







tips
- 统计代码行数的工具:cloc(Count Lines of Code) 安装教程
- 待续…
《Go语言设计与实现》
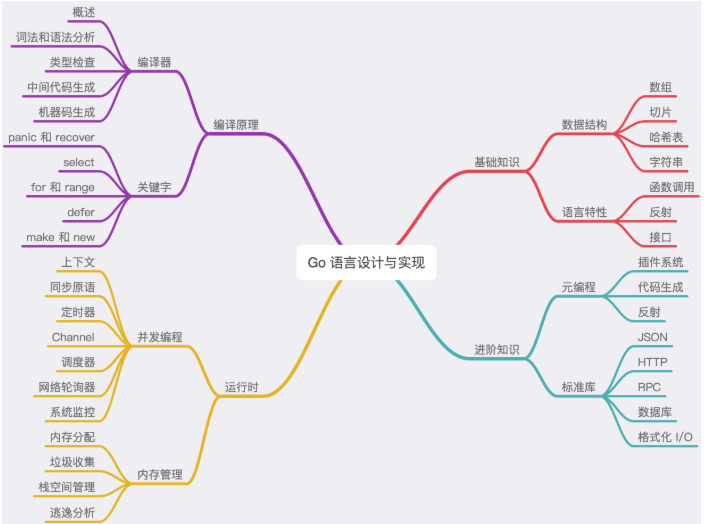
一、编译原理
- 理解编译器的词法与语法解析、类型检查、中间代码生成以及机器码生成过程
- 想要了解Go语言的实现原理,理解它的编译过程就是一个没有办法绕开的事情
- link
1. 调试源代码
- 修改源代码,然后/src/make.sh脚本会编译Go语言的二进制、工具链以及标准库和命令并将源代码和编译好的二进制文件移动到对应的位置上
- 编译好的二进制会存储在$GOPATH/src/github.com/golang/go/bin目录中。需要用绝对路径来访问和使用它
- $GOPATH/src/github.com/golang/go/bin/go run main.go
- 如果直接使用go run main.go,可能会使用包管理器安装的go二进制,得不到期望的结果
- 中间代码
- Go 语言编译器的中间代码具有静态单赋值(Static Single Assignment、SSA)的特性
- 掌握调试和自定义Go语言二进制的方法,可以帮助我们快速验证对Go语言内部实现的猜想
- 通过最简单粗暴的println函数可以调试Go语言的源码和标准库
- 如果想要研究源代码的详细编译优化过程,可以使用SSA中间代码深入研究Go语言的中间代码以及编译优化的方式
- 想了解Go语言的实现原理,阅读源代码是绕不开的过程
2. 将go语言源代码编译成汇编语言
go build -gcflags -S main.go
3. 编译过程涉及的术语和专业知识
-
抽象语法树 (Abstract Syntax Tree、AST)
- 是源代码语法结构的一种抽象表示
- 用树状的方法表示编程语言的语法结构
- 以表达式 2 * 3 + 7 为例,编译器的语法分析阶段会生成如下图所示的抽象语法树
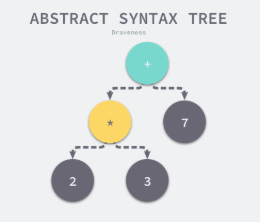
- 作为编译器常用的数据结构,抽象语法树抹去了源代码中不重要的一些字符 - 空格、分号或者括号等等
- 编译器在执行完语法分析之后会输出一个抽象语法树,这个抽象语法树会辅助编译器进行语义分析,我们可以用它来确定语法正确的程序是否存在一些类型不匹配的问题
-
静态单赋值(Static Single Assignment、SSA)
- 是中间代码的特性
- 如果中间代码具有静态单赋值的特性,那么每个变量就只会被赋值一次
x := 1 --> x_1 x := 2 --> x_2 y := x --> y_1 = x_2 - y_1和x_1是没有任何关系的,所以在机器码生成时就可以省去x := 1的赋值,减少需要执行的指令优化这段代码
-
指令集
- 本地开发环境编译和运行正常的代码,在生产环境却无法正常工作,背后的原因有多种。不同机器使用的不同指令集可能是其中之一
- 复杂指令集(CISC):通过增加指令的类型减少需要执行的指令数
- 精简指令集(RISC):通过使用更少的指令类型完成目标的计算任务
4. 编译原理
源代码位置:src/cmd/compile
- 编译器的前端:承担词法分析、语法分析、类型检查和中间代码生成几部分工作
- 编译器的后端:负责目标代码的生成和优化。也就是将中间代码翻译成目标机器能够运行的二进制机器码
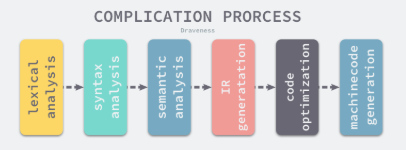
- 词法分析
- 所有的编译过程都是从解析代码的源文件开始的
- 词法分析作用就是解析源代码文件,它将文件中的字符串序列转换成Token序列,方面后面的处理和解析
- 一般会把执行词法分析的程序称为词法解析器(lexer)
- 词法分析会返回一个不包含空格、换行等字符的Token序列
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
