







目录
2.2 视觉定位 (With Visual Grounding)
2.3 视觉分割 (With Visual Segmentation)
2.3.3 Glamm(Pixel Grounding Large Multimodal Model)
2.4 视频和3D细粒度多模态语言模型 (Video and 3D Fine-Grained MLLM)
2.4.1 PG-Video-LLaVA和MotionEpic
2.4.3 3D Fine-Grained Reasoning
3.2 统一架构设计 (Unified Architecture Designs)
3.3 用于长视频分析的多模态语言模型 (MLLM For Long Video Analysis)
3.4 带有MOE设计的多模态语言模型 (MLLM With MOE Design)
0 完整Tutorial内容
本文为"⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程"——第三部分的学习笔记,完整内容参见:
⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程-CSDN博客

1 内容讲解安排
在这部分的讲解中,内容围绕着细粒度多模态语言模型设计和高级多模态语言模型设计展开。

2 细粒度多模态语言模型设计
2.1 概述(Overview)

这种模型不仅关注图像和文本,还关注图像的局部区域以及与之相关的文本。这意味着输入和输出不仅是图像和文本,还包括区域和像素级的信息。
通过在像素或区域层面理解信息,可以增强多模态 MLLM 设计中的互动特性,这对于实际产品非常重要。
2.1.1 主要动机

- 新特性:能够参考特定的区域或对象。比如,可以从聊天内容中识别出图像中的特定部分。
- 应用扩展:例如,增强现实(AR)或虚拟现实(VR);医学图像分析。
