






 本文解析了LeetCode上WordBreak II题目,介绍了两种解决方案:动态规划和回溯法,并对比了两者的优缺点。通过具体实例展示了如何避免重复计算,以及在特定情况下哪种方法更高效。
本文解析了LeetCode上WordBreak II题目,介绍了两种解决方案:动态规划和回溯法,并对比了两者的优缺点。通过具体实例展示了如何避免重复计算,以及在特定情况下哪种方法更高效。
Leetcode 140. Word Break II
@(LeetCode)[LeetCode | Algorithm | DP | Backtracking | DFS]
Given a non-empty string s and a dictionary wordDict containing a list of non-empty words, add spaces in s to construct a sentence where each word is a valid dictionary word. Return all such possible sentences.
Note:
The same word in the dictionary may be reused multiple times in the segmentation. You may assume the dictionary does not contain duplicate words.
Example 1:
Input:
s = "catsanddog"
wordDict = ["cat", "cats", "and", "sand", "dog"]
Output:
[
"cats and dog",
"cat sand dog"
]The original problem is HERE.
Solution #1 DP
Time:
O(2n)
O
(
2
n
)
Space:
O(2n)
O
(
2
n
)
一种方法是用动态规划(DP),思路很简单。dp[i]表示从起始(第0位)到第i位之前字符串所能组成的句子。dp[i]可以表示为:
如下图所示,为一个DP构造的示意图
