







目录
4.1.1 Chain-of-Thought Prompting(链式思维提示)
4.1.2 Knowledge Distillation for LLMs(大型语言模型的知识蒸馏)
4.2.1 Chain-of-Thought Annotations(链式思维标注)
4.2.3 Reasoning Distillation(推理蒸馏)
4.4.1 Various Student Models (RQ1)(不同的学生模型(研究问题1))
4.4.2 Ablation Studies (RQ2)(消融实验(研究问题2))
4.4.3 Impact of Data Augmentation (RQ3)(数据增强的影响(研究问题3))
4.4.4 Low-resource Scenarios (RQ4)(低资源场景(研究问题4))
4.4.5 Effects of Mentor Sizes (RQ5)(导师模型规模的影响(研究问题5))
0 论文及代码链接
论文链接:[2410.09037] Mentor-KD: Making Small Language Models Better Multi-step Reasoners
发表会议:EMNLP 2024
1 NLP领域三大顶会简介:
ACL、EMNLP 和 NAACL 是自然语言处理(NLP)领域的三大顶级学术会议,主要聚焦于自然语言处理、计算语言学及其相关方向的最新研究成果,均为CCF-A类。以下是对这三大会议的详细介绍:
1.1 ACL
- 全称:Association for Computational Linguistics Annual Meeting
- 领域定位:
- ACL 是 NLP 和计算语言学领域最顶级、最具影响力的会议之一。
- 涵盖广泛的研究方向,包括语言建模、机器翻译、语音处理、文本生成、多模态学习等。
- 主办方:国际计算语言学协会(Association for Computational Linguistics, ACL)。
- 会议特点:
- 历史最悠久的 NLP 会议,始于 1963 年。
- 接收论文数量多,竞争激烈,录取率通常在 20%-30%。
- 注重理论创新和实际应用的结合。
- 时间与地点:每年夏季举办,地点在全球范围内轮流更换。
- 影响力:是自然语言处理领域学术影响力最高的会议,吸引全球顶尖学者投稿。
1.2 EMNLP
- 全称:Empirical Methods in Natural Language Processing
- 领域定位:
- 专注于自然语言处理中的数据驱动和实验方法。
- 强调机器学习方法在 NLP 任务中的应用,尤其是大规模数据集的使用。
- 主办方:ACL 特设兴趣小组 SIGDAT(Special Interest Group on Linguistic Data and Corpus-Based Approaches)。
- 会议特点:
- 以实际方法和实验为核心,偏向于机器学习算法、深度学习模型在 NLP 中的应用。
- 注重对实际数据的建模和分析。
- 起步较晚(1996 年首次举办),但影响力迅速提升。
- 时间与地点:每年秋季举办,通常在全球范围内选择地点。
- 影响力:逐渐成为与 ACL 并驾齐驱的 NLP 领域顶会,录取率与 ACL 类似。
1.3 NAACL
- 全称:North American Chapter of the Association for Computational Linguistics Annual Conference
- 领域定位:
- ACL 的区域性会议,主要面向北美研究者,但其学术地位和论文质量非常高。
- 涉及广泛的 NLP 研究主题,从语法解析到深度学习和生成任务。
- 主办方:ACL 的北美分会(NAACL)。
- 会议特点:
- 强调区域性和社区参与,适合关注北美 NLP 社区的研究动向。
- 融合 NLP 基础研究和工业应用。
- 论文的录取率稍高于 ACL 和 EMNLP,但仍具备很高的学术价值。
- 时间与地点:每年春季或初夏举办,通常在北美的主要城市。
- 影响力:作为 ACL 的子会议,逐渐发展为顶会之一,吸引北美及其他地区的研究者投稿。
2 第一遍——粗读部分章节:
2.1 Title:
Mentor-KD: Making Small Language Models Better Multi-step Reasoners
导师-知识蒸馏:让小型语言模型更擅长多步推理
读后感:没问题
2.2 Abstract:
大型语言模型(Large Language Models, LLMs)通过链式思维(Chain-of-Thought, CoT)提示在各种复杂任务中表现出了显著的性能。最近的研究提出了一种知识蒸馏(Knowledge Distillation, KD)方法——推理蒸馏(reasoning distillation),通过对生成多步推理过程的 LLM 教师模型进行微调,将这种推理能力传递给较小的语言模型。然而,这些研究在以下两个方面对蒸馏过程中的挑战考虑不足:1)数据质量不足;2)软标签的提供不足。在本文中,我们提出了一种称为 Mentor-KD 的方法,能够有效地将 LLM 的多步推理能力蒸馏到较小的语言模型中,同时解决上述挑战。具体而言,我们利用了一个导师(mentor)模型,即一个经过任务特定微调的中等规模模型,用于在推理蒸馏过程中为学生模型生成额外的 CoT 标注和提供软标签。我们进行了广泛的实验,并验证了 Mentor-KD 在各种模型和复杂推理任务上的有效性。
读后感:没问题
2.3 Introduction:
大型语言模型(Large Language Models, LLMs)展现出了令人印象深刻的新兴能力,在自然语言处理(NLP)领域的各种推理任务中表现出色(Brown 等, 2020;Rae 等, 2021;Hoffmann 等, 2022;Chowdhery 等, 2023)。其中一个特别有趣的策略是链式思维(Chain-of-Thought, CoT)提示,它通过显式生成复杂任务的中间推理步骤来激发 LLM 的多步推理能力(Wei 等, 2022b)。然而,研究表明,这种推理能力仅在拥有数百亿参数的语言模型中显现(Chung 等, 2022;Wei 等, 2022a),这些模型需要大量计算资源或昂贵的 API 调用,限制了它们在资源受限场景中的部署。
为了解决这些部署上的挑战,已有研究(Ho 等, 2023;Li 等, 2023;Magister 等, 2023)采用了一种知识蒸馏(Knowledge Distillation, KD)的方法——推理蒸馏(reasoning distillation),将 LLM 的多步推理能力传递给较小的语言模型。知识蒸馏流程通常通过在 LLM 教师模型上应用上下文学习(In-Context Learning, ICL)生成输出(例如多步推理过程)作为蒸馏集,然后利用这些数据对学生模型进行微调。先前研究表明,推理蒸馏可以显著提升学生模型的性能,甚至在某些特定任务上超越其 LLM 教师(Ho 等, 2023;Chen 等, 2023)。
然而,现有的推理蒸馏方法存在两个因 LLM 教师生成的蒸馏集不足而导致的挑战。首先,由于 LLM 可能无法访问任务特定的数据,用于蒸馏的推理过程的质量可能较低(例如,GPT-3.5 在 StrategyQA 数据集上的推理准确率仅为 58%)。LLM 教师的推理质量较低限制了推理数据集中正确推理样本的数量,因为需要排除可能负面影响学生模型性能的错误推理样本(Ho 等, 2023)。其次,由于黑盒 LLM 教师模型的访问权限通常受限,学生模型无法模仿教师模型的预测行为和知识(如软标签)(Hinton 等, 2015)。这些问题可能导致学生模型过拟合于教师模型提供的有限蒸馏集,从而削弱其泛化能力。
为了解决这些问题,我们提出了 Mentor-KD,一种新颖的推理蒸馏框架,可以有效地蒸馏 LLM 的多步推理能力。我们的核心思想是引入一个“导师”(mentor),即一个中等规模的任务特定模型,用于在推理蒸馏过程中补充 LLM 教师的知识。具体而言,我们首先对导师模型进行任务特定的微调,并生成链式思维推理(CoT)样本和软标签,以增强蒸馏集。通过利用任务特定的导师模型,其能力集中于特定目标能力,Mentor-KD 能够通过在更多样化的推理样本和软标签内在知识上进行训练,有效解决这两个问题。
我们在各种复杂推理任务上进行了广泛的实验,包括常识推理、算术推理、逻辑推理和符号推理。实验结果清楚地表明,我们的方法在仅利用 LLM 知识的基线方法之上具有显著的优势。此外,我们验证了导师模型可以生成比其他 LLM 基线更多数量的正确推理样本,突出了我们方法作为数据增强手段的有效性。最后,我们证明了 Mentor-KD 在低资源场景下显著提高了学生模型的性能,表明其具有成本效益。总结来说,本文的贡献包括以下几点:
- 我们提出了 Mentor-KD,一种新颖的推理蒸馏框架,能够在解决 LLM 教师蒸馏集不足的情况下提升小型语言模型的推理能力。
- 我们引入了一个导师模型,用于生成额外的推理样本和软标签,补充 LLM 教师提供的有限训练数据集。
- 我们通过广泛的实验验证了 Mentor-KD 在多种推理任务和不同模型上的有效性,显著提升了学生模型的推理蒸馏效果。
读后感:有以下4个问题
2.3.1 问题1——理解正确
问题:
“知识蒸馏流程通常通过在 LLM 教师模型上应用上下文学习(In-Context Learning, ICL)生成输出(例如多步推理过程)作为蒸馏集,然后利用这些数据对学生模型进行微调。”
这里的“应用上下文学习生成输出作为蒸馏集”是什么意思?
个人理解:
✅感觉就是少样本提示(Few-shot Prompting)+CoT吧,输入是{问题-推理过程、答案}的QA对+一个Q,输出是这个Q对应的A,然后这一对{Q,A}作为一个训练样本吧。
GPT的回答:
上下文学习(In-Context Learning, ICL)是一种方法,即将输入任务的说明和几个示例作为提示提供给 LLM 教师模型,目的是让模型理解任务并生成相应的输出。这些输出包括多步推理的中间过程(即 Chain-of-Thought,CoT),被称为蒸馏集,随后用来微调学生模型。
举例:
假设任务是解答一个算术问题,例如:
问题:“如果一个车间有 20 台机器,每台机器一天生产 5 个零件,一周(7 天)生产多少零件?”
ICL 的做法:
我们首先给 LLM 提供几个示例:
提示:
以下是一些多步推理的示例:
问题:3 人每人带 2 个苹果,问总共有多少个苹果?
回答:3 人 × 2 个苹果 = 6 个苹果。答案是 6。
问题:一个箱子里有 10 个橙子,另一个箱子有 15 个橙子,两箱总共多少个橙子?
回答:10 个橙子 + 15 个橙子 = 25 个橙子。答案是 25。
问题:如果一个车间有 20 台机器,每台机器一天生产 5 个零件,一周(7 天)生产多少零件?
利用这个提示,LLM 将生成如下回答:
回答:每台机器一天生产 5 个零件,一周生产 7 天 × 5 个零件 = 35 个零件;20 台机器一周生产 20 × 35 = 700 个零件。答案是 700。
生成的蒸馏集:
这个问题的多步推理过程(包括中间步骤和最终答案)将作为蒸馏集,用于微调较小的学生模型。
2.3.2 问题2——理解正确
问题:
“由于 LLM 可能无法访问任务特定的数据,用于蒸馏的推理过程的质量可能较低(例如,GPT-3.5 在 StrategyQA 数据集上的推理准确率仅为 58%)。”
这句话具体是什么含义呢?
个人理解:
✅可能是因为某个LLM在训练时由于某些因素(训练后这个数据集才发布)在训练时没有在这个数据集上进行训练;也可能是只有输入没有输出,无法构成答案对用于训练;或是 LLM 没有接触过类似任务的数据集。以上因素导致生成的推理答案质量较低。
GPT的回答:
由于 LLM 并未在任务特定的数据集上训练过,其生成的推理过程可能不够准确。这是因为 LLM 的训练数据通常是广泛的通用文本数据,而非专门针对特定任务(如 StrategyQA 这样需要高精度的推理任务)的数据集。因此,在特定任务上,LLM 可能会生成不准确的推理步骤,导致蒸馏集中存在噪声和错误答案,从而影响学生模型的性能。
2.3.3 问题3——理解正确
问题:
“由于黑盒 LLM 教师模型的访问权限通常受限,学生模型无法模仿教师模型的预测行为和知识(如软标签)。”
这里“黑盒 LLM 教师模型”的意思是?
个人理解:
✅黑盒意思是模型是闭源的(如GPT虽然对用户open使用,但不open源码),因此我们只能获取其生成的答案或让LLM自己说出其推理的过程,而无法直接获得其知识传递过程(如软标签、真实的CoT步骤)。
GPT的回答:
“黑盒”指的是模型的内部机制和训练过程对用户不可见或不可访问。对于闭源 LLM(例如 GPT-3.5),用户只能通过 API 获取输入的答案和推理过程,无法访问模型的内部参数、训练数据或生成的软标签(即预测时每个类别的概率分布)。软标签通常包含更丰富的知识,而不是单一的硬标签(如分类问题的最终类别),因此它们对学生模型的训练非常重要。然而,由于黑盒模型的限制,这种软标签的知识无法直接传递给学生模型。
2.3.4 问题4——理解错误
问题:
“我们首先对导师模型进行任务特定的微调,并生成链式思维推理(CoT)样本和软标签,以增强蒸馏集。”
为什么说这个方法解决了上述两个问题?这里用来微调导师模型的数据集是从哪里来的?不是说无法访问特定数据集么?
个人理解:
❌对LLM进行重新训练太麻烦了,我们不如用一个与该特定任务类似的数据集去微调导师模型。然后让将其应用到新的数据集上生成CoT样本和软标签,视为是辅助LLM,弥补了数据数量和质量不足的问题,使得学生模型可以接收到更好的知识用于训练。
GPT的回答:
为什么 Mentor-KD 解决了上述两个问题?
- 对于问题 1(数据质量不足),导师模型通过微调任务特定的数据集,可以生成更高质量、更贴近任务需求的推理样本(CoT)。这样,学生模型可以学习到更准确的推理过程。
- 对于问题 2(软标签缺失),导师模型是一个开源且可控的模型,因此可以生成软标签。这些软标签包含了更丰富的知识,有助于学生模型的泛化性能。
用于微调导师模型的数据集通常是公开的或特定任务的标注数据集,而非闭源 LLM 的训练数据。这种任务特定的数据集可以从公共数据来源(例如开放式的 NLP 数据集库)中获取。相比直接训练 LLM,这种方法的成本更低。
正确回答:
根据第二轮对论文进行详细阅读后得知,中等规模导师模型用于微调的数据集来源于 LLM 教师生成的蒸馏集。
2.4 各个标题:
0 Abstract(摘要)
1 Introduction(引言)
2 Related Works(相关工作)
2.1 Chain-of-Thought Prompting(链式思维提示)
2.2 Knowledge Distillation for LLMs(大型语言模型的知识蒸馏)
3 Methodology(方法)
3.1 Chain-of-Thought Annotations(链式思维标注)
3.2 Mentor Model(导师模型)
3.3 Reasoning Distillation(推理蒸馏)
4 Experiments(实验)
4.1 Experiment Setup(实验设置)
4.2 Main Results(主要结果)
5 Analysis(分析)
5.1 Various Student Models (RQ1)(不同的学生模型(研究问题1))
5.2 Ablation Studies (RQ2)(消融实验(研究问题2))
5.3 Impact of Data Augmentation (RQ3)(数据增强的影响(研究问题3))
5.4 Low-resource Scenarios (RQ4)(低资源场景(研究问题4))
5.5 Effects of Mentor Sizes (RQ5)(导师模型规模的影响(研究问题5))
6 Conclusion(结论)
7 Limitations(局限性)
8 Acknowledgements(致谢)
9 References(参考文献)
2.5 数学内容:
基本不太复杂,大体都能看懂,但具体含义得留到后续阅读再分析了。

2.6 Conclusion:
我们提出了Mentor-KD,这是一种将大型语言模型(LLMs)的推理能力迁移到小型语言模型(LMs)的新型框架。为此,我们引入了一种名为导师模型(mentor model)的新型辅助模型,用于通过扩充多步推理过程和为学生模型提供软标签来补充来自LLMs的蒸馏集。通过广泛的实验,我们证明了Mentor-KD显著提升了推理蒸馏的有效性。具体而言,在复杂推理任务中,我们的学生模型在各种规模和类型的模型上均优于现有的推理蒸馏基线。此外,我们验证了导师模型能够生成有效的推理样本和软标签用于训练学生模型,从而带来持续的性能提升。
2.7 References:
扫了一眼,都是蛮新的文章(20年之后的),除了发KD论文大概率都要提到的KD开山之作——2015年Hinton的“Distilling the knowledge in a neural network”。
3 第一遍阅读结束要回答的五个问题:
1、类别:这篇论文属于哪个类别?实验数据类、还是提出一个新的研究模型、还是其他类别?
