






目录
7 体验进阶版(附带Tool以及Code Interpreter):
1 白嫖阿里云DSW:
过程可以参考下面两个博客,注意不使用的时候要记得关闭。
超详细教程教你白嫖阿里云GPU,搭建专属AI绘画平台 - 知乎
注意,通过DSW上传文件上传的文件目录为/mnt根目录。
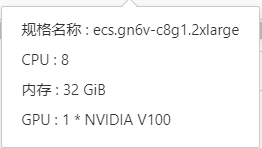
配置如下:(32G内存、16G显存)
2 下载Anaconda:
具体的安装过程参考:
Linux Anaconda下载&安装_linux下载anaconda-CSDN博客
Anaconda最好安装在linux哪个目录下:
3 创建虚拟环境(配置cuda、 torch):
Linux (Ubuntu)安装 cuda 11.7(非虚拟环境)
虚拟环境conda安装cuda11.7和cudnn和pytorch
cuda和torch对照表
Previous PyTorch Versions | PyTorch
显卡驱动版本、cudatoolkit版本、cudann版本、tensorflow-gpu版本之间的对应关系_cudatoolkit和tensorflow对应关系-CSDN博客
环境配置好后,就可以下载模型了,由于我们使用的是类似与云服务器,没有clash,所以需要在加载模型时候肯定是访问不了huggingface官网的,这就需要我们下载到服务器上。
4 下载ChatGLM3
其最后一次训练时间截止于2023年11月左右
5 下载预训练模型chatglm3-6b
注意:把下载好的 THUDM/chatglm3-6b 预训练模型文件放到 ChatGLM3 仓库目录下
至此,我们的环境和所需要的模型都准备好了
6 体验基础版(命令行、网页、API):
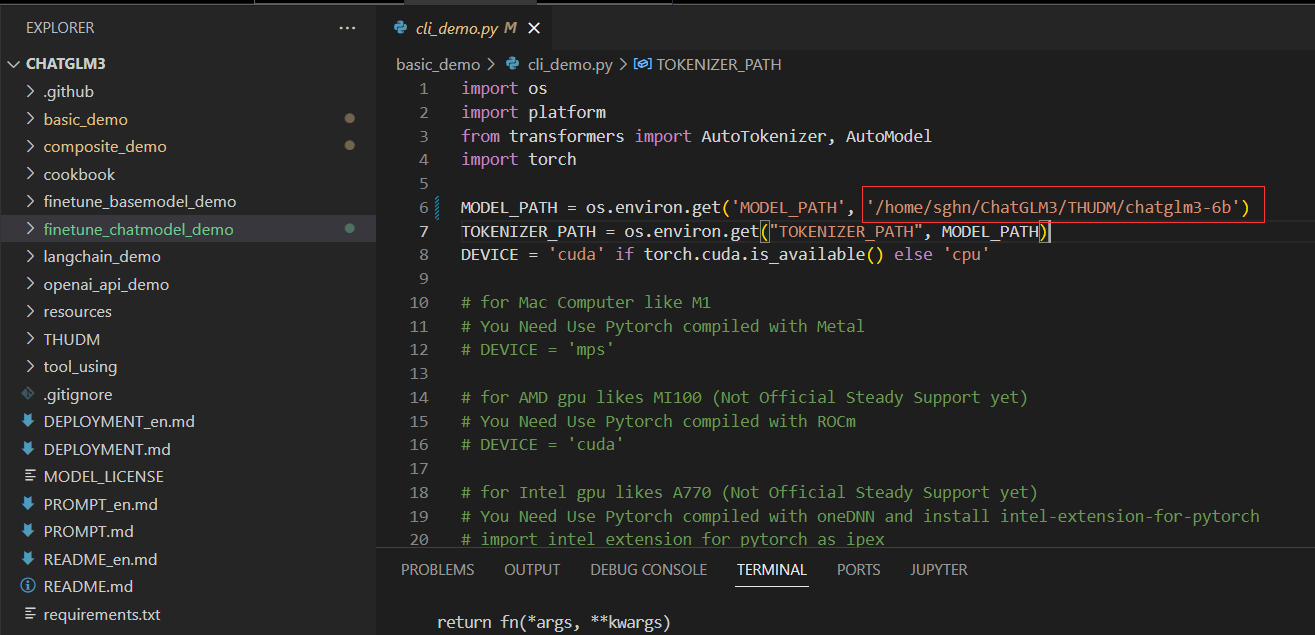
将basic_demo文件夹下的cli_demo中的路径替换为我们下载好的预训练模型路径,运行,然后就可以在命令行和ChatGLM3进行交流了。
 除此之外,我们还可以体验网页版 Demo 和 API 部署,代码和命令行的修改方法一致。