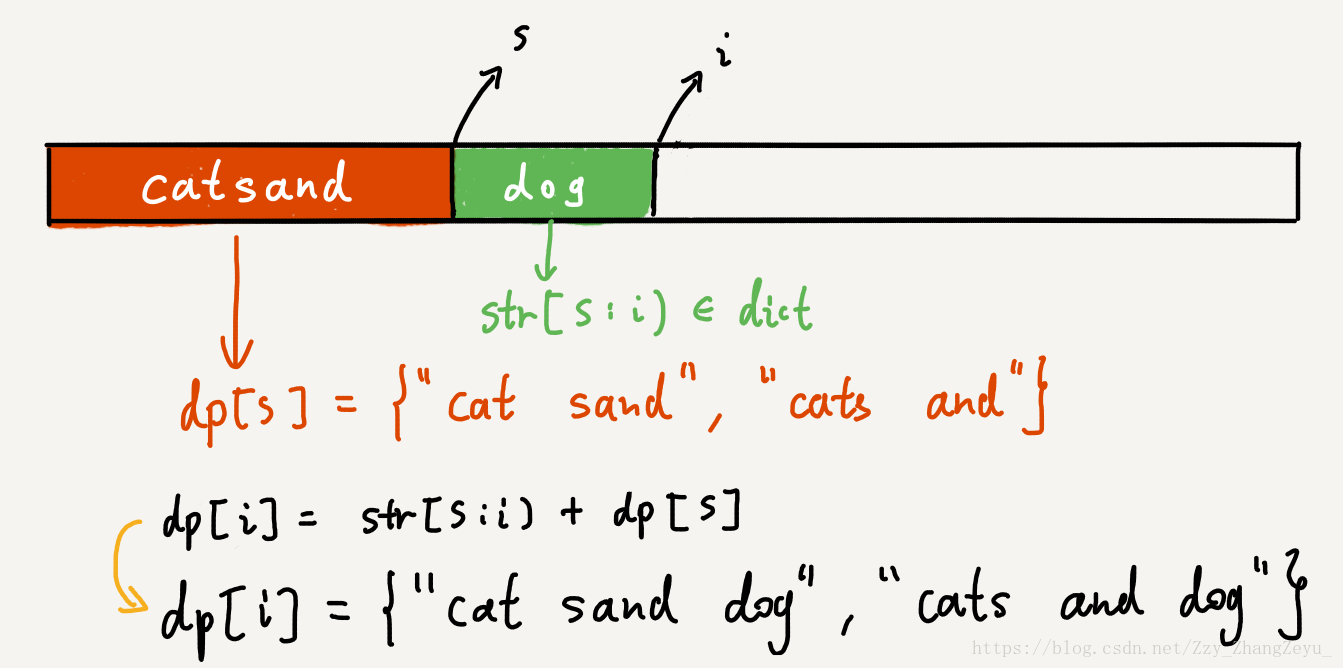
利用DP可以避免重复搜索之前位置所能构造的句子。
注意:算法实现中加入了一个breakable函数,该函数用于判断该字符串能否被break。为什么要加入这个函数,在本文的最后一节会有说明。
class Solution {
public:
vector<string> wordBreak(string s, vector<string>& wordDict) {
vector<vector<string> > dp(s.length() + 1, vector<string>());
dp[0].push_back(string());
unordered_set<string> dict;
for(string str : wordDict)
dict.insert(str);
if( !breakable(s, dict) )
return dp.back();
for(int i = 1; i <= s.length(); i++){
for(int j = 0; j < i; j++){
string ss = s.substr(j, i - j);
if(dp[j].size() > 0 && dict.find(ss) != dict.end()){
for(string prefix : dp[j]){
dp[i].push_back(prefix + (prefix == "" ? "" : " ") + ss);
}
}
}
}
return dp.back();
}
bool breakable(string s, unordered_set<string> &dict){
vector<bool> dp(s.length() + 1, false);
dp[0] = true;
for(int i = 1; i <= s.length(); i++){
for(int j = 0; j < i; j++){
string ss = s.substr(j, i - j);
if(dp[j] && dict.find(ss) != dict.end()){
dp[i] = true;
break;