这篇论文主要属于提出新研究模型和方法的类别,具体来说,它引入了一个新型的推理蒸馏框架 Mentor-KD,并通过大量实验验证了其有效性。
2、内容:这篇论文和哪些已经读过的论文相关?比如是在哪些文章的基础上做的工作,还是自成一脉全新的工作?
这篇论文 Mentor-KD 是基于已有研究工作的进一步扩展与改进,而非完全独立的一脉新工作。通过对论文内容的分析,可以发现它结合了两个主要研究方向的成果:链式思维提示(Chain-of-Thought Prompting) 和 知识蒸馏(Knowledge Distillation),并针对这两个方向存在的挑战提出了创新方法。
3、正确性:这篇论文的前提假设合理吗?
该论文的前提假设如下,个人感觉比较合理:
- LLMs 展现出强大的推理能力,但资源消耗大;
- LLMs 的推理能力可以通过知识蒸馏传递给较小模型;
- LLMs 教师模型在生成蒸馏集时存在局限性;
- 引入中等规模的任务特定导师模型可以弥补上述问题。
4、贡献:这篇论文的主要贡献是什么?
总的来说,论文的主要贡献在于提出了一个创新的推理蒸馏框架 Mentor-KD,通过引入任务特定的导师模型来解决传统方法中蒸馏集不足的问题,从而提升小型语言模型的推理能力。在各种规模和类型的模型上均优于现有的推理蒸馏基线,尤其在低资源场景下展现出了较好的性能,具有较高的实际应用潜力。
5、清晰度:这篇论文写得好吗,你如何看待这篇论文?
我读过的论文相对较少,但从目前第一步阅读来看,虽然心中还是有一些疑惑,但整体感觉行文比较清晰严谨,值得进一步阅读。
4 第二遍——细读全文:
4.1 Related Works(相关工作)
4.1.1 Chain-of-Thought Prompting(链式思维提示)
CoT 提示是一种通过上下文学习(ICL)激发语言模型(LMs)多步推理能力的方法(Wei 等, 2022b)。CoT 的本质是,它作为语言模型逻辑推理的指导,帮助语言模型分解并解决复杂的推理任务(Xia 等, 2024)。因此,它使得语言模型在复杂推理任务中表现出色(Kojima 等, 2022;Wang 等, 2023b;Zhang 等, 2023),而传统的少样本学习方法在这些任务中表现较差(Rae 等, 2021)。近期的研究进一步改进了 CoT 提示,通过提高推理步骤的质量来增强其效果。Madaan 等人(2023)使语言模型通过自我反馈进行推理的迭代自我修正,而 Gou 等人(2024)利用外部工具获得反馈。Trivedi 等人(2023);Zhao 等人(2023)结合信息检索系统以增强语言模型推理的真实性。
尽管取得了成功,先前的研究(Hoffmann 等, 2022;Wei 等, 2022b;Chu 等, 2024)报告称,CoT 提示的推理优点在于当语言模型的规模达到数百亿参数时才能显现。为了应对这一问题,我们的研究重点是通过推理蒸馏使小规模的语言模型能够进行 CoT 推理。
大致意思就是要通过改进CoT推理步骤的质量然后喂给学生模型,进而使得学生模型也能够具备CoT推理能力。
4.1.2 Knowledge Distillation for LLMs(大型语言模型的知识蒸馏)
知识蒸馏(KD)(Hinton 等, 2015)已经被证明是通过将大规模语言模型(LMs)的预测行为(例如软标签)或内部知识(例如隐藏表示)传递给小规模语言模型,从而压缩语言模型的一个有前途的方法。然而,现有的用于预训练语言模型的知识蒸馏方法,涉及到蒸馏软标签(Sanh 等, 2019;Gu 等, 2024)或表示(Wang 等, 2020, 2021;Kim 等, 2022),需要访问教师模型的内部参数。这些要求对知识蒸馏中利用大规模语言模型(LLMs)提出了重大挑战,因为它们是黑盒性质的且不切实际。
因此,最近的研究实践了推理蒸馏,使得小规模语言模型(学生模型)能够通过利用大规模语言模型教师生成的推理过程,而非软标签,进行类似的多步推理。例如,Ho 等人(2023);Magister 等人(2023);Li 等人(2023)对学生模型进行了多步推理过程的微调,这些推理过程是由大规模语言模型生成的。类似地,Shridhar 等人(2023)通过让大规模语言模型生成原始问题的子问题,使学生模型学习如何分解复杂问题。Wang 等人(2023c)迭代性地利用大规模语言模型提供专门针对学生生成的实时反馈。Kang 等人(2023);Zhao 等人(2024)利用信息检索系统来增强学生在知识密集型任务中的推理真实性。最近,Zhu 等人(2024a,b)结合了由大规模语言模型生成的多步推理代码格式,以提升学生的算术推理能力。
与我们的研究同期,Zhou 和 Ai(2024)也使用中等规模模型进行大规模语言模型蒸馏。我们的工作不同之处在于,我们使用中等规模模型来补充教师模型的蒸馏信号,而不是用来过滤注释。
尽管大多数先前的研究是通过利用大规模语言模型提供的蒸馏集来改进推理蒸馏,我们认为这些蒸馏集可能不足,甚至可能削弱学生模型的能力。从这个意义上说,我们的工作不同之处在于,我们补充了大规模语言模型教师蒸馏集的不足之处。
不同于之前其他工作想法设法改进大模型输出的蒸馏集质量,这项工作认为蒸馏集的数量和质量一样都需要得到提升,因此设计了一个中等规模的模型对来补充教师模型的蒸馏信号。
4.1.3 小节总结
论文“Related Works(相关工作) ”这块介绍的比较清晰,也成功地将已有研究和该论文的创新点结合一起进行了比对,没有什么比较困惑的地方。
4.2 Methodology(方法)
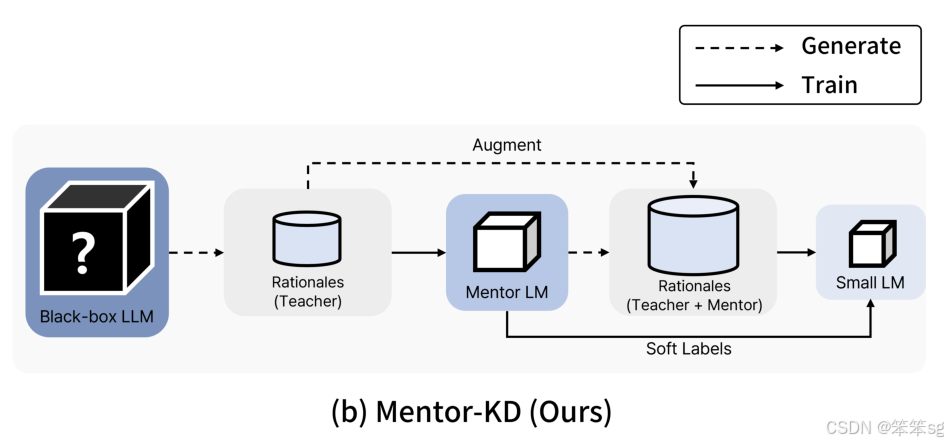
我们详细阐述了 Mentor-KD 的实现过程。其核心思想是通过利用一个任务特定的中等规模导师模型来增强蒸馏训练集。为此,我们首先从 LLM 教师模型生成链式思维(CoT)注释(第 3.1 节)。然后,我们使用来自 LLM 教师的蒸馏集对导师模型进行微调,经过训练的导师模型生成额外的训练集,包括推理过程和软标签(第 3.2 节)。通过增强导师模型提供的两种信号,我们将知识蒸馏到学生模型中(第 3.3 节)。图 2 展示了我们框架的概述。
图 2:我们提出的框架 Mentor-KD 的整体概述。Mentor-KD 包含三个步骤。首先,从教师 LLM 收集链式思维(CoT)注释并进行筛选。其次,使用保留下来的注释训练导师模型,训练后的导师模型增强多步推理过程。最后,学生模型在来自教师和学生的注释以及导师模型提供的软标签上进行训练。
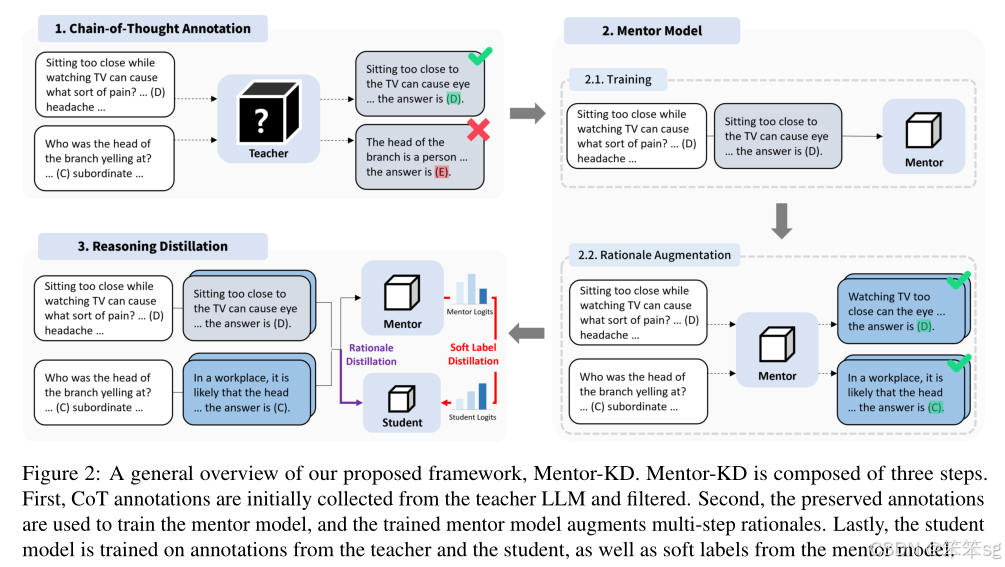
有以下两个问题:
第1:“并进行筛选”中这个筛选是由谁完成的?人工么?
第2:“使用保留下来的注释训练导师模型,训练后的导师模型增强多步推理过程”,这里的意思是筛选后有了更好的数据所以可以用于训练出一个更好的模型么?
我们继续往下走
4.2.1 Chain-of-Thought Annotations(链式思维标注)
我们使用 LLM 通过零样本 CoT(Kojima 等, 2022)获得包含推理过程和最终预测的链式思维(CoT)注释。这是一个由推理和答案提取两个阶段组成的策略,因此,我们首先引导 LLM 生成链式思维推理过程,然后再生成最终预测。
具体而言,我们首先在问题后附加“让我们一步一步思考”,然后提示 LLM 以获得推理过程。接着,我们再次提示 LLM,将之前获得的推理过程融入其中,以引导其生成最终预测。形式上,给定一个数据集 D = {qi, yi},其中 qi 表示问题,yi 表示黄金标签,我们的目标是引导 LLM 在给定问题 qi 作为输入时,生成一步一步的推理过程
和最终预测
。提示模板的形式为:“Q: {qi}. A: 让我们一步一步思考。{
注:把这些手工标记的数据称为“黄金”标签,因为它们代表了一些可靠的基础真值。
举个例子:

随后,我们对LLM生成的注释进行筛选。根据之前的研究(Li等,2023;Magister等,2023;Fu等,2023;Lee等,2024),我们保留最终预测
, yi),其中
。
这里回答我之前的一个疑惑——“这个筛选是由谁完成的?人工么?”
答案是只需要比对生成的预测和黄金标签,匹配就保留,不匹配就不要。
但这样子又有了另一个问题,不匹配就不要的话,如果有大量的QA对不匹配,那我们从LLM教师模型得到的蒸馏集岂不是大大缩水了,还能有足够的数据集去支持我们训练出一个效果更好的导师模型么?