- 研究探索:避免幻觉,为设计新的多模态模型开辟道路,探索如何平衡文本和位置感知能力。
2.1.2 在LLM之前细粒度多模态语言模型的概述
在LLM之前,视觉语言任务(如视觉定位、图像分割等)大多由语言驱动,并且许多相关的工作都来自视觉社区。

在RM领域,除了传统的图像任务外,还可以进行问答任务(例如,给定图像和问题,输出图像中的相关区域)。
视觉问答:例如,给定一个问题(如图像中的某个类别),输出一个边界框或区域掩码。模型需要理解图像并回答具体的问题。
2.1.3 代表性工作
- GLIP(Grounded Language-Image Pretraining):首次提出了区域级别的图像文本配对和对齐,使用定位损失来确保区域和文本的对齐。
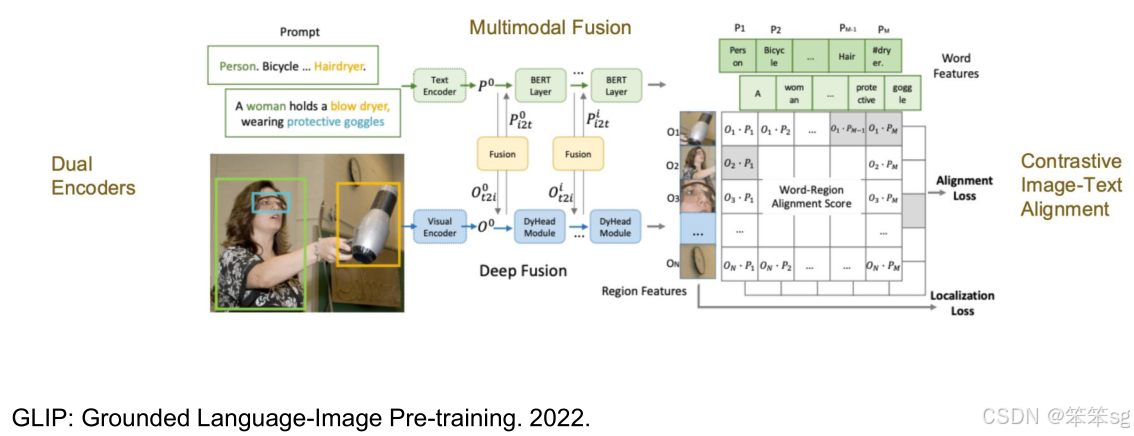
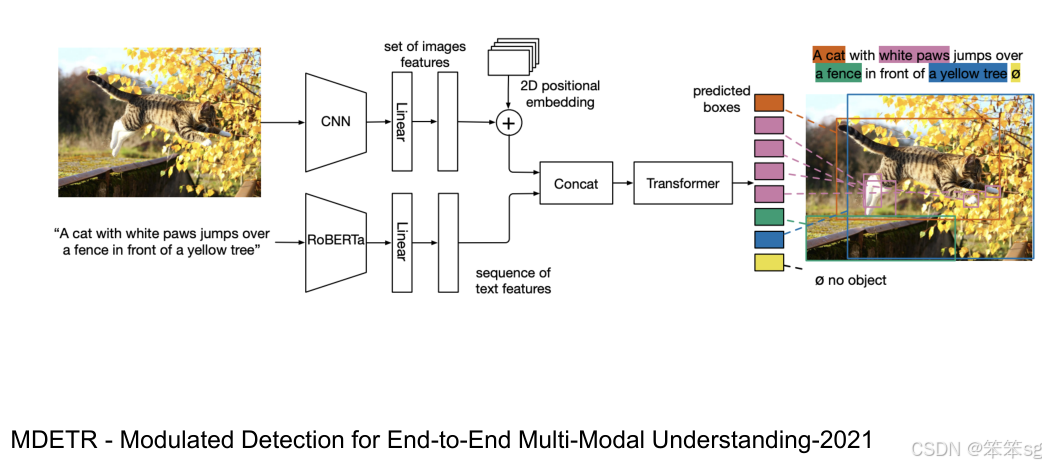
- MDETR(Modular Detection Transformer):通过结合视频和语言部分的两种架构,进行目标查询和文本特征的融合,从而进行视觉定位和目标检测。
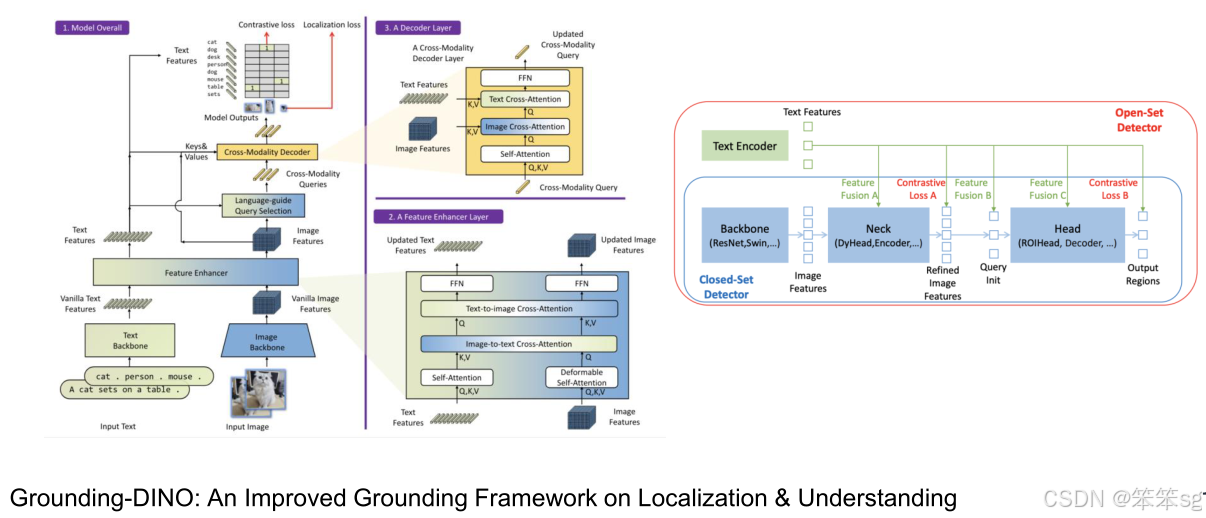
- Grounding Dino:使用更强的骨干网络和解码器,增强了特征融合,改善了定位精度。
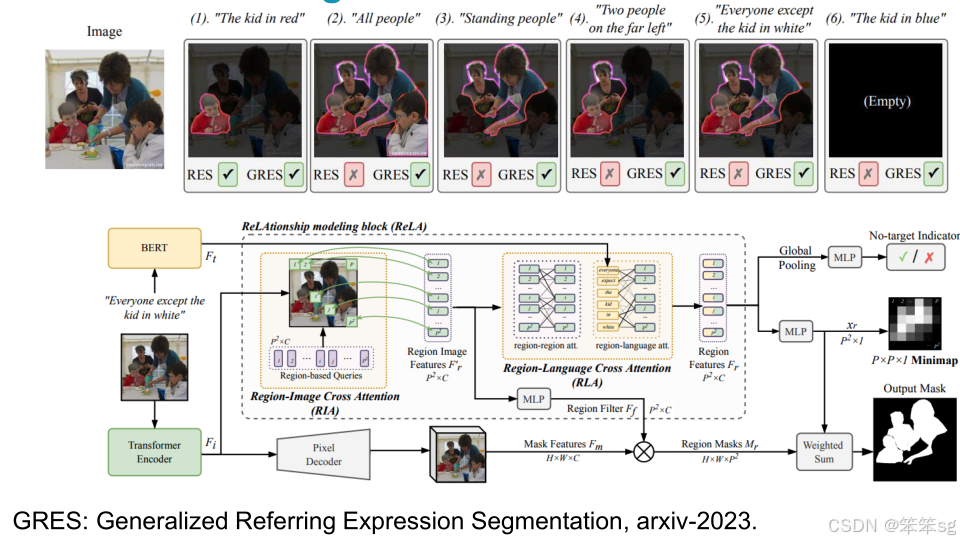
- GRES(Generalized Referring Expression Segmentation):通过语言提示生成图像区域的掩码,用于识别和定位特定区域。
用户输入图像(可能指定一个区域),LLM根据其理解输出内容,将视觉内容固定到图像的特定像素级区域。
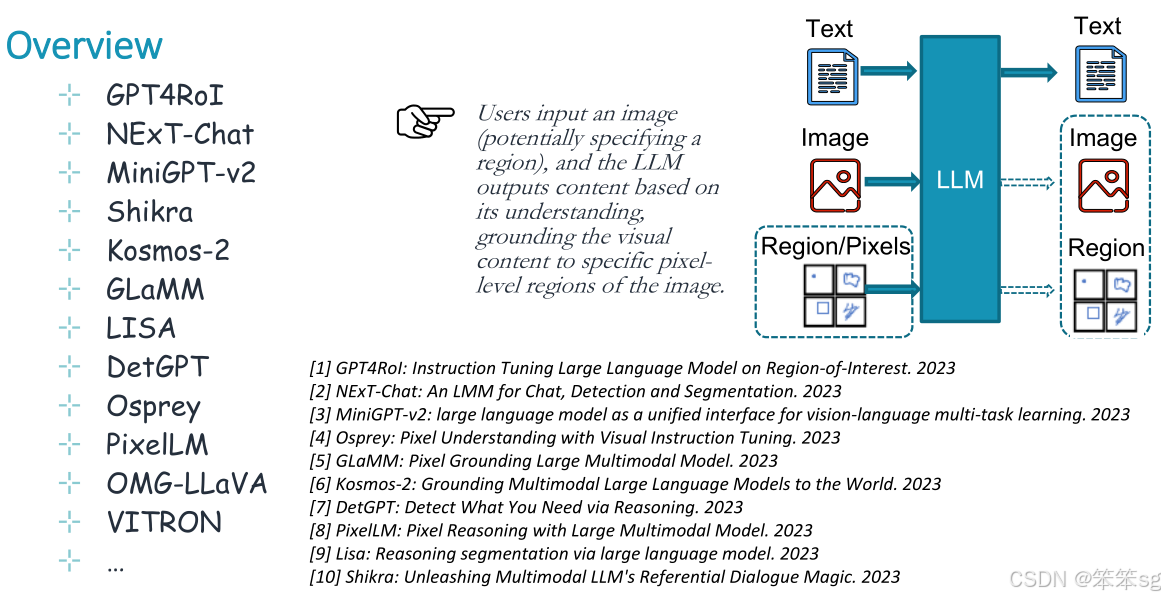
2.2 视觉定位 (With Visual Grounding)
2.2.1 Kosmos-2 and Shikra
