







论文链接:https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/41159.pdf
概要
预测广告点击率(CTR)是一个巨大的规模学习问题,是在线广告业数十亿美元的核心问题。 我们从最近的实验中选择出来一个案例,这种方法的研究和主题设置都已部署的CTR预测系统。 这些包括基于FTRL-Proximal在线学习算法的传统监督学习环境的改进(具有出色的稀疏性和收敛性)以及每个坐标学习率的使用
我们还探讨了一些挑战,这些挑战可能首先出现真实世界的 ctr 系统中。 这些包括节省内存的有用技巧,评估和可视化性能的方法,为提供预测概率的置信度估计提出来的实用方法、校准方法和自动管理功能的方法。 最后,我们还详细介绍了几个方向,尽管文献中这些方面的结果很有希望,但这对我们并没有益处。 本文的目标是为了突出这个工业环境中理论进步与实际工程之间的密切关系,并展示在复杂中应用传统机器学习方法时出现的挑战深度动态系统。
1:介绍
在线广告是一个数十亿美元的行业,并且已成为机器学习行业的重大成功案例之一。 赞助搜索广告,内容相关广告,展示广告和实时出价拍卖,所有这些都严重依赖于模型预测的能力准确、快速性,可靠地实现广告点击率[28,15,33,1,16]。 这个问题也推动了解决甚至十年前的规模问题几乎是不可思议的。 典型的工业模型可以提供每天数十亿事件的预测,这具有一个相应大的特征空间,然后学习由此产生的大量数据。
在本文中,我们提出了一系列案例研究,这些研究来自于最近在Google用于预测广告点击率的部署系统的实验,这些广告是来自于提供赞助的搜索广告。 因为这个问题现在研究得很好,我们选择专注于一系列主题,在一个工作系统中虽然受到较少关注但同样重要。 因此,我们探索内存节约问题,性能分析,预测准确性,校准和特征管理,我们再具有相同的准确率上给出了设计有效学习算法的问题。 本文的目的是给出读者了解真实中出现的挑战深度工业问题,以及分享技巧和见解,这可能适用于其他大规模问题领域。
2.简要系统概述
当用户进行搜索q时,一组初始候选者广告根据广告客户查询的q匹配这个关键字。 算法机制决定是否这些广告会向用户显示,显示的顺序是什么,以及用户在点击广告时广告主要支付的价格。除了广告客户的出价之外,还有就是广告的 P(click | q,a)也是很重要的
我们系统中使用的特征包含各种来源,包括查询,广告创意本身的文本以及各种与广告相关的元数据。 数据倾向于非常稀疏,每个示例通常只有一小部分非零特征值。
正则化逻辑回归等方法很适合这种问题设定。 有必要做预测每天数十亿次,并迅速在观察到新点击和非点击时更新模型。当然,这个数据速率意味着训练数据集巨大。 数据由基于的流媒体服务提供Photon系统 - 参见[2]进行全面讨论。
因为近年来大规模的学习已经得到了很好的研究(例如参见[3]),我们在本文中没有花费大量篇幅来详细描述我们的系统架构。 但是,我们将重心放到训练方法,方法与由谷歌大脑团队[8]描述的Downpour SGD方法相似,与众不同的是我们训练单层模型而不是多层深层网络。 这使我们能够在我们所知的其他地方,得到显着的处理比报告的更大的数据集和更大的模型,有数十亿个系数。 因为训练模型需要数据被复制到许多数据中心服务(见图1),我们更关心在预估服务时的稀疏性,而不是在训练期间。
3.在线学习和稀疏性
对于大规模学习,广义线性模型(例如逻辑回归)的在线算法有很多好处。 虽然特征向量x可能有数十亿个维度,但通常每个实例都只有数百个非零值。 这可以通过磁盘或以上的流示例,实现高效的训练来处理大型数据集网络[3],因为每个训练样例只需要被认为是一次。
为了准确地呈现算法,我们需要建立一些符号。 我们表示像gt∈R这样的向量的时候,用粗体字表示,其中t索引当前的训练实例。在gt中的第i个数字我们表示为gt,i。 我们也用压缩求和符号
![]()
如果我们希望使用逻辑回归建模我们的问题,我们可以使用以下在线框架。 在t时刻,我们被要求预测特征描述的实例向量 xt∈Rd;
给定模型参数 wt,我们预测的概率 pt = wt*xt,然后再过下 sigmoid 函数,sigmoid 函数可以表达为 σ(a) = 1/(1 + exp(−a)),然后我们拿到真实的 label y(t) 属于{0,1},并且计算 logloss,用下面的函数
`t(wt) = −yt log pt − (1 − yt) log(1 − pt)
上面是负的log似然函数,yt是真实label,p是预测值。它的梯度可以表示为 ![]()
这个梯度也正是我们要优化的目标
在线梯度下降法(OGD)对于这些问题已经被证明非常有效,产生了很好的预测精度,并且是最低的计算资源。 然而,在实践中,另一个关键考虑因素是最终模型的大小; 由于模型可以稀疏地存储,因此w中的非零系数的数量是决定内存使用的因素