}
}
}
return dp.back();
}
};Solution #2 DFS (Backtracking) with memory
Time:
O(2n)
O
(
2
n
)
Space:
O(2n)
O
(
2
n
)
另一种思路是Backtracking。如果[start, end]之间组成的单词在wordDict中,就递归调用dfs(end + 1, ...)来查找以end + 1开头所能组成的句子。再将[start, end]和dfs(end + 1, ...)返回的句子拼接起来,组成完成的句子。(注:若dfs返回为空,则表明不能组成句子)。
一个关键的地方就是使用memory来避免重复计算。比如下图中,黄色高亮部分的dog,可以直接根据之前相同位置的搜索结果来获得。其中memo[7],表示以index为7的位置为起始所能组成的句子。
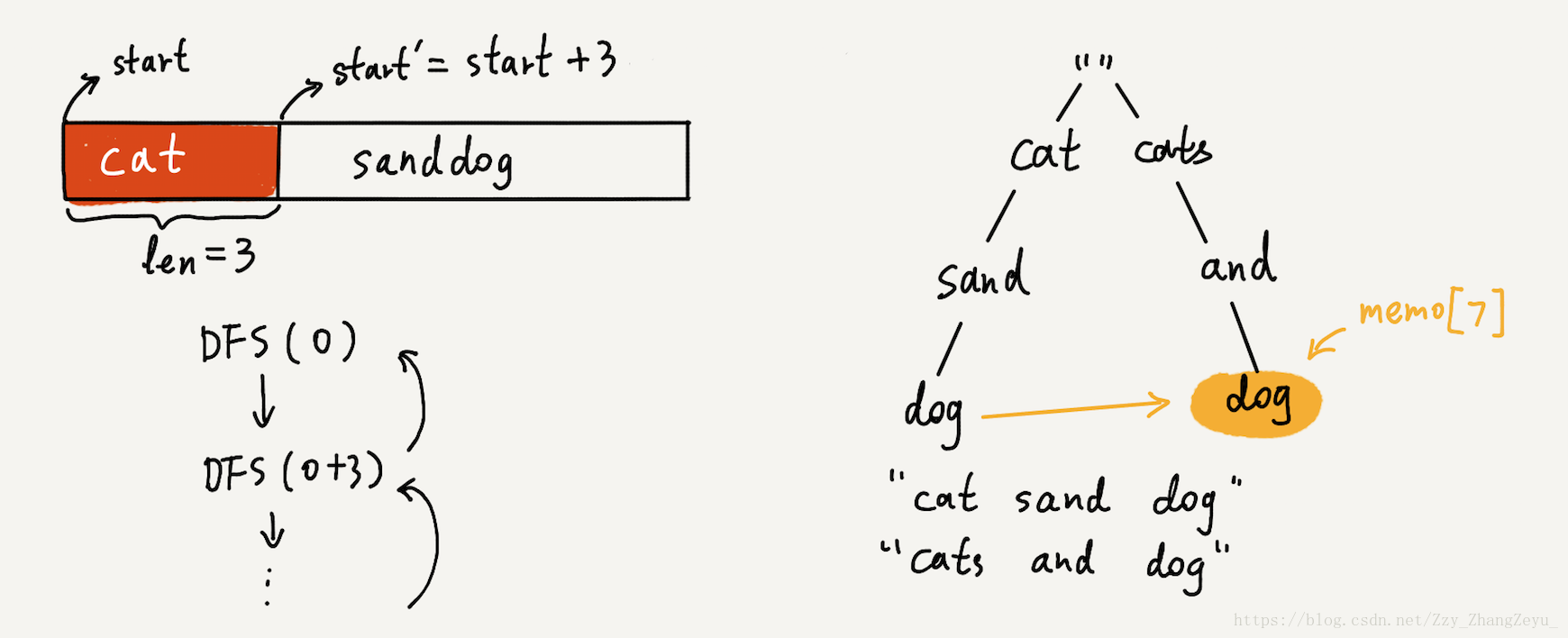
class Solution {
public:
vector<string> wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> dict;
for(string str : wordDict)
dict.insert(str);
vector<string >ret = dfs(s, 0, dict);
return ret;
}
vector<string> dfs(string &s, int start, unordered_set<string> &dict){
if(memo.find(start) != memo.end())
return memo[start];
if(start == s.length()){
cout << "create memo: " << start << endl;
memo[start] = vector<string>(1, string());
return memo[start];
}
vector<string> ret;
for(int i = start; i < s.length(); i++){