- Kosmos-2:该方法通过多模态模型(MLLM)直接输出与参考语言相对应的物体定位框(BBox)。
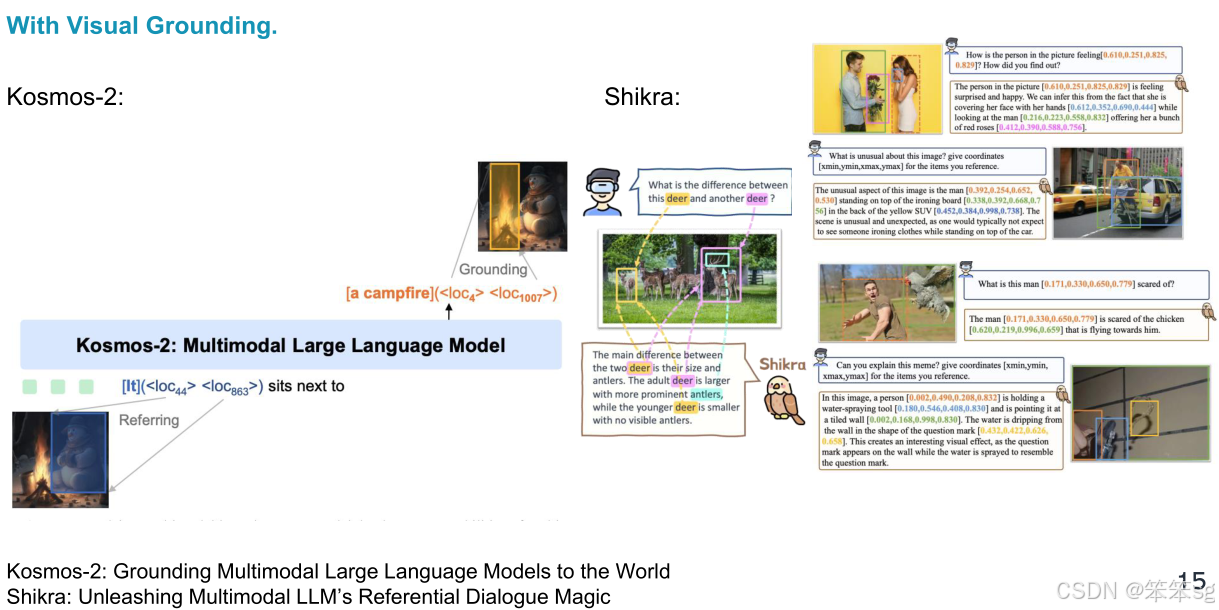
- Shikra:该方法对文本进行新的表示处理,例如通过标准化坐标格式,使得系统能够直接输出标准化后的坐标,实现定位的精准输出。
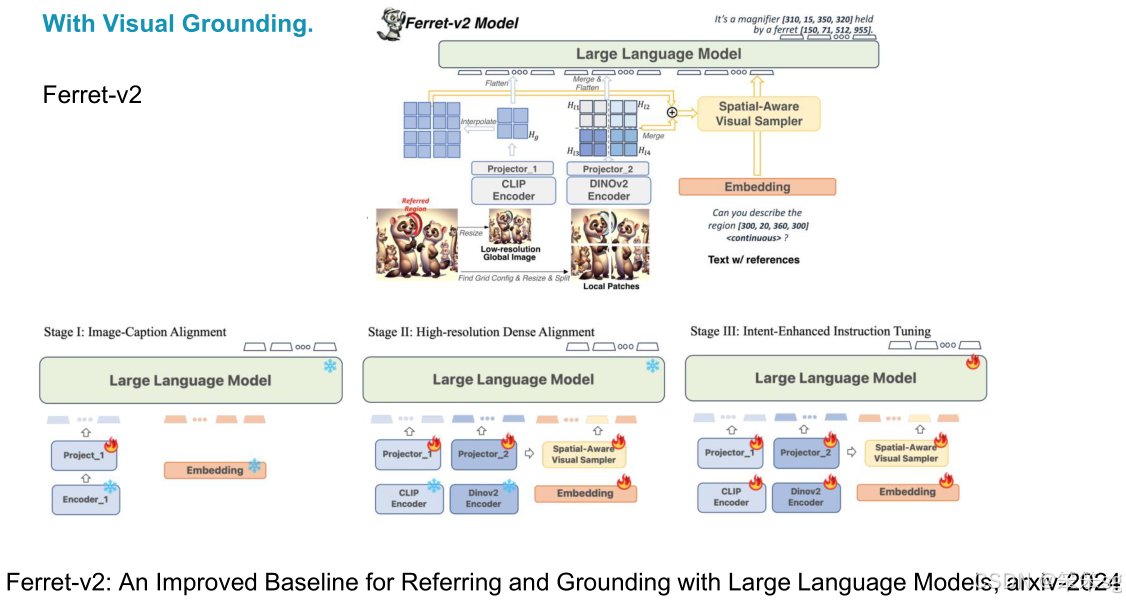
2.2.2 Ferret
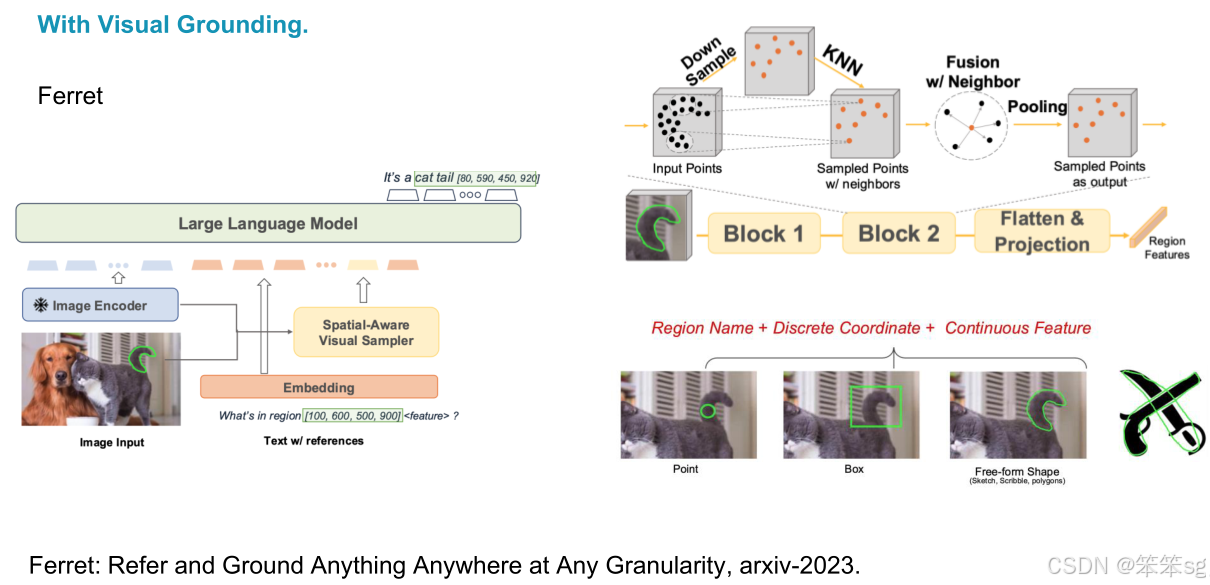
- Ferret 是来自IPO团队的开创性工作,旨在实现“任何地方、任何物体、任何精度”的引用定位。
- 核心思想:提出了一个特殊的视频采样器,结合更多的功能性视频特征。通过将区域特征作为语言标记输入到语言模型,从而获得更强的定位能力。
- 他们使用了强大的编码器,并提出了一个新的增强数据集,包含了图像-文本对齐、高分辨率图像对齐等多种数据增强方法,显著提升了视觉定位的能力。
2.2.3 Groma
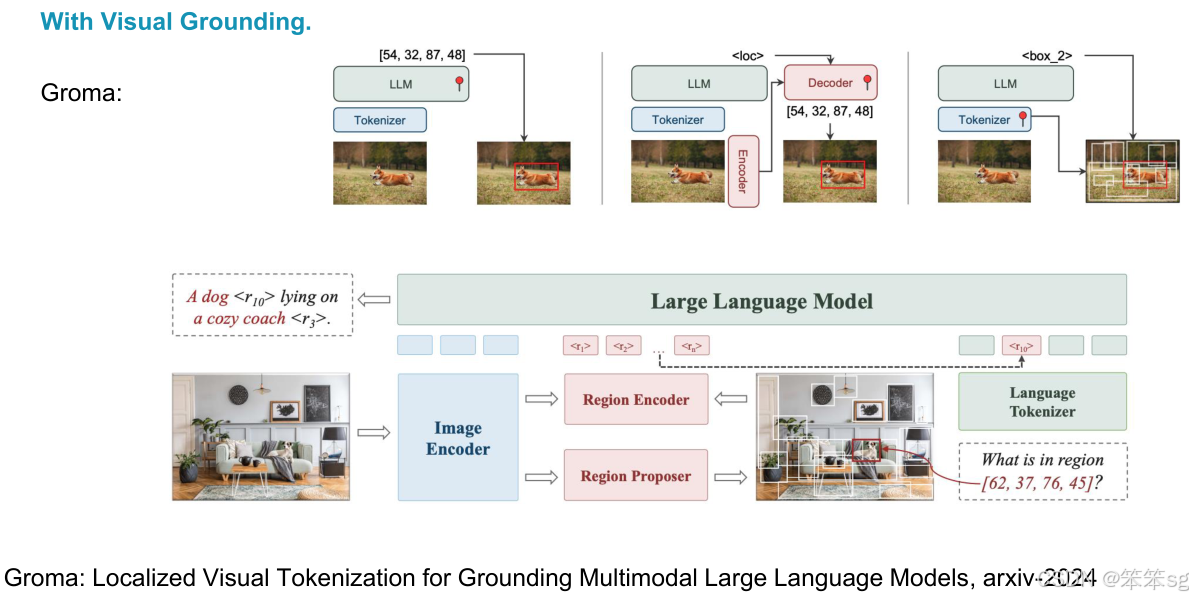
- Groma提出了一种新的元文本设计方法,旨在解耦定位器(localizer)和RM(reference model)。
- 工作原理:选择预处理的定位器输出,使用预训练的物体检测器作为定位器,并通过语言模型选择对应的特征或框。
- 性能提升:这种方法在定位、引用、甚至聊天(Chat)任务中均表现出了强大的能力。通过结合图像描述和定位框,系统可以将图像中的每个物体与其对应的文本描述和边界框进行关联,从而增强理解能力。

2.3 视觉分割 (With Visual Segmentation)
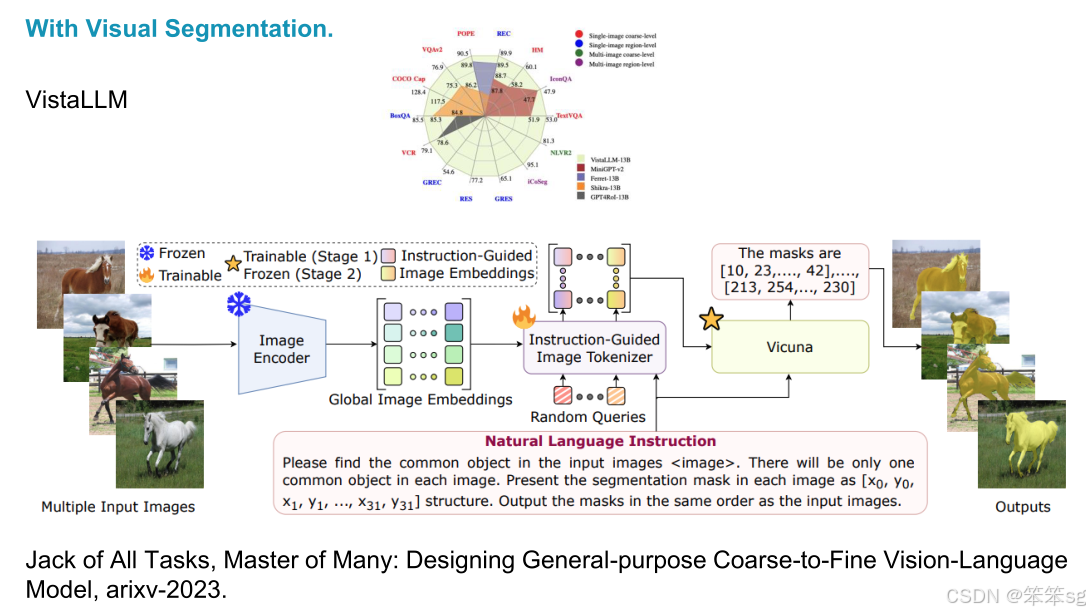
2.3.1 VistaLLM
2.3.2 LISA
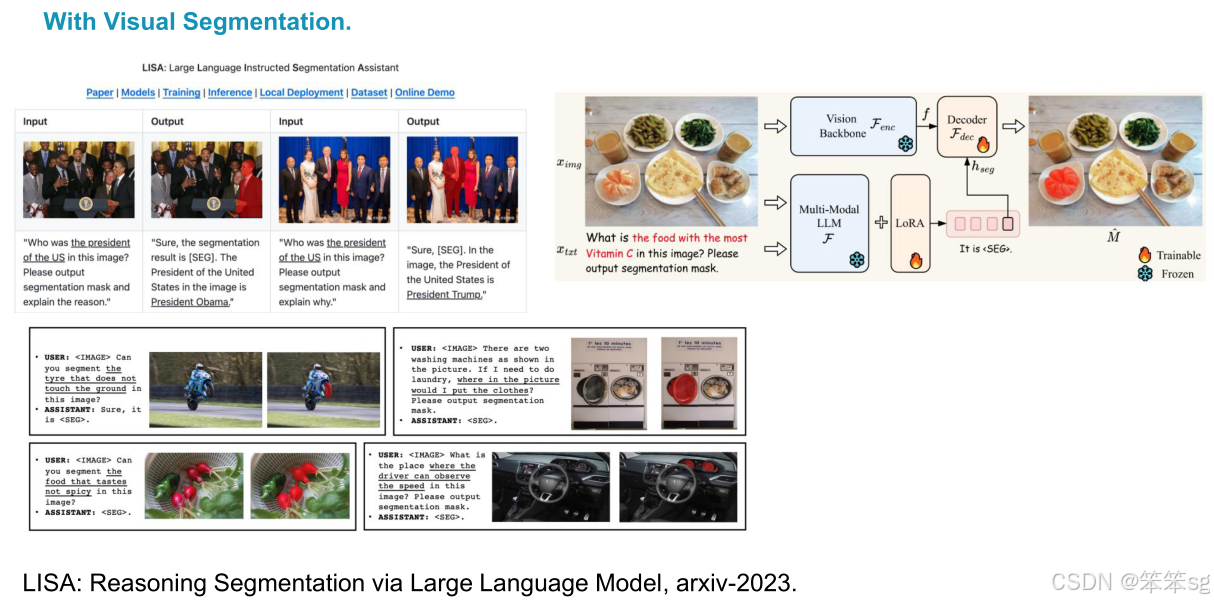