不幸的是,OGD在生产稀疏模型方面并不是特别有效。实际上,只需将L1惩罚的次级梯度添加到损失的梯度(Ow`t(w)),基本上永远不会产生精确的系数零。更复杂的方法,如FOBOS和截断梯度确实成功引入了稀疏性[11,20]。与FOBOS相比,正则化双平均(RDA)算法与稀疏权衡相比产生更高的准确度[32]。但是,我们观察到了梯度下降样式方法可以产生比RDA更好的准确性,在我们的数据集上[24]。那么问题是,我们可以得到两者RDA提供的稀疏性和提高的准确性OGD?答案是肯定的,使用“跟随(近端)正则化领导者”算法或FTRL-Proximal。如果没有正则化,该算法与标准在线梯度下降相同,但因为它使用模型系数w,L1的替代惰性表示正规化可以更有效地实施。
FTRL-Proximal算法先前已被框架化以一种方便理论分析的方式[24]。在这里,我们专注于描述实际的实现。给定一系列梯度gt∈Rd,OGD执行更新
![]()
其中的 ηt 是一个递减的学习速率,例如设置 ηt = ![]()
ftrl 用的损失函数是
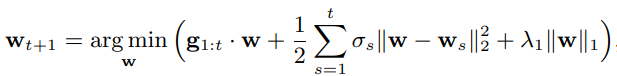
我们把公式里面的 σs 定义为学习速率,![]() ,从表面上看,这些更新看起来很不同,但实际上当我们取λ1= 0时,它们会产生相同的系数向量序列。 然而λ1> 0的FTRL-Proximal更新中,降低稀疏性(见下面的实验结果)方面表现非常出色
,从表面上看,这些更新看起来很不同,但实际上当我们取λ1= 0时,它们会产生相同的系数向量序列。 然而λ1> 0的FTRL-Proximal更新中,降低稀疏性(见下面的实验结果)方面表现非常出色
在快速检查时,人们可能会认为FTRL-Proximal更新比梯度下降更难实现,或需要存储所有过去的系数。 事实上,每个系数只需要存储一个数字,因为我们会把更新函数重写成
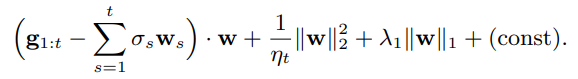
因此,如果我们存储 ![]() ,在第t轮的开始,我们会更新参数
,在第t轮的开始,我们会更新参数
zt = zt−1 + gt +![]() ,并且将 wt+1 也用一个可根据 zt,i 动态更新的参数
,并且将 wt+1 也用一个可根据 zt,i 动态更新的参数
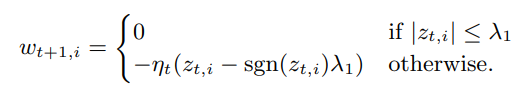
因此,ftrl就只在内存中存储 z ∈ R d,OGD存储 w ∈ R d,算法1采用这种方法,但是还增加了每坐标学习率计划(接下来讨论),并支持强度λ2的L2正则化。 或者,我们可以存储-ηt * zt而不是直接存储zt;然后,当λ1= 0时,我们正好存储正常的梯度下降系数。 注意,当ηt是常数值时,η和λ1= 0,很容易看到在线梯度下降的等价,因为我们有 ![]() ,这正是梯度下降起到的作用
,这正是梯度下降起到的作用

表1:FTRL结果,显示非零系数值的相对数量、AucLoss(1-AUC)对于竞争方法(较小的数字对两者都更好)。 总的来说,FTRL提供了更好的稀疏性准确度相同或更高(损害0.6%)对我们的应用来说意义重大)。 RDA和FOBOS在较小的原型上与FTRL进行了比较具有数百万个示例的数据集,而OGD-Count在全尺寸数据集上与FTRL进行比较。
实验结果: 在较早的实验中,我们的数据的原型版本较小,McMahan [24]表明了这一点:具有L1正则化的FTRL-Proximal在产生的模型尺寸与准确性权衡方面明显优于RDA和FOBOS; 这些先前的结果总结在表1第2行和第3行中。
在许多情况下,简单的启发式工作几乎也可以作为更有原则的方法,但这不是其中之一案例。 我们的“稻草人算法”,OGD-Count简单地保持了一个特征的出现次数,直到该计数超过阈值k,系数才固定在零,但计数通过k后,在线梯度下降(没有任何L1正则化)照常进行。 去测试FTRL-Proximal反对这个更简单的启发式,我们运行了非常大的数据集。 我们调整k以产生相同的准确度到FTRL-Proximal; 使用更大的k导致更糟糕的AucLoss。结果在表1第4行中给出。
总体而言,这些结果表明FTRL-Proximal具有显着改善的稀疏性,具有相同或更好的预测准确性
3.1每坐标学习率
在线梯度下降的标准理论表明,使用一个全局的学习率表,![]() ,对每一个坐标来说都是很常见的。一个简单的思想实验表明这可能并不理想:假设我们使用逻辑回归估计10个硬币的正方面概率 Pr(head | coini)。每一轮t,一个硬币我被翻转,我们看到一个特征向量 x∈R10 表示xi = 1且xj = 0表示j ! = i。 从而,我们基本上解决了10个独立的逻辑回归问题,并打包成一个问题。
,对每一个坐标来说都是很常见的。一个简单的思想实验表明这可能并不理想:假设我们使用逻辑回归估计10个硬币的正方面概率 Pr(head | coini)。每一轮t,一个硬币我被翻转,我们看到一个特征向量 x∈R10 表示xi = 1且xj = 0表示j ! = i。 从而,我们基本上解决了10个独立的逻辑回归问题,并打包成一个问题。