除此之外,我们还可以体验网页版 Demo 和 API 部署,代码和命令行的修改方法一致。
如果直接运行遇到错误,可以尝试在Terminal输入如下命令:
streamlit run web_demo2.py
7 体验进阶版(附带Tool以及Code Interpreter):
将client.py中的MODEL_PATH路径进行替换,替换为我们下载好的模型路径。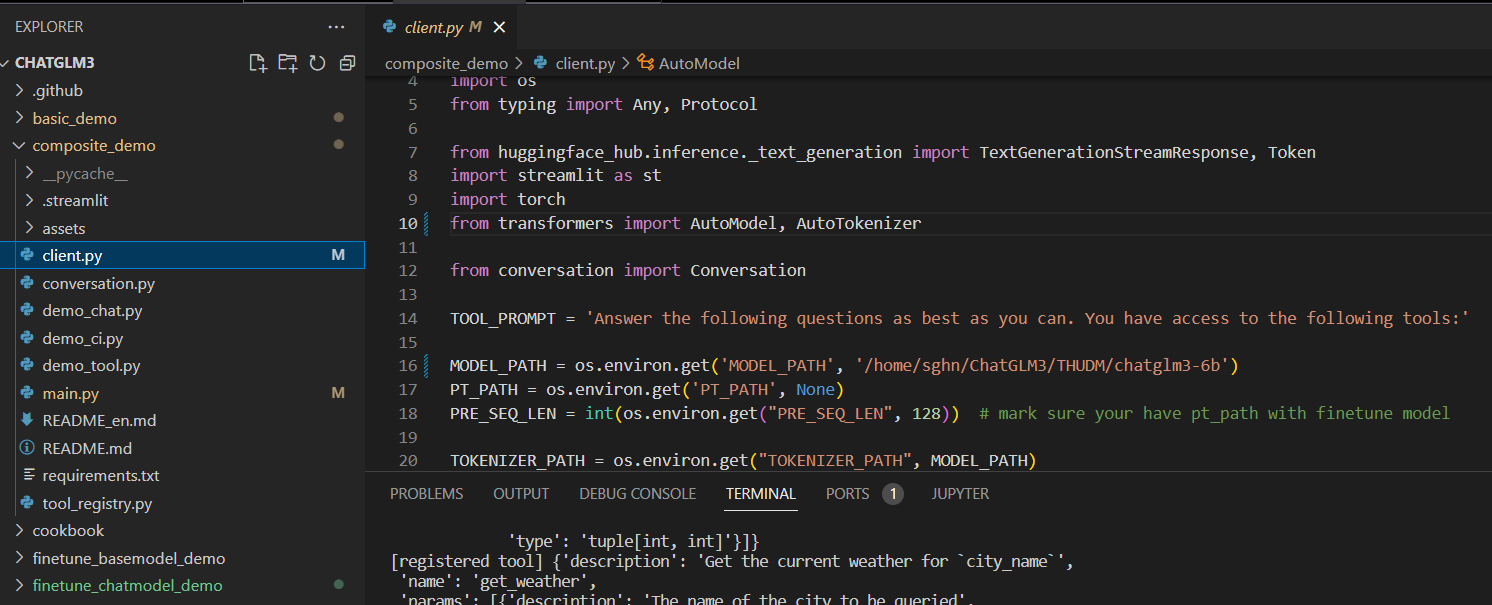
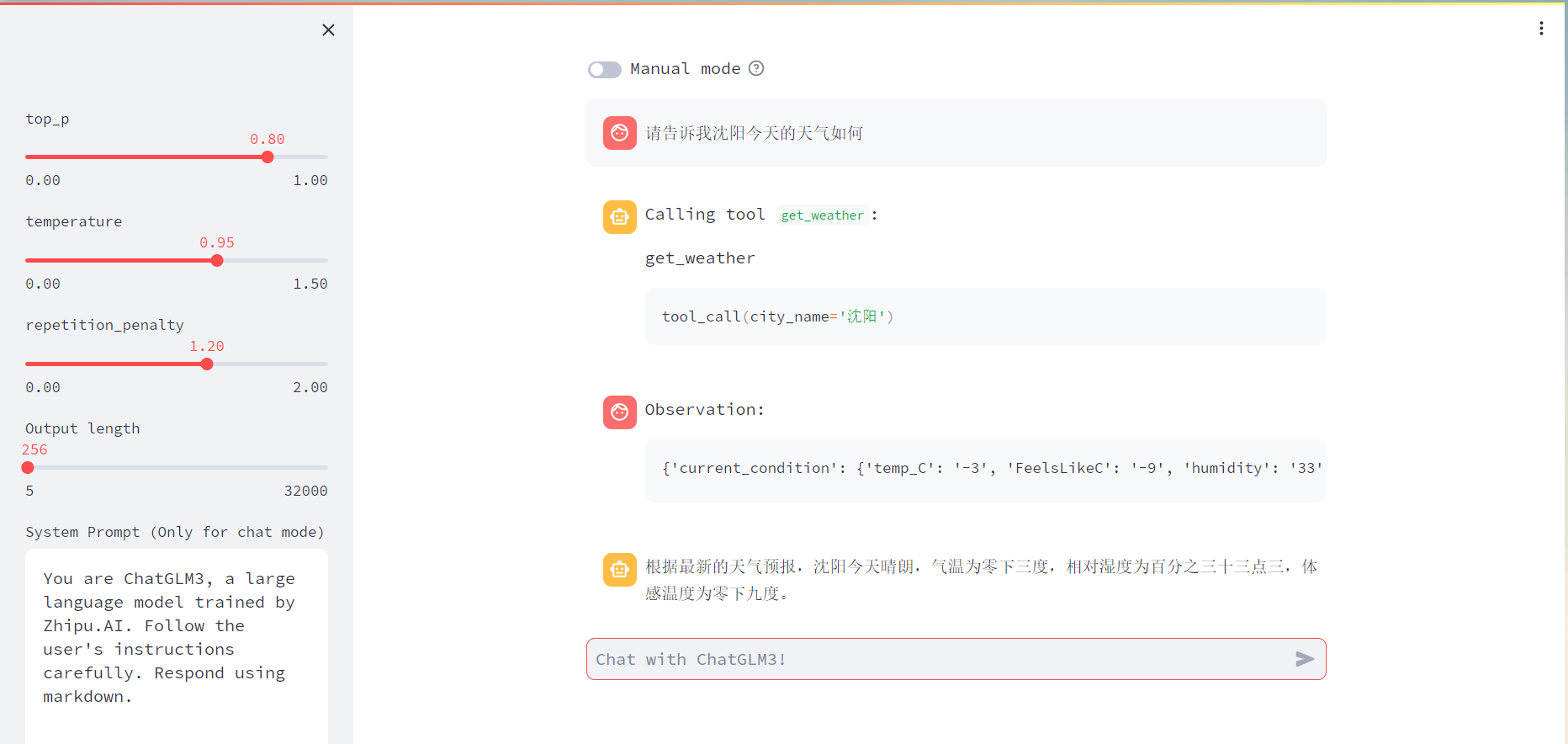
控制台输入、运行
streamlit run main.py
8 微调之前你要了解的:
8.1 四个Shell脚本文件的区别:
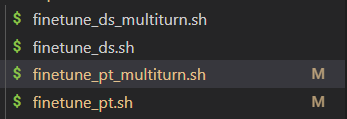
以上四个Shell脚本文件的区别是:
- ds的都是全量微调,pt的都是 P-Tuning v2 微调。
- _multitum的是多轮对话格式,另一个的是输入输出格式微调。
8.2 两种数据格式示例:
按照官网的说法,我们需要整理json格式的数据用于训练,但最后我们用于模型训练的数据其实是jsonl格式。关于数据格式官网并没有给出明确的例子,可以参考下面的格式(均为jsonl格式):
多轮对话的数据格式可以参考如下(以2条数据为例):
{"conversations": [{"role": "system", "content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown."}, {"role": "user", "content": "董宇辉"}, {"role": "assistant", "content": "董宇辉,男,1993年出生于陕西省渭南市潼关县。2015年毕业于西安外国语大学。2016年加入西安新东方,当选(新东方)当时最年轻的英语教研主管;2019年加入新东方在线,是高三英语名师并成为高三英语学科最年轻的负责人,被称为“中关村周杰伦”。现是东方甄选高级合伙人、新东方教育科技集团董事长文化助理,兼任新东方文旅集团副总裁。"}]}
