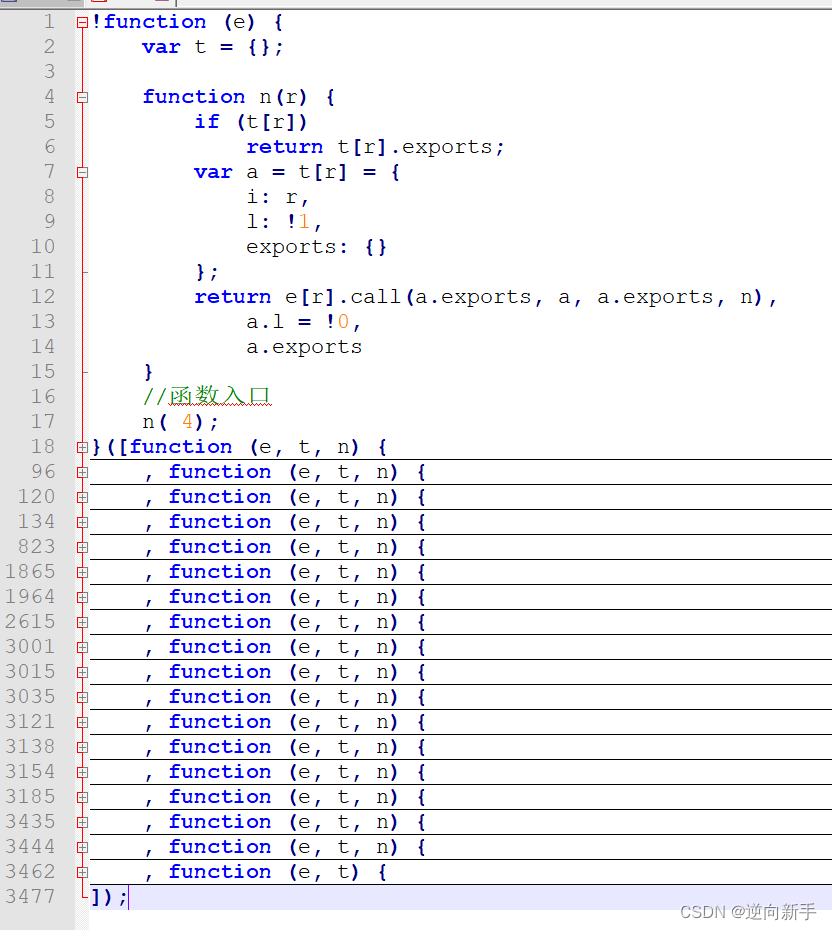
往上翻了翻发现是一个webpak打包的js文件,
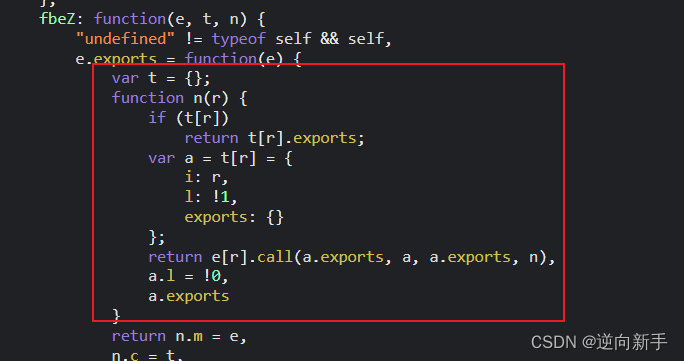
扣代码
对于webpack就是那几大件:分发器、所需模块、导出函数。
把这几个东西给搞好,基本就成了。
将整个文件全部拷贝到本地,找到所需的代码,适当的修改。
整理完后结果:
想要使用也很简单,设置一个全局变量作为导出函数。
window.xxx = Le
前文得知Le最终返回的结果就是anti_content,所以这样设置一个全局变量然后调用就可以了。
运行之后发现抱错。
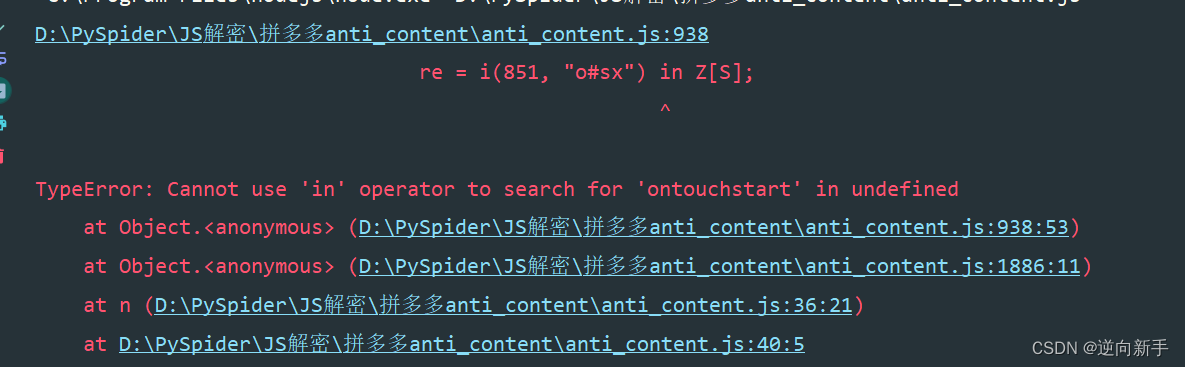
通过搜索得知这是一个浏览器的属性
 这里贴上查询链接:
这里贴上查询链接:https://developer.mozilla.org/zh-CN/docs/Web/API/
遇到本地执行有问题时,将代码放到浏览器中运行一下。这样做的好处时浏览器拥有所需的全部环境,遇到环境问题直接降维打击。

可以看到浏览器没有任何问题,我们运行代码希望是本地能够直接运行而不是一直挂一个浏览器。所以剩下的内容是直接补环境。
有两种方式可以完成:
1、使用jsDom;
2、手动补环境;
使用jsDom之前要先安装。
npm install jsdom
然后在文件开头放上如下代码:
const jsdom = require('jsdom')
const {JSDOM} = jsdom
const dom = new JSDOM('<!DOCTYPE html><p>hello world</p>>');
window = dom.window
document = window.document
XMLHttpRequest = window.XMLHttpRequest
这样就完成了,非常简单快捷。第二种就是手动补,缺什么补什么,更加考验耐心。
总结
1、大量使用promise,增加了调试难度;
2、使用了webpack将代码拆分;
3、检测了浏览器指纹(属性)















 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