我们可以运行10个独立的在线梯度渐变下降,问题 i 的算法实例我会使用像ηt这样的学习率,i =1/√nt,i其中nt,i是到目前为止,我已经翻过硬币的次数。 如果硬币i比硬币j翻转的更多, 硬币 i 的学习率我会更快地减少,映射到我们有更多的事实数据情况下, 硬币j的学习率将保持高位,因为我们有对我们目前估计的信心不足,因此需要做出反应更快地获取新数据。
另一方面,如果我们将此视为单一学习问题,则标准学习率计划ηt=1/√Ť 会被应用于所有坐标:也就是说,即使没有翻转,我们也会降低硬币i的学习率。 这个显然不是最佳行为。 事实上,Streeter和McMahan [29]已经展示了一系列问题,标准算法的性能是渐近的比运行独立副本更糟糕。因此,在至少对于某些问题,每个坐标学习率可以提供了实质性的优势。
回想一下gs,i,就是我梯度gs = ![]() 的第 i 个坐标,然后,仔细分析显示每个坐标率,
的第 i 个坐标,然后,仔细分析显示每个坐标率,
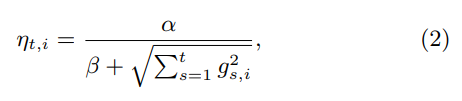
在某种意义上几乎是最优的在实践中,我们使用a学习率,其中选择α和β以在验证集下产生良好的性能(参见第5.1节)。 我们我还尝试过在 counter n(t,i) 做平方,而不是原始的 0.5 。 α的最佳值可以变化,一般取决于特征和数据集,β = 1通常足够好; 这简单地确保了早期学习率不是太高。
如上所述,该算法要求我们跟踪每个特征上,“梯度”的总和、“梯度”平方和的总和。 第4.5节介绍了另一种节省内存的公式,其中总和为梯度的平方在许多模型上摊销。
对每个坐标学习率的相对简单的分析出现在[29]中,以及在小的数据集Google数据集上的实验结果;这项工作直接建立在Zinkevich [34]的方法上。 对于FTRLProximal的更恰当的理论出现在杜奇[26] [10]等人。分析RDA和镜像下降版本,并给出了许多实验结果。
实验结果。 我们通过测试两个相同的模型评估了percoordinate学习率的影响,一个使用单一的全局学习率,一个使用percoordinate学习率。 基本参数α分别被每个模型调整。 我们使用了具有代表性数据设置,并使用AucLoss作为我们的评估指标(参见第5节)。 结果显示使用每坐标学习率相比全局学习率基线,AucLoss降低了11.2%。 把这个结果放在上下文中,在我们的设定中,AucLoss减少1%被认为是大的。
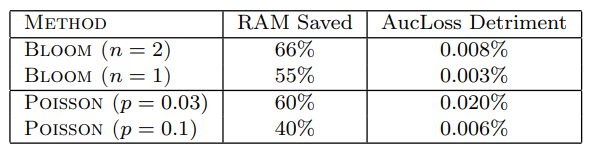
表2:特征包含效果概率。
两种方法都是有效的,但 bloom 过滤方法在节省RAM、预测准确率之间提供了更好的权衡
4.大规模保存记忆
如上所述,我们使用L1正则化来在预测时节省存储。 在本节中,我们将介绍在训练期间节省内存的其他技巧。
4.1 Probabilistic Feature Inclusion
在许多具有高维数据的领域,大多数特征都非常罕见。 事实上,在一些我们的模型,整个训练集数十亿的例子中,有一半的特征只出现一次
跟踪这些罕见的特征的统计数据非常耗时,并且这永远不会有任何实际用途。 不幸的是,我们没有事先知道哪些特征很少见。在线上预处理移除稀有特征的数据是一个有问题的设置:额外读取然后写入数据非常昂贵的,如果某些功能被丢弃(比如,因为它们发生的次数少于k次),再也不可能尝试使用这些特征来估算成本的模型在准确性方面进行预处理。
一系列方法通过训练获得稀疏性,通过L1正则就实现了这一个功能,而不用在训练期间去统计非0的数量。 这样可以在训练过程中删除信息量较少的特征。 但是,我们发现了这一点导致了在acc方面一个不能接受的损失,与那些在训练过程中使用更多的特征但是在预估的时候保证稀疏性。 这个问题的另一个常见解决方案是使用碰撞进行散列,但也没有给出有用的好处(参见第9.1节)。
我们探索的另一类方法是概率性的特征包含,当那些首次出现的特征,也会有一定概率包含在我们的概率模型中。 这不仅实现了预处理数据的效果,而且可以在线设置。我们测试了这种方法的两种方法。
• 泊松包含。 当我们遇到我们的模型中尚未添加一个特征,它具有概率p会被添加到我们的模型。 一旦添加了一个特征,在随后的观察中我们将其系数值和OGD使用的相关统计更新为定值。一个特征会被只有点出现一定的次数时,他才会被添加到模型,这样一个处理符合几何分配预期值1/p。
• Bloom Filter Inclusion。 我们使用滚动集计算Bloom过滤器[4,12]以检测一个特征在训练集中前n次出现。 一旦有特征发生超过n次(根据过滤器),我们将其添加到模型中,并将其用于上述后续观察中的训练。 注意这个方法也是概率性的,因为“计数布隆过滤器”能够出现误报(但不是假阴性)。也就是说,我们有时会包含一个功能实际发生不到n次。
实验结果。 这些方法的效果如表2所示,表明两种方法都运行良好,但Bloom过滤器方法提供了一组更好的权衡用于节省预测质量损失的RAM。
4.2使用较少的位编码值
