







目录
1 量化的本质:

4bit表示的范围是[-128,127]

2 4bit量化:
4bit表示的范围是[-8,7]

3 线性量化:

量化效果和数据的分布方式息息相关

4 QLoRA:
QLoRA 的核心思想是在大型语言模型的微调过程中,采用 4-bit 量化 来压缩模型的权重,从而减少显存的占用,并使用 LoRA 技术来对模型进行微调。
具体来讲,QLoRA实现了3件事儿,分别是:
- NF4量化
- 双重量化
- 分页优化器
4.1 NF4量化
4.1.1 分位数量化:


4.1.2 完整实例:
看了上面那么多,可能有点懵,其实看下面这个例子即可:
- 先对原始数据进行归一化;
- 接着将其与NF4进行匹配得到临近表示;
- 再将其按表中顺序映射为[0,15]即可。

4.2 双重量化:

4.3 分页优化器:
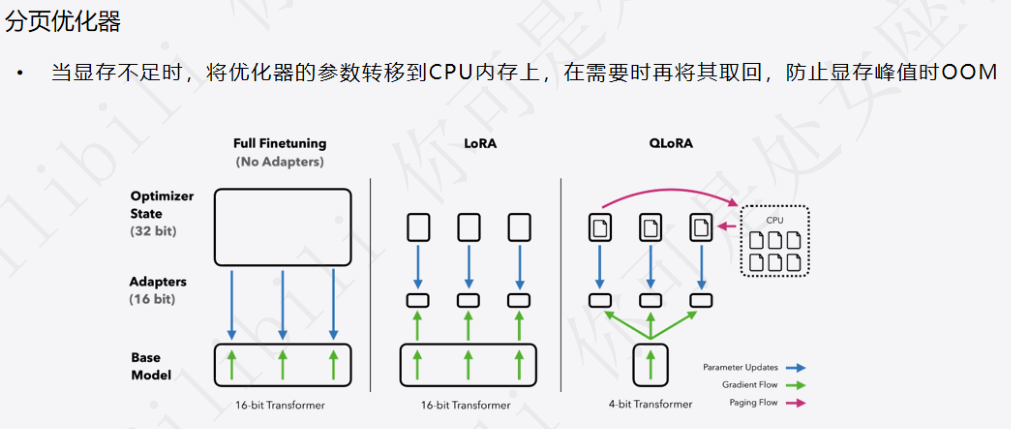
5 代码实战演练:
5.1 导包
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer5.2 加载数据集
ds = Dataset.load_from_disk("../data/alpaca_data_zh/")
ds5.3 数据集处理
tokenizer = AutoTokenizer.from_pretrained("D:/Pretrained_models/modelscope/Llama-2-7b-ms")
tokenizer
tokenizer.padding_side = "right" # 一定要设置padding_side为right,否则batch大于1时可能不收敛
tokenizer.pad_token_id = 2 # 半精度训练时,正确加入eos_token后,要将pad_token_id也设置为eos_token_id,否则会因为溢出问题导致模型无法正常收敛
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ", add_special_tokens=False)
response = tokenizer(example["output"], add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.eos_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.eos_token_id]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds5.4 创建模型
import torch
# 多卡情况,可以去掉device_map="auto",否则会将模型拆开
model = AutoModelForCausalLM.from_pretrained("D:/Pretrained_models/modelscope/Llama-2-13b-ms", low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16, device_map="auto", load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True)bnb_4bit_quant_type="nf4":指定了使用 NF4 量化类型
bnb_4bit_use_double_quant=True:这个参数启用了 双重量化
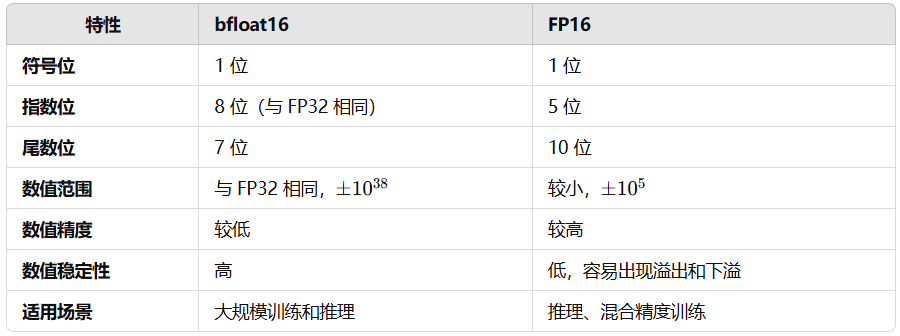
bnb_4bit_compute_dtype=torch.bfloat16:电脑的卡较好情况下可以使用bfloat16,不太好就可以使用FP16,FP16有时候会出现一些溢出的问题
两者的区别:
for name, parameter in model.named_parameters():
print(name)model.config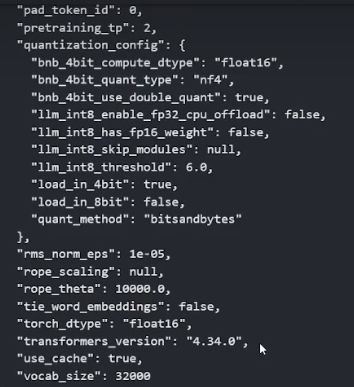
5.4.1 配置文件
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(task_type=TaskType.CAUSAL_LM)
config5.4.2 构建模型
model = get_peft_model(model, config)model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法model.print_trainable_parameters()![]()
5.5 配置训练参数
args = TrainingArguments(
output_dir="./chatbot",
per_device_train_batch_size=1,
gradient_accumulation_steps=32,
logging_steps=10,
num_train_epochs=1,
gradient_checkpointing=True,
optim="paged_adamw_32bit"
)optim="paged_adamw_32bit":使用32位分页优化器
5.6 创建训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds.select(range(6000)),
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)数据集较大,这里只选前6000条做训练
5.7 模型训练
trainer.train()5.8 模型推理
model.eval()
ipt = tokenizer("Human: {}\n{}".format("你好", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
tokenizer.decode(model.generate(**ipt, max_length=512, do_sample=True, eos_token_id=tokenizer.eos_token_id)[0], skip_special_tokens=True)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