- Lisa 代表了“推理引用(Reasoning Citation)”的概念,这意味着我们不直接描述物体,而是通过语言推理来描述物体。例如,问题是“哪个食物含有最多的维生素?”,我们不直接给出食物名称,而是让模型推理并输出最富含维生素的食物。
- 该方法提出了一个新的数据集,称为 Reasoning Reference Dataset,并结合了 Sum 和 Lava 框架来处理推理任务。
- SE Token:SE标记是一种特殊的标记,传入解码器用于解码生成的分割掩码。通过这种方法,模型不仅能执行推理引用,还能执行引用推理任务,生成更精确的分割结果。

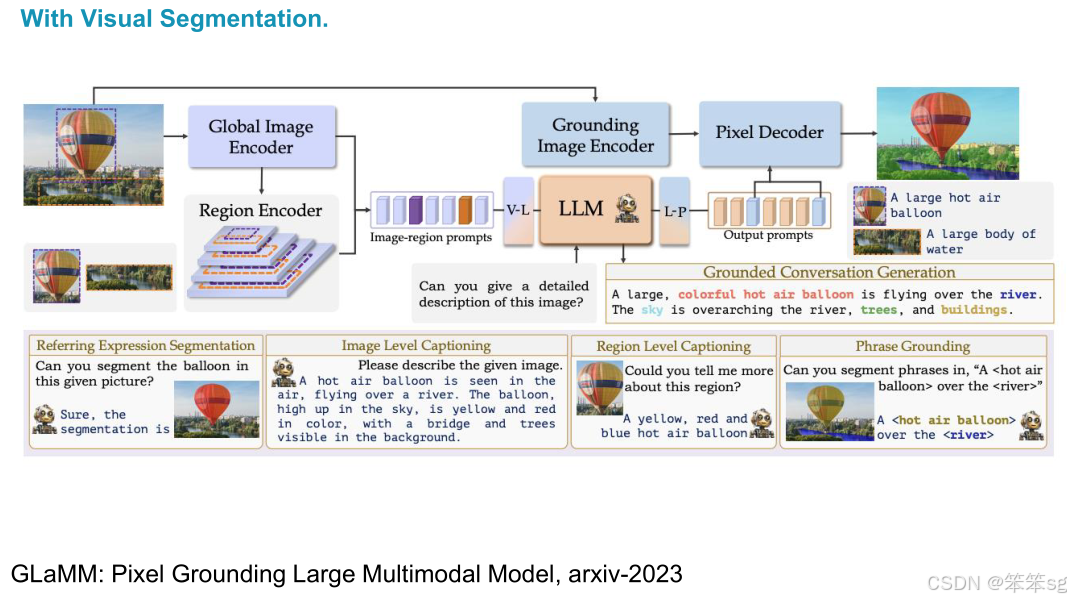
2.3.3 Glamm(Pixel Grounding Large Multimodal Model)
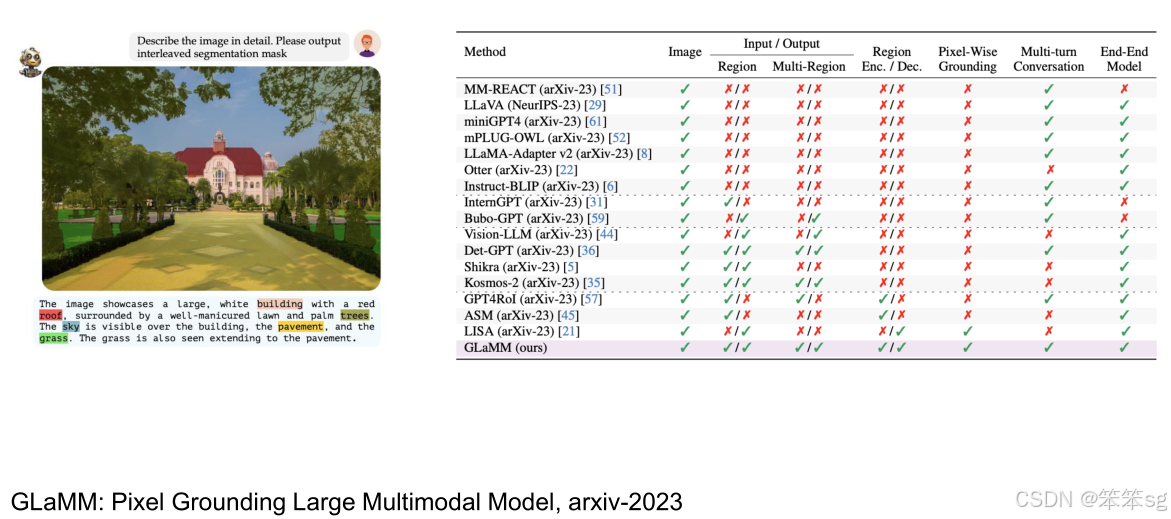
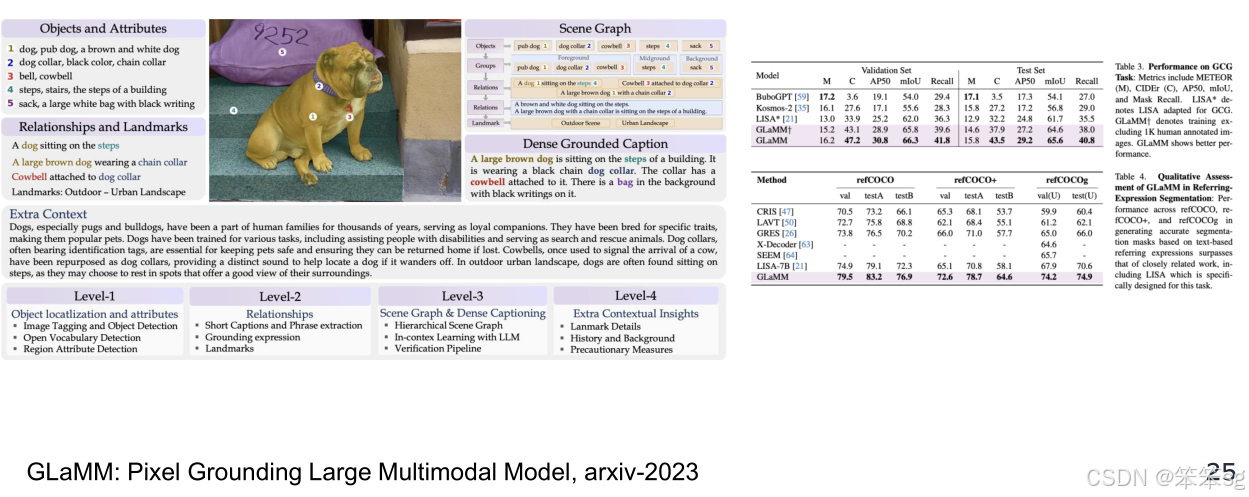
- Glamm 是另一个重要的工作,旨在实现“像素级语言模型的基础定位”。该方法提出了一个更精细的数据集,其中包含了区域级、多区域和像素级的定位和标注。
- 该数据集的标注非常密集,包括了狗的不同部位(如头部、身体等),以及背景标注。
- 模型架构:Glamm 模型使用一个 全局编码器 和 基础图像编码器,以及 像素解码器,来处理视频分割任务。这种组合使得模型能够更精确地完成区域定位和像素级标注任务。
- 性能:Glam 模型在多个引用定位数据集上表现出色,并达到了很高的性能水平。
2.4 视频和3D细粒度多模态语言模型 (Video and 3D Fine-Grained MLLM)
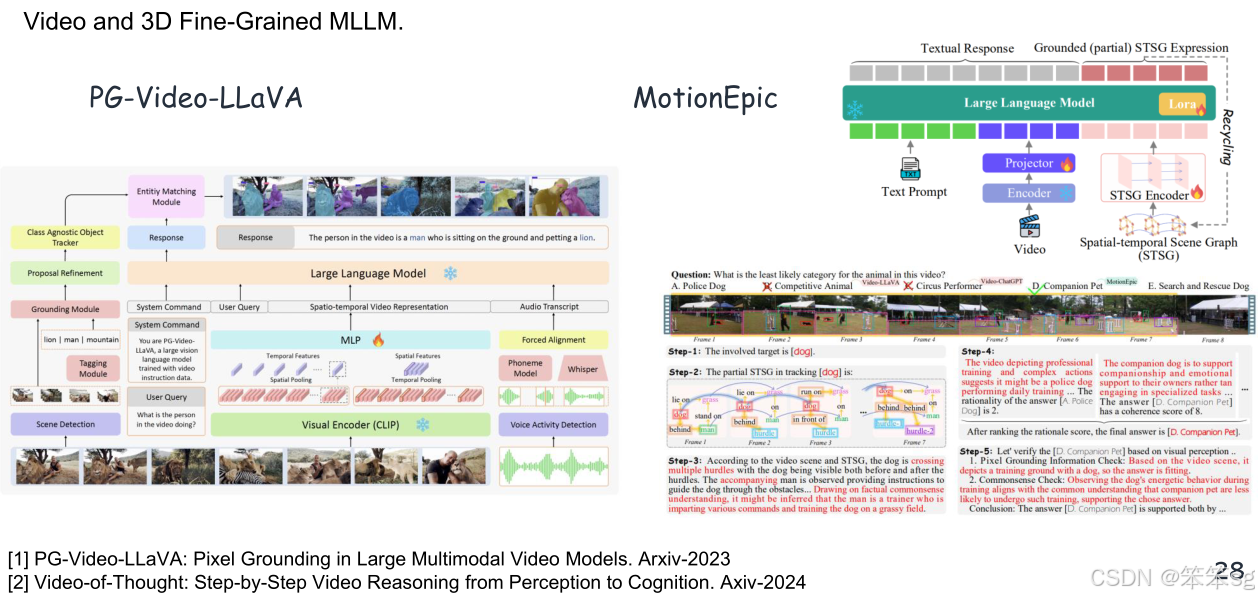
2.4.1 PG-Video-LLaVA和MotionEpic
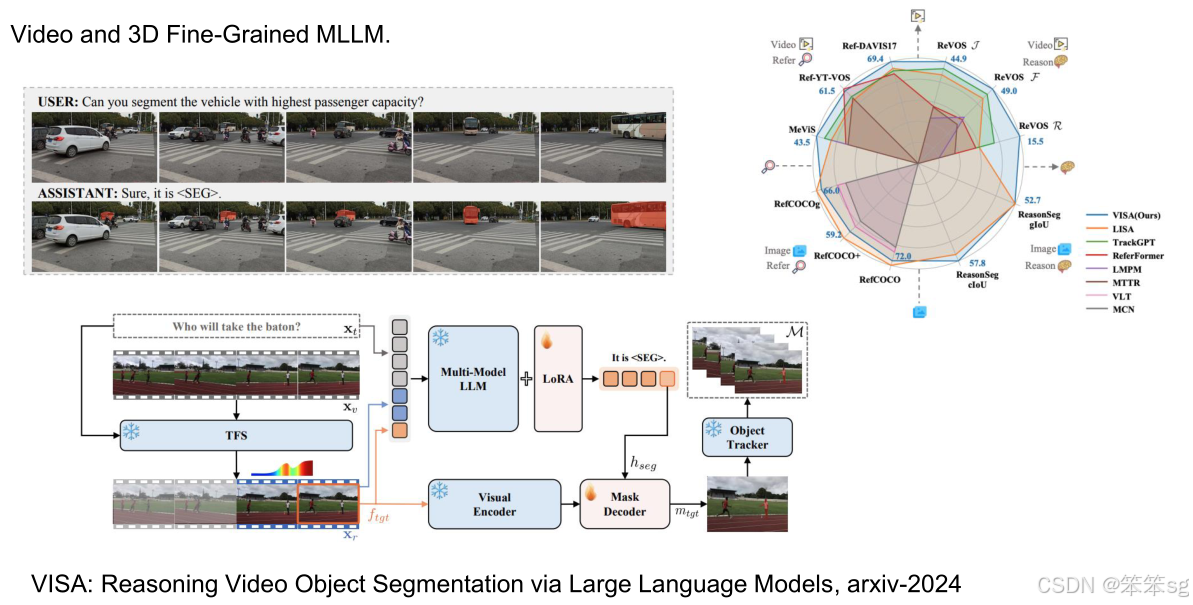