OGD的朴素实现使用32或64位浮动点编码来存储系数值。 浮点编码通常很有吸引力,因为它们的动态很大范围和细粒度精度; 但是,对于系数我们的正则化逻辑回归模型得出结论太过分了。 几乎所有的系数值都在其中范围(-2,+ 2)。 分析表明,细粒度也不需要精确[14],激励我们去探索使用定点q2.13编码而不是浮动点。
在q2.13编码中,我们保留了左边的两位二进制小数点,二进制右边的十三位小数点和符号位,总共16位每个值使用。
这种减少的精度可能会在OGD设置中产生累积舍入误差的问题,这需要积累了大量的微小步骤。 (事实上,我们甚至看到使用32位浮点数的严重舍入问题而不是64.)但是,一个简单的随机舍入战略纠正了这一点,代价是一点点遗憾术语[14]。 关键是通过明确舍入,我们可以确保离散化误差为零均值。
特别是,如果我们存储系数w,我们设置
![]()
其中R是在0和1直接的随机偏差均匀分布,gi,rounded 以q2.13这种固定点格式进行存储; 超出范围[-4,4]之外的值被剪裁。 对于FTRL-Proximal,我们可以用这种方式存储ηtzt,其中与wt相似。
实验结果。 在实践中,我们测出来使用q2.13编码而不是64位浮点值的模型的结果,并没有明显的损失,我们节省75%的RAM用于系数存储。
4.3 训练许多类似的模型
在测试对超参数设置或特征的更改时,评估许多简单的指标通常很有用一种形式。 这种常见的用例导致了有效的训练策略。 这一行中有一项有趣的工作是[19],它使用固定模型作为先验和允许的变量来评估残差。 这个方法非常简单,但不容易评估特征删除或替代学习参数设置
我们的主要方法依赖于观察数据,即每个坐标依赖于可以有效共享的一些数据跨模型变体,而其他数据(如系数值本身)特定于每个模型变体,不能共享。 如果我们将模型系数存储在哈希表中,我们可以使用单个表来表示所有变量,并进行摊销存储key值的成本(字符串或多字节哈希值)。 在下一节(4.5)中,我们将展示每个模型学习率计数器ni可以被共享的统计数据取代通过所有变体,这也减少了存储。
任何没有特定特征的样本都会将该特征的系数存储为0,浪费一小部分空间量。 (我们通过设置学习率来强制执行这些特征为0.)因为我们只训练在一起高度相似的模型,不代表键的内存节省和每个模型的数量比不常见的特征带来的损失要大得多。
当几个模型一起训练时,摊销降低所有每个坐标元数据的成本,例如每个坐标学习率所需的计数,以及附加模型的增量成本仅取决于需要存储的附加系数值。 这个不仅可以节省内存,还可以节省网络带宽值通过网络在同一个网络中传播方式,我们只读取训练数据一次),CPU(仅限一个哈希表查找而不是很多,功能是仅从训练数据生成一次而不是一次每个型号)和磁盘空间。 这种捆绑式架构显着提高了我们的训练能力。
4.4单一价值结构
有时我们希望评估非常大的模型集变体在一起,仅通过添加或删除而不同一小组特征。 在这里,我们可以使用均匀的更加压缩的数据结构,既有损又有广告但是在实践中却给出了非常有用的结果。 此单值结构仅为每个存储一个系数值包含的所有模型变体共享的坐标该功能,而不是对于每个型号变体存储单独的系数值。 比特字段用于跟踪哪个模型变体包括给定的坐标。 请注意这一点在实意上与[19]的方法类似,但也允许特征删除和添加的评估。该使用额外的模型,RAM成本增长得慢得多变体比第4.3节的方法。
学习进度如下。 对于OGD中的给定更新,每个模型变量使用计算其预测和损失它包含的坐标子集,绘制在为每个系数存储单个值。 对于每个特征 i,使用 i 的每个模型都计算出一个新的期望值给定的系数。 得到的值是平均值和存储为单个值,然后在下一步中由所有变体共享。
我们通过比较大组模型变量,来评估这种启发式方法使用单值结构训练的模型变体针对与设置完全一致训练的相同变体来自第4.3节。 结果显示变体的相对性能几乎相同,但单值结构在RAM中保存了一个数量级。
4.5计算学习率
如3.1节所述,我们需要为每个特征存储他的梯度之和、每个特征的梯度平方之和。 所以正确的梯度计算是很重要的,但总近似值要和学习率一起计算。
假设包含给定特征的所有事件都有相同的概率。 (一般来说,这是一个几乎不可能的假设,但在这次研究中是可行的)进一步假设该模型已准确地学习到了事件发生的概率。 如果有N个负面事件和P个正面事件,那么概率是p = P /(N + P)。 如果我们使用逻辑回归,正样本的梯度是p - 1,负样本的梯度是p,所需的梯度之和需要和学习率对等。

这种不太合常规的近似使我们只能跟踪计数N和概率P,省去存储![]() ,根据经验,学习率用这个近似值,和用全量的sum值来计算,表现的效果无差。 使用第4.3节的框架,总存储成本较低,因为所有变体模型都具有相同的存储成本计数,因此N和P的存储成本是摊销的。该计数可以用可变长度的位编码存储,和绝大多数特征一样不需要很多位。
,根据经验,学习率用这个近似值,和用全量的sum值来计算,表现的效果无差。 使用第4.3节的框架,总存储成本较低,因为所有变体模型都具有相同的存储成本计数,因此N和P的存储成本是摊销的。该计数可以用可变长度的位编码存储,和绝大多数特征一样不需要很多位。
