







目录
视图(View)
1. 视图的理解
① 视图,可以看做是一个虚拟表,本身是不存储数据的。
视图的本质,就可以看做是存储起来的SELECT语句② 视图建立在已有表的基础上, 视图赖以建立的这些表称为基表
③ 针对视图做DML操作,会影响到对应的基表中的数据。反之亦然。
④ 视图本身的删除,不会导致基表中数据的删除。
⑤ 视图的应用场景:针对于小型项目,不推荐使用视图。针对于大型项目,可以考虑使用视图。
⑥ 视图的优点:简化查询; 控制数据的访问
常见的数据库对象

- 创建视图
精简版
CREATE VIEW 视图名称AS 查询语句
在 CREATE VIEW 语句中嵌入子查询
CREATE [ OR REPLACE ][ ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]VIEW 视图名称 [( 字段列表 )]AS 查询语句[ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
注意:如果基表中存在 要求不为空 的限制字段 ,有可能添加失败 。删除同理(引用完整性)
针对于单表
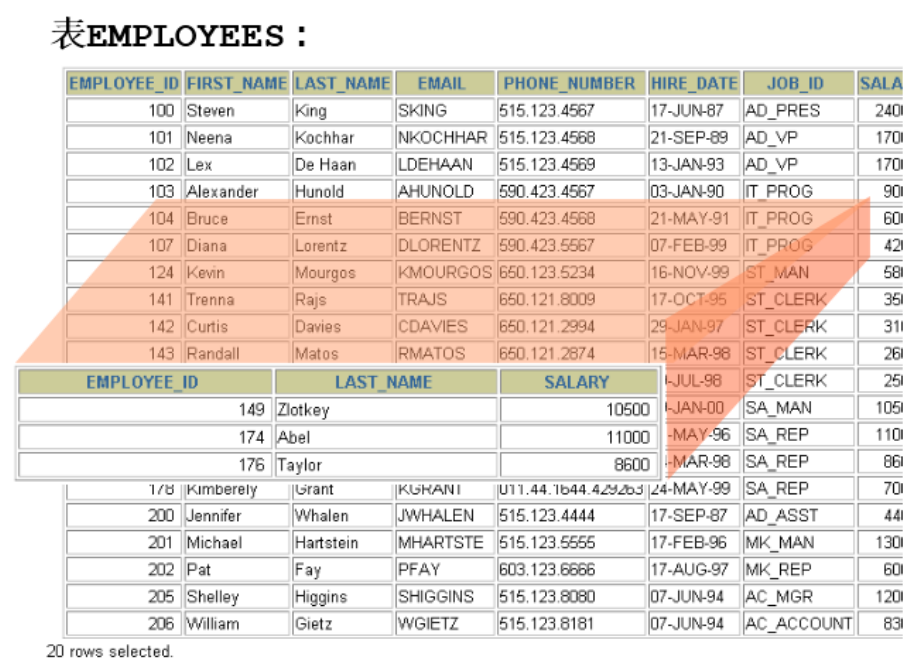
#情况1:视图中的字段与基表的字段有对应关系
CREATE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary
FROM emps;
SELECT * FROM vu_emp1;
#确定视图中字段名的方式1:
CREATE VIEW vu_emp2
AS
SELECT employee_id emp_id,last_name lname,salary #查询语句中字段的别名会作为视图中字段的名称出现
FROM emps
WHERE salary > 8000;
#确定视图中字段名的方式2:
CREATE VIEW vu_emp3(emp_id,NAME,monthly_sal) #小括号内字段个数与SELECT中字段个数相同
AS
SELECT employee_id,last_name,salary
FROM emps
WHERE salary > 8000;
SELECT * FROM vu_emp3;
#情况2:视图中的字段在基表中可能没有对应的字段
CREATE VIEW vu_emp_sal
AS
SELECT department_id,AVG(salary) avg_sal
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
SELECT * FROM vu_emp_sal;
#2.2 针对于多表
CREATE VIEW vu_emp_dept
AS
SELECT e.employee_id,e.department_id,d.department_name
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept;
#利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e.last_name,'(',d.department_name,')') emp_info
FROM emps e JOIN depts d
ON e.`department_id` = d.`department_id`;
SELECT * FROM vu_emp_dept1;
#2.3 基于视图创建视图
CREATE VIEW vu_emp4
AS
SELECT employee_id,last_name
FROM vu_emp1;
SELECT * FROM vu_emp4; 查看视图
查看视图
# 语法1:查看数据库的表对象、视图对象
SHOW TABLES;