- 语法分析
- 语法分析的输入是词法分析器输出的Token序列
- 语法分析器会按照顺序解析Token序列,该过程会将词法分析生成的Token按照编程语言定义好的文法(Grammar)自下而上或自上而下的规约,每一个Go的源代码文件最终会被归纳成一个SourceFile结构
- 语法分析会把 Token 序列转换成有意义的结构体,即语法树
"json.go": SourceFile { PackageName: "json", ImportDecl: []Import{ "io", }, TopLevelDecl: ... } - Token 到抽象语法树(AST)的转换过程会用到语法解析器,每一个 AST 都对应着一个单独的 Go 语言文件
- 抽象语法树中包括当前文件属于的包名、定义的常量、结构体和函数等
- 语法解析的过程中发生的任何语法错误都会被语法解析器发现并将消息打印到标准输出上,整个编译过程也会随着错误的出现而被中止
- 类型检查
- 当拿到一组文件的抽象语法树之后,Go 语言的编译器会对语法树中定义和使用的类型进行检查
- 类型检查会按照以下的顺序分别验证和处理不同类型的节点
1. 常量、类型和函数名及类型; 2. 变量的赋值和初始化; 3. 函数和闭包的主体; 4. 哈希键值对的类型; 5. 导入函数体; 6. 外部的声明; - 通过对整棵抽象语法树的遍历,我们在每个节点上都会对当前子树的类型进行验证,以保证节点不存在类型错误
- 所有的类型错误和不匹配都会在这一个阶段被暴露出来,其中包括:结构体对接口的实现
- 类型检查阶段不止会对节点的类型进行验证,还会展开和改写一些内建的函数,例如 make 关键字在这个阶段会根据子树的结构被替换成 runtime.makeslice 或者 runtime.makechan 等函数
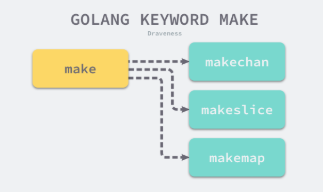
- Go 语言的很多关键字都依赖类型检查期间的展开和改写
- 中间代码生成
- 当我们将源文件转换成了抽象语法树、对整棵树的语法进行解析并进行类型检查之后,就可以认为当前文件中的代码不存在语法错误和类型错误的问题了
- Go 语言的编译器就会将输入的抽象语法树转换成中间代码
- 编译器会编译整个Go语言项目中的全部函数,这些函数会在一个编译队列中等待几个Goroutine的消费,并发执行的 Goroutine 会将所有函数对应的抽象语法树转换成中间代码
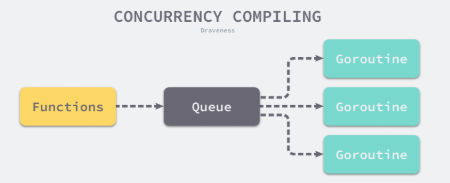
- 机器码生成
- 不同类型的 CPU 分别使用了不同的包生成机器码
- 根据目标的 CPU 架构生成机器码
- 编译
- 得到抽象语法树后会分九个阶段对抽象语法树进行更新和编译
- 抽象语法树会经历类型检查、SSA 中间代码生成以及机器码生成三个阶段
1. 检查常量、类型和函数的类型; 2. 处理变量的赋值; 3. 对函数的主体进行类型检查; 4. 决定如何捕获变量; 5. 检查内联函数的类型; 6. 进行逃逸分析; 7. 将闭包的主体转换成引用的捕获变量; 8. 编译顶层函数; 9. 检查外部依赖的声明;
5. 词法分析与语法分析
- 从Go语言的源代码出发详细分析Go语言的编译器是如何在底层实现词法和语法解析功能
- 词法分析器: cmd/compile/internal/syntax.scanner
- 语法分析器: cmd/compile/internal/syntax.parser
- 如何模拟人理解源代码的方式构建一个能够分析编程语言代码的程序
- 源代码在计算机眼中其实是一团乱码,一个由字符组成的、无法被理解的字符串,所有的字符在计算机看来并没有区别
- 为了理解这些字符,需要做的第一件事就是将字符串分组,降低理解字符串的成本,简化源代码的分析过程
- 词法分析就是将字符序列转换成标记Token序列的过程