2.4.2 Visa
- Visa 是 Lisa 的扩展,专注于视频中的推理引用。它通过引入新的数据集,执行视频分割任务,要求模型对视频序列中的对象进行分割,同时确保每一帧的正确性。
- 视频分割:这需要对视频中的每个对象进行分割并检查每一帧,确保分割精度高。Visa 通过添加 对象跟踪器 来关联视频中的每个掩码,确保分割的一致性。
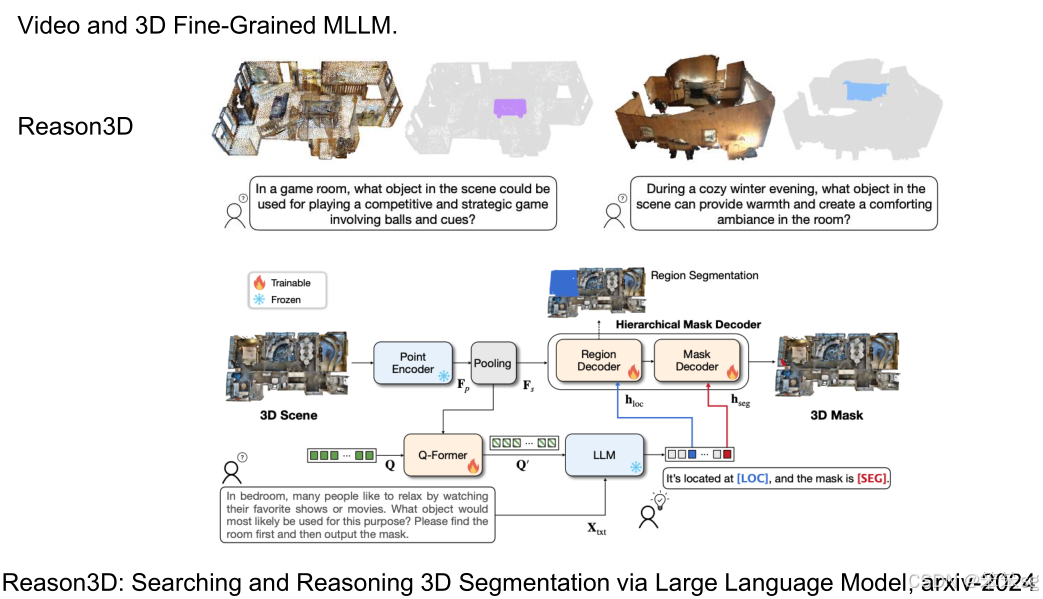
2.4.3 3D Fine-Grained Reasoning
- 3D Fine-Grained Reasoning 是针对三维推理的任务框架,要求模型在三维空间中输出对应的掩码。这些掩码与图像或视频中的三维位置相关,增强了空间维度的理解能力。
- 任务示例:模型不仅进行 语言 grounding,还包括 问题回答 和 物体检测,能够进行多对象的定位与推理。
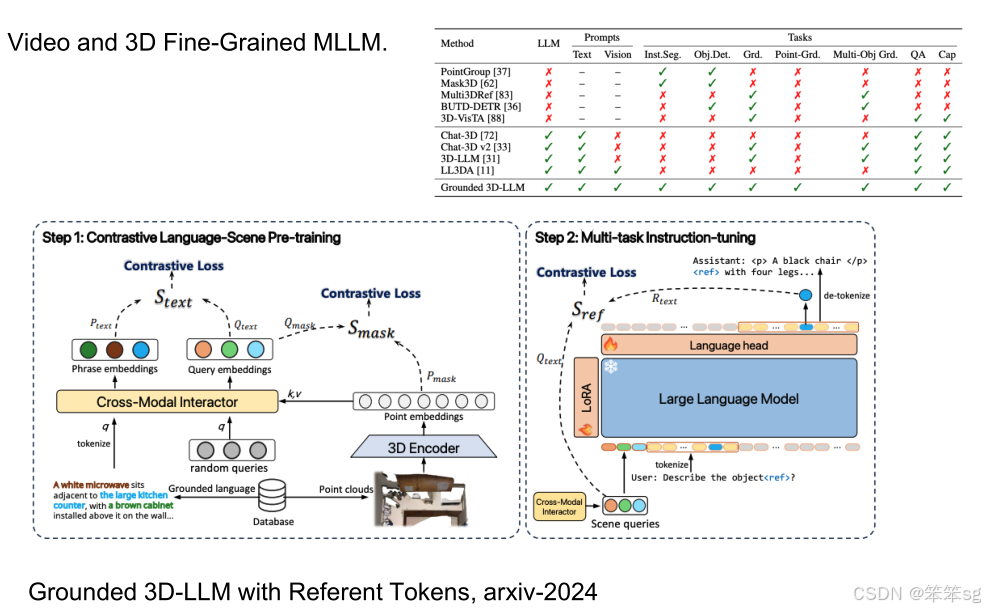
- 工作示例:Grounded 3D-LLM,该模型结合了 3D Grounding 和 语言模型,处理了包括 物体检测 和 多点定位 等多种三维推理任务。该架构与 2D 模型类似,但增加了对三维空间的支持,能够直接输出三维空间中的推理结果。

3 高级多模态语言模型设计
3.1 概述 (Overview)

-
高级多模态设计概述
- 高级多模态设计需要关注更多功能性和 长视频分析 以及 多模型导出。
- 目标是创建一种 单一模型 来处理所有语言任务,利用互惠的成本效益。
-
长视频分析
- 处理 超长视频,例如电影级别的长视频是一个挑战。
- 设计和采用新的架构来应对这一挑战,提升模型的 性能 和 处理能力,以应对大规模视频数据。
3.2 统一架构设计 (Unified Architecture Designs)
在谈到 统一模型(Unified Model)时,有几个相关的研究工作
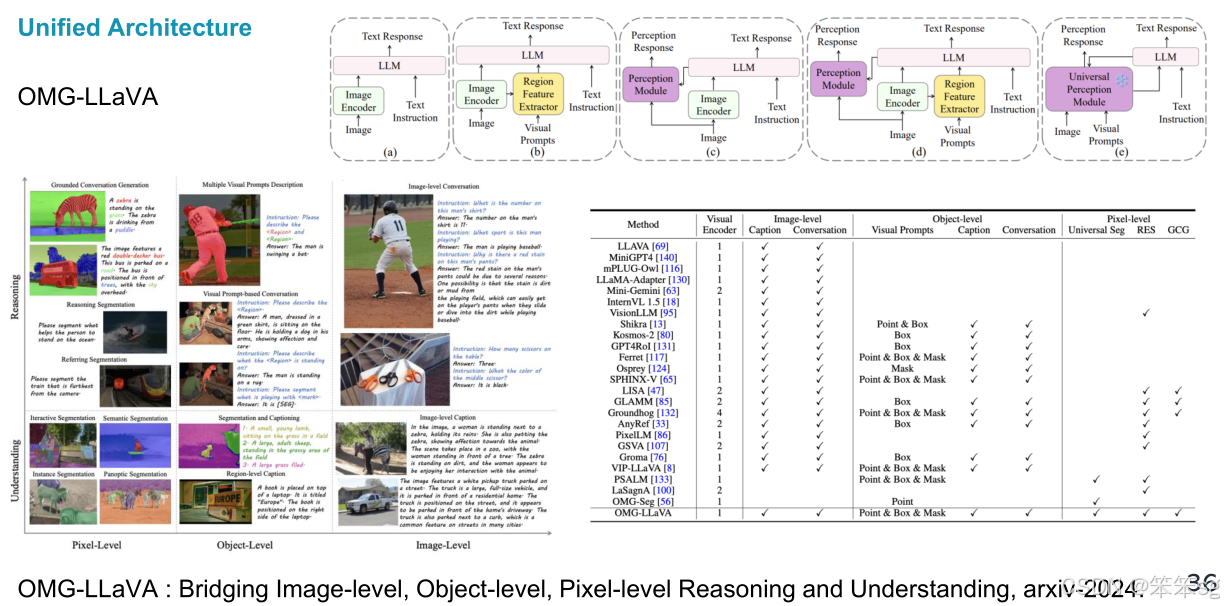