#语法2:查看视图的结构
DESCRIBE vu_emp1;
#语法3:查看视图的属性信息
SHOW TABLE STATUS LIKE 'vu_emp1';
#语法4:查看视图的详细定义信息
SHOW CREATE VIEW vu_emp1;- 更新视图的数据
"更新"视图中的数据
#4.1 一般情况,可以更新视图的数据
SELECT * FROM vu_emp1;
SELECT employee_id,last_name,salary
FROM emps;
#更新视图的数据,会导致基表中数据的修改
UPDATE vu_emp1
SET salary = 20000
WHERE employee_id = 101;
#同理,更新表中的数据,也会导致视图中的数据的修改
UPDATE emps
SET salary = 10000
WHERE employee_id = 101;
#删除视图中的数据,也会导致表中的数据的删除
DELETE FROM vu_emp1
WHERE employee_id = 101;
SELECT employee_id,last_name,salary
FROM emps
WHERE employee_id = 101;
#4.2 不能更新视图中 基表中不存在的数据
SELECT * FROM vu_emp_sal;
#更新失败
UPDATE vu_emp_sal
SET avg_sal = 5000 #(平均值)
WHERE department_id = 30;
#删除失败
DELETE FROM vu_emp_sal
WHERE department_id = 30;
- 修改、删除视图
修改视图
#方式1
CREATE OR REPLACE VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email
FROM emps
WHERE salary > 7000;
方式2
ALTER VIEW vu_emp1
AS
SELECT employee_id,last_name,salary,email,hire_date
FROM emps;
删除视图
SHOW TABLES;
DROP VIEW vu_emp4;
DROP VIEW IF EXISTS vu_emp2,vu_emp3;事务(transaction)
- 事物:一组逻辑操作单元,使数据从一种状态变化到另一种状态。一组逻辑单元:一个或多个DML操作。
- 事务处理原则:保证事物都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事物中执行多个操作时,要么所有的事务都被提交(commit),要么数据库管理系统放弃当前所做的修改,将事物回滚(rollback)到最初状态
- 事物一旦提交无法撤回
事务的ACID属性 :
(1)原子性(Automicity)
事务中的操作要么都发生,要么都不发生。(2)一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。(3)隔离性(Isolation)
事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。事物间相互不影响
(4)持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响
事务的开启、提交、回滚
MySQL默认情况下是自动提交事务。每一条语句都是一个独立的事务,一旦成功就提交了。一条语句失败,单独一条语句不生效,其他语句是生效的。
事务只对 DML操作有效(增删改) ,对DDL(修改表属性)无效
#开启手动提交事务模式 事务当前连接一直有效
set autocommit = false; 或 set autocommit = 0;