4.2.2 Mentor Model(导师模型)
在这里,我们描述了如何训练我们的导师模型,使其专注于特定任务,并利用它来补充LLM教师的不足的蒸馏集。
训练:为了训练导师模型,我们直接在之前构建的 Dteacher 上进行微调。具体来说,导师模型以 qi 作为输入,
推理增强:训练后的导师模型随后用于训练数据的增强。对于来自 D 的数据样本,我们让导师模型为每个 qi 生成逐步推理过程的注释。导师模型生成的标签
包括逐步推理过程和它自己的预测。我们按照与过滤教师注释相同的方式过滤导师模型的注释,并保留那些
= yi 的数据样本。通过这个阶段,我们为每个数据集构建了 Dmentor =
。
通过从教师 (Dteacher) 和导师 (Dmentor) 获得的注释,我们最终构建了 Dtrain 用于训练学生模型。
4.2.3 Reasoning Distillation(推理蒸馏)
为了训练学生模型,我们结合了微调(推理蒸馏)和通过导师模型获得的logit值进行的知识蒸馏(软标签蒸馏)。这样做的目的是让学生模型同时 1)学习如何以符号的方式进行逐步推理(Ho 等,2023;Li 等,2023;Magister 等,2023),以及 2)模仿更大模型的预测行为(Hinton 等,2015)。相应地,我们的训练目标包括两个损失函数。
推理蒸馏:与训练导师模型相同,逐步推理能力可以通过使用从教师和导师模型获得的问题-标签对来微调学生模型进行蒸馏。更具体地,通过微调学习多步推理能力的形式定义如下:
其中 f 表示学生模型,方括号表示字符串连接。
软标签蒸馏:利用LLM教师的内在知识可能是不实际的,因为其黑箱性质或巨大规模。相反,我们使用导师模型来提供软标签进行蒸馏。软标签通过前向传播,然后应用softmax函数得到,给定输入q。形式上,我们从k位置的logit值zk获得软标签(概率分布)pk,具体计算如下:
其中,τ表示一个温度超参数,用于使分布更加柔和。获得导师(pm)和学生(ps)的概率分布后,我们采用Kullback-Leibler散度损失来最小化这两种分布之间的差异。这样,学生模型可以模仿预测行为,并学习更大模型的内部知识。软标签蒸馏的训练目标定义如下:
注:KL散度损失函数用于衡量两个概率分布之间的差异,用在这里非常恰当。
联合学习:最后,我们让学生模型联合学习上述两个目标。训练学生模型的损失函数如下:
其中,λ是一个超参数,用于插值两个损失函数。(插值=平衡+结合)
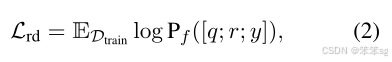
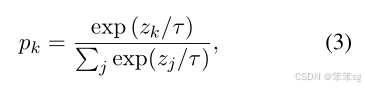
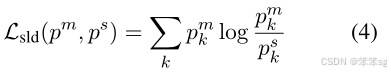
看完了上述步骤,现在我们应该就很容易下图了:
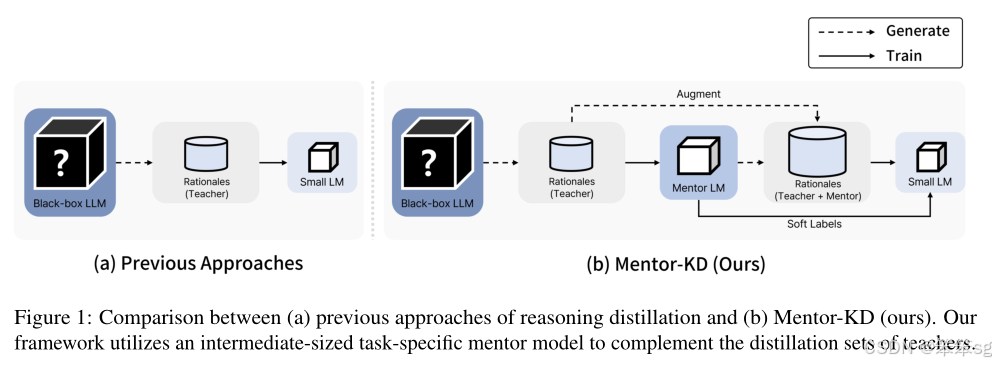
图1: (a) 之前的推理蒸馏方法与 (b) Mentor-KD(我们的框架)之间的比较。我们的框架利用一个中等规模的任务特定导师模型来补充教师模型的蒸馏集。
4.2.4 小节总结
论文“Methodology(方法) ”这块介绍的也比较清晰,但我有以下3个问题还未得到解决:
1)教师模型生成的预测和黄金标签相比,不匹配就不要的话,如果有大量的QA对不匹配,那我们从LLM教师模型得到的蒸馏集岂不是大大缩水了,还能有足够的数据集去支持我们训练出一个效果更好的导师模型么?
2)导师模型为啥效果比LLM更好呢?是不是因为数据集都是针对特定任务的,所以更加专注集中,LLM更综合反而不能集中于一类问题。这类似我们如果做一个多分类问题,发现分类错误主要体现在A识别为B,B识别为A,那我们就单独训练一个二分类模型用于区分A和B得了,让这个模型专注于解决A和B的分类问题,当多分类预测结果为A或者B时就把数据输入给二分类预测器得到一个更准确的答案。
3)公式2的具体含义是啥,目前看不明白这个损失函数的表达形式(后续可能需要看源码才能明白)。
我们继续往下看,看下文能否解决我们的疑惑。
4.3 Experiments(实验)
在本节中,我们描述了实验细节,并在各种复杂的推理任务中评估了我们的Mentor-KD。
4.3.1 Experiment Setup(实验设置)
任务与数据集:
根据(Wei et al., 2022b; Kojima et al., 2022)的研究,我们在四类复杂推理任务上评估了我们的 Mentor-KD,分别是常识推理、算术推理、逻辑推理和符号推理。具体而言,我们每个任务采用最多三个数据集,以评估我们框架在同一任务类型的不同数据集上的表现。本文使用的数据集包括:常识推理任务的 StrategyQA(Geva et al., 2021)和 CommonsenseQA(Talmor et al., 2019),算术推理任务的 GSM8K(Cobbe et al., 2021)、ASDiv(Miao et al., 2020)和 SV AMP(Patel et al., 2021),逻辑推理任务的 Tracking Shuffled Objects 和 Date Understanding(Srivastava et al., 2023),符号推理任务的 Last Letter Concatenation(Wei et al., 2022b; Kojima et al., 2022)。更多细节见附录A。
语言模型:
我们通过 OpenAI API 使用 gpt-3.5-turbo 作为教师模型。对于导师和学生模型,我们主要使用 FlanT5-XXL 和 FlanT5-XL(Chung et al., 2022)作为导师和学生模型。为了进行额外分析,我们还使用了各种大小的 FlanT5 和 T5(Raffel et al., 2020),包括大模型、基础模型和小模型。
Chain-of-Thought 注释:
对于 GSM8K、ASDiv、SV AMP 和 CommonsenseQA,我们利用(Chen et al., 2023)提供的 CoT 注释。这些注释是通过使用 Zero-shot-CoT 提示,由 GPT-3.5-Turbo 收集的,方法与我们在第3.1节中提到的方法相同。其他数据集则是由我们研究所新提示并收集的。
基线:
为了进行对比,我们采用了之前的推理蒸馏方法。具体来说,我们实现了 Vanilla-KD,这是一种通用的推理蒸馏方法,旨在通过教师模型生成的推理过程微调学生模型(Ho et al., 2023; Magister et al., 2023);MCC-KD 进一步强调了多重 CoT 推理过程中的多样性和一致性(Chen et al., 2023)。我们还将 Mentor-KD 的表现与 Fu et al.(2023)的研究进行了对比,该研究旨在将语言模型的推理能力专门化为某一特定任务。我们通过 Zero-shot-CoT(ZS-CoT)提示报告教师模型的表现。
实现:
我们采用了 HuggingFace(Wolf et al., 2020)提供的模型,在两台 NVIDIA RTX A6000 GPU 上进行训练。具体而言,我们对 XXL-/XL-规模模型训练了 18 个 epoch,对大规模模型训练了 10 个 epoch,对基础模型和小规模模型训练了 20 个 epoch,训练设置参照了之前的工作(Chen et al., 2023; Ho et al., 2023)。所有实验的最大序列长度设置为 512,并且我们在批量大小为 {2, 4, 6, 8} 的范围内进行选择。为了加速训练并节省内存使用,我们在主要实验中应用了 bfloat16 的混合精度和 LoRA(Hu et al., 2022),并遵循了(Chen et al., 2023)中的相关配置。此外,我们使用了 AdamW(Loshchilov and Hutter, 2019)优化器,学习率设置为 {1e-4, 2e-4, 3e-4, 5e-4}。我们将损失插值超参数 λ 设置为 0.3,将蒸馏温度 τ 设置为 {1.0, 2.0}。我们报告了四个随机种子的平均测试准确率结果。
4.3.2 Main Results(主要结果)
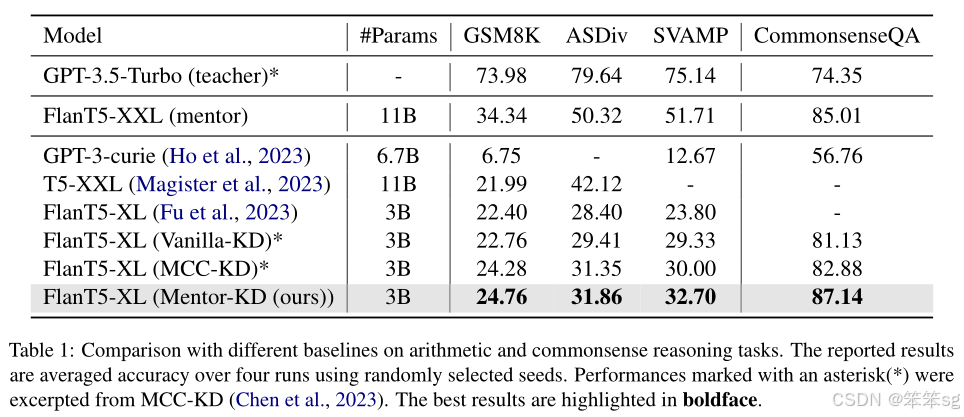
为了公平比较,我们主要比较了使用 FlanT5-XL 模型的 Mentor-KD 在三项算术推理任务和一项常识推理任务上的表现,这些任务通常用于推理蒸馏(Ho et al., 2023; Chen et al., 2023)。主要结果见表1。我们观察到,Mentor-KD 在四个不同的推理数据集上达到了最先进的性能。具体来说,我们的模型在平均准确率上比之前的最先进模型 MCC-KD 高出大约 2.0%。这些结果证明了 Mentor-KD 在解决具有挑战性的复杂推理任务中的有效性,包括算术推理和常识推理。
表1:在算术和常识推理任务上与不同基准方法的比较。报告的结果是使用随机选择的种子进行四次实验的平均准确率。标有星号(*)的性能摘自 MCC-KD(Chen et al., 2023)。最佳结果用粗体标出。
4.3.3 小节总结
论文作者进行了一系列实验来证明这项工作的优越表现,同时为了增强说服力,还尝试了多种数据集、多种推理任务、多种规模的模型,并与其他现有的优越的推理蒸馏框架进行性能上的对比。整体来看行文比较清晰流畅。
4.4 Analysis(分析)
为了深入探讨我们方法的优势,我们进行了一系列细致的分析实验,研究问题如下:
• RQ1. Mentor-KD 能否推广到不同大小和类型的学生模型?(§5.1)
• RQ2. Mentor-KD 中的每个组件如何贡献于其整体性能?(§5.2)
• RQ3. 导师模型能否为学生生成有效的蒸馏数据集?(§5.3)
• RQ4. Mentor-KD 是否在低资源场景下提供了改进?(§5.4)
• RQ5. 导师模型的大小是否会影响学生模型的性能?(§5.5)
4.4.1 Various Student Models (RQ1)(不同的学生模型(研究问题1))
为了进一步研究我们的 Mentor-KD 的通用性,我们在不同大小的学生模型上进行了一系列实验。特别地,我们通过额外加入逻辑和符号推理任务,扩展了实验的范围。具体来说,我们使用了 T5 和 FlanT5,这些模型在 LLM 蒸馏中被广泛采用(Ho et al., 2023;Chen et al., 2023)。我们利用 T5 和 FlanT5 的大模型变种作为导师模型,{base, small} 变种作为学生模型。此部分的实施细节在附录 B 中详细说明。
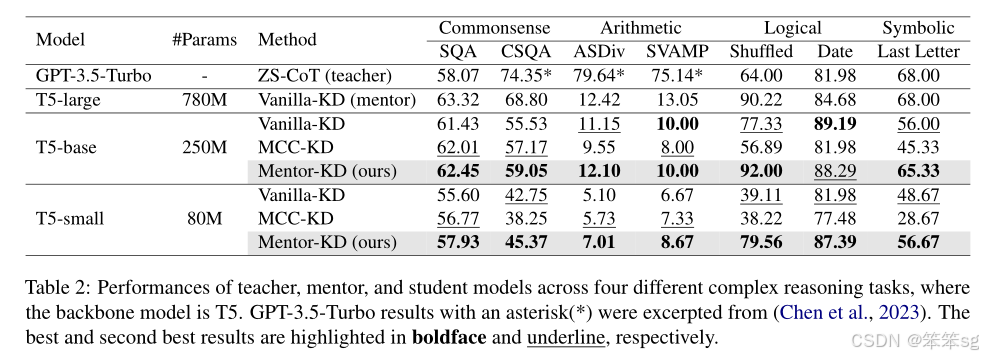
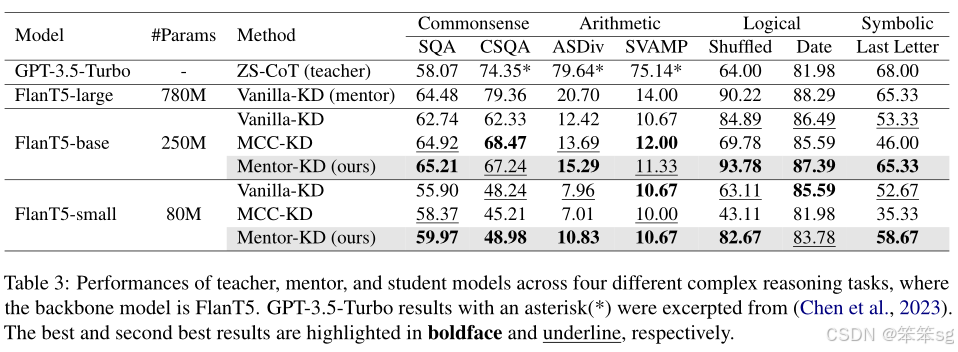
实验结果如表 2 和表 3 所示。我们观察到,Mentor-KD 在四类复杂推理任务中,始终优于其他基线方法,且适用于各种学生模型。特别是,Mentor-KD 在常识推理和逻辑推理任务中表现出了显著的性能提升,某些情况下学生模型的表现甚至超过了 LLM 教师(即 GPT-3.5)。这些结果证明,我们的任务特定导师模型能够成功补充 LLM 教师知识的不足,从而通过传递更具信息量的蒸馏信号,帮助各种学生模型实现更好的性能。
表 2:教师、导师和学生模型在四个不同复杂推理任务中的表现,其中导师模型为 T5。GPT-3.5-Turbo 的结果标有星号(*),摘自(Chen et al., 2023)。最佳和第二最佳结果分别用粗体和下划线标出。
表3:教师、导师和学生模型在四个不同复杂推理任务上的表现,其中导师模型为FlanT5。带有星号(*)的GPT-3.5-Turbo结果摘自(Chen等,2023)。最佳和第二最佳结果分别以粗体和下划线突出显示。
4.4.2 Ablation Studies (RQ2)(消融实验(研究问题2))
我们进行消融研究,以探索我们方法中每个技术的贡献。具体而言,我们关注导师模型中推理蒸馏(RD)和软标签蒸馏(SLD)的效果。详细结果见表4。我们观察到,省略RD和SLD会显著影响两种模型类型和数据集。这些结果强调了RD对训练样本和软标签的重要性,它们增强了来自教师的不足知识。
表4:Mentor-KD在追踪打乱物体和最后字母拼接任务上的消融研究。我们使用每个骨干模型的大模型作为导师,小模型作为学生。

4.4.3 Impact of Data Augmentation (RQ3)(数据增强的影响(研究问题3))
为了进一步研究导师模型提出的数据增强方法,我们从数量和质量两个角度分析其有效性。
增强数据集的数量:
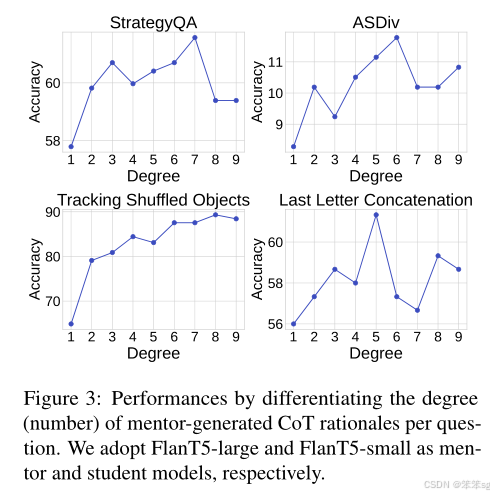
我们首先分析通过多样化导师每个问题产生的推理数量,生成的蒸馏集数量对结果的影响。结果如图3所示。总体而言,我们观察到学生模型的表现随着蒸馏集数量的增加而改善。这表明我们的导师模型成功生成了有助于学生模型学习多步推理的推理。然而,我们也观察到,当引入更多的蒸馏集时,性能通常会在六次增强后饱和,并开始下降,这可能是由于模型生成的噪声(Liu等,2022)所致。
图3:通过区分对每个问题,导师生成的CoT推理的程度(数量)来展示的表现。我们分别采用FlanT5-large和FlanT5-small作为导师和学生模型。
增强数据集的质量:
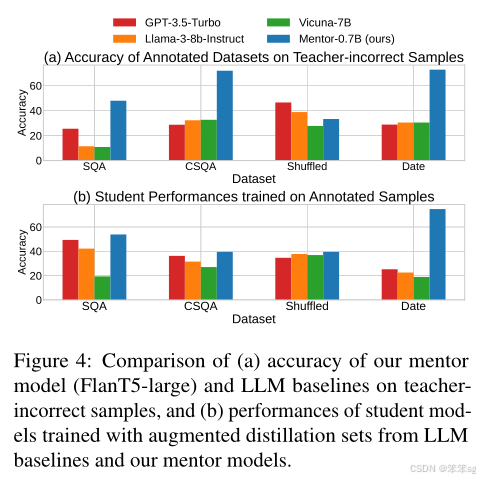
为了调查我们增强的蒸馏集的质量,我们将我们的导师模型(即FlanT5-large)与各种可能作为增强导师的LLM进行比较(即GPT-3.5-Turbo3、Llama-3-8B-Instruct4和Vicuna-7B(Chiang等,2023))。我们首先通过Zero-shot-CoT提示比较导师生成的增强集与其他基线在LLM教师预测的错误样本上的准确性。然后,我们报告在每个增强集上训练的学生(即FlanT5-small)的表现,以分析任务特定的导师是否能为学生提供有用的集合。
结果如图4所示。尽管导师模型的参数量比LLM小(例如,比Llama3-8B-Instruct小10倍),它们生成的推理比其他LLM基线更准确,表明其能够为学生模型提供更多样的推理。此外,我们观察到,使用导师模型生成的蒸馏集训练的学生确实取得了比使用LLM教师生成的集训练的学生更高的性能。这些结果表明,导师模型可以生成比LLM教师更高质量的推理。总体结果突出显示了任务特定的导师模型微调的优势。
图4:(a)我们导师模型(FlanT5-large)和LLM基线在教师预测错误样本上的准确性比较,(b)使用来自LLM基线和我们导师模型的增强蒸馏集训练的学生模型的表现比较。
4.4.4 Low-resource Scenarios (RQ4)(低资源场景(研究问题4))
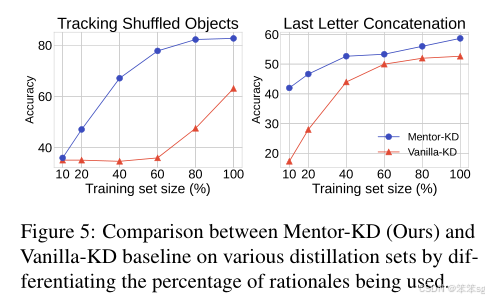
在推理蒸馏中,由于黑箱LLM的API调用费用,收集足够大的蒸馏集可能会非常昂贵。因此,我们研究了Mentor-KD在低资源场景下的有效性,在这种场景下,只为原始数据集的一部分收集蒸馏集。具体而言,我们比较了Vanilla-KD基线与我们的Mentor-KD,变化了从LLM教师模型生成的蒸馏集的比例。结果如图5所示。
我们观察到,在低资源场景下,鉴于导师模型提供了有用的推理集和软标签,Mentor-KD也能提升学生模型的表现。特别地,Vanilla-KD基线在高度有限的蒸馏信号下表现下降,而我们的Mentor-KD在有限数据集上展现出了鲁棒性。这些结果表明,我们的导师模型可以缓解学生模型由于有限蒸馏信号导致的过拟合问题,并且能够以低成本的方式蒸馏LLM教师的知识。我们在附录C中详细讨论了这个研究问题。
图5:通过区分使用的训练集百分比,比较Mentor-KD(我们的)与Vanilla-KD基线在不同蒸馏集上的表现。
4.4.5 Effects of Mentor Sizes (RQ5)(导师模型规模的影响(研究问题5))
为了进一步探索Mentor-KD的有效性并验证我们的设计选择,我们进行了一项额外的实验,通过区分导师模型的大小来进行分析。在该实验中,我们使用FlanT5-small作为学生模型,FlanT5-{XL, large, base, small}作为导师模型。对于从小模型到小模型的蒸馏,我们采用自我蒸馏,参考了之前的工作(Allen-Zhu和Li,2023;Zhu等,2024a)。
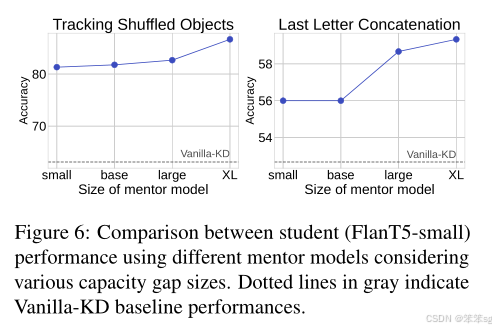
图6展示了结果。一般来说,我们观察到,当在推理蒸馏过程中使用较大的导师模型时,学生模型的表现更好。使用最小的导师模型会导致性能下降,但我们观察到这种情况下的表现仍然优于表3中的基线结果。这些结果表明,使用较大的性能更好的模型有助于提升小型学生模型的表现,这与之前的研究发现一致,即学生模型的表现与其相应模型的表现相关(Ho等,2023)。
图6:考虑不同容量差距大小的情况下,学生模型(FlanT5-small)使用不同导师模型的表现比较。灰色虚线表示Vanilla-KD基线的表现。
4.4.6 小节总结
作者做了一系列细致的分析实验来解释这项工作的优越性,行文清晰易懂,没有什么比较困惑的地方。
4.5 Limitations(局限性)
尽管我们已经证明了Mentor-KD通过增强训练集和软标签有效地提高了小型语言模型的推理能力,但仍然存在一些限制,为未来的研究提供了有希望的方向。
导师模型的训练成本。我们的框架需要额外的计算成本来训练导师模型进行推理蒸馏。除了蒸馏过程中的训练成本外,本研究主要集中在提高小型学生模型的推理效率,这与大多数推理蒸馏研究的目标一致(Ho等,2023;Chen等,2023;Wang等,2023a)。我们在附录C中进一步阐述了这个问题。
不同推理策略的探索。尽管我们成功地展示了在小型语言模型中CoT推理能力的性能提升,但一个未解的问题是,我们的框架是否可以应用于其他类型的推理策略,如程序引导推理(Zhu等,2024a)、基于检索的推理(Kang等,2023;Zhao等,2024)以及基于上下文化的结构化知识的推理(Park等,2024)。我们将蒸馏不同类型推理策略的探索作为未来研究的方向。
不同架构的探索。我们已经验证了我们的框架在编码器-解码器模型(例如FlanT5、T5)上对学生模型(参数少于30亿)有效。因此,框架在解码器-only模型上的适用性在本研究中尚未得到充分探索。然而,基于近期的证据表明,推理蒸馏可以有效地推广到不同架构(Ho等,2023;Chen等,2023;Wang等,2023c),我们相信Mentor-KD有望在基于解码器的学生模型上也能提升性能。
5 第二遍阅读总结:
经过第二遍的阅读,对该论文整体的行文逻辑以及具体的细节已经比较熟悉了,了解了该方法工作的整套流程,但也仍然存有以下几个问题需要解决:
1)教师模型生成的预测和黄金标签相比,不匹配就不要的话,如果有大量的QA对不匹配,那我们从LLM教师模型得到的蒸馏集岂不是大大缩水了,还能有足够的数据集去支持我们训练出一个效果更好的导师模型么?
2)公式2计算推理蒸馏损失公式的具体含义是啥,目前看不明白这个损失函数的表达形式(后续可能需要看源码才能明白)(看完了,其实就是和硬标签做交叉熵损失)。
6 第三遍——读代码:
6.1 代码文件树状图
通过绘制仓库代码文件的树状图,我们能够以更直观的方式理解项目的整体结构,可以更清楚该项目的代码布局。
绘制树状图的代码如下,输入代码仓库文件夹路径即可:
import os
def print_directory_tree(folder_path, level=0):
"""
打印指定文件夹的树状图
:param folder_path: 目标文件夹的路径
:param level: 当前递归的层级,默认为0
"""
# 获取当前文件夹下的所有文件和文件夹
items = os.listdir(folder_path)
# 遍历文件夹中的每一项
for item in items:
item_path = os.path.join(folder_path, item)
# 判断是文件夹还是文件
if os.path.isdir(item_path):
# 如果是文件夹,打印文件夹名,并递归调用打印子文件夹
print(" " * level + f"📁 {item}")
print_directory_tree(item_path, level + 1) # 递归调用,增加层级
else:
# 如果是文件,直接打印文件名
print(" " * level + f"📄 {item}")
# 输入文件夹路径
folder_path = input("请输入文件夹路径:")
# 检查文件夹是否存在
if os.path.exists(folder_path) and os.path.isdir(folder_path):
print(f"\n{folder_path} 文件夹的树状结构:")
print_directory_tree(folder_path)
else:
print("输入的路径无效,请检查路径是否存在并重新输入。")
该代码仓库的树状图如下所示:
📁 assets # 存放项目资源文件
📄 main_figure.png # 主图像文件
📁 data # 存放数据文件
📁 aug # 数据增强目录
📁 flan-t5_large # flan-t5_large 模型的增强数据
📄 asdiv_rand3_aug3.json # ASDiv数据集增强版本
📄 commonsense_qa_rand3_aug3.json # 常识问答数据集增强版本
📄 date_understanding_rand3_aug3.json # 日期理解数据集增强版本
📄 last_letter_concatenation_rand3_aug3.json # 最后一字拼接数据集增强版本
📄 strategy_qa_rand3_aug3.json # 策略问答数据集增强版本
📄 svamp_rand3_aug3.json # SVAMP数据集增强版本
📄 tracking_shuffled_objects_rand3_aug3.json # 跟踪打乱物体数据集增强版本
📁 t5_large # t5_large 模型的增强数据
📄 asdiv_rand3_aug3.json # ASDiv数据集增强版本
📄 commonsense_qa_rand3_aug3.json # 常识问答数据集增强版本
📄 date_understanding_rand3_aug3.json # 日期理解数据集增强版本
📄 last_letter_concatenation_rand3_aug3.json # 最后一字拼接数据集增强版本
📄 strategy_qa_rand3_aug3.json # 策略问答数据集增强版本
📄 svamp_rand3_aug3.json # SVAMP数据集增强版本
📄 tracking_shuffled_objects_rand3_aug3.json # 跟踪打乱物体数据集增强版本
📁 main # 主要数据文件
📄 asdiv_3_train.json # ASDiv训练数据
📄 asdiv_test.json # ASDiv测试数据
📄 commonsense_qa_3_train.json # 常识问答训练数据
📄 commonsense_qa_test.json # 常识问答测试数据
📄 date_understanding_3_train.json # 日期理解训练数据
📄 date_understanding_test.json # 日期理解测试数据
📄 gsm8k_3_train.json # GSM8K训练数据
📄 gsm8k_test.json # GSM8K测试数据
📄 last_letter_concatenation_3_train.json # 最后一字拼接训练数据
📄 last_letter_concatenation_test.json # 最后一字拼接测试数据
📄 strategy_qa_3_train.json # 策略问答训练数据
📄 strategy_qa_test.json # 策略问答测试数据
📄 svamp_3_train.json # SVAMP训练数据
📄 svamp_test.json # SVAMP测试数据
📄 tracking_shuffled_objects_3_train.json # 跟踪打乱物体训练数据
📄 tracking_shuffled_objects_test.json # 跟踪打乱物体测试数据
📁 prompt # 提示数据
📄 date_understanding_6.json # 日期理解提示数据
📄 last_letter_concatenation_6.json # 最后一字拼接提示数据
📄 strategy_qa_6.json # 策略问答提示数据
📄 tracking_shuffled_objects_6.json # 跟踪打乱物体提示数据
📁 skeleton # 骨架数据,包含训练和测试数据
📄 asdiv_test.json # ASDiv测试数据
📄 asdiv_train.json # ASDiv训练数据
📄 clean_last_letter_data.py # 清理最后字拼接数据的脚本
📄 commonsense_qa_test.json # 常识问答测试数据
📄 commonsense_qa_train.json # 常识问答训练数据
📄 date_understanding_test.json # 日期理解测试数据
📄 date_understanding_train.json # 日期理解训练数据
📄 gsm8k_test.json # GSM8K测试数据
📄 gsm8k_train.json # GSM8K训练数据
📄 last_letter_concatenation_test.json # 最后一字拼接测试数据
📄 last_letter_concatenation_train.json # 最后一字拼接训练数据
📄 strategy_qa_test.json # 策略问答测试数据
📄 strategy_qa_train.json # 策略问答训练数据
📄 svamp_test.json # SVAMP测试数据
📄 svamp_train.json # SVAMP训练数据
📄 tracking_shuffled_objects_test.json # 跟踪打乱物体测试数据
📄 tracking_shuffled_objects_train.json # 跟踪打乱物体训练数据
📁 mcckd # MCCKD相关代码和数据
📁 data # MCCKD的数据
📁 tracking_shuffled_objects # 跟踪打乱物体数据
📄 train_with_indices_flan-t5_jaccard3.json # 带有索引的训练数据
📁 shells # MCCKD相关的shell脚本
📄 run_mcckd.sh # 运行MCCKD的shell脚本
📁 src # MCCKD源码
📄 dataset.py # 数据集处理模块
📄 evaluator.py # 评估模块
📄 generator.py # 数据生成模块
📄 model.py # 模型定义模块
📄 model_lora.py # Lora模型定义模块
📄 tokenizer.py # 分词器模块
📄 trainer.py # 训练模块
📄 trainer_backup.py # 备份的训练模块
📄 utils.py # 工具函数模块
📄 train_mcc.py # 训练MCCKD模型的脚本
📄 README.md # 项目说明文档
📁 scripts # 脚本文件夹
📁 data # 数据相关脚本
📄 augment_train_data.py # 增强训练数据的脚本
📁 fine_tune_cot # CoT微调相关脚本
📄 fine_tune_cot.py # 微调CoT模型的脚本
📁 kd # 知识蒸馏相关脚本
📄 mentor_kd.py # Mentor-KD知识蒸馏脚本
📁 shells # shell脚本
📁 data # 数据相关的shell脚本
📄 augment_train_data.sh # 增强训练数据的shell脚本
📁 fine_tune_cot # CoT微调相关的shell脚本
📄 run_fine_tune_cot.sh # 运行CoT微调的脚本
📁 kd # 知识蒸馏相关的shell脚本
📄 run_mentor_kd.sh # 运行Mentor-KD的脚本
📁 src # 源代码文件夹
📄 dataset.py # 数据集处理脚本
📄 evaluator.py # 评估模型性能的脚本
📄 functions.py # 通用函数脚本
📄 kd_tools.py # 知识蒸馏工具脚本
6.2 data文件夹剖析
在开始了解代码之前,我们有必要深入了解一下要用到的各个数据集文件:
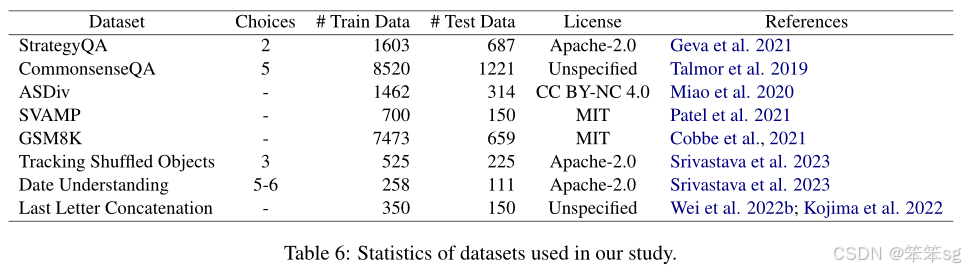
如下图所示,可以看到该论文中共使用了8种数据集,训练集和测试集的样本数量也已注明,Choices代表该数据集中每个选择题的答案选项数量,该项为"-"则表示该数据集非选择题数据集。
📁 data # 存放数据文件
📁 aug # 数据增强目录
📁 flan-t5_large # flan-t5_large 模型的增强数据
📄 asdiv_rand3_aug3.json # ASDiv数据集增强版本
📄 commonsense_qa_rand3_aug3.json # 常识问答数据集增强版本
📄 date_understanding_rand3_aug3.json # 日期理解数据集增强版本
📄 last_letter_concatenation_rand3_aug3.json # 最后一字拼接数据集增强版本
📄 strategy_qa_rand3_aug3.json # 策略问答数据集增强版本
📄 svamp_rand3_aug3.json # SVAMP数据集增强版本
📄 tracking_shuffled_objects_rand3_aug3.json # 跟踪打乱物体数据集增强版本
📁 t5_large # t5_large 模型的增强数据
📄 asdiv_rand3_aug3.json # ASDiv数据集增强版本
📄 commonsense_qa_rand3_aug3.json # 常识问答数据集增强版本
📄 date_understanding_rand3_aug3.json # 日期理解数据集增强版本
📄 last_letter_concatenation_rand3_aug3.json # 最后一字拼接数据集增强版本
📄 strategy_qa_rand3_aug3.json # 策略问答数据集增强版本
📄 svamp_rand3_aug3.json # SVAMP数据集增强版本
📄 tracking_shuffled_objects_rand3_aug3.json # 跟踪打乱物体数据集增强版本
📁 main # 主要数据文件
📄 asdiv_3_train.json # ASDiv训练数据
📄 asdiv_test.json # ASDiv测试数据
📄 commonsense_qa_3_train.json # 常识问答训练数据
📄 commonsense_qa_test.json # 常识问答测试数据
📄 date_understanding_3_train.json # 日期理解训练数据
📄 date_understanding_test.json # 日期理解测试数据
📄 gsm8k_3_train.json # GSM8K训练数据
📄 gsm8k_test.json # GSM8K测试数据
📄 last_letter_concatenation_3_train.json # 最后一字拼接训练数据
📄 last_letter_concatenation_test.json # 最后一字拼接测试数据
📄 strategy_qa_3_train.json # 策略问答训练数据
📄 strategy_qa_test.json # 策略问答测试数据
📄 svamp_3_train.json # SVAMP训练数据
📄 svamp_test.json # SVAMP测试数据
📄 tracking_shuffled_objects_3_train.json # 跟踪打乱物体训练数据
📄 tracking_shuffled_objects_test.json # 跟踪打乱物体测试数据
📁 prompt # 提示数据
📄 date_understanding_6.json # 日期理解提示数据
📄 last_letter_concatenation_6.json # 最后一字拼接提示数据
📄 strategy_qa_6.json # 策略问答提示数据
📄 tracking_shuffled_objects_6.json # 跟踪打乱物体提示数据
📁 skeleton # 骨架数据,包含训练和测试数据
📄 asdiv_test.json # ASDiv测试数据
📄 asdiv_train.json # ASDiv训练数据
📄 clean_last_letter_data.py # 清理最后字拼接数据的脚本
📄 commonsense_qa_test.json # 常识问答测试数据
📄 commonsense_qa_train.json # 常识问答训练数据
📄 date_understanding_test.json # 日期理解测试数据
📄 date_understanding_train.json # 日期理解训练数据
📄 gsm8k_test.json # GSM8K测试数据
📄 gsm8k_train.json # GSM8K训练数据
📄 last_letter_concatenation_test.json # 最后一字拼接测试数据
📄 last_letter_concatenation_train.json # 最后一字拼接训练数据
📄 strategy_qa_test.json # 策略问答测试数据
📄 strategy_qa_train.json # 策略问答训练数据
📄 svamp_test.json # SVAMP测试数据
📄 svamp_train.json # SVAMP训练数据
📄 tracking_shuffled_objects_test.json # 跟踪打乱物体测试数据
📄 tracking_shuffled_objects_train.json # 跟踪打乱物体训练数据如上树状图所示,data文件夹下共有4个子文件夹,下面我们来一一解读。
6.2.1 skeleton
该文件夹存储的是原始的8类数据集的训练集和测试集。
不妨拿ASDiv数据集举个例子:
# asdiv_train.json
[
{
"input": "Allan brought two balloons and Jake brought four balloons to the park. How many balloons did Allan and Jake have in the park?\n",
"answer": "6"
},
{
"input": "Adam has five more apples than Jackie. Jackie has nine apples. How many apples does Adam have?\n",
"answer": "14"
},
]
# asdiv_test.json
[
{
"input": "I see 115 cows grazing in the pasture. How many legs do I see?\n",
"answer": "460"
},
{
"input": "A cafeteria sold 49 cartons of regular flavored milk. If the ratio of regular milk sold to chocolate milk sold was 7:2, what is the combined amount of chocolate and regular milk sold?\n",
"answer": "63"
},
]可以看到原始的数据集中每个样本都是{input,answer}的样式。
6.2.2 prompt
该文件夹存储的是将上述数据集中的每个问题输入老师模型LLM生成6个推理过程的数据集。(注意只对训练集进行处理,测试集保留原来的{input,answer}的样式即可)。

原始数据集有8种,为啥这个目录下只有4个输出结果呢?别急,作者在附录A里进行了说明:
在实践中,我们对GSM8K、ASDiv、SV AMP、CommonsenseQA使用了(Chen et al ., 2023)的CoT注释,并对其他数据集使用了新的LLM提示。对于其他数据集,我们每个问题提示6个CoT注释的LLM。
接下来,让我们直观看一下LLM输出的结果,不妨拿StrategyQA数据集举个例子:
# strategy_qa_6.json
[
{
"instruction": "Hydrogen's atomic number squared exceeds number of Spice Girls?",