4.6 采样训练数据
典型的点击率远低于50%,这意味着正样本(点击)是相对罕见的。 从而,简单的统计计算表明正样本在ctr模型中更加的重要。 我们可以利用这一点来显着减少训练数据大小,同时也保证对准确性影响最小。 我们通过抽样来完成这样一个事情:
•任何至少有一个广告被点击的查询实例。
•查询的预估分数r∈(0,1),其中没有广告被点击了。
在query级别进行采样是可取的,得到许多特征前,都需要对query进行常见处理。 当然,直接训练这个二次抽样数据会导致显着的偏见预测。 这个问题通过赋予重要性权重ωt,来很容易地理解这个问题
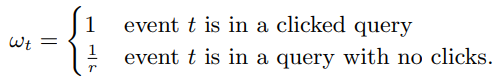
由于我们控制采样分布,我们必要像在一般样本中那样估计权重ω[7]。重要性权重只会扩大每个样本的损失值,Eq.(1),因此也缩放了梯度。 查看这具有预期的效果,考虑在非抽样中随机选择的事件t的预期贡献数据,加到子采样目标函数。 让 st 成为事件 t (不管采样比例是1 or r) 的贡献概率,定义 st = 1 / wt,因此我们可以定义
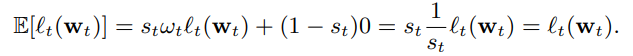
期望的线性关系,意味着预期的加权子采样训练数据的目标函数,等于原始数据集上的目标函数。 实验有验证了即使是对那样未曾产生点击的query数据进行多的采样,对于准确性的影响也非常小,预测性能不会受到特定速率的影响的值。
5.评估模型性能
评估我们模型的质量最方便是使用记录的历史数据。(用线上流量来验证是一件非常昂贵的事情)
因为不同的指标以不同的方式响应模型的变化,我们发现在一个数据集上评价多个指标是很有用的操作。 我们计算AucLoss等指标(即1 - AUC,其中AUC是ROC下的标准区域曲线度量[13]),LogLoss(见公式(1))和SquaredError。为了保持一致性,我们还设计了较小的指标表现总是更好。
5.1逐步验证
我们通常使用逐步验证(有时称为在线损失)[5],而不是交叉验证或使用一个固定的数据集。 因为计算学习的梯度的话,总需要先计算预测值,我们可以很方便的将这些预测值记录下来进行后续分析,每小时汇总一次。 我们还在各种方面计算这些指标数据的子切片,例如按国家/地区划分的查询主题和布局。
在线损失是我们线上查询服务准确性的良好代表,因为它只测量在我们训练数据之后发生的最新数据 - 完全类似于模型提供查询时发生的事情。 在线损失也有比使用固定的数据验证集好的地方,因为我们可以使用100%的数据训练和测试。 这很重要,因为很小改进可以在规模和需求上产生有意义的影响要高信度地观察大量数据。
绝对度量值通常会产生误导。 即使预测是完美的,LogLoss和其他指标也会根据问题的难度(即贝叶斯风险)。 如果点击率接近50%,则可以达到最大的比对效果,LogLoss远高于点击率接近2%的情况。这很重要,因为点击率因国家/地区而异,在同一个query下,而且1天中改变很多次。
因此,我们始终关注相对变化,通常表示为度量相对于基线模型的百分比变化。 根据我们的经验,相对变化随着时间的推移更稳定。我们也只注意比较从完全相同的数据计算的指标; 例如,在一个时间范围内在模型a上计算的损失度量, 与另一个模型在不同的时间范围内计算的相同损失指标,不具有可比性
5.2通过可视化深入理解
大规模学习中的一个潜在缺陷是聚合性能指标可能隐藏特定于数据,也就是某些子群体带来的影响。 例如,实际上,在一个度量上可以获得小的聚合精度是由不同国家/地区的特定查询主题的正样本和抚养比变化混合引起的。 这使得至关重要的是,不仅要提供绩效指标聚合数据,也有关于数据的各种切片等作为每个国家/地区或每个主题的基础。
因为有数百种方法可以有意义地对数据进行切片,所以我们必须能够有效地汇总数据来检查视觉效果。 为此,我们开发了一种名为的高维交互式可视化GridViz工具,以允许全面了解模型性能。
GridViz中一个视图的屏幕截图如图2所示,显示了与控制模型相比两个模型的查询主题的一组切片数据展示。 度量值由彩色单元格表示,行对应于“模型名”、列对应“数据的切片”。 列宽意味着切片的重要性,并且可以设置为反映作为展示次数或点击次数这样的量。 单元格颜色反映了与所选度量相比的度量值基线,可以快速扫描异常值和区域感兴趣,以及对整体表现的视觉理解。 当列足够宽时,数字显示所选指标的值。 多个指标可以选择; 这些在每一行中一起显示。 一个用户划过鼠标时,弹出给定单元格的详细报告。
因为有数百种可能的切片,我们有设计了一个交互式界面,允许用户通过下拉菜单或通过设置正则表达式来控制切片的数量。 列可能是排序和色标的动态范围修改为匹配当前的数据。 总的来说,这个工具使我们成功地大大增加我们对模型的理解的深度,以及在各种数据子集上的性能,并确定需要改进的高影响区域。