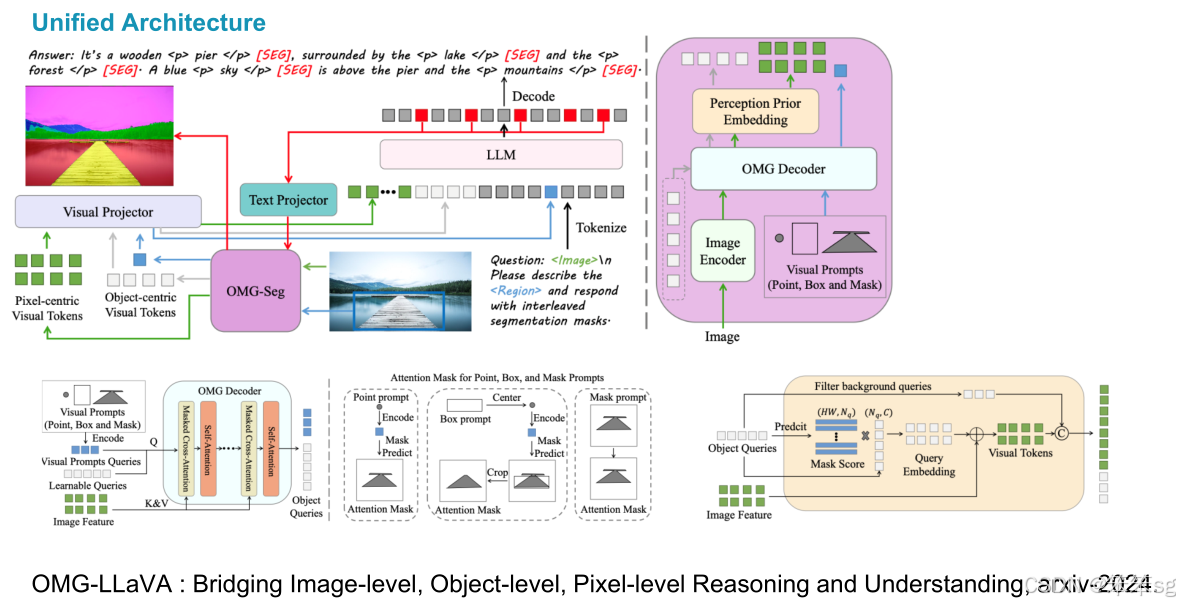
3.2.1 OMG-LLaVA
这项工作将所有分割任务统一到一个模型中。具体来说,OMG-LLaVA 统一了 图像级对象、像素级推理 和理解任务,同时也扩展了 推理与定位任务,包括参考引用、图像级对话等。
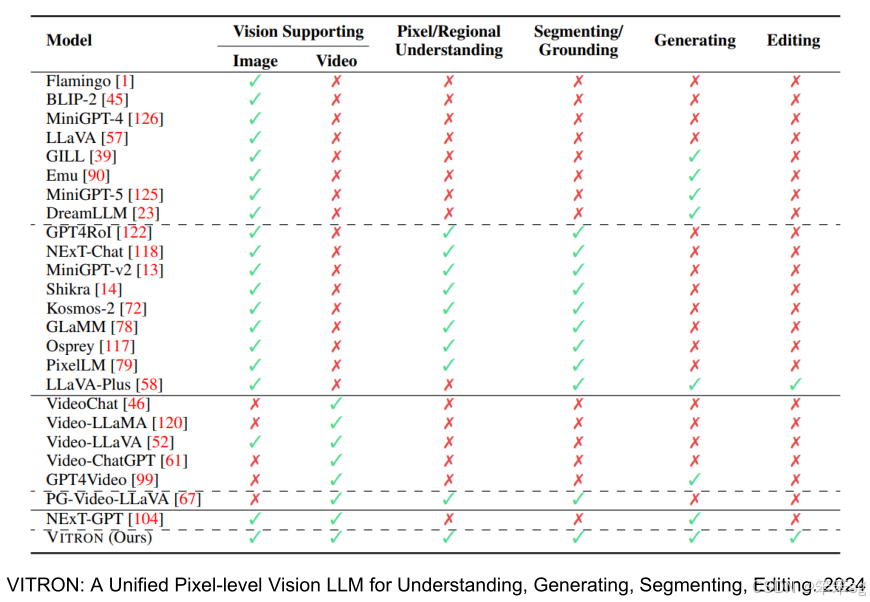
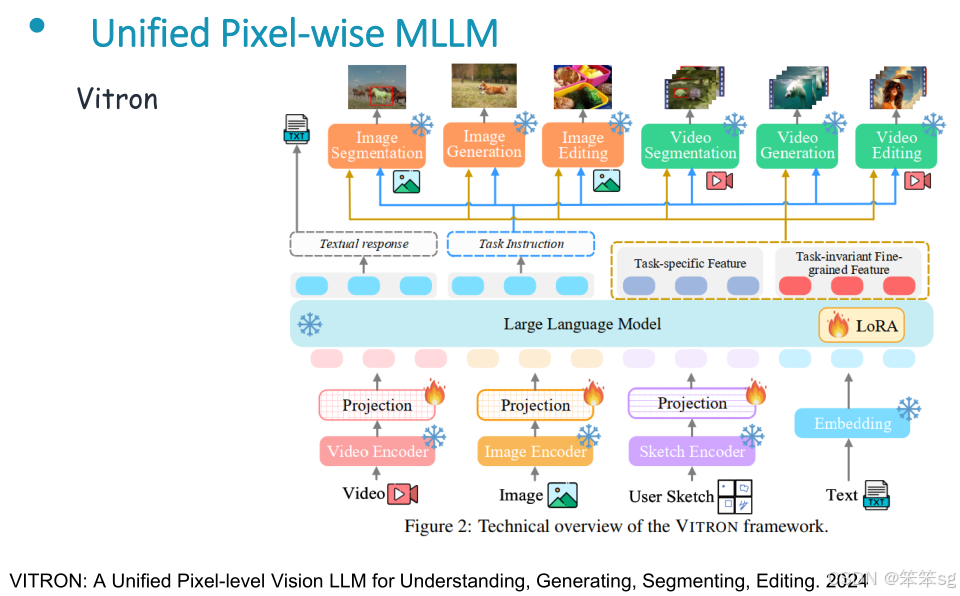
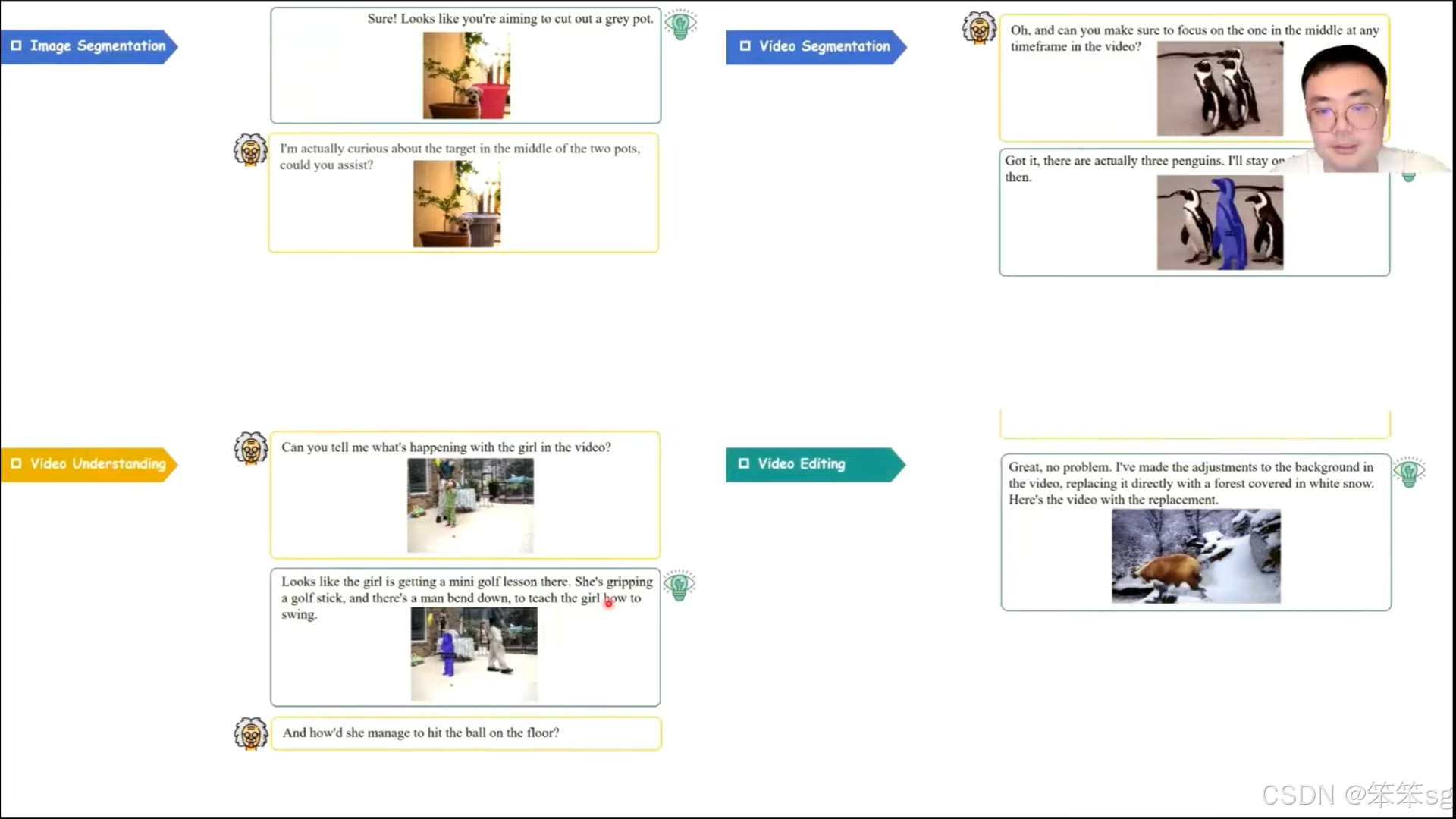
3.2.2 Vitron
该研究提出了一个新概念,使用一个模型统一多种任务,包括 理解、生成、分类,甚至 图像和视频编辑。它支持图像、视频、像素级、区域级的理解,分割、定位以及生成任务。
Vitron 通过结合多个专家模型来增强任务处理能力,每个任务模块通过 Language Model 来控制指令的生成,并输出相应的结果。

上述工作都朝着 统一模型 的方向发展,试图通过一个模型来处理 多种任务(如图像和视频分割、理解、生成等)。这些模型通过不同的专家系统(例如定位、生成模型)进行组合,最终实现多任务的高效处理。
3.3 用于长视频分析的多模态语言模型 (MLLM For Long Video Analysis)
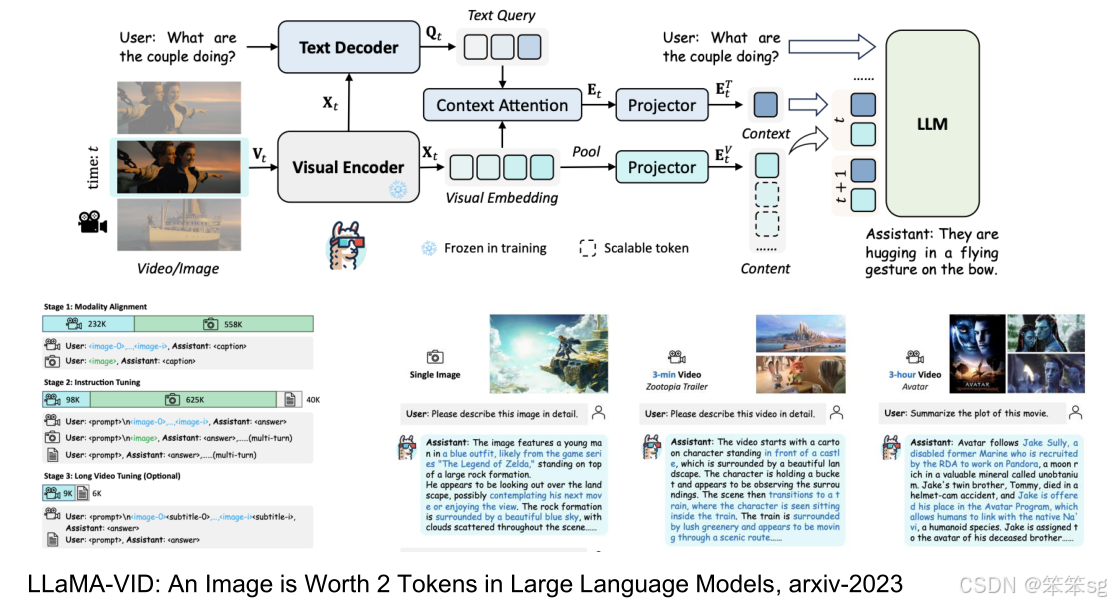
3.3.1 LLaMA-VID
这项工作在多模态长视频分析中非常有影响力且简单。作者提出了 上下文注意力(Context Attention)的概念。具体来说,上下文注意力 通过使用查询文本(test query)来选择更合理的上下文,从而编码和合并所有视频帧的特征。每个视频帧被合并为一个单独的 token,减少了冗余数据。由于长视频中的帧数非常多,直接合并有助于减少计算量,使得长视频的处理变得更加高效。