"output": [
"The atomic number of hydrogen is 1. \n\n1 squared is 1.\n\nThere were 5 Spice Girls in the group.\n\n1 is not greater than 5.\n\nTherefore, the statement \"Hydrogen's atomic number squared exceeds the number of Spice Girls\" is false.",
"The atomic number of hydrogen is 1, so 1 squared is 1. The number of Spice Girls is 4. \n\n1 squared is 1, which is less than 4. Therefore, the statement \"Hydrogen's atomic number squared exceeds the number of Spice Girls\" is false.",
"First, let's find the atomic number of hydrogen. Hydrogen has an atomic number of 1.\n\nNext, let's square the atomic number of hydrogen: 1^2 = 1.\n\nNow, let's count the number of Spice Girls. The Spice Girls were a British girl group formed in 1994 and consisted of five members: Melanie Brown (Scary Spice), Melanie Chisholm (Sporty Spice), Emma Bunton (Baby Spice), Geri Halliwell (Ginger Spice), and Victoria Beckham (Posh Spice).\n\nThere are five Spice Girls.\n\nFinally, let's compare the squared atomic number of hydrogen (1) to the number of Spice Girls (5). Since 1 is less than 5, the statement \"Hydrogen's atomic number squared exceeds the number of Spice Girls\" is false.",
"The atomic number of hydrogen is 1. Therefore, 1 squared is equal to 1.\n\nThe number of Spice Girls is 5.\n\nSince 1 squared (1) is less than the number of Spice Girls (5), the statement \"Hydrogen's atomic number squared exceeds the number of Spice Girls\" is false.",
"The atomic number of hydrogen is 1, so when squared it becomes 1^2 = 1. \n\nThe number of Spice Girls is 5. \n\nTherefore, 1 (hydrogen's atomic number squared) is less than 5 (number of Spice Girls).",
"First, let's determine the atomic number of hydrogen. Hydrogen's atomic number is 1.\n\nNext, let's square the atomic number of hydrogen:\n\n1^2 = 1\n\nNow, let's count the number of Spice Girls. The Spice Girls were a British girl group consisting of 5 members.\n\nSo, 1 (hydrogen's atomic number squared) is less than 5 (number of Spice Girls).\n\nTherefore, the statement \"Hydrogen's atomic number squared exceeds the number of Spice Girls\" is false."
],
"label": "No"
},
{
"instruction": "Would a pear sink in water?",
"output": [
"1. Pear is generally composed of around 84% water, which means it is less dense than water.\n\n2. Objects sink or float in water based on their density. If an object is less dense than water, it will float. If it is more dense, it will sink.\n\n3. Given that a pear is less dense than water, it should float in water.\n\nConclusion: A pear would float in water, as it is less dense than water.",
"First, let's consider the density of a pear. Most pears are made up of mostly water, which means they are less dense than water. Objects that are less dense than water will float. So, based on this information, a pear would likely float in water rather than sink.",
"First, let's consider the density of a pear. Pears are mostly composed of water, which has a density of about 1 g/cm^3.\n\nNext, let's consider the density of water. Water has a density of 1 g/cm^3.\n\nSince the density of a pear is very close to the density of water, it is likely that a pear would float in water rather than sink. This is because objects that are less dense than water will float, while objects that are more dense will sink.\n\nTherefore, a pear would likely float in water.",
"First, let's consider the density of a pear. Pears are made up of mostly water, so they have a relatively low density. This means that pears are likely to float in water, as objects with lower density than water will float.\n\nSecondly, let's consider the shape of a pear. Pears are usually oval or pear-shaped, which means they have a large surface area compared to their volume. This shape also contributes to their buoyancy in water.\n\nTherefore, based on these considerations, it is likely that a pear would float in water rather than sink.",
"First, we need to consider the density of a pear. Pears are mostly made up of water, which means they have a similar density to water. \n\nNext, we need to consider Archimedes' Principle, which states that an object will sink if it is denser than the fluid it is placed in (in this case, water). \n\nSince pears have a similar density to water, it is likely that a pear would float in water rather than sink. However, there are other factors that could affect whether a pear sinks or floats, such as the shape and size of the pear. \n\nIn conclusion, a pear would most likely float in water rather than sink.",
"First, pears are typically less dense than water, so they should float. However, a pear may sink if it is bruised or rotting, causing it to take on water and become denser. Additionally, if the pear is very ripe and has absorbed a lot of water, it may also sink. Overall, a fresh and ripe pear should float in water."
],
"label": "No"
},
...
]如上所示,为每个问题生成了6个具体的{推理过程-预测答案}对,正如我们在4.2.1所提到的那样。
那么下一步流程是啥呢?
没错,是筛选,因为老师模型输出的{推理过程-预测答案}对中的‘预测答案’不一定和我们数据集的标签吻合(也即输出的可能是错误的推理过程),因此我们就需要筛选掉这部分错误的数据集。(当然这一步并不在prompt文件夹考虑范围内,该文件夹下存储的就是老师模型LLM的输出结果,无论对错)。
6.2.3 main
该文件夹下存储的是8个数据集的训练集和测试集(其中训练集是由prompt中每个问题生成的6个推理过程中随机选择3个组合而成的,当然这3个的预测结果并非一定和标签相吻合,我们只保留与标签相吻合的{推理过程-预测答案}对,这也就是为啥你输出该数据集json文件中的字典对数量是小于等于prompt中字典对数量的3倍)(测试集和原始测试集保持一致)。

接下来,让我们直观看一下对LLM输出进行(随机3+筛选后)的结果,不妨拿StrategyQA数据集举个例子:
# data\main\strategy_qa_3_train.json
[
{
"input": "Hydrogen's atomic number squared exceeds number of Spice Girls?",
"chain": "First, let's determine the atomic number of hydrogen. Hydrogen's atomic number is 1.\n\nNext, let's square the atomic number of hydrogen:\n\n1^2 = 1\n\nNow, let's count the number of Spice Girls. The Spice Girls were a British girl group consisting of 5 members.\n\nSo, 1 (hydrogen's atomic number squared) is less than 5 (number of Spice Girls).\n\nTherefore, the statement \"Hydrogen's atomic number squared exceeds the number of Spice Girls\" is false.",
"answer": "No",
"initial_correct": true
},
{
"input": "Hydrogen's atomic number squared exceeds number of Spice Girls?",
"chain": "The atomic number of hydrogen is 1. \n\n1 squared is 1.\n\nThere were 5 Spice Girls in the group.\n\n1 is not greater than 5.\n\nTherefore, the statement \"Hydrogen's atomic number squared exceeds the number of Spice Girls\" is false.",
"answer": "No",
"initial_correct": true
},
{
"input": "Hydrogen's atomic number squared exceeds number of Spice Girls?",
"chain": "The atomic number of hydrogen is 1, so when squared it becomes 1^2 = 1. \n\nThe number of Spice Girls is 5. \n\nTherefore, 1 (hydrogen's atomic number squared) is less than 5 (number of Spice Girls).",
"answer": "No",
"initial_correct": true
},
{
"input": "Would a pear sink in water?",
"chain": "First, pears are typically less dense than water, so they should float. However, a pear may sink if it is bruised or rotting, causing it to take on water and become denser. Additionally, if the pear is very ripe and has absorbed a lot of water, it may also sink. Overall, a fresh and ripe pear should float in water.",
"answer": "No",
"initial_correct": true
},
{
"input": "Would a pear sink in water?",
"chain": "First, let's consider the density of a pear. Pears are mostly composed of water, which has a density of about 1 g/cm^3.\n\nNext, let's consider the density of water. Water has a density of 1 g/cm^3.\n\nSince the density of a pear is very close to the density of water, it is likely that a pear would float in water rather than sink. This is because objects that are less dense than water will float, while objects that are more dense will sink.\n\nTherefore, a pear would likely float in water.",
"answer": "No",
"initial_correct": true
},
{
"input": "Would a pear sink in water?",
"chain": "First, let's consider the density of a pear. Most pears are made up of mostly water, which means they are less dense than water. Objects that are less dense than water will float. So, based on this information, a pear would likely float in water rather than sink.",
"answer": "No",
"initial_correct": true
},
...