{"conversations": [{"role": "system", "content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown."}, {"role": "user", "content": "你知道董宇辉吗?"}, {"role": "assistant", "content": "董宇辉,男,1993年出生于陕西省渭南市潼关县。2015年毕业于西安外国语大学。2016年加入西安新东方,当选(新东方)当时最年轻的英语教研主管;2019年加入新东方在线,是高三英语名师并成为高三英语学科最年轻的负责人,被称为“中关村周杰伦”。现是东方甄选高级合伙人、新东方教育科技集团董事长文化助理,兼任新东方文旅集团副总裁。"}]}
输入输出的数据格式可以参考:
{"prompt": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤", "response": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"}
需要注意的是,官方案例微调模型时直接将content作为prompt,summary作为response。
8.3 官网的微调示例
官网说的可能不太清楚,但肯定是最准确的,仅供参考
9 P-Tuning v2 微调:
9.1 输入输出格式的微调:
由于本人主要做多轮对话格式的微调,因此这个可以参考保姆级教程:
参考一:
ChatGLM3保姆级P-Tuning v2微调教程 - 知乎
参考二:
对于数据集,可以先使用较小的测试一下效果,比如:
{"content": "你好,你是谁", "summary": "你好,我是树先生的助手小6。"} {"content": "你是谁", "summary": "你好,我是树先生的助手小6。"