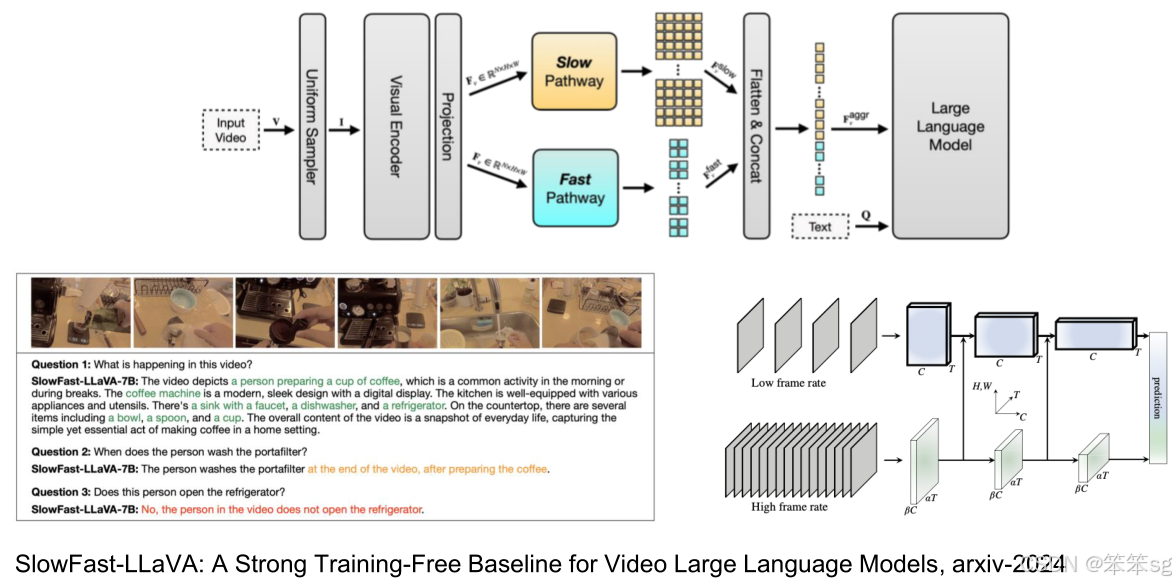
3.3.2 SlowFast LLaVA
这个模型的灵感来源于 SlowFast 网络,该网络是 KingMing's work 中提出的。SlowFast 模型由两个分支组成:慢分支(Slow Branch)和快分支(Fast Branch)。慢分支负责捕捉详细的信息,而快分支则采样更多的帧,但牺牲了一些细节。这种设计使得模型可以在长视频任务中达到更好的性能,尤其是在视频问答(Video Q&A)等任务上。
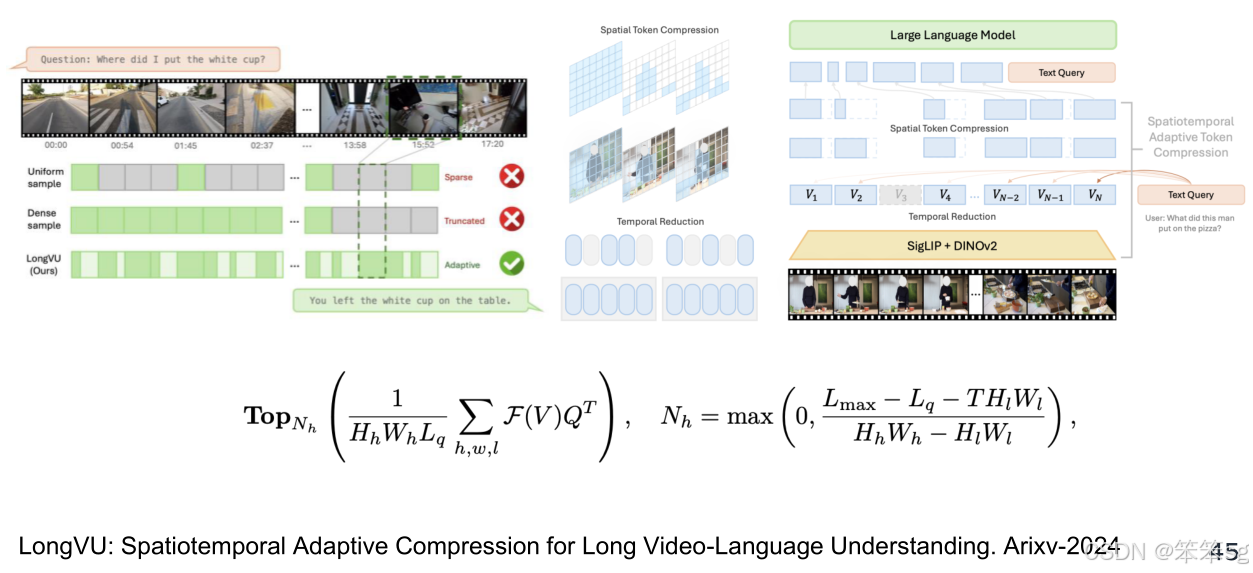
3.3.3 LongVU
这是 Meta 提出的近期工作,目标是对长视频进行更加精细化的设计。模型采用了 选择性特征减少(selective feature reduction)和 帧选择性减少(selective frame reduction)等方法。具体而言,模型通过 测试查询(test query) 动态选择需要关注的帧,从而减少不必要的信息量,提升了长视频分析的效率。
3.4 带有MOE设计的多模态语言模型 (MLLM With MOE Design)
3.4.1 MoE-LLaVA
MoE-LLaVA 是一个代表性的工作,它将不同的视频专家模型(Video Expert)直接结合到 LLaVA 架构 中。通过这种设计,LLaVA 在处理多个视频任务时表现出显著的性能提升。该设计的核心思想是利用多个视频专家通过 MOE 架构 动态调整输入到 LLM 中,从而提升性能。
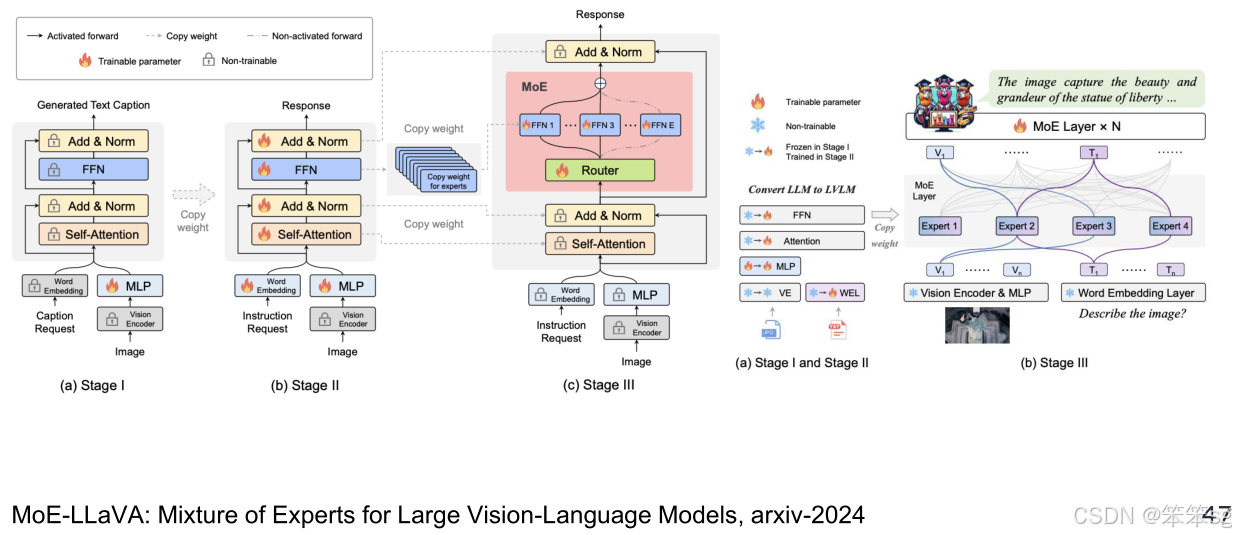
MOE(Mixture of Experts)是指专家混合模型,它是一种在机器学习中广泛使用的架构。MOE的核心思想是将多个“专家”模型(通常是神经网络)结合起来,每个专家在特定任务或数据子集上表现更好。通过选择性地激活不同的专家来处理输入,MOE能够有效地处理不同类型的任务或数据,同时提高计算效率。