]那么这个main数据集有啥用呢?
一方面用于训练最后的学生模型;
另一方面用于训练导师模型,如4.2.2小节所示。
6.2.4 aug
该文件夹存储的是已经在main数据集上训练好的导师模型(分别为{t5_large、flan-t5_large}时)重新接受skeleton中的原始问题,并对每个问题生成3个{推理过程,预测结果}对的数据集。
这里不知为何少了GSM8k数据集,只有其他的7个数据集:
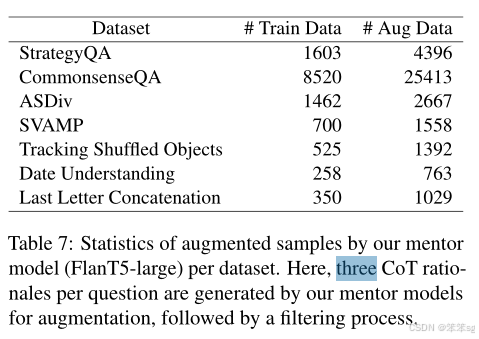
接下来,让我们直观看一下用导师模型对原始数据进行增强的结果(未被筛选,存在预测答案错误的样本),不妨拿StrategyQA数据集举个例子:
# data\aug\flan-t5_large\strategy_qa_rand3_aug3.json
[
{
"input": "Hydrogen's atomic number squared exceeds number of Spice Girls?",
"chain": "First, let's calculate the atomic number of hydrogen: 12 = 1 Now, let's square the atomic number of hydrogen: 12 = 1 Now, let's count the number of Spice Girls: 5 The Spice Girls consist of 5 members: 2 - 1 = 4 Therefore, 1 (hydrogen's atomic number squared) is less than 4 (number of Spice Girls).",
"completion": "no",
"answer": "No",
"initial_correct": true
},
{
"input": "Hydrogen's atomic number squared exceeds number of Spice Girls?",
"chain": "The atomic number of hydrogen is 1, so when squared it becomes 12 = 1. The number of Spice Girls is 5. Therefore, 1 (hydrogen's atomic number squared) is less than 5 (number of Spice Girls).",
"completion": "no",
"answer": "No",
"initial_correct": true
},
{
"input": "Hydrogen's atomic number squared exceeds number of Spice Girls?",
"chain": "The atomic number of hydrogen is 1, so when squared it becomes 12 = 2. The number of Spice Girls is 5. Therefore, 1 (hydrogen's atomic number squared) is less than 5 (number of Spice Girls).",
"completion": "no",
"answer": "No",
"initial_correct": true
},
{
"input": "Would a pear sink in water?",
"chain": "First, pears are denser than water, so they will sink when placed in water. Secondly, the density of a pear determines its ability to float or sink. If a pear is less dense than water, it will most likely float. However, if a pear is more dense than water, it may sink. In conclusion, it is likely that a pear would float in water rather than sink.",
"completion": "no",
"answer": "No",
"initial_correct": true
},
{
"input": "Would a pear sink in water?",
"chain": "First, pears are very light and dense. They are not designed to float in water like objects in the ocean. Secondly, pears are high in moisture, which contributes to their buoyancy. When immersed in water, objects that are less dense than water will float. Conclusion: Based on the size, moisture content, and density of a pear, it is likely that a pear will float in water rather than sink due to its buoyancy.",
"completion": "no",
"answer": "No",
"initial_correct": true
},
{
"input": "Would a pear sink in water?",
"chain": "First, let's consider the density of a pear. Most pears are made up of mostly water, which means that they may float some when placed in water. To determine if a pear will float or sink in water, we need to consider the density of the water and the size of the pear. If the pear is large and has a heavy skin, it may float while the rest of the pear may sink. Next, let's consider the density of an air pea. Air peas have a thin, jelly-like skin that helps them float in water. This air lacks opacity and causes the pear to sink when placed in water. Based on these factors, it is likely that a pear would float in water. There is no reason for the pear to sink if it is not large and has an air pea like the rest of the pear.",
"completion": "yes",
"answer": "No",
"initial_correct": false
},
...
]注意这里的"initial_correct": false就代表预测结果和黄金标签不匹配,后续在训练学生模型时不使用这些样本即可。
6.3 src文件夹剖析
如下这些脚本是主框架调用的基础,可以认为是前置函数,作者将它们分离出来避免主框架变得过于臃肿,不仅可以提高代码的结构化程度和复用性,还能降低维护和扩展的成本。
📁 src # 源代码文件夹
📄 dataset.py # 数据集处理脚本
📄 evaluator.py # 评估模型性能的脚本
📄 functions.py # 通用函数脚本
📄 kd_tools.py # 知识蒸馏工具脚本下面就让我们一一来展开介绍:
6.3.1 dataset.py
前面我们已经介绍过了data文件夹,可以发现每个数据集文件都是以json的形式(嵌套字典)存储的,因此我们需要自定义Dataset类。
那么什么时候需要自定义?什么时候不需要自定义呢?
需要自定义数据类的场景:
- 数据格式复杂且需要特殊处理:数据以嵌套字典、JSON 文件、特定格式的文本、图像-文本对等形式存在,需要自定义解析逻辑。
- 需要动态调整数据加载逻辑:根据任务需要动态切换输入格式。
- 不常见的数据存储方式:数据可能存储在 CSV、SQL 数据库、HDF5 文件中,而库中的默认
Dataset类不支持这些格式。不需要自定义数据类的场景:
- 数据格式简单,库中已有直接支持的工具:例如:MNIST、CIFAR-10 等标准数据集可通过
torchvision.datasets加载。Hugging Face 提供的datasets库支持大多数 NLP 数据集(如 SQuAD、IMDB)。
那么该如何自定义Dataset类呢?这个我们在之前的学习笔记"3 数据读入"已经介绍过了,可以浏览一下:
《深入浅出PyTorch》学习笔记——第三章:PyTorch的主要组成模块-CSDN博客
也即:
定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
- __init__: 用于向类中传入外部参数,同时定义样本集
- __getitem__: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据
- __len__: 用于返回数据集的样本数
但是注意我们这篇论文处理的是NLP的任务,涉及到复杂的数据转换逻辑,因此需要我们再自定义一些数据处理函数。
自定义函数1:format_texts
在6.2里我们详细了解了每个json文件中数据的存储格式,采用的是列表中多个字典结构的方式,但为了适配深度学习模型(特别是语言模型)的数据处理需求,我们需要将其转换为一个包含多个列表的字典结构,因为深度学习模型(如 T5、GPT)通常需要批量输入数据,而这些数据需要满足以下特性:
- 统一结构:模型的输入和标签需要是统一的张量格式(如
input_ids、attention_mask等),不能直接处理列表中嵌套的字典。 - 高效批量处理:在训练过程中,通过
DataLoader按批次加载数据,每个批次需要具有一致的格式。将字典列表分离为独立的键值对列表(如input和labels),有助于后续批量处理和转张量。
def format_texts(self):
"""
格式化输入和标签为字符串列表。
"""
formatted_data = dict()
inputs = []
labels = []
for s in self.data:
inputs.append(s["input"].strip()) # 去除输入中的多余空格
if self.dataset_type == "train":
labels.append(
f"{s['chain'].strip()} --> {s['answer'].strip()}"
) # 格式化标签,包含推理链和答案
formatted_data["input"] = inputs
formatted_data["labels"] = labels
return formatted_data[ 举个例子 ]:
原始数据:
[
{
"input": "Question 1",
"chain": "Reasoning for Question 1",
"answer": "Answer 1"
},
{
"input": "Question 2",
"chain": "Reasoning for Question 2",
"answer": "Answer 2"
}
]
处理后的数据:
{
"input": ["Question 1", "Question 2"],
"labels": ["Reasoning for Question 1 --> Answer 1", "Reasoning for Question 2 --> Answer 2"]
}
自定义函数2:tokenize_texts
这个函数主要是按照模型类型对格式化的输入和标签进行分词操作,得到"input_ids"、"attention_mask"等字段。
在这篇论文中,老师模型使用的是GPT,导师模型使用的是T5,因此对这两个分开进行处理即可。
先来看T5:
T5采用的是Encoder-Decoder架构,进行右填充即可,它有两个部分:Encoder用于处理输入文本,Decoder用于生成输出(通常是文本)。在这种架构中,输入和输出的标记化分别需要不同的处理方式。我们需要得到4个字段,分别为:
"input_ids"、"attention_mask"、"labels"、"decoder_attention_mask"。
如果你对"input_ids"、"attention_mask"这些还不熟悉,可以参见我之前的文章:
if "t5" in self.model_type:
inputs = self.tokenizer(
self.formatted_texts["input"], **self.tokenizer_kwargs
)
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
result = {"input_ids": input_ids, "attention_mask": attention_mask}
# 如果是训练集,处理标签的分词
if self.dataset_type == "train":
labels = self.tokenizer(
self.formatted_texts["labels"], **self.tokenizer_kwargs
)
label_ids = labels["input_ids"]
decoder_attention_mask = labels["attention_mask"]
label_ids[~decoder_attention_mask.bool()] = -100 # 忽略填充位置的损失
result.update(
{
"decoder_attention_mask": decoder_attention_mask,
"labels": label_ids,
}
)QA:
1)为啥需要对label_ids的填充位置赋值为-100?
答:如果你不将填充位置的标签设置为 -100,那么计算损失时,模型会错误地认为填充位置也有实际的目标输出。因此计算出的损失会误导模型,从而影响训练过程。可以看看下面这个文章:
input_ids`、`attention_mask` 和 `labels` 在训练过程中的作用和数据流动变化-CSDN博客
再来看GPT:
GPT采用的是Decoder-Only架构,进行左填充即可,Decoder的输入和labels是通过自回归生成的,模型依赖于已经生成的token来预测下一个token,因此只需要处理输入和标签。我们需要得到3个字段,分别为:
"input_ids"、"attention_mask"、"labels"
elif self.model_type in ["gpt2", "opt"]:
it = self.tokenizer(
self.formatted_texts["input"], max_length=512, truncation=True
)
iids = it["input_ids"]
if self.dataset_type == "train":
lids = self.tokenizer(
self.formatted_texts["labels"], max_length=512, truncation=True
)["input_ids"]
else:
lids = [
list() for _ in range(len(iids))
] # 测试集不需要计算损失,所以这里创建空列表的做法是为了让代码结构一致
# 手动应用左侧填充
lengths = [] # 存储每个样本(输入 + 标签)总长度的列表
input_ids = [] # 存储处理后的输入ID的列表
attention_mask = [] # 存储每个样本的attention mask的列表
label_ids = [] # 存储处理后的标签ID的列表
# 对每个输入和标签进行处理
for iid, lid in zip(iids, lids): # 遍历输入(iid)和标签(lid)
lengths.append(
len(iid) + len(lid)
) # 计算每个样本的总长度(输入 + 标签的长度)
input_ids.append(iid + lid) # 合并输入和标签,形成一个新的输入ID序列
attention_mask.append(
[1] * (len(iid) + len(lid))
) # 为输入和标签的每个标记生成一个mask,1表示该位置是有效的
label_ids.append(
[-100] * len(iid) + lid
) # 对于输入部分,填充-100表示不计算损失,对于标签部分,保留标签ID
# 将长度转换为张量
lengths = torch.tensor(lengths)
# 计算填充长度,保证每个样本的长度一致,填充长度等于最大长度减去当前样本的长度
pad_lengths = (lengths.max() - lengths).tolist()
# 对每个样本进行左侧填充,保证输入的长度一致
for i, l in enumerate(pad_lengths): # 遍历每个样本
input_ids[i] = [self.tokenizer.pad_token_id] * l + input_ids[
i
] # 在输入ID的前面填充pad_token_id
attention_mask[i] = [0] * l + attention_mask[
i
] # 在attention_mask的前面填充0,表示这些位置是填充部分
label_ids[i] = [-100] * l + label_ids[
i
] # 对标签部分,填充-100,表示填充部分不计算损失
# 将所有的处理结果转化为张量并返回
result = {
"input_ids": torch.tensor(input_ids, dtype=torch.long), # 输入ID张量
"attention_mask": torch.tensor(
attention_mask, dtype=torch.long
), # attention mask张量
"labels": torch.tensor(label_ids, dtype=torch.long), # 标签ID张量
}QA:
1)为啥采用左对齐而不是右对齐?
答:
- encoder-only模型主要采用right-padding的原因是,填充右侧的方式很直观,并且我们有时需要获得每个句子的首个token(cls),左侧不对齐不好操作
- decoder-only模型采用 left-padding的原因是, 模型的输入是对模型输入的延续(模型的输出中会带着输入,并在输入后边补充输出),如果采用right-padding,会导致大量的[pad]token夹在模型的输入和输入之间,不利于处理结果.并且模型的输出句子的语义也被pad打乱了,输入并不直观.此外,decoder-only的模型并不需要cls等开头的token来做额外的处理,right-padding在decoder-only的模型中没有任何优势.
- decoder-only的模型也可以使用right-padding方式,如果设置 skip_special_tokens=True 也应该会获得正确的输入,但是不建议使用.