图2:高维分析可视化的屏幕截图。 这里,将三种变体与a控制模型进行比较,在一系列查询主题中计算AucLoss和LogLoss的结果。 列宽反映曝光数量。 鼠标悬停的那块展示出特定细分的详细信息。 用户界面允许选择多个指标和几个可能的细分,包括细分主题,国家/地区,匹配类型和页面布局。 这允许快速扫描异常和深入理解模型效果。用颜色进行展示最易于分析。

图3:可视化不确定性分数。Log-odds错误 ![]() 绘制了相对于不确定性评分,一种置信度。 x轴归一化,因此各个估计的密度(灰点)在整个域中是一致的。线条给出估计的25%,50%,75%的误差百分位数。 高不确定性与...有很好的相关性更大的预测误差。
绘制了相对于不确定性评分,一种置信度。 x轴归一化,因此各个估计的密度(灰点)在整个域中是一致的。线条给出估计的25%,50%,75%的误差百分位数。 高不确定性与...有很好的相关性更大的预测误差。
6. 置信度估计
对于许多应用程序,重要的是不仅要估算广告的点击率,还要量化预测的准确性。 特别是,这样的估计可以用于衡量和控制 曝光和点击 之间的权衡:为了做出准确的预测,系统有时必须展示其数据很少的广告,但这应该与广告给公司带来的收益之间处于一种平衡的关系[21,22]。
置信区间捕捉到不确定性的概念,但出于实际和统计的原因,它们不适合我们的应用。 标准方法将评估完全融合批量模型的预测的置信度,而无需正则化; 我们的模型在线,没有假设IID数据(因此收敛甚至没有明确定义),并且严格正规化。 标准统计方法(例如,[18],Sec。 2.5)还需要反转n×n矩阵; 什么时候数十亿,这是一个非首发。
此外,任何置信度估计都必须如此在预测时间进行计算 - 比如说与预测本身一样多的时间。
我们提出了一种启发式方法,我们称之为不确定性得分,在计算上易于处理,并且在经验上量化预测准确性做得很好。 基本观察是学习算法本身保持一个概念,每个特征计数器的数字大小 nt,i,制我用于学习速率控制。 ni大的特征得到小的学习率,正是因为我们认为当前的系数值更可能是准确的。 渐变log-odds得分的逻辑损失是(pt-yt)因此,绝对值的界限为1.因此,如果我们假设特征向量被归一化,所以| xt,i | ≤1,我们可以由于观察单个训练样本(x,y)带来的损失。 为简单起见,请λ1=λ2= 0,因此FTRL-Proximal相当于在线梯度下降。
我们让 ![]() ,根据公式(2)有
,根据公式(2)有
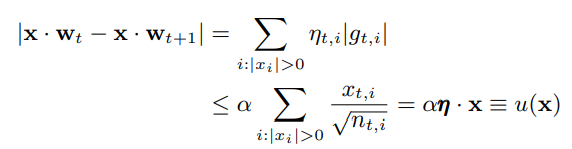
其中η是学习率的向量。 我们定义了不确定性得分为上限 ![]() 它可以使用单个稀疏点积计算,就像预测 p =σ(w·x)。
它可以使用单个稀疏点积计算,就像预测 p =σ(w·x)。
实验结果。 我们验证了这种方法如下。 首先,我们训练了一个真实的“有真实Label”的模型,但和通常使用的特征略有不同。 然后,我们丢弃了真正的点击标签,并对新标签进行了采样将真实的标签的数据看做真实点击率。 这是必要的,因为评估置信度过程的有效性需要知道真实的标签。 然后我们在重新标记的数据上运行FTRL-Proximal,记录预测pt,这使我们能够比较其准确性log-odds空间中的偏差,et = |σ-1(PT)-σ-1(p*t)| ,pt*是真正的CTR(由真实数据给出)。图3绘制了误差和不确定性的函数得分ut = u(xt); 存在高度相关性
另外的实验表明,不确定性评分的表现相当(在上述评估体系下),通过bootstrap获得的更昂贵的32个在随机子样本训练的模型
7.校准预测
准确且经过良好校准的预测不仅对于进行训练模型至关重要,而且还允许松散耦合的整体系统设计将训练模型中的优化问题与机器学习机器分开。
系统偏差(某些数据片上的预测和观察到的CTR之间的差异)可以是由各种因素引起,例如,不准确的建模假设,学习算法的缺陷或隐藏在训练和/或线上中的不一致问题。 为了解决这个问题,我们可以使用校准层来匹配预测的点击率和观察到的点击率
我们的预测是根据一个数据 d 校准的平均值,当我们预测p时,实际观察到的CTR是靠近p。 我们可以通过应用校正函数来改进校准函数τd(p)其中p是预测的CTR,d是a训练数据分区的元素。 我们定义成功在很多范围内提供经过良好校准的预测可能的数据分区。
对τ进行建模的简单方法是对数据拟合函数τ(p)=γpκ。 我们可以在汇总的数据上使用泊松回归来学习γ和κ。 一种稍微更为通用的方法能够应对偏置曲线中更复杂的形状,是使用分段线性或分段恒定校正功能。 唯一的限制是映射功能τ应该是保序的(单调增加)。 我们可以使用保序回归找到这样的映射,保序回归计算输入数据主体的加权最小二乘拟合到那个约束(参见,例如,[27,23])。 这种分段线性的方法显着降低了两者的预测偏差与上述合理的基线方法相比,该范围的高端和低端。
值得注意的是,如果没有强有力的额外假设,系统中的固有反馈回路使得无法为其影响提供理论保证。校准[25]。
8.自动化功能管理
可扩展机器学习的一个重要方面是管理安装的规模,包括所有的安装配置,开发人员,代码和计算资源构成机器学习系统。 安装由几个团队组成的几十个领域特定问题的建模需要一些开销。 一个特别有趣的案例是管理特征空间机器学习。