} {"content": "树先生是谁", "summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"} {"content": "介绍下树先生", "summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"} {"content": "树先生", "summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
分别作为训练集和验证集即可。
最后运行inference.py,记得修改路径:
python inference.py --pt-checkpoint /home/sghn/ChatGLM3/finetune_chatmodel_demo/output/advertise_gen_pt-20231208-162720-128-2e-2/checkpoint-1000 --model /home/sghn/ChatGLM3/THUDM/chatglm3-6b
微调前:
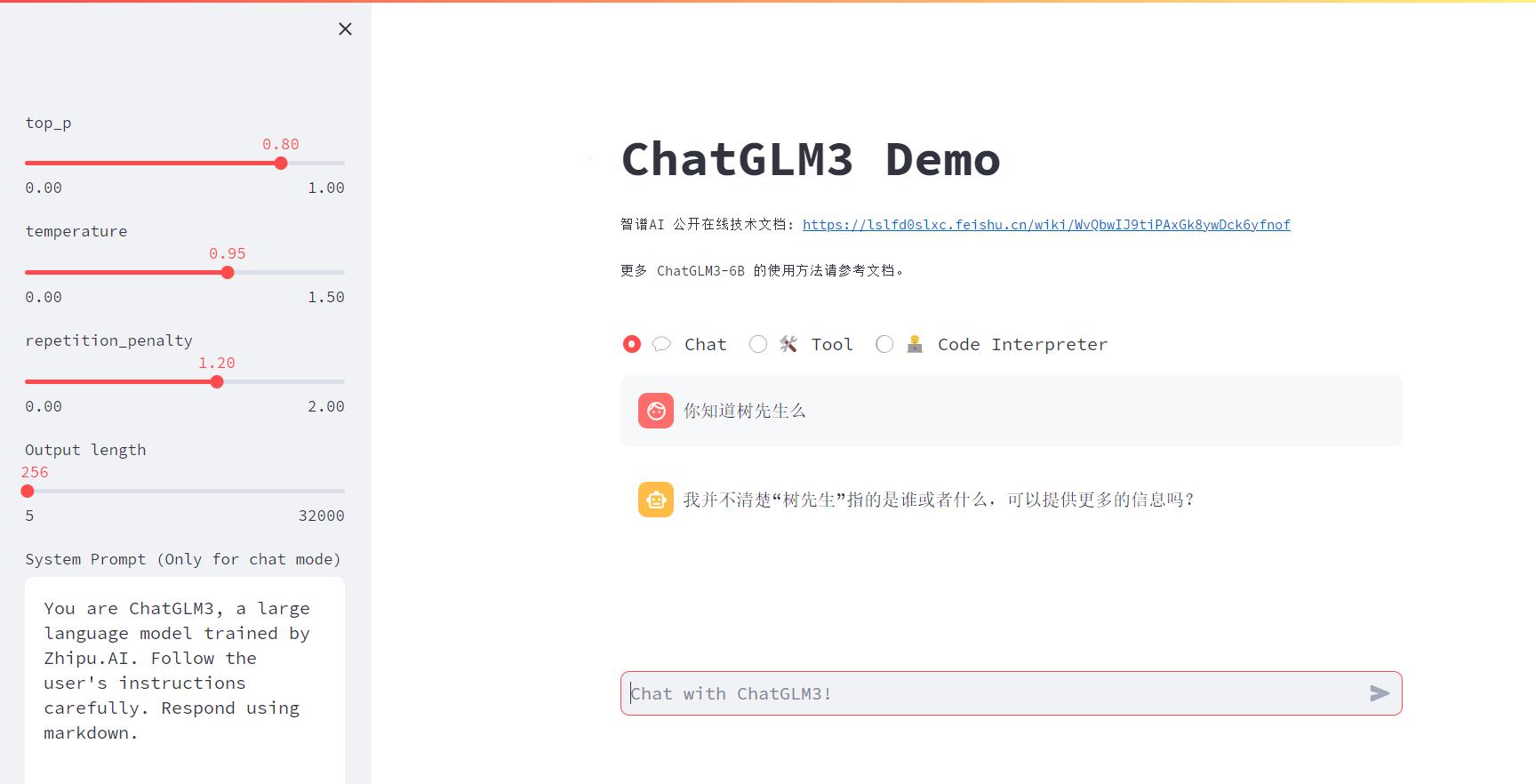
微调后:

9.2 多轮对话格式的微调:
Step1:按照jsonl的格式整理数据,例如(这是2条数据):
{"conversations": [{"role": "system", "content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown."}, {"role": "user", "content": "董宇辉"}, {"role": "assistant", "content": "董宇辉,男,1993年出生于陕西省渭南市潼关县。2015年毕业于西安外国语大学。2016年加入西安新东方,当选(新东方)当时最年轻的英语教研主管;2019年加入新东方在线,是高三英语名师并成为高三英语学科最年轻的负责人,被称为“中关村周杰伦”。现是东方甄选高级合伙人、新东方教育科技集团董事长文化助理,兼任新东方文旅集团副总裁。"}]}