可以参考下面这个文章:
大部分的大模型(LLM)采用左填充(left-padding)的原因 - 知乎
自定义函数3:store_raw_answers
该函数用于提取数据中的原始答案作为黄金标签(之前的那些标签是包含了推理过程的,是想让导师模型按照那种格式输出的)
def store_raw_answers(self):
"""
提取数据中的原始答案。
"""
raw_answers = [s["answer"] for s in self.data]
return raw_answers6.3.2 evaluator.py
这个脚本主要用来自定义一个模型评估类,通过规范统一模型预测值与真实标签的格式,然后再按照定义的匹配规则进行比较,基本不涉及复杂的逻辑。
import re
from typing import List, Tuple, Dict
# 定义不同任务类型对应的预测前缀
PREDICTION_PREFIXES = {
None: None, # 无前缀
"zs": None, # 无前缀
"ft_natural": None, # 无前缀
"ft_token": None, # 无前缀
"fs_cot": "The answer is", # 预测前缀为 "The answer is"
"zs_cot": None, # 无前缀
"ft_cot_natural": "Therefore, the answer is", # 预测前缀为 "Therefore, the answer is"
"ft_cot_token": "-->", # 预测前缀为 "-->"
}
class Evaluator:
"""
用于评估模型预测的类,支持不同数据集和任务类型。
"""
def __init__(self, dataset_key, task_type="ft_cot_token"):
"""
初始化函数,设置数据集和任务类型。
:param dataset_key: 数据集的标识符,例如 "gsm8k" 或 "commonsense_qa"
:param task_type: 任务类型,用于设置预测前缀
"""
self.dataset_key = dataset_key # 存储数据集标识符
self.prediction_prefix = PREDICTION_PREFIXES[
task_type
] # 根据任务类型获取预测前缀
def _extract_prediction_candidates(self, prediction: str) -> List[str]:
"""
从预测字符串中提取所有符合数据集答案格式的候选答案。
:param prediction: 预测的结果字符串
:return: 可能的候选答案列表
"""
original_prediction = [prediction] # 默认返回原始预测
# 根据不同的数据集,提取符合格式的答案
if self.dataset_key in ("aqua", "commonsense_qa"):
# 对于"aqua"和"commonsense_qa"数据集,预测的答案应该是[A, B, C, D, E]选项之一
prediction = re.findall(r"[ABCDE]", prediction)
elif self.dataset_key == "date_understanding":
# 对于"date_understanding"数据集,预测的答案应该是[A, B, C, D, E, F]选项之一
prediction = re.findall(r"[ABCDEF]", prediction)
elif self.dataset_key in ("tracking_shuffled_objects"):
# 对于"tracking_shuffled_objects"数据集,预测的答案应该是[A, B, C]选项之一
prediction = re.findall(r"[ABC]", prediction)
elif self.dataset_key in (
"gsm8k",
"addsub",
"multiarith",
"svamp",
"single_eq",
"asdiv",
):
# 对于这些数据集,预测结果通常是数字类型
prediction = prediction.replace(",", "") # 去掉逗号
prediction = re.findall(r"-?\d+(?:\.\d+)?", prediction) # 正则提取数字
if self.dataset_key in ("addsub", "svamp", "single_eq"):
# 如果是加法、减法或方程数据集,将预测转换为浮点数
prediction = [float(s) for s in prediction]
elif self.dataset_key in ("strategy_qa", "coin_flip"):
# 对于"strategy_qa"和"coin_flip"数据集,预测结果应该是"yes"或"no"
prediction = prediction.lower() # 转为小写
prediction = re.sub(
"\"|'|\n|\.|\s|\:|\,", " ", prediction
) # 去掉多余的符号
prediction = prediction.split(" ") # 分词
prediction = [
i for i in prediction if i in ("yes", "no")
] # 只保留"yes"或"no"
elif self.dataset_key == "last_letter_concatenation":
# 对于"last_letter_concatenation"数据集,预测是一个单一的字符串
prediction = re.sub("\"|'|\n|\.|\s", "", prediction) # 去掉多余的符号
prediction = [prediction]
else:
# 如果数据集无效,抛出异常
raise ValueError("Invalid dataset: {}".format(self.dataset_key))
if len(prediction) != 0:
return prediction # 如果提取到有效的预测候选,则返回
else:
return original_prediction # 否则返回原始预测
def cleanse_prediction(self, completion, return_all=False):
"""
对模型输出的预测进行清洗,处理并返回候选答案。
:param completion: 模型的预测结果
:param return_all: 是否返回所有候选答案,默认为False,返回第一个答案
:return: 清洗后的预测答案
"""
if self.prediction_prefix is None:
# 如果没有前缀,直接提取所有候选答案
predictions = self._extract_prediction_candidates(completion)
first = True
else:
# 如果有前缀,查找前缀所在位置并从该位置开始提取预测
index = completion.find(self.prediction_prefix)
if index == -1:
# 如果找不到前缀,候选答案为整个预测结果
predictions = self._extract_prediction_candidates(completion)
first = False
else:
# 如果找到前缀,从前缀后开始提取候选答案
start_of_answer = index + len(self.prediction_prefix)
predictions = self._extract_prediction_candidates(
completion[start_of_answer:]
)
first = True
# 根据需要返回单个答案或所有候选答案
answer = None
if predictions:
answer = predictions[0] if first else predictions[-1]
return (answer, predictions) if return_all else answer
def cleanse_answer(self, answer: str) -> str:
"""
对真实答案进行清洗,格式化为与预测结果相同的形式。
:param answer: 真实答案字符串
:return: 清洗后的答案
"""
if self.dataset_key in [
"gsm8k",
"addsub",
"multiarith",
"svamp",
"single_eq",
"asdiv",
]:
# 对于这些数据集,答案中的逗号需要去掉
answer = answer.replace(",", "")
if self.dataset_key == "strategy_qa":
# 对于"strategy_qa"数据集,答案需要转换为小写
answer = answer.lower()
if self.dataset_key in ["addsub", "svamp", "single_eq"]:
# 对于加法、减法和方程数据集,答案需要转换为浮点数
answer = float(answer)
# 针对特定数据集的额外处理
elif self.dataset_key == "commonsense_qa":
# 对于"commonsense_qa",答案为一个单词的首字母
answer = answer.split()[0][0]
return answer
def _compare_prediction_and_answer(self, prediction, answer) -> bool:
"""
比较预测结果和真实答案是否匹配。
:param prediction: 预测的结果
:param answer: 真实的答案
:return: 如果匹配,返回True,否则返回False
"""
if self.dataset_key in ("addsub", "svamp", "single_eq"):
if type(prediction) is float or type(prediction) is int:
# 对于加法、减法和方程数据集,允许误差范围内的匹配
return prediction is not None and abs(prediction - answer) <= 1e-6
else:
return False
elif self.dataset_key in ("last_letter_concatenation"):
# 对于"last_letter_concatenation"数据集,匹配时不区分大小写
return prediction is not None and prediction.lower() == answer.lower()
else:
# 对于其他数据集,完全匹配
return prediction is not None and prediction == answer
def evaluate_single_instance(self, prediction, answer) -> bool:
"""
评估单个预测结果与真实答案的匹配情况。
:param prediction: 预测的结果
:param answer: 真实的答案
:return: 如果匹配,返回True,否则返回False
"""
# 清洗预测结果
cleanse_prediction = self.cleanse_prediction(prediction)
# 清洗真实答案
cleanse_answer = self.cleanse_answer(answer)
# 比较清洗后的预测和答案
evaluation = self._compare_prediction_and_answer(
cleanse_prediction, cleanse_answer
)
return evaluation
这里简单解释一下“PREDICTION_PREFIXES”的作用
我在用训练集对一个模型进行训练后,在这种特定任务上,它在测试集上的输出结果会包含很多话(因为大模型喜欢长篇大论,我这个就是一般情况下答案的前缀,比如经验前缀是“-->”,大模型输出“因为...所以正确答案是-->C”,这个前缀其实就是这种任务下大模型输出的经验格式,用于准确定位答案抽离出来方便后续评估。
6.3.3 functions.py
主要定义了三个前置函数,分别为:
get_model_and_tokenizer:这个函数根据输入的模型类型(如flan-t5,t5,gpt2)和模型大小,加载相应的预训练模型和 tokenizer。支持指定设备(如 CPU 或 GPU)以及对某些大模型(如flan-t5)进行LoRA微调配置。seed_everything:用于设置随机种子,使得实验的结果可复现。这对于深度学习模型的训练和评估非常重要。return_evaluations_in_boolean:这个函数将原始预测和答案进行清洗(格式化),然后比较它们是否匹配,返回布尔值的评估结果。可选地,还可以返回清洗后的预测结果。
import os, sys
sys.path.append(
os.getcwd()
) # 将当前工作目录添加到路径中,以便后续可以导入当前目录中的模块
import json
import random
import torch
import math
import numpy as np
from collections import Counter # 用于统计元素出现次数
from peft import (
LoraConfig,
get_peft_model,
prepare_model_for_int8_training,
TaskType,
) # 导入PEFT(Parameter Efficient Fine-Tuning)相关的库
from transformers import (
AutoModelForSeq2SeqLM,
AutoModelForCausalLM,
AutoTokenizer,
T5ForConditionalGeneration,
T5TokenizerFast,
GPT2LMHeadModel,
GPT2Tokenizer,
GPT2Model,
) # 导入transformers库中的模型和tokenizer
from torch.nn.functional import cross_entropy # 导入交叉熵损失函数
def get_model_and_tokenizer(
model_type,
model_size,
device,
model_max_length=512,
tokenizer_kwargs={},
all_cuda=True,
):
"""
根据模型类型和大小,加载相应的预训练模型和tokenizer,并进行一些特定设置
参数:
model_type: 模型类型(如 flan-t5, t5, gpt2)
model_size: 模型大小(如 small, xl, xxl)
device: 模型运行设备(如 'cuda', 'cpu')
model_max_length: 模型输入的最大长度(默认为 512)
tokenizer_kwargs: 传递给tokenizer的额外参数
all_cuda: 是否将模型加载到所有可用的CUDA设备上(默认为True)
返回:
model, tokenizer: 加载的模型和tokenizer
"""
if model_type == "flan-t5":
model_name = f"google/{model_type}-{model_size}"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name) # 加载seq2seq模型
tokenizer = AutoTokenizer.from_pretrained(
model_name, model_max_length=model_max_length, **tokenizer_kwargs
)
if model_size == "xxl":
model = AutoModelForSeq2SeqLM.from_pretrained(
model_name, device_map="auto", torch_dtype=torch.bfloat16
) # 使用bfloat16类型和自动设备映射加载模型
lora_config = LoraConfig(
r=128, # LoRA中低秩矩阵的维度。r值越大,低秩矩阵越复杂,模型容量越大,计算开销也会增加。
lora_alpha=32, # LoRA的放大因子,用于缩放低秩矩阵的影响力。这个参数控制低秩矩阵在模型训练中的贡献大小。
target_modules=[
"q",
"v",
], # 指定LoRA应用的目标模块。这里应用于Transformer模型的查询(q)和值(v)模块。通常这些模块负责计算注意力。
lora_dropout=0.05, # LoRA层的Dropout率,用于防止过拟合。Dropout有助于在训练时随机丢弃部分神经元,以增强模型的泛化能力。
bias="none", # 指定是否使用偏置。设置为 "none" 表示不使用偏置,这通常用于降低模型的复杂度。
task_type=TaskType.SEQ_2_SEQ_LM, # 任务类型,表示这是一个序列到序列的语言建模任务(Sequence-to-Sequence Language Modeling)。LoRA配置适应这个任务的特点。
)
model = get_peft_model(model, lora_config) # PEFT配置
model.print_trainable_parameters()
elif model_size == "xl":
model = AutoModelForSeq2SeqLM.from_pretrained(
model_name, torch_dtype=torch.bfloat16
).to(device)
lora_config = LoraConfig(
r=64,
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM,
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
for n, p in model.named_parameters():
if "lm_head" in n:
p.requires_grad = True # 只对语言模型的最后一层进行训练
elif model_type == "t5":
if not model_size in ["xl", "xxl"]:
model_name = f"{model_type}-{model_size}"
else:
model_name = f"google/{model_type}-v1_1-{model_size}"
model = T5ForConditionalGeneration.from_pretrained(
model_name
) # 加载T5条件生成模型
tokenizer = T5TokenizerFast.from_pretrained(
model_name, model_max_length=model_max_length, **tokenizer_kwargs
)
elif model_type == "gpt2":
if model_size == "small":
model_name = "gpt2"
else:
model_name = f"gpt2-{model_size}"
model = GPT2LMHeadModel.from_pretrained(model_name) # 加载GPT2语言模型
tokenizer = GPT2Tokenizer.from_pretrained(
model_name, model_max_length=model_max_length, **tokenizer_kwargs
)
tokenizer.pad_token = tokenizer.eos_token # 设置pad_token为eos_token(结束符)
else:
raise NotImplementedError(
f"{model_type} not implemented yet!"