我们可以将特征空间表征为一组上下文和语义信号,其中每个信号(例如,'广告中的文字信息','广告中涉及到的国家'等)都可以被翻译成一组用于学习的实价特征。 在一个大型系统中,许多开发人员可能异步工作。 信号可以具有与配置改变,改进和替代实现相对应的许多版本。 工程团队可能会消费他们没有直接发展的信号。 信号可能是在多个不同的学习平台上使用,并应用于不同的学习问题(例如预测搜索与展示广告点击率)。 处理组合生长用例,我们已经部署了一个用于管理的元数据索引消耗数千个输入信号活跃的模型。
索引信号既可以手动也可以自动注释,以解决各种问题; 示例包括弃用,特定于平台的可用性和特定于域的适用性。 新模型和活动模型消耗的信号由自动警报系统审查。 不同的学习平台共享报告信号的通用接口消费到中央指数。 当信号被弃用时(例如当新版本可用时),我们可以快速识别信号和跟踪的所有消费者更换工作。 当改进版本的信号时提供消费者,可以提醒消费者进行实验新版本。
新信号可以通过自动测试进行审查,并列入白名单。 白名单既可用于确保,也可用于确保生产系统和学习系统的正确性使用自动功能选择。 老信号是不再使用的是自动指定代码清理,以及删除任何相关数据
有效的自动信号消耗管理确保第一次正确完成更多学习。 这个减少浪费和重复的工程工作,节省很多工程时间。 在运行学习算法之前验证配置的正确性会消除很多可能导致模型不可用的情况,可以节省大量潜在的资源浪费。
9.不成熟的实验
在最后一节中,我们将简要介绍几个方向(可能令人惊讶的是)并没有带来显着的好处。
9.1积极的特征哈希
1 对特征进行哈希
近年来,各地都出现了一系列操作,使用特征散列来降低大规模的RAM成本学习。 值得注意的是,[31]报告了使用的优秀结果哈希技巧投射出一个能够学习的特征空间个性化垃圾邮件过滤模型仅限于空间
2 24个特征
使模型足够小,易于安装在一台机器的RAM中。 同样,Chapelle报道使用散列技巧,224个结果特征用于建模显示广告数据[6]。
我们测试了这种方法,但发现我们无法做到投影低于数十亿的特征没有可观察到的损失。 这并没有为此节省大笔费用我们,我们更喜欢维护可解释的(无方向)特征向量。
9.2 扔掉一些特征
最近的工作引起了对随机“dropout”新技术的兴趣,特别是在训练中深信深度训练网络社区[17]。 主要想法是以概率p独立地从输入示例向量中随机移除特征,并通过补偿来补偿将得到的权重向量缩放(1-p)在测试时间。 这被视为一种正则化形式模拟可能的特征子集上的装袋。
我们已经尝试了一系列的学习率0.1到0.5,每个都有一个伴随的网格搜索学习率设置,包括改变epoch次数。 在所有情况下,我们都发现了dropout在预测准确度指标或泛化能力方面没有给出好处,并且通常会产生不利影响。
我们认为这些消极的差异来源结果和愿景社区的有希望的结果在于特征分布的差异。 在视觉任务中,输入特征通常是密集的,而在我们的任务输入中特征稀疏,标签嘈杂。 在密集的环境中,dropout用于将影响与强相关分开功能,导致更健壮的分类器。 但在我们的稀疏,嘈杂的设置添加辍学似乎很简单减少可用于学习的数据量
9.3 特征做bagging
另一种沿着dropout的训练变体我们研究的是特征bagging,其中k个模型在特征空间的k个重叠子集上独立训练。 模型的输出是a的平均值最终预测。 这种方法已被广泛使用数据挖掘社区,最着名的是有关的集合决策树[9],提供了一种管理偏差 - 方差权衡的潜在有用方法。 我们也对进一步并行化训练模型感兴趣。然而,我们发现特征bagging实际上略微降低了预测质量,AucLoss在0.1%和0.6%之间取决于装袋方案。
9.4特征向量归一化
在我们的模型中,每个事件的非零特征数量可能会有很大差异,导致不同的样本x有不同的量级kxk。 我们担心这种可变性可能会减慢收敛或影响预测准确性。 我们通过x训练探索了几种正常化的风格KXK具有各种规范,目标是减少示例向量之间的幅度变化。 尽管有一些早期结果显示我们无法获得小的准确性收益将这些转化为整体积极的指标。 事实上,我们的实验看起来有点不利,可能是由于与每个坐标学习率和正规化的互动。
10.致谢
我们非常感谢以下方面的贡献:Vinay Chaudhary,Jean-Francois Crespo,JonathanFeinberg,Mike Hochberg,Philip Henderson,Sridhar Ramaswamy,Ricky Shan,Sajid Siddiqi和Matthew Streeter。
11.参考文献
[1] D. Agarwal, B.-C. Chen, and P. Elango. Spatio-temporal models for estimating click-through rate. In Proceedings of the 18th international conference on World wide web, pages 21–30. ACM, 2009.
