







使用ResNet卷积网络识别验证码图片
备注:验证码训练集可以在有验证码网站获取(但前期标注比较恶心),这里使用captcha自动进行验证码图像生成,验证码为4位数字,范围0~4(范围较小方便训练),使用pillow和opencv两种方法进行了图像预处理,使用torch+cpu训练。
-
网络架构图
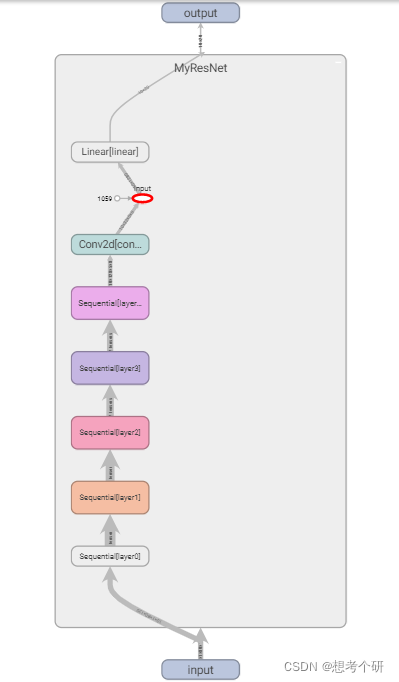
0.1 整体结构
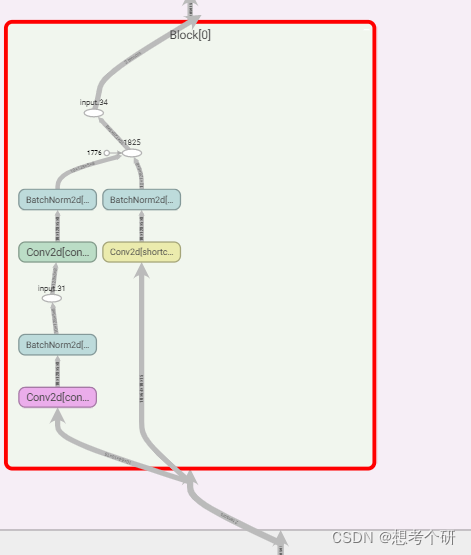
0.2 残差单元结构
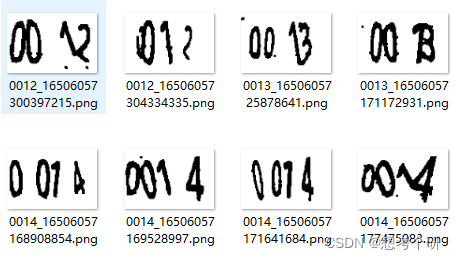
0.3 部分识别结果展示

-
导包
from captcha.image import ImageCaptcha import matplotlib.pyplot as plt import random import numpy as np import glob import os import time import cv2 from PIL import Image from PIL import ImageFilter import torch import torch.nn as nn from torch.utils.data import Dataset,DataLoader from torch.nn import BCEWithLogitsLoss from torch.optim import Adam -
验证码图像生成
image = ImageCaptcha(width=120,height=80) # 生成批量验证码函数 def generate_captcha(fp='./',captcha_nums=3): for i in range(captcha_nums): chars = ''.join([str(random.randint(0,4)) for i in range(4)]) timestamp = str(time.time()).replace('.','') image.write(chars,os.path.join(fp,f'{chars}_{timestamp}.png')) generate_captcha(fp='./test/image',captcha_nums=3000)
训练集原始图像
-
验证码图像预处理(使用pillow和opencv两种方法进行了图像预处理)
# PIL排序滤镜 def PIL_process(filename,save_path): # 图像灰度化和二值化 im1 = Image.open(filename).convert('L').convert('1') # 图像排序过滤 im1 = im1.filter(ImageFilter.RankFilter(3,2)) save_path = os.path.join(save_path,os.path.basename(filename)) im1.save(save_path) # opencv def opencv_process(filename,save_path): im2 = cv2.imread(filename) # 灰度化 im2 = cv2.cvtColor(im2,cv2.COLOR_BGR2GRAY) # 二值化 thresh,im2 = cv2.threshold(im2,200,255,cv2.THRESH_BINARY) # opencv 形态学变换,先膨胀后腐蚀,去除小黑点 im2 = cv2.morphologyEx(im2,cv2.MORPH_CLOSE,np.ones(shape=(3,3))) save_path = os.path.join(save_path,os.path.basename(filename)) cv2.imwrite(save_path,im2) # 将两种预处理后的图像数据集分别存入不同文件夹 for i in glob.iglob('./data/image/*.png'): PIL_process(i,'./data/pillow_process') opencv_process(i,'./data/opencv_process')
pillow图像预处理

