







本笔记是对《王道数据结构》中各章节涉及的基础知识进行整理。本笔记主要用以应对夏令营面试中可能会问到的数据结构方面的问题,比较泛泛而谈,如果您对这些内容感兴趣,建议参考原书。大佬可自行绕路
更多章节内容请参见:保研复习——数据结构篇-CSDN博客
目录
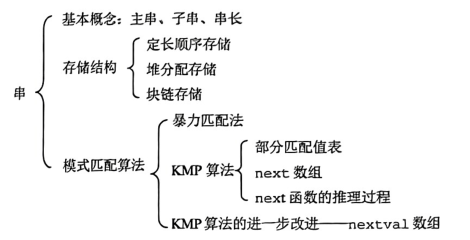
知识框架:
串的模式匹配算法:
子串的定位操作通常称为串的模式匹配,求解的是子串在主串中的位置
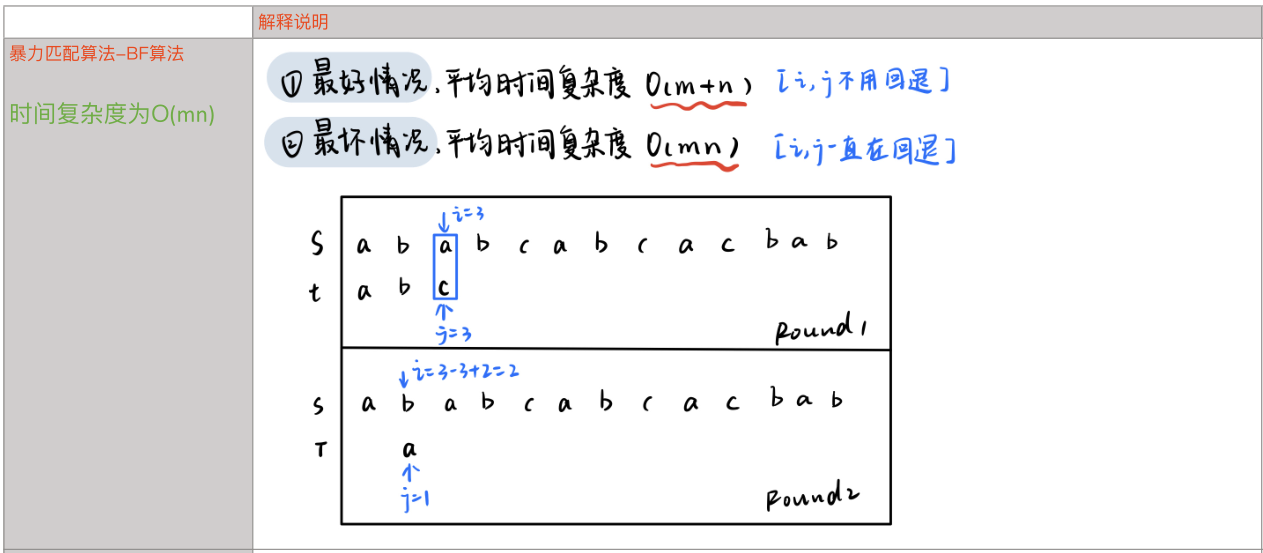
暴力匹配算法——BF算法:
步骤:
时间复杂度为O(nm),其中n和m分别代表主串和子串的长度。
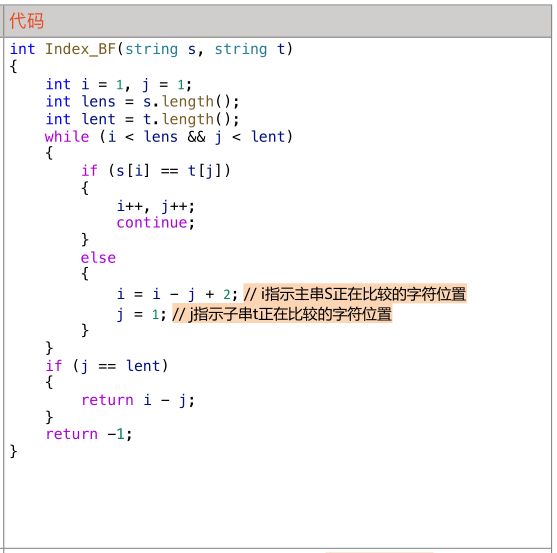
代码:
模式匹配算法——KMP算法:
在暴力匹配中,每趟匹配失败都是模式串后移一位再从头开始比较。而某趟已匹配相等的字符序列是模式串的某个前缀,这种频繁的重复比较相当于模式串不断地进行自我比竹,这就是其低效率的根源。因此,可以从分析模式串本身的结构着手,若已匹配相等的前缀序列中有某个后缀正好是模式串的前缀,则可将模式串向后滑动到与这些相等字符对齐的位置,主串主指针无须回溯,并从该位置开始继续比较。而模式串向后滑动位数的计算仅与模式串本身的结构有关,而与主串无关。
next数组的作用:
在KMP算法中,next[j]的含义是:当子串的第j个字符与主串发生失配时,跳到子串的next[j]位置重新与主串当前位置进行比较。
注意并非向右侧移动的距离,而是跳到子串的next[j]位置重新与主串的当前位置进行比较。
求解next数组的步骤:
Step1:先求PM表(代表包含当前下标在内的字符串的最长相等前后缀长度):
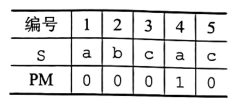
Step2:将PM表右移一位,得到next数组,左侧补-1,右侧溢出不处理
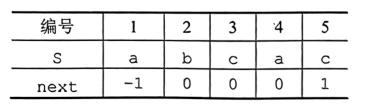
Step3:将next数组整体加1,得到我们所要的next数组
在实际KMP算法中,为了使公式更简洁、计算简单,若串的位序是从1开始的,则next数组才需要整体加1;若串的位序是从0开始的,则next数组不需要整体加1。
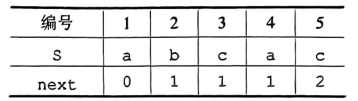
next数组的注意事项:
next数组代表的并非是当发生不匹配时子串向右移动的距离,而是跳到子串的next[j]位置(若next[1]为0则代表下标从1开始)重新与主串的当前位置进行比较。
例子一:
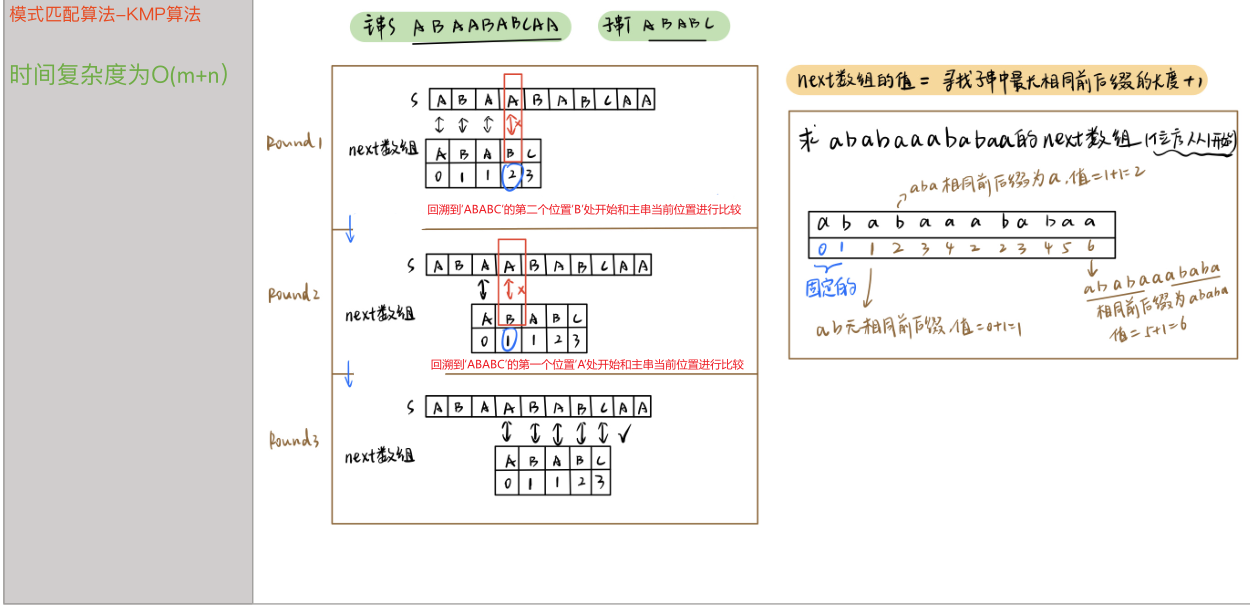
这个例子看完你可能觉得next[j]指的就是当发生不匹配时子串向右侧移动的距离,但是当你看完例二发现就不是这样子了。
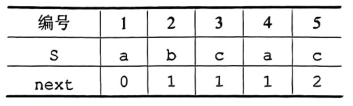
例子二:



代码:

改进的KMP算法:
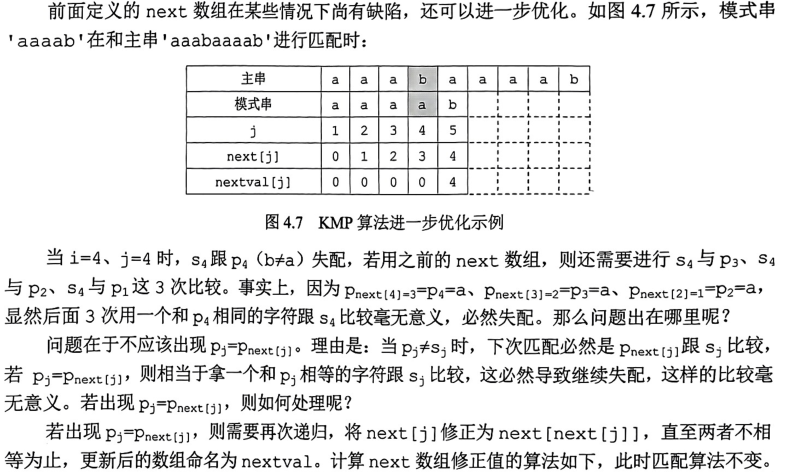
求解nextval的步骤:
1)首先求出next;
2)接着判断T[j]与T[next[j]]是否相等。
- 若相等,则nextval[j]=nextval[next[j]];
- 否则,nextval[j]=next[j];
















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