上面语句执行之后,它之后的所有sql,都需要手动提交才能生效,直到恢复自动提交模式。
ROLLBACK;#回滚
COMMIT;#提交
#恢复自动提交模式
set autocommit = true; 或 set autocommit = 1;-- 例:
SET autocommit = FALSE;#设置当前连接为手动提交模式
#如果后面没有提交,直接关了连接,那么这句修改不会生效
UPDATE t_employee SET salary = 15000
WHERE ename = '孙红雷';
ROLLBACK; #回滚
COMMIT;#提交
#恢复自动提交模式
set autocommit = true; 或 set autocommit = 1;start transaction; 事务一次有效
一旦回滚 或者提交则事务 ,事务就完成了四种事务隔离级别
数据库事务的隔离性:数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题。一个事务与其他事务隔离的程度称为隔离级别。数据库规定了多种事务隔离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就越好, 但并发性越弱。
脏读:一个事务读取了另一个事务未提交数据;
不可重复读:同一个事务中前后两次读取同一条记录不一样。因为被其他事务修改了并且提交了。(同一事务中查询的数据应保持一致性)
幻读:一个事务读取了另一个事务新增、删除的记录情况,记录数不一样,像是出现幻觉。
不可重复读的重点是修改,幻读重点是新增或删除
-
Oracle 支持的 2 种事务隔离级别:READ-COMMITED, SERIALIZABLE。 Oracle 默认的事务隔离级别为: READ COMMITED 。
-
Mysql 支持 4 种事务隔离级别。 Mysql 默认的事务隔离级别为: REPEATABLE-READ。在mysql中REPEATABLE READ的隔离级别也可以避免幻读了。
-- 获取mysql默认的隔离级别
SELECT @@transaction_isolation| 隔离级别 | 描述 |
|---|---|
| read-uncommitted | 允许A事务读取其他事务未提交和已提交的数据。无法避免脏读、不可重复读、幻读问题 |
| read-committed | 只允许A事务读取其他事务已提交的数据。可以避免脏读。 |
| repeatable-read | 确保事务可以多次从一个字段中读取相同的值。在这个事务持续期间,禁止其他事务对这个字段进行更新。注意:mysql中使用了MVCC多版本控制技术,解决了幻读问题。可以避免脏读、不可重复读、幻读 |
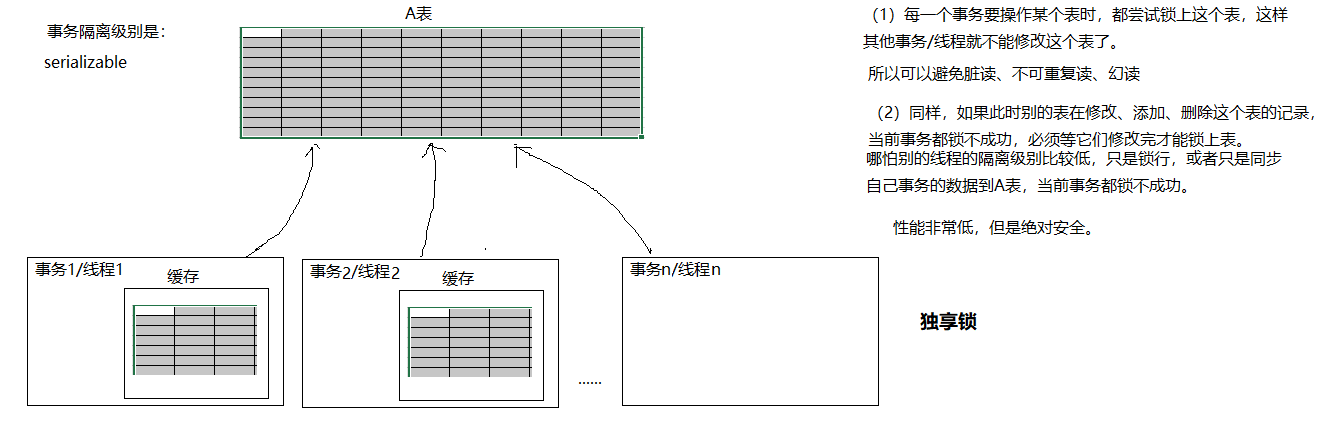
| serializable | 确保事务可以从一个表中读取相同的行,相同的记录。在这个事务持续期间,禁止其他事务对该表执行插入、更新、删除操作。所有并发问题都可以避免,但性能十分低下。 |



用户的创建
#用户登录
mysql -h192.168.31.23 -P端口号 -u用户名 -p
Enter password: ******权限管理
-
全局权限
-
数据库权限
-
数据表权限
-
字段权限
-
存储过程或函数子程序的权限
对用户的操作进行逐级权限验证,如果上一级有这个权限,下一级就不用验证了。
用户管理
添加用户时
用户名与主机绑定
% //任何计算机都可以
192.168.32.% --只有192.168.32网段的计算机
192.168.32.3 --只能在当前ip登录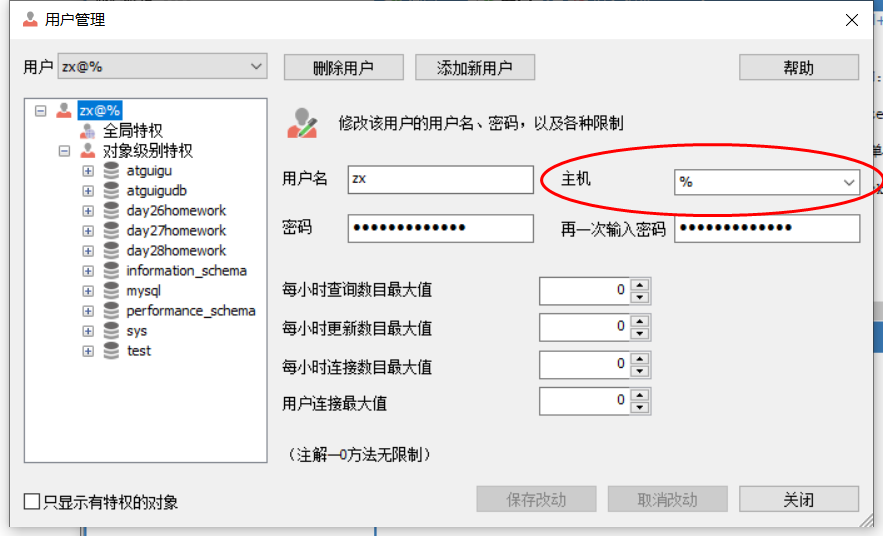















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