{"conversations": [{"role": "system", "content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown."}, {"role": "user", "content": "你知道董宇辉吗?"}, {"role": "assistant", "content": "董宇辉,男,1993年出生于陕西省渭南市潼关县。2015年毕业于西安外国语大学。2016年加入西安新东方,当选(新东方)当时最年轻的英语教研主管;2019年加入新东方在线,是高三英语名师并成为高三英语学科最年轻的负责人,被称为“中关村周杰伦”。现是东方甄选高级合伙人、新东方教育科技集团董事长文化助理,兼任新东方文旅集团副总裁。"}]}
Step2:对数据进行检验
因为可能你整理出的jsonl数据并不符合严格的规范
比如你在使用你的数据过程中遇见'Expecting ',' delimiter'+'Invalid \escape'这两种报错,那么可以使用如下代码进行检验并修正
import json
#用于处理jsonl文件中每行数据的content中包含' " '以及包含无效字符反斜线'\'的情况
#也就是用于解决'Expecting ',' delimiter'+'Invalid \escape'这两种报错
def transform_jsonl(line):
# 存储替换后的行数据
transformed_line = line
# 查找 "content": " 的索引
content_index = transformed_line.find('"content": "')
while content_index != -1:
# 提取 content 的值
start_index = content_index + len('"content": "')
end_index = transformed_line.find('"}', start_index)
if end_index != -1:
# 提取 content 值
content_value = transformed_line[start_index:end_index]