- Go语言中的Token类型,可以将语言中的元素分成几个不同的类别,分别是名称和字面量、操作符、分隔符和关键字
- 词法分析中的文法组成
1. N有限个非终结符的集合; 2. Σ有限个终结符的集合; 3. P有限个生产规则12的集合; 4. S非终结符集合中唯一的开始符号 - 文法分析方法
- 自顶向下分析
- 自底向上分析
6. 类型检查
- 强类型的编程语言在编译期间会有更严格的类型限制,也就是编译器会在编译期间发现变量赋值、返回值和函数调用时的类型错误
- 弱类型的编程语言在出现类型错误时可能会在运行时进行隐式的类型转换,在类型转换时可能会造成运行错误
- Go 语言的编译器不仅使用静态类型检查来保证程序运行的类型安全,还会在编程期间引入类型信息,让工程师能够使用反射来判断参数和变量的类型
- make和new这些内置函数其实并不会直接对应某些函数的实现,它们会在编译期间被转换成真正存在的其他函数
7. 中间代码生成
- 中间代码的生成过程是从 AST 抽象语法树到 SSA 中间代码的转换过程
- 在这期间会对语法树中的关键字再进行改写,改写后的语法树会经过多轮处理转变成最后的 SSA 中间代码
- 很多 Go 语言中的关键字和内置函数都是在这个阶段被转换成运行时包中方法的
8. 机器码生成
- 机器码的生成过程其实是对 SSA 中间代码的降级(lower)过程,在 SSA 中间代码降级的过程中,编译器将一些值重写成了目标 CPU 架构的特定值,降级的过程处理了所有机器特定的重写规则并对代码进行了一定程度的优化
- 如果一个编程语言想要在所有的机器上运行,它就可以将中间代码转换成使用不同指令集架构的机器码,这可比为不同硬件单独移植要简单的太多了
- 只需对汇编语言转机器指令的过程有所了解,遇到问题能快速定位即可
二、基础知识
理解数组、切片、哈希表和字符串等数据结构的内部表示以及常见操作的原理
理解make、new、defer、select、for和range等关键字的实现
理解Go语言中的函数、方法以及反射等语言特性
1. 数组
- 数组的访问和赋值需要同时依赖编译器和运行时
- 它的大多数操作在编译期间都会转换成直接读写内存
- 在中间代码生成期间,编译器还会插入运行时方法runtime.panicIndex调用防止发生越界错误
2. 切片
- 切片,即动态数组,其长度不固定,可以向切片中追加元素,它会在容量不足时自动扩容
- 整块拷贝内存仍然会占用非常多的资源,在大切片上执行拷贝操作时一定要注意对性能的影响
3. 哈希表
- 实现哈希表的关键点在于哈希函数的选择,哈希函数的选择在很大程度上能够决定哈希表的读写性能
- Go语言使用拉链法来解决哈希碰撞的问题实现了哈希表
- 它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法
4. 字符串
- 切片在go语言的运行时表示与字符串高度相似,所以常说字符串是一个只读的切片类型
- 字符串上的写入操作都是通过拷贝实现的
5. 函数
- go通过栈传递函数的参数和返回值
- 通过堆栈传递参数,入栈的顺序是从右到左,而参数的计算是从左到右
- 函数返回值通过堆栈传递并由调用者预先分配内存空间
- 调用函数时都是传值,接收方会对入参进行复制再计算
6. 接口
- 接口的类型转换
- 类型断言以及动态派发机制
- 函数调用时发生的隐式类型转换
7. 反射
- 使用反射来动态修改变量
- 判断类型是否实现了某些接口以及动态调用方法等功能
8. for和range
- Go语言遍历数组和切片时会复用变量
- 哈希表的随机遍历原理以及底层的一些优化
9. select
- select结构的执行过程与实现原理
- select关键字是Go语言特有的控制结构,它的实现原理比较复杂,需要编译器和运行时函数的通力合作
10. defer
- defer关键字的实现主要依靠编译器和运行时的协作
11. panic和recover
- 分析程序的崩溃和恢复过程比较棘手
