







本笔记是对《王道数据结构》中各章节涉及的基础知识进行整理。本笔记主要用以应对夏令营面试中可能会问到的数据结构方面的问题,比较泛泛而谈,如果您对这些内容感兴趣,建议参考原书。大佬可自行绕路
更多章节内容请参见:保研复习——数据结构篇-CSDN博客
目录
知识框架:

树:
树的基本概念:
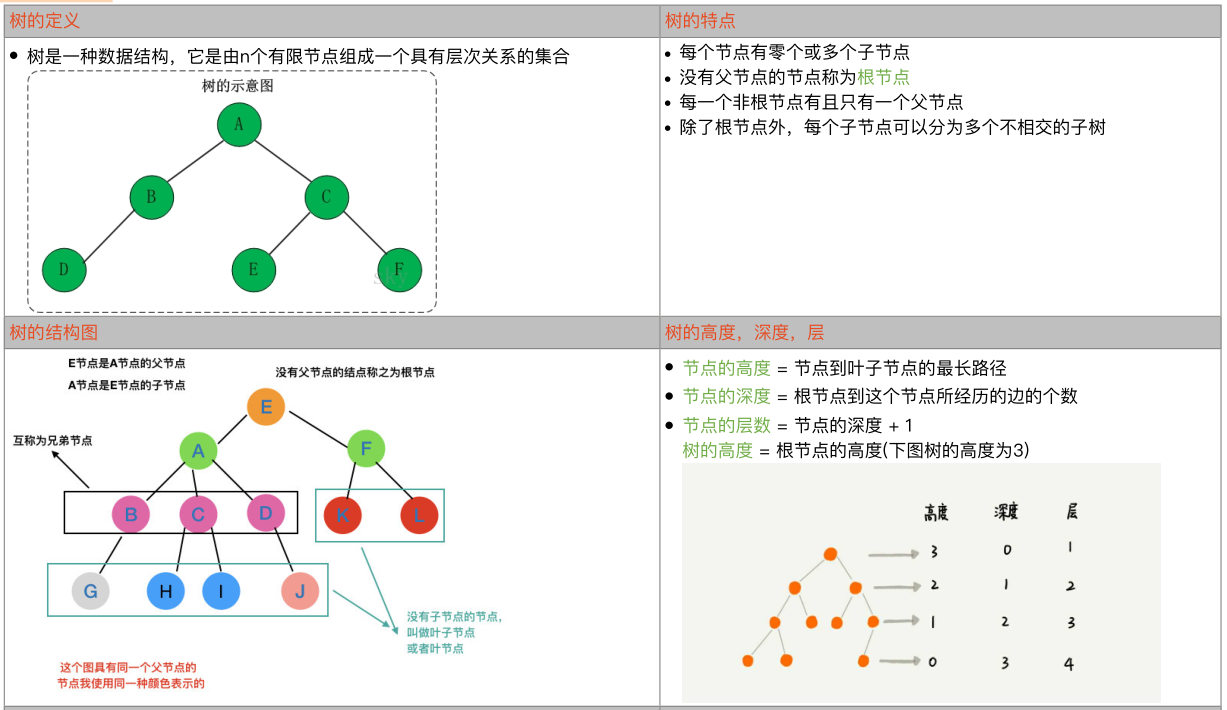

树的存储结构(树的表示):
包含双亲表示法、孩子表示法以及孩子兄弟表示法。

树、树林与二叉树的转换:
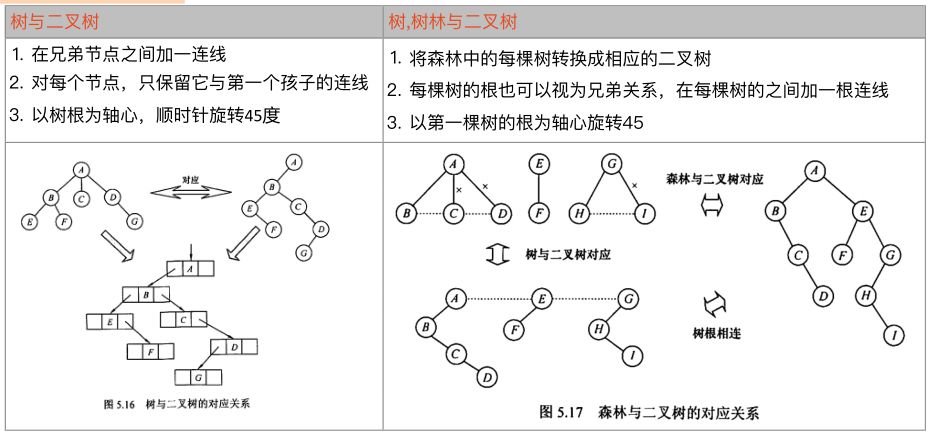
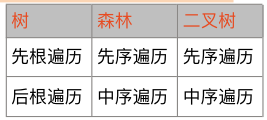
树和森林的遍历对应关系:
二叉树:
二叉树的基本概念:

特殊的二叉树:
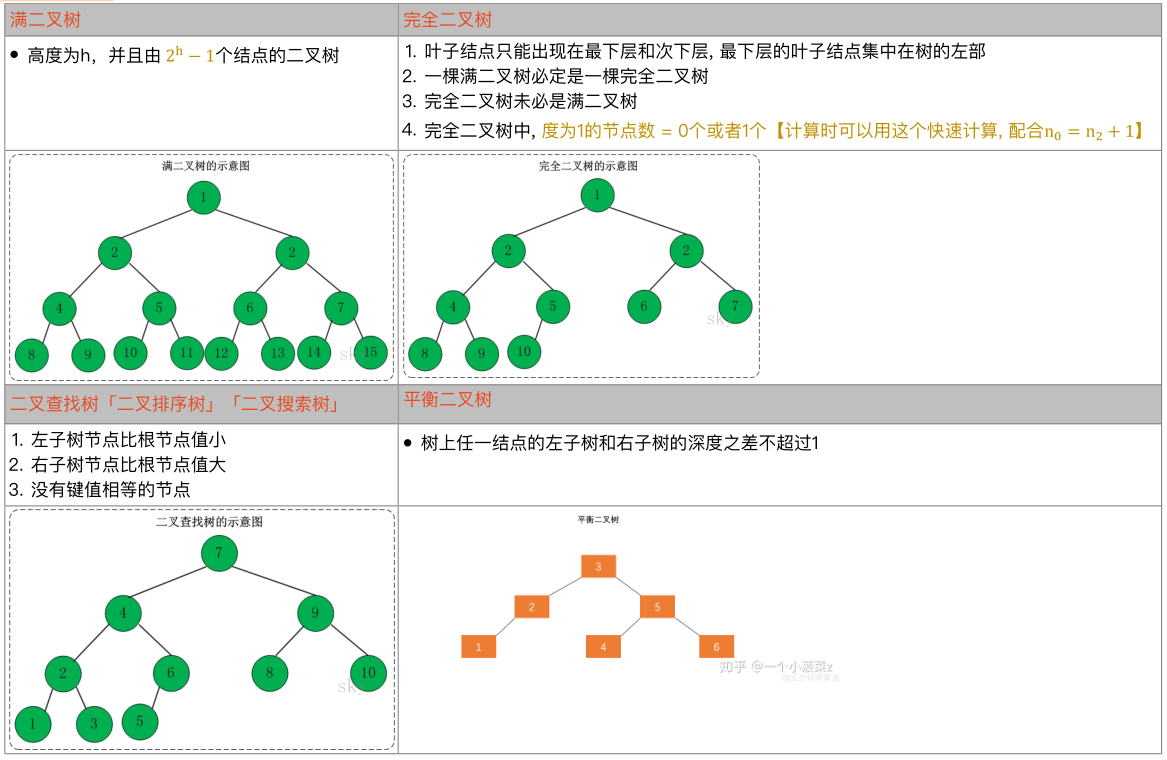
二叉树的存储结构:
包含顺序存储结构和链式存储结构

二叉树的实现:
二叉树的代码表示:

二叉树的4种遍历方法:
包含前序、中序、后序和层序

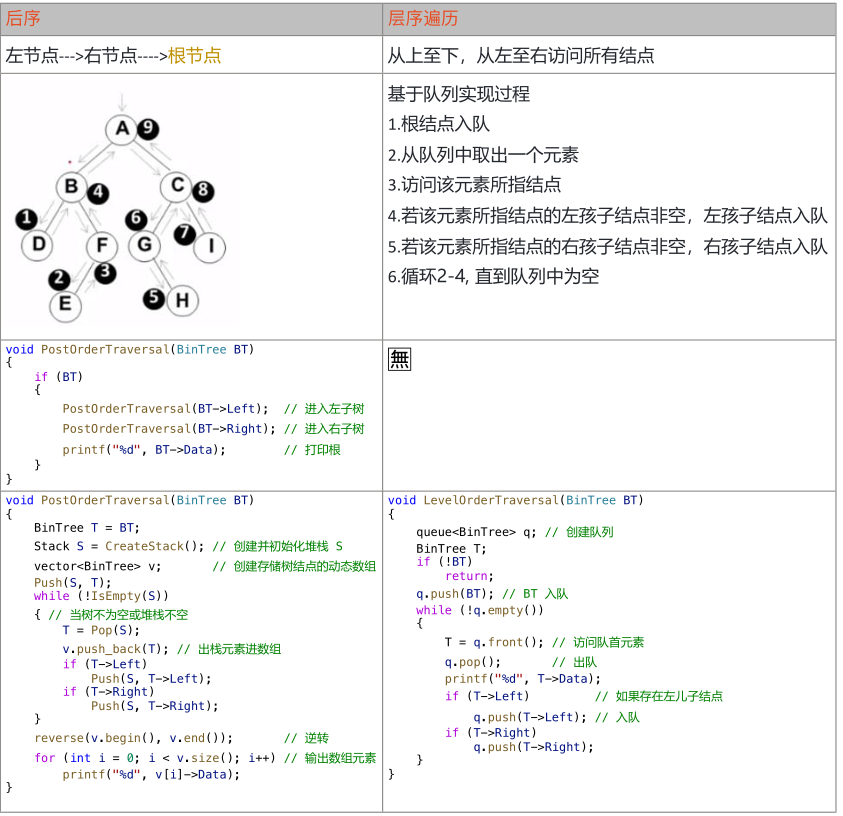
3种遍历实例:

常考的结论:
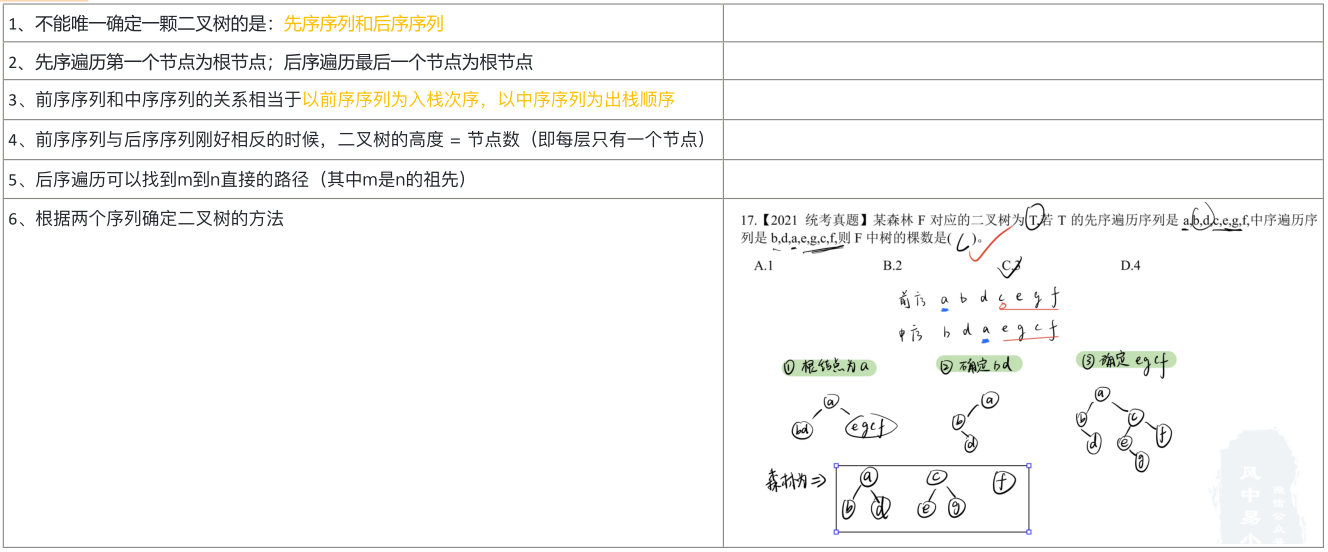
在树的遍历中,前序遍历(preorder)和后序遍历(postorder)本身并不能唯一确定一个二叉树。这是因为这两种遍历不提供足够的信息来明确节点的层次结构和左右子树的区分。
线索二叉树:
在二叉树的链式存储结构中,有不少结点存在空指针域,而线索二叉树正是利用了这些空指针域,存放结点在某种遍历次序下的前驱和后继结点的地址。
我们把这种指向前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,相应的二叉树就是线索二叉树。
其实线索二叉树,等于是把一棵二叉树转变为一个双向链表,这样就为我们的插入删除结点、查找某个结点都带来了方便。可以说,线索二叉树的目的是加快对二叉树的遍历。
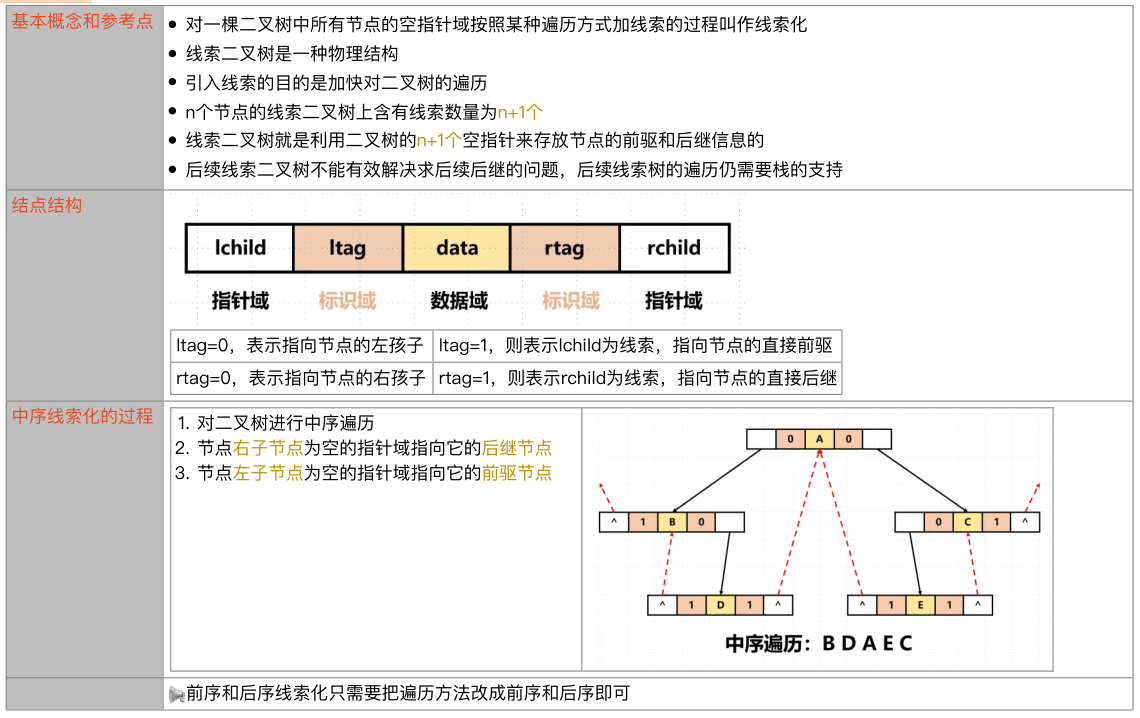
树和二叉树的应用:
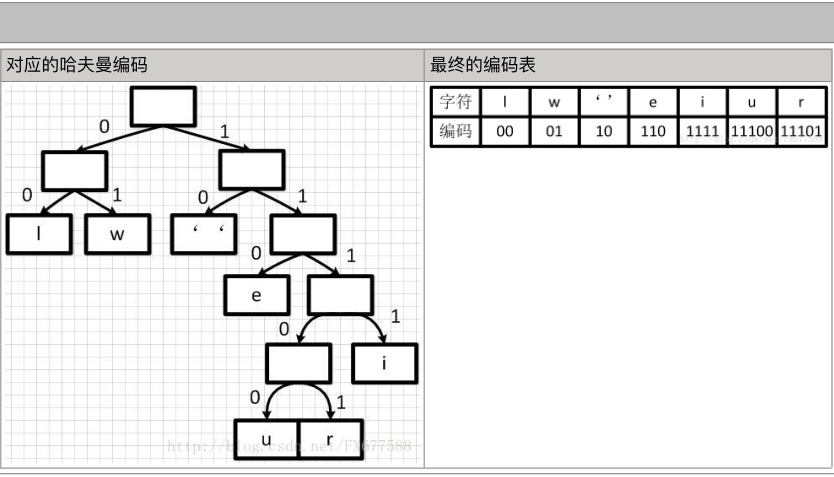
哈夫曼树/最优二叉树:

哈夫曼编码:
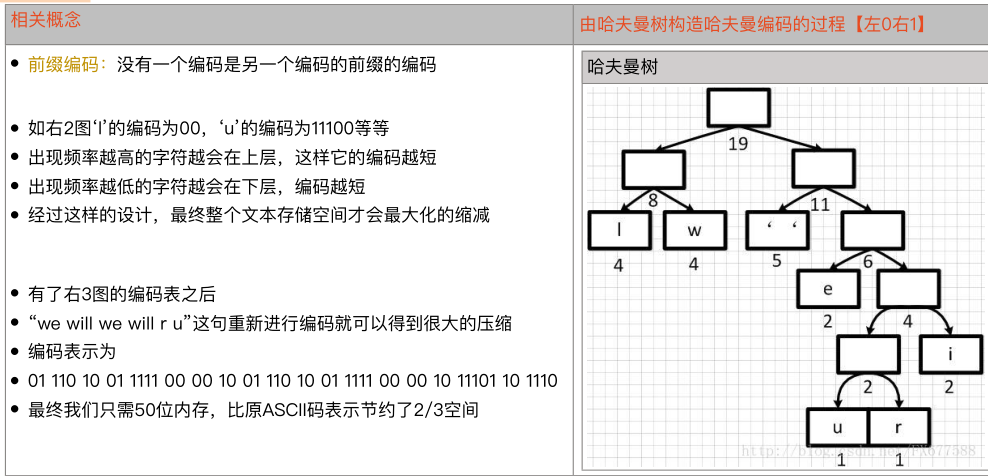
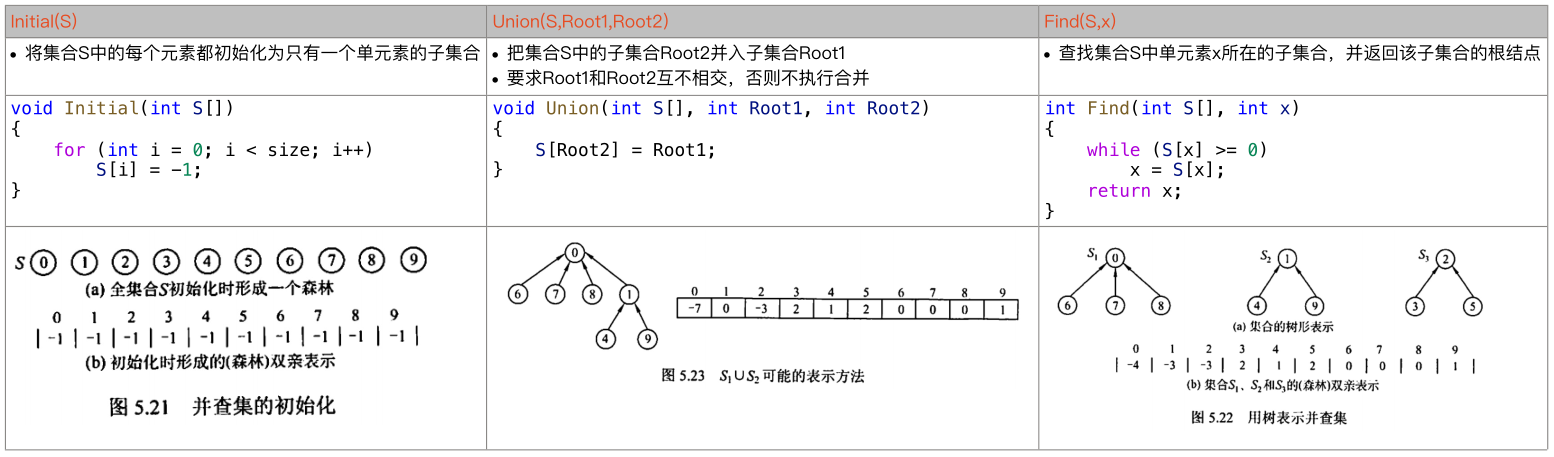
并查集:
并查集(Union-Find Set),也称为不相交集合(Disjoint Set),是一种用于管理和合并不相交集合的数据结构,可以用于检测一个图中的连通分量个数等问题。

















 3920
3920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