opencv图像预处理
备注:并不是pillow处理图像效果比Opencv差,只是自己没好好调而已
-
构建图像数据集
# 定义数据集 class MyDataset(Dataset): def __init__(self,data): self.len_ = len(data) self.data = data def __getitem__(self,index): im = cv2.imread(self.data[index]) im = torch.div(torch.permute(torch.tensor(im),(2,0,1))[0].unsqueeze(0),255)# 将像素归一化 chars = os.path.splitext(os.path.basename(self.data[index]))[0] chars = chars[:chars.index('_')] label = nn.functional.one_hot(torch.tensor([int(i) for i in chars]),num_classes=5).flatten() return im,label def __len__(self): return self.len_ # 形成批量数据集 batch_size = 300 dataset = MyDataset(glob.glob('./data/opencv_process/*.png')) # 本次测试使用的opencv处理的预想 # 该生成器能多次循环,自己使用yield关键字创建的生成器数据只能迭代一次 dataloader = DataLoader(dataset=dataset,batch_size=batch_size,shuffle=True) -
构建ResNet神经网络
# 构建ResNet网络 # 构建基础残差块 class Block(nn.Module): def __init__(self,in_channels,out_channels,stride,is_channel_adjust=False): super().__init__() self.conv1 = nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,stride=stride,padding=1) self.bn1 = nn.BatchNorm2d(num_features=out_channels) self.conv2 = nn.Conv2d(in_channels=out_channels,out_channels=out_channels,kernel_size=3,padding=1) self.bn2 = nn.BatchNorm2d(num_features=out_channels) self.is_channel_adjust = is_channel_adjust # if is_channel_adjust: #是否调整短接线上x 的通道数,使用与残差逐点相加时,维度一致。 self.shortcut = nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=1,stride=stride) self.bn3 = nn.BatchNorm2d(num_features=out_channels) def forward(self,x): z = torch.relu(self.bn1(self.conv1(x))) z = self.bn2(self.conv2(z)) if self.is_channel_adjust: x = self.bn3(self.shortcut(x)) z = torch.relu(z+x) return z # 构建残差网络 class MyResNet(nn.Module): def __init__(self): super().__init__() self.layer0 = self._init_layer(in_channels=1,out_channels=8) self.layer1 = self._make_layer(in_channels=8,out_channels=16) self.layer2 = self._make_layer(in_channels=16,out_channels=32) self.layer3 = self._make_layer(in_channels=32,out_channels=64) self.layer4 = self._make_layer(in_channels=64,out_channels=128) # 最后使用全连接层进行输出 out_tokens = 5 # 验证码范围[0,4] num_captchas = 4 # 验证码为4位 self.conv0 = nn.Conv2d(in_channels=128,out_channels=32,kernel_size=1) # 使用1*1卷积调小输出通道数 self.linear = nn.Linear(in_features=32*5*8,out_features=out_tokens*num_captchas) def _init_layer(self,in_channels,out_channels): '进入重复残差单元前的初始卷积层' self.layer0 = nn.Sequential(nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=(7,7),stride=1,padding=0)) return self.layer0 def _make_layer(self,in_channels,out_channels): '生成制定数目的残差网络层' # 一层两个残差单元、4个卷积层,第一个残差单元的第一层进行stride=2的特征图尺寸减半,通道数增加,其他3个卷积层不改变尺寸和通道数 self.layer_x = nn.Sequential( Block(in_channels=in_channels,out_channels=out_channels,stride=2,is_channel_adjust=True) ,Block(in_channels=out_channels,out_channels=out_channels,stride=1,is_channel_adjust=False)) return self.layer_x def forward(self,x): x = self.layer0(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.conv0(x) z = self.linear(x.view(-1,32*5*8)) return z -
训练
# 设置损失函数和优化器 loss = BCEWithLogitsLoss() net = MyResNet() opt = Adam(params=net.parameters(),lr=0.001) # 训练 epochs = 50 # 先简单训练50轮 res = [] for epoch in range(epochs): for train_x,train_y in dataloader: z = net(train_x) # print(z,train_y.dtype) loss_value = loss(z.flatten(),train_y.flatten().float()) # 二分类损失真实标签使用float类型 opt.zero_grad() loss_value.backward() opt.step() print(f'第{epoch}轮: loss_value {loss_value}') res.append(loss_value.detach()) ''' 第0轮: loss_value 0.46215111017227173 第1轮: loss_value 0.3640962839126587 第2轮: loss_value 0.24070784449577332 第3轮: loss_value 0.12332100421190262 ...... 第46轮: loss_value 3.6085257306694984e-05 第47轮: loss_value 3.699706940096803e-05 第48轮: loss_value 3.6059012927580625e-05 第49轮: loss_value 3.572095010895282e-05 '''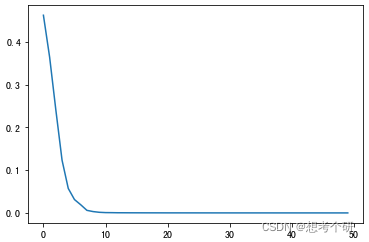
-
测试模型识别效果
# 重新生成测试验证码图像 generate_captcha(fp='./test/image',captcha_nums=20) # 测试图像的读取与预处理 def read_and_process_image(filename): im2 = cv2.imread(filename) # 灰度化 im2 = cv2.cvtColor(im2,cv2.COLOR_BGR2GRAY) # 二值化 thresh,im2 = cv2.threshold(im2,200,255,cv2.THRESH_BINARY) # opencv 形态学变换,先膨胀后腐蚀,去除小黑点 im2 = cv2.morphologyEx(im2,cv2.MORPH_CLOSE,np.ones(shape=(3,3))) return im2 # 模型预测函数 def net_predict(im): z = net(torch.div(torch.tensor(im).view(1,1,80,120),255)).detach() res = torch.argmax(z.reshape(4,5),dim=1).tolist() return res # 识别效果可视化 test_list = glob.glob('./test/image/*.png')[:10] fig,axs = plt.subplots(2,5) fig.set_size_inches(w=12,h=5) for i,image in enumerate(test_list): row = 1 if i>4 else 0 column = i-5 if i >4 else i axs[row,column].imshow(cv2.imread(image)) axs[row,column].set_xticks([]);axs[row,column].set_yticks([]) axs[row,column].set_xlabel(f'模型识别:{net_predict(read_and_process_image(image))}')大概测试了20张新生成的图像,有3张识别错了其中一个数字。















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