- 分析的过程涉及了很多语言底层的知识,源代码阅读起来比较晦涩
- 充斥着反常规的控制流程,通过程序计数器来回跳转
12. make和new
- make关键字的作用是创建切片、哈希表和channel等内置的数据结构
- new的作用是为类型申请一片内存空间,并返回指向这片内存的指针
三、运行时
理解运行时中的调度器、网络轮询器、内存分配器、垃圾收集器的实现原理
1. 并发编程 - 上下文Context
- context.Context的主要作用还是在多个Goroutine组成的树中同步取消信号以减少对资源的消耗和占用
2. 并发编程 - 同步原语与锁
- 并发编程的原语能够帮助我们更好地利用Go语言的特性构建高吞吐量、低时延的服务、解决并发带来的问题
- 在设计同步原语时,不仅要考虑API接口的易用、解决并发编程中可能遇到的线程竞争问题,还需要对尾延时进行优化保证公平性
- 理解同步原语是理解并发编程无法跨越的一个步骤
3. 并发编程 - 定时器
- 计时器在并发编程中起到了非常重要的作用
4. 并发编程 - Channel
- Channel是Go语言提供强大并发能力的原因之一
- Channel的设计原理、数据结构以及发送数据、接收数据和关闭Channel的基本操作,帮助理解Channel的工作原理
5. 并发编程 - 调度器
- Goroutine和调度器是Go语言能够高效地处理任务并且最大化利用资源的基础
- Go语言用于处理并发任务的G-M-P模型
6. 并发编程 - 网络轮询器
- 所有的文件I/O、网络I/O和计时器都是由网络轮询器管理的,它是Go语言运行时重要的组成部分
7. 并发编程 - 系统监控
- 运行时通过系统监控来触发线程的抢占、网络的轮询和垃圾回收,保证Go语言运行时的可用性
- 系统监控能够很好地解决尾延迟的问题,减少调度器调度Goroutine的饥饿问题并保证计时器在尽可能准确的时间触发
8. 内存管理 - 内存分配器
- 内存分配是Go语言运行时内存管理的核心逻辑
9. 内存管理 - 垃圾收集器
- Go语言垃圾收集器的实现非常复杂
- 垃圾收集是一门非常古老的技术,它的执行速度和利用率很大程度上决定了程序的运行速度
- Go语言为了实现高性能的并发垃圾收集器,使用三色抽象、并发增量回收、混合写屏障、调步算法以及用户程序协助等机制将垃圾收集的暂停时间优化至毫秒级以下
10. 内存管理 - 栈内存管理
- 栈内存是应用程序中重要的内存空间
- 它能够支持本地的局部变量和函数调用
- 栈空间中的变量会与栈一同创建和销毁,这部分内存空间不需要工程师过多的干预和管理
四、进阶知识
理解常见并发原语Mutex、WaitGroup以及扩展原语的使用和原理
理解HTTP、RPC、JSON等标准库的设计与原理
1. 插件系统
- 插件系统利用了操作系统的动态库实现模块化的设计
- 目前的插件系统也仅支持Linux、Darwin和FreeBSD,Windows上没办法使用
- 插件系统的实现基于一些黑魔法,所以跨平台的编译也会遇到一些比较奇葩的问题
2. 代码生成
- Go语言的标准库暴露了编译器的很多能力,其中包含词法分析和语法分析,可以直接利用这些现成的解析器编译Go语言的源文件并获得抽象语法树
- 有了识别源文件结构的能力,就可以根据源文件对应的抽象语法树自由地生成更多的代码
- 使用元编程技术来减少代码重复、提高工作效率
五、标准库
1. JSON
- Json本身是一种树形的数据结构,无论序列化还是反序列化,都会遵循自顶向下的编码和解码过程,使用递归的方式处理JSON对象
2. HTTP
- Go语言的HTTP标准库提供了非常丰富的功能
3. 数据库
- database/sql是一个抽象层的经典例子
参考
- https://draven.co/golang/

















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