# 将 content 值中的双引号替换为单引号
content_value = content_value.replace('"', "'").replace('\\','\\\\')
# 将原始行数据中的 content 部分替换为新的 content_value
transformed_line = transformed_line[:start_index] + content_value + transformed_line[end_index:]
# 继续查找下一个 "content": "
content_index = transformed_line.find('"content": "', end_index)
return transformed_line
def standardize_jsonl(input_file, output_file):
with open(input_file, 'r', encoding='utf-8') as infile, open(output_file, 'w', encoding='utf-8') as outfile:
for line in infile:
#事先进行一种错误处理,用'替换content中的"
line=transform_jsonl(line)
try:
# 解析 JSON 对象
data = json.loads(line)
# 重新序列化 JSON 对象,确保其符合标准 JSON 格式
standardized_line = json.dumps(data, ensure_ascii=False) + '\n'
# 写回到文件
outfile.write(standardized_line)
except json.JSONDecodeError as e:
print(f"Error decoding JSON: {line},{e}")
# 使用示例
input_file_path = "input.jsonl"#请替换为你输入的数据路径
output_file_path = "output.jsonl"#请替换为你输出的数据路径
standardize_jsonl(input_file_path, output_file_path)Step3:修改finetune_pt_multiturn.sh脚本
主要修改2个训练参数和加载数据、保存路径即可
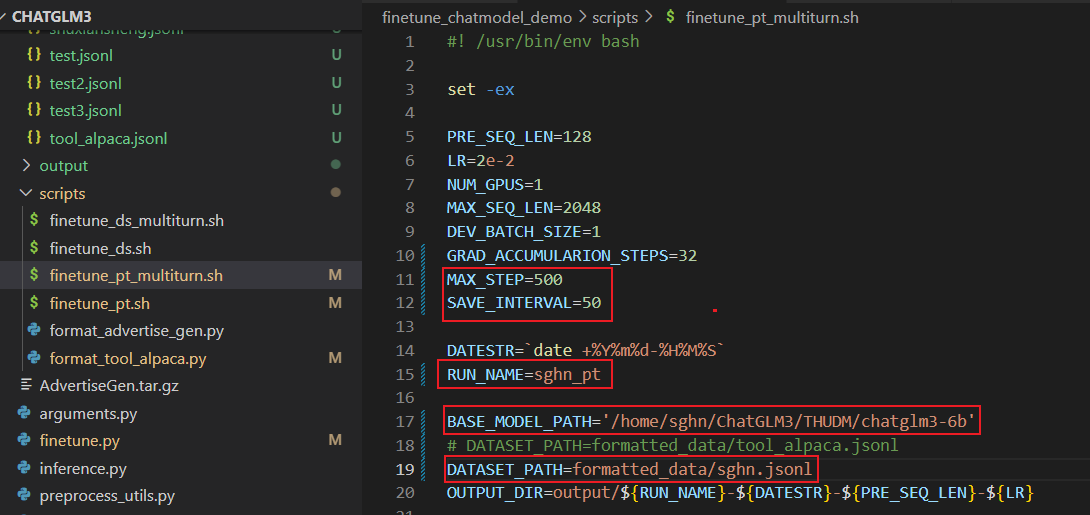
Step4:运行
在Terminal输入如下命令
cd /home/sghn/ChatGLM3/finetune_chatmodel_demo
然后
bash ./scripts/finetune_pt_multiturn.sh
Step5:使用模型,测试效果
在Terminal输入如下命令(注意替换路径):
cd ../composite_demo
MODEL_PATH="path to chatglm3-6b" PT_PATH="path to p-tuning checkpoint" streamlit run main.py
Step6:前后的效果对比
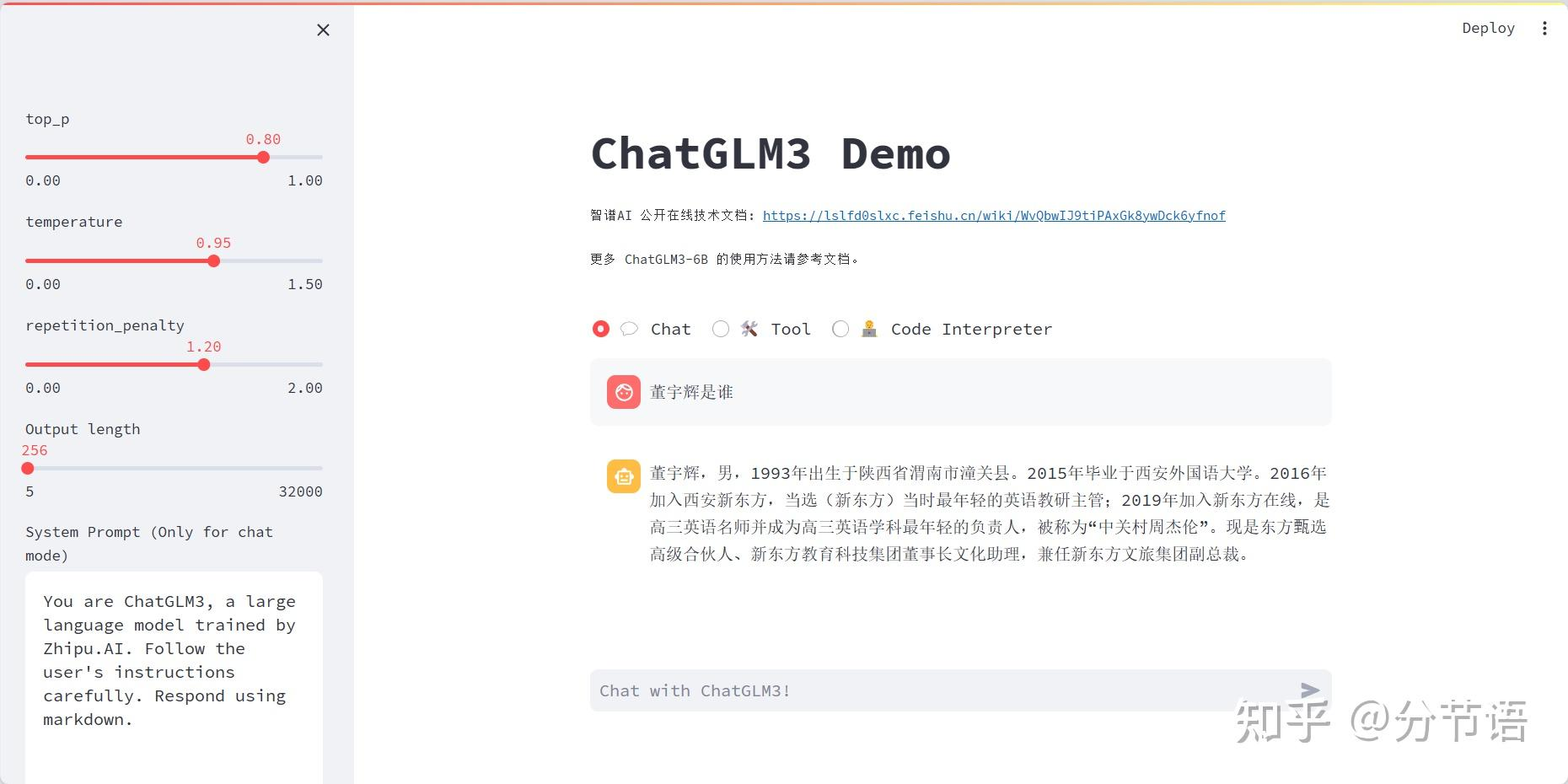
微调前:模型不知道董宇辉的资料
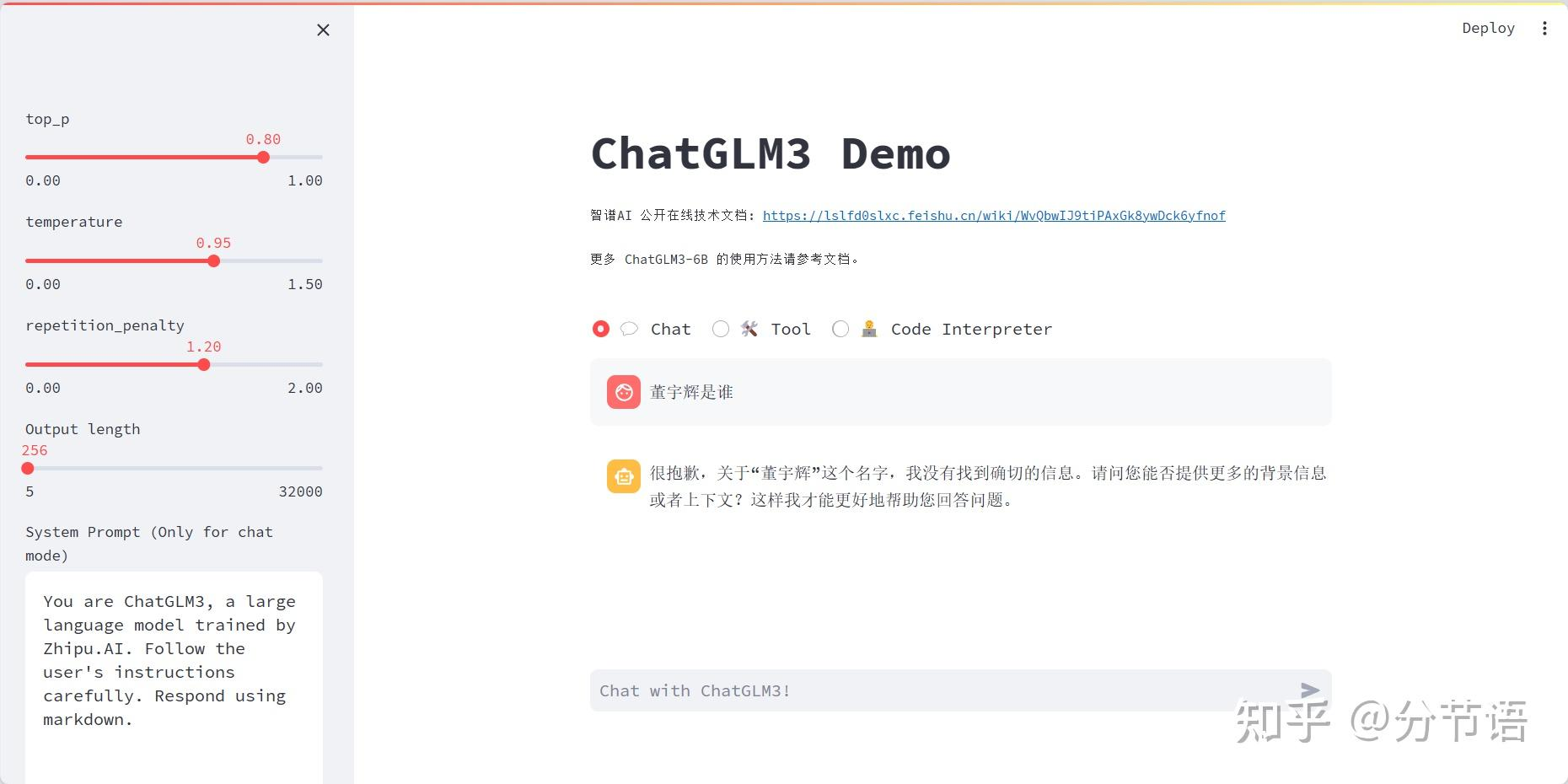
微调后:模型能够对董宇辉进行简单介绍
Step7:绘制loss曲线
在训练结束后,output文件夹下有一个trainer_state.json的训练日志,我们可以使用这个绘制loss曲线
代码如下:
import json
import matplotlib.pyplot as plt
def plot_global_step_loss(json_file_path, save_path=None):
with open(json_file_path, 'r') as file:
data = json.load(file)
log_history = data['log_history'][:-1] # 排除最后一个总结数据