MOE的基本原理:
多个专家模型:MOE系统通常包含多个不同的专家模型,每个专家模型专注于不同类型的任务或输入数据。例如,一个专家可能专注于图像识别,另一个可能专注于文本处理。
门控机制(Gating Mechanism):MOE模型使用一个门控网络来决定哪些专家应该被激活。这个门控网络通常是一个较小的神经网络,它根据输入数据选择一组专家进行计算。通常,在每次推理过程中,只会选择少数几个专家来处理特定任务或数据,降低计算负担。
稀疏激活:MOE的一个关键特点是稀疏激活,即在每次计算时,只有一部分专家被激活。相比传统的全连接模型,MOE的稀疏激活可以显著减少计算量,提高效率。
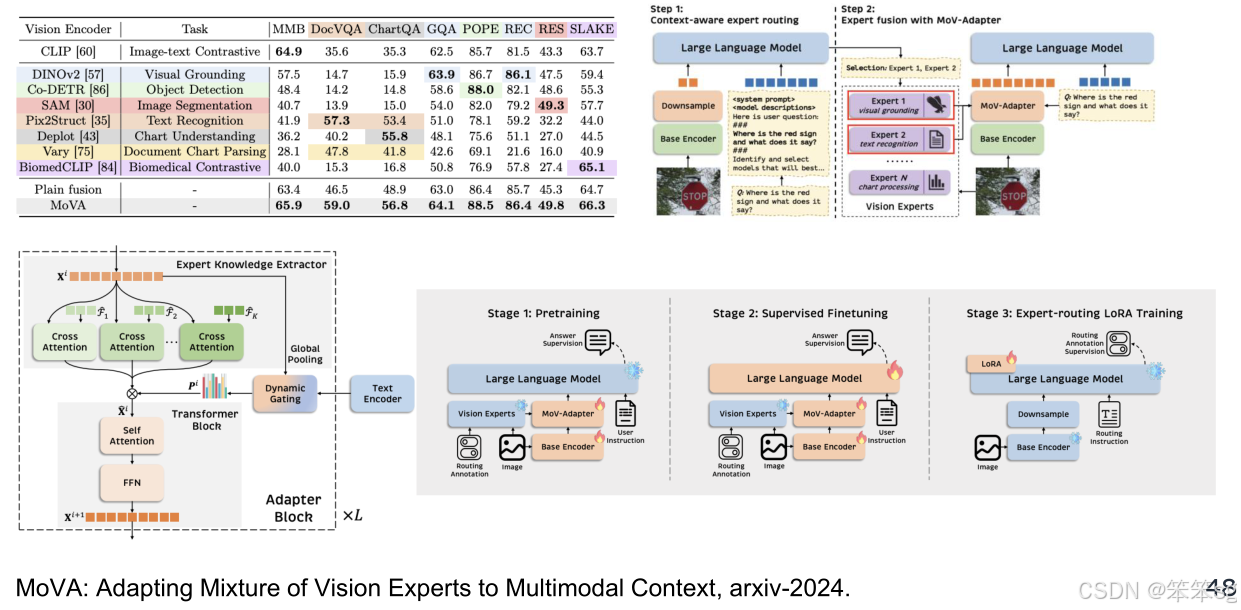
3.4.2 MooVA
MoVA 是另一项在此领域的代表性工作,它结合了多个不同的视频专家。这些视频专家通过新的 动态结构 被输入到一个统一的 LLM 中。通过这种方式,MOVA 提供了更强的多模态理解能力,尤其在视频相关任务中表现优异。
3.4.3 未来多模态设计的几个关键方向

- 多模态IRM的结合:例如,结合图像、视频、3D和音频到一个统一的模型中,以提升跨领域的理解能力。
- 新的操作符设计:随着多模态系统的发展,需要为这些模型设计新的操作符,特别是那些从语言领域中来的操作符。
- 单一Transformer架构:例如,最近的一项工作提出将图像生成和文本生成统一到一个模型中,这意味着我们不再需要专门的视觉专家,只需通过一个通用的架构进行处理。
- 长视频理解与聊天检查:长视频理解是一个非常具有挑战性的任务,如何有效地进行 grounding 和 聊天检查 是未来研究的重要方向。
- 简化统一架构设计:可以探索如何将所有专家结合到一个模型中,实现更简单高效的架构设计。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