string ss = s.substr(start, i - start + 1);
if(dict.find(ss) != dict.end()){
vector<string> suffixes = dfs(s, i + 1, dict);
for(string suffix : suffixes)
ret.push_back(ss + (suffix == "" ? "" : " ") + suffix);
}
}
cout << "create memo: " << start << endl;
memo[start] = ret;
return ret;
}
private:
map<int, vector<string> > memo;
};Conclusion
虽然DP和Backtracking的时间复杂度都是一样的,但是Backtracking更好一点。原因在于,当整个句子无法被构建时,Backtracking不会浪费大量的计算资源来计算前缀所能组成的句子,直接会判定该句子无法被组成。
举个例子:
input:
"aaaaaaaaaaaaabaaaaaaaaaaaaa"
["a", "aa", "aaa", "aaaa", "aaaaa", "aaaaaa", "aaaaaaa", "aaaaaaaa", "aaaaaaaaa", "aaaaaaaaaa", "aaaaaaaaaaa", "aaaaaaaaaaaa", "aaaaaaaaaaaaa"]
Output:
[]字符串aaaaaaaaaaaaabaaaaaaaaaaaaa是不能被break的。
Backtracking通过DFS很快就能判断该句子不能被break。
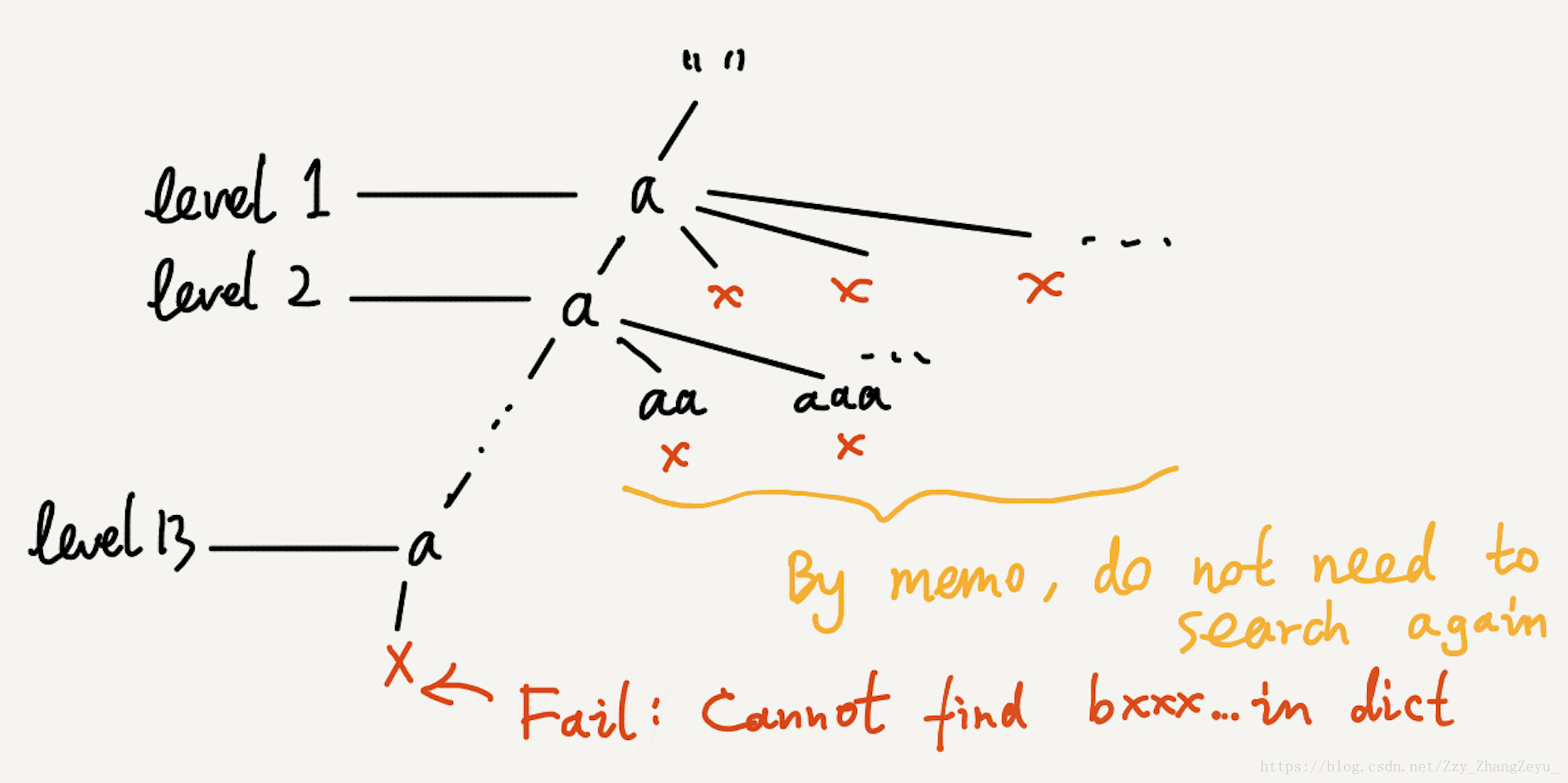
但是DP则不然,如果使用DP会浪费大量时间用于计算前缀aaaaaaaaaaaaa所能划分出的句子(这个前缀能划分出
212
2
12
个句子,会消耗大量的时间和空间),直到扫描到最后一位的时候,才会发现原字符串无法被break。

















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