[2] R. Ananthanarayanan, V. Basker, S. Das, A. Gupta, H. Jiang, T. Qiu, A. Reznichenko, D. Ryabkov, M. Singh, and S. Venkataraman. Photon: Fault-tolerant and scalable joining of continuous data streams. In SIGMOD Conference, 2013. To appear.
[3] R. Bekkerman, M. Bilenko, and J. Langford. Scaling up machine learning: Parallel and distributed approaches. 2011.
[4] B. H. Bloom. Space/time trade-offs in hash coding with allowable errors. Commun. ACM, 13(7), July 1970.
[5] A. Blum, A. Kalai, and J. Langford. Beating the hold-out: Bounds for k-fold and progressive cross-validation. In COLT, 1999.
[6] O. Chapelle. Click modeling for display advertising. In AdML: 2012 ICML Workshop on Online Advertising, 2012.
[7] C. Cortes, M. Mohri, M. Riley, and A. Rostamizadeh. Sample selection bias correction theory. In ALT, 2008.
[8] J. Dean, G. S. Corrado, R. Monga, K. Chen, M. Devin, Q. V. Le, M. Z. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, and A. Y. Ng. Large scale distributed deep networks. In NIPS, 2012.
[9] T. G. Dietterich. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Machine learning, 40(2):139–157, 2000.
[10] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. In COLT, 2010.
[11] J. Duchi and Y. Singer. Efficient learning using forward-backward splitting. In Advances in Neural Information Processing Systems 22, pages 495–503. 2009.
[12] L. Fan, P. Cao, J. Almeida, and A. Broder. Summary cache: a scalable wide-area web cache sharing protocol. IEEE/ACM Transactions on Networking, 8(3), jun 2000.
[13] T. Fawcett. An introduction to roc analysis. Pattern recognition letters, 27(8):861–874, 2006.
[14] D. Golovin, D. Sculley, H. B. McMahan, and M. Young. Large-scale learning with a small-scale footprint. In ICML, 2013. To appear.
[15] T. Graepel, J. Q. Candela, T. Borchert, and R. Herbrich. Web-scale Bayesian click-through rate prediction for sponsored search advertising in microsofts bing search engine. In Proc. 27th Internat. Conf. on Machine Learning, 2010.
[16] D. Hillard, S. Schroedl, E. Manavoglu, H. Raghavan, and C. Leggetter. Improving ad relevance in sponsored search. In Proceedings of the third ACM international conference on Web search and data mining, WSDM ’10, pages 361–370, 2010.
[17] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. CoRR, abs/1207.0580, 2012.
[18] D. W. Hosmer and S. Lemeshow. Applied logistic regression. Wiley-Interscience Publication, 2000.
[19] H. A. Koepke and M. Bilenko. Fast prediction of new feature utility. In ICML, 2012.
[20] J. Langford, L. Li, and T. Zhang. Sparse online learning via truncated gradient. JMLR, 10, 2009.
[21] S.-M. Li, M. Mahdian, and R. P. McAfee. Value of learning in sponsored search auctions. In WINE, 2010.
[22] W. Li, X. Wang, R. Zhang, Y. Cui, J. Mao, and R. Jin. Exploitation and exploration in a performance based contextual advertising system. In KDD, 2010.
[23] R. Luss, S. Rosset, and M. Shahar. Efficient regularized isotonic regression with application to gene–gene interaction search. Ann. Appl. Stat., 6(1), 2012.
[24] H. B. McMahan. Follow-the-regularized-leader and mirror descent: Equivalence theorems and L1 regularization. In AISTATS, 2011.
[25] H. B. McMahan and O. Muralidharan. On calibrated predictions for auction selection mechanisms. CoRR, abs/1211.3955, 2012.
[26] H. B. McMahan and M. Streeter. Adaptive bound optimization for online convex optimization. In COLT, 2010.
[27] A. Niculescu-Mizil and R. Caruana. Predicting good probabilities with supervised learning. In ICML, ICML ’05, 2005.
[28] M. Richardson, E. Dominowska, and R. Ragno. Predicting clicks: estimating the click-through rate for new ads. In Proceedings of the 16th international conference on World Wide Web, pages 521–530. ACM, 2007.
[29] M. J. Streeter and H. B. McMahan. Less regret via online conditioning. CoRR, abs/1002.4862, 2010.
[30] D. Tang, A. Agarwal, D. O’Brien, and M. Meyer. Overlapping experiment infrastructure: more, better, faster experimentation. In KDD, pages 17–26, 2010.
[31] K. Weinberger, A. Dasgupta, J. Langford, A. Smola, and J. Attenberg. Feature hashing for large scale multitask learning. In ICML, pages 1113–1120. ACM, 2009.
[32] L. Xiao. Dual averaging method for regularized stochastic learning and online optimization. In NIPS, 2009.
[33] Z. A. Zhu, W. Chen, T. Minka, C. Zhu, and Z. Chen. A novel click model and its applications to online advertising. In Proceedings of the third ACM international conference on Web search and data mining, pages 321–330. ACM, 2010.
[34] M. Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. In ICML, 2003.















 5363
5363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