global_steps = [entry['step'] for entry in log_history]
loss_values = [entry['loss'] for entry in log_history]
plt.plot(global_steps, loss_values, marker='.', linestyle='-', color='orange')
plt.title('Loss_curve')
plt.xlabel('Global Step')
plt.ylabel('Loss')
plt.grid(True)
if save_path:
plt.savefig(save_path)
else:
plt.show()
# 替换你的JSON文件路径
json_file_path = 'train_log.json'
# 替换为你希望保存的图片路径,或者保持为 None,仅显示图形而不保存
save_path = 'Loss_curve.png'
plot_global_step_loss(json_file_path, save_path)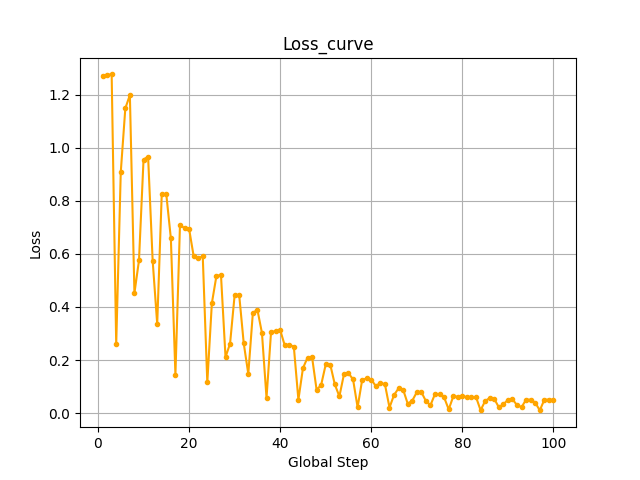
Step8:参考文献
如果以上步骤仍然不够清晰,可以参考ChatGLM3-6B 微调实践,更新模型知识 - 知乎
10 显存不够:
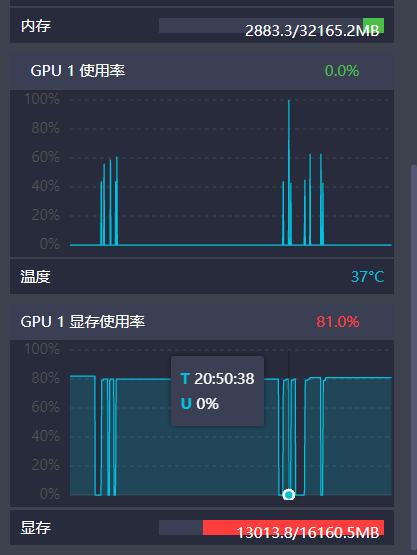
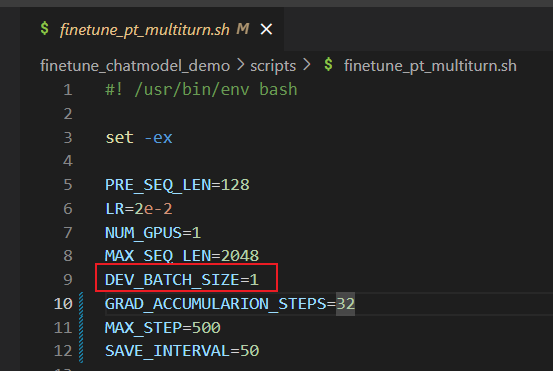
我们微调训练的时候可能会遇到显存不够引发的报错,这时候只能选择降低batch_size(用时间换空间了)或者调节一下其他参数,将显存降到16G以下就可以训了
11 存在的问题:

我们可以直观地看到,在粗糙的微调后,灾难性遗忘非常严重,但说明了微调的可行性。相对于LORA微调,P-tuning v2在大模型微调过程中出现的知识遗忘问题要更严重。
















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