) # 如果模型类型不支持,则抛出异常
if all_cuda:
model = (
model.to(device) if torch.cuda.is_available() else model.to("cpu")
) # 将模型加载到CUDA设备或CPU
return model, tokenizer
def seed_everything(seed: int = 42):
"""
设置随机种子,确保实验结果可复现
"""
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed) # 设置CUDA的随机种子
torch.backends.cudnn.deterministic = True # 保证每次运算的结果相同
torch.backends.cudnn.benchmark = True # 启用CuDNN优化
def return_evaluations_in_boolean(
evaluator, raw_pred, raw_ans, return_cleansed_predictions=False
):
"""
将原始的预测结果和答案进行清洗和格式化,并返回一个布尔值的评估结果
参数:
evaluator: 用于评估的对象
raw_pred: 原始预测结果列表
raw_ans: 原始答案列表
return_cleansed_predictions: 是否返回清洗后的预测结果(默认为False)
返回:
evaluations: 布尔值的评估结果列表
cleansed_predictions(可选): 清洗后的预测结果列表
"""
c_pred = [
evaluator.cleanse_prediction(pred) for pred in raw_pred
] # list[str] 清洗预测结果
c_answ = [
evaluator.cleanse_answer(answer) for answer in raw_ans
] # list[str] 清洗真实答案
assert len(c_answ) == len(
c_pred
), f"Prediction: {len(c_pred)}, Answer: {len(c_answ)} does not match!" # 确保预测和答案数量一致
evaluations = [
evaluator._compare_prediction_and_answer(pred, ans)
for pred, ans in zip(c_pred, c_answ)
] # 比较预测和答案是否匹配
if return_cleansed_predictions:
return evaluations, c_pred # 如果要求返回清洗后的预测结果,则返回
else:
return evaluations # 否则只返回布尔值的评估结果
注意:这里的模型"flan-t5"训练时用的是LoRA对其参数进行高效微调;对于"t5"和"gpt2"训练时则是正常的流程。
6.3.4 kd_tools.py
这个函数主要定义了一个类,该类实现了一个基本的知识蒸馏(Knowledge Distillation, KD)损失函数。
之前我们在“《深入浅出Pytorch》第6章”提到了自定义损失函数的两种方式:1)用函数;2)用类。链接如下:
《深入浅出PyTorch》学习笔记——第六章:PyTorch进阶训练技巧-CSDN博客
KL散度损失函数用于衡量两个概率分布之间的差异。
import torch
import torch.nn as nn
import torch.nn.functional as F
class VanillaKDLoss(nn.Module):
"""
该类实现了一个基本的知识蒸馏(Knowledge Distillation, KD)损失函数。
知识蒸馏的目的是通过让学生模型(student)模仿教师模型(teacher)的输出分布,
以此来提升学生模型的性能。
"""
def __init__(self, temperature=2.0, eps=1e-8):
"""
初始化VanillaKDLoss类,设置温度和epsilon。
参数:
- temperature:温度超参数,用于平滑教师模型的输出概率分布
- eps:一个非常小的值,避免数值不稳定,尤其在计算交叉熵时使用
"""
super(VanillaKDLoss, self).__init__()
self.temperature = temperature # 温度,用于调整softmax的平滑度
self.eps = eps # 防止数值不稳定的极小值
def forward(self, student_logits, teacher_logits):
"""
前向传播方法,计算学生模型和教师模型之间的知识蒸馏损失。
参数:
- student_logits:学生模型的预测logits,形状为(batch_size, num_classes)
- teacher_logits:教师模型的预测logits,形状为(batch_size, num_classes)
返回:
- loss:计算出的知识蒸馏损失值
"""
# 对学生模型的logits进行温度调节并计算log-softmax值
p_student = F.log_softmax(student_logits / self.temperature, dim=-1)
# 对教师模型的logits进行温度调节并计算softmax值
p_teacher = F.softmax(teacher_logits / self.temperature, dim=-1)
# 使用KL散度来计算学生模型和教师模型之间的差异
loss = nn.KLDivLoss(reduction="batchmean")(p_student, p_teacher)
# 返回计算出的损失值
return loss
如何使用这个损失函数呢?浅浅举个例子:
# 假设 student_model 和 teacher_model 是已经定义好的模型
# student_logits 是学生模型的输出
# teacher_logits 是教师模型的输出
import torch
import torch.nn as nn
import torch.optim as optim
# 假设我们已经有学生模型和教师模型
student_model = ... # 你的学生模型
teacher_model = ... # 你的教师模型
kd_loss = VanillaKDLoss(temperature=2.0)
# 假设我们有数据
input_data = torch.randn(32, 3, 224, 224) # 假设输入是32个样本的图片
target_data = torch.randint(0, 10, (32,)) # 假设目标是10类分类任务
# 优化器
optimizer = optim.Adam(student_model.parameters(), lr=0.001)
# 训练过程
for epoch in range(num_epochs):
optimizer.zero_grad()
# 获取教师模型和学生模型的输出
teacher_logits = teacher_model(input_data)
student_logits = student_model(input_data)
# 计算知识蒸馏损失
loss = kd_loss(student_logits, teacher_logits)
# 反向传播和优化
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}")
6.4 scripts文件夹剖析
6.4.1 fine_tune_cot.py
这个脚本主要是用来对导师模型进行训练的。
前置条件:手头已经有了data/prompt下的4种老师模型生成的多步推理过程(每个问题6个)以及另外4种从别的地方可以获取到的。
整体的步骤较为清晰,和大多数DL项目的训练流程一致,如下所示:
1)导包
2)定义命令行参数(数据集名称、从老师模型生成的推理过程中随机选择的数量、训练批次大小、测试批次大小、模型类型、模型大小、模型最大输入长度、训练轮次、学习率、随机种子)
3)设置随机种子
4)配置日志记录器
5)检测是否有GPU可用
6)输出训练配置信息
7)配置模型和分词器(functions.get_model_and_tokenizer())
8)初始化评估器(evaluator.Evaluator())
9)加载并准备数据集
10)读取JSON数据并过滤无效样本,只保留初始预测正确的样本(老师模型生成的“推理过程->答案”中预测对的)
11)创建自定义数据集(训练集和测试集)(dataset.FinetuneCoTDataset(Dataset))
12)创建训练集和测试集的数据加载器
13)配置优化器
14)开始训练和评估(保存最佳结果、记录测试准确率等)
15)保存最佳模型、打印最终信息、记录最佳准确率如果你还不太了解argparse,请参见下面笔记中“7 使用argparse进行调参” 章节:
《深入浅出PyTorch》学习笔记——第六章:PyTorch进阶训练技巧-CSDN博客
如果你还不太了解 tensorboardX|torch.utils.tensorboard 中的SummaryWriter,请参见下面笔记中“3 使用TensorBoard可视化训练过程” 章节:
《深入浅出PyTorch》学习笔记——第七章:PyTorch可视化-CSDN博客
import os, sys # 导入操作系统模块(os)和系统模块(sys)
sys.path.append(os.getcwd()) # 将当前工作目录添加到Python路径中,方便模块导入
os.environ["TOKENIZERS_PARALLELISM"] = "false" # 禁用tokenizers库的并行处理,避免冲突
# 导入相关的库
import copy # 用于对象的深拷贝和浅拷贝操作
import json # 用于JSON数据的加载和保存
import datetime # 用于获取日期和时间
import argparse # 用于解析命令行参数
import torch # PyTorch深度学习框架
import torch.nn as nn # PyTorch的神经网络模块
import numpy as np # 用于数值计算的库
from torch.utils.data import DataLoader # 用于加载和处理数据集
from torch.nn.utils import clip_grad_norm_ # 用于裁剪梯度,避免梯度爆炸
from torch.utils.tensorboard import (
SummaryWriter,
) # 用于记录训练过程,支持TensorBoard可视化
from transformers import StoppingCriteriaList # 用于控制生成模型停止的条件
from tqdm.auto import tqdm # 用于显示进度条,支持终端和Jupyter Notebook
# 导入自定义模块
from src.dataset import FinetuneCoTDataset # 自定义数据集类,用于微调CoT模型
from src.functions import * # 自定义函数模块
from src.evaluator import Evaluator # 自定义评估器,用于计算模型性能
# 定义命令行参数
parser = argparse.ArgumentParser()
parser.add_argument(
"--dataset_key", type=str, default="tracking_shuffled_objects"
) # 数据集关键字
parser.add_argument("--num_random_selection", type=int, default=3) # 随机选择的数量
parser.add_argument("--batch_size", type=int, default=8) # 训练批次大小
parser.add_argument("--test_batch_size", type=int, default=8) # 测试批次大小
parser.add_argument("--model_type", type=str, default="t5") # 模型类型
parser.add_argument("--model_size", type=str, default="small") # 模型大小
parser.add_argument("--model_max_length", type=int, default=512) # 模型的最大输入长度
parser.add_argument("--epoch", type=int, default=20) # 训练的轮次
parser.add_argument("--lr", type=float, default=3e-4) # 学习率
parser.add_argument("--seed", type=int, default=42) # 随机种子,用于结果复现
args = parser.parse_args() # 解析命令行参数
# 设置随机种子,确保实验可重复
seed_everything(args.seed)
# 配置日志记录器,用于记录训练过程
writer = SummaryWriter(
comment=f"FTCoT_{args.dataset_key}_{args.num_random_selection}_{args.model_type}_{args.model_size}_{args.lr}_{args.seed}"
) # comment 参数是用来给日志文件名添加注释信息的,主要作用是让生成的日志目录更加直观和便于区分。个日志目录的名字通常是由当前时间戳和你提供的 comment 参数拼接而成的。
device = (
"cuda" if torch.cuda.is_available() else "cpu"
) # 检测是否有GPU可用,否则使用CPU
# 输出训练配置信息
print("#" * 10, "Fine-tune-CoT Training", "#" * 10)
print("\n".join(f"{k.ljust(25)}:{v}" for k, v in vars(args).items()))
# 配置模型和分词器
tokenizer_kwargs = {
"padding": "longest", # 按最长样本长度填充
"max_length": args.model_max_length, # 最大输入长度
"truncation": True, # 超过最大长度时截断
"return_tensors": "pt", # 返回PyTorch张量
}
model, tokenizer = get_model_and_tokenizer(
model_type=args.model_type,
model_size=args.model_size,
model_max_length=args.model_max_length,
tokenizer_kwargs=tokenizer_kwargs,
device=device,
)
evaluator = Evaluator(args.dataset_key, task_type="ft_cot_token") # 初始化评估器
# 加载并准备数据集
train_data_path = f"data/main/{args.dataset_key}_{args.num_random_selection}_train.json" # 训练数据路径
test_data_path = f"data/main/{args.dataset_key}_test.json" # 测试数据路径
# 读取JSON数据并过滤无效样本
with open(train_data_path) as f_train, open(test_data_path) as f_test:
train_json_data = json.load(f_train)
test_json_data = json.load(f_test)
train_json_data = [
s for s in train_json_data if s["initial_correct"] == True
] # 只保留初始预测正确的样本
# 创建自定义数据集
train_dataset = FinetuneCoTDataset(
dataset_key=args.dataset_key,
dataset_type="train",
data=train_json_data,
model_type=args.model_type,
tokenizer=tokenizer,
tokenizer_kwargs=tokenizer_kwargs,
)
test_dataset = FinetuneCoTDataset(
dataset_key=args.dataset_key,
dataset_type="test",
data=test_json_data,
model_type=args.model_type,
tokenizer=tokenizer,
tokenizer_kwargs=tokenizer_kwargs,
)
# 创建数据加载器
train_dataloader = DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True
) # 在每个 epoch 中打乱数据可以提高模型的泛化能力,避免模型学习到固定的样本顺序,从而更好地适应训练数据的多样性。
test_dataloader = DataLoader(
test_dataset, batch_size=args.test_batch_size, shuffle=False
) # 在测试集上不需要打乱数据,因为测试集的目的是评估模型的性能,而不是训练模型。
# 释放加载后的JSON数据,节省内存
del train_json_data
del test_json_data
# 配置优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr) # 使用AdamW优化器
# 开始训练和评估
step = 0 # 全局步骤计数
best_accuracy = 0 # 最佳准确率
best_epoch = 0 # 最佳模型所在的训练轮次
best_gen = [] # 最佳模型生成的结果
for epoch in range(1, args.epoch + 1):
model = model.train() # 设置模型为训练模式
total_loss = 0.0 # 累计损失
tqdm_format = tqdm(
train_dataloader,
total=len(train_dataloader),
bar_format="{l_bar}{bar:25}{r_bar}",
desc=f"Epoch #{epoch}",
ascii=True,
) # 用于显示进度条,支持终端和Jupyter Notebook
for train_data in tqdm_format: # 遍历训练数据
# 准备输入数据
kwargs = {
"input_ids": train_data["input_ids"],
"attention_mask": train_data["attention_mask"],
"labels": train_data["labels"],
}
if "t5" in args.model_type:
kwargs["decoder_attention_mask"] = train_data["decoder_attention_mask"]
kwargs = {
k: v.to(device) for k, v in kwargs.items()
} # 将数据移动到设备(GPU或CPU)
# 前向传播与反向传播
optimizer.zero_grad() # 梯度清零
outputs = model(**kwargs) # 模型前向计算
loss = outputs["loss"] # 获取损失值
loss.backward() # 反向传播
optimizer.step() # 更新模型参数
total_loss += loss # 累加损失
step += 1 # 更新全局步数计数
# 每一步记录损失
writer.add_scalar(f"{args.dataset_key}/{args.seed}/loss/step", loss, step)
# 每轮记录总损失
writer.add_scalar(f"{args.dataset_key}/{args.seed}/loss/epoch", total_loss, epoch)
# 评估模型性能
raw_predictions = []
generation_kwargs = {"max_length": 512}
if "gpt" in args.model_type: # 如果模型类型包含"gpt",则设置pad_token_id参数
generation_kwargs["pad_token_id"] = tokenizer.eos_token_id
with torch.no_grad(): # 禁用梯度计算
model = model.to(device)
model = model.eval() # 设置模型为评估模式
tqdm_format = tqdm(
test_dataloader,
total=len(test_dataloader),
bar_format="{l_bar}{bar:25}{r_bar}",
desc=f"Evaluating",
ascii=True,
)
outputs_to_decode = []
for test_samples in tqdm_format:
outputs = model.generate(
test_samples["input_ids"].to(device), **generation_kwargs
).detach()
outputs_to_decode.append(outputs)
raw_predictions = []
for output in outputs_to_decode:
decoded_output = tokenizer.batch_decode(output, skip_special_tokens=True)
raw_predictions.extend(decoded_output)
raw_answers = [s["answer"] for s in test_dataset]
evaluations, c_pred = return_evaluations_in_boolean(
evaluator, raw_predictions, raw_answers, return_cleansed_predictions=True
)
accuracy = evaluations.count(True) / len(evaluations)
if accuracy > best_accuracy:
best_accuracy = accuracy
best_epoch = epoch
best_model = copy.copy(model.state_dict()) # 保存最佳模型
# 保存最佳生成结果
current_best_gen = []
for i, data in enumerate(test_dataset):
result_dict = {
"question": data["input"],
"generation": raw_predictions[i],
"prediction": c_pred[i],
"label": data["answer"],
"correct": evaluations[i],
}
current_best_gen.append(result_dict)
best_gen = current_best_gen
print(
f"{args.dataset_key} || TEST Epoch #{epoch} accuracy: {accuracy} || Current Best: {best_accuracy}"
)
# 每轮记录测试准确率
writer.add_scalar(f"{args.dataset_key}/{args.seed}/accuracy/epoch", accuracy, epoch)
# 释放显存
torch.cuda.empty_cache()
# 训练后处理
# 保存最佳生成结果
generation_dir = f"logs/gen_outputs/ftcot/{args.model_type}_{args.model_size}"
os.makedirs(generation_dir, exist_ok=True)
gen_file_name = f"{args.dataset_key}_rand{args.num_random_selection}_seed{args.seed}_epoch{best_epoch}.json"
with open(os.path.join(generation_dir, gen_file_name), "w") as f:
json.dump(best_gen, f, indent=4)
# 保存最佳模型
model_save_dir = f"logs/models/ftcot/{args.model_type}_{args.model_size}"
os.makedirs(model_save_dir, exist_ok=True)
model_name = (
f"{args.dataset_key}_rand{args.num_random_selection}_lr{args.lr}_seed{args.seed}.pt"
)
torch.save(best_model, os.path.join(model_save_dir, model_name))
# 打印最终信息
print(f"Saved best epoch model: Epoch #{best_epoch}, Accuracy: {best_accuracy}")
# 记录最佳准确率
with open("./best_acc_ftcot.txt", "a") as f:
msg = f"{args.model_type}_{args.model_size} | {args.dataset_key} | seed {args.seed} | lr {args.lr} | acc: {best_accuracy}"
f.write(msg + "\n")
6.4.2 augment_train_data.py
这个脚本主要是用来通过导师模型对原始数据集样本进行推理增强。
具体步骤也是非常清晰且规范的,如下所示:
1)导包
2)定义命令行参数(#模式选择#、数据集名称、随机采样次数、多样性数量、模型类型、模型大小、模型最大输入长度、采样温度、批次大小、微调时的学习率、随机种子)
3)设置随机种子
4)检测是否有GPU可用
5)输出配置信息
6)配置模型和分词器(functions.get_model_and_tokenizer())
7)初始化评估器(evaluator.Evaluator())
8)加载预训练模型权重
9)加载原始(骨架)数据集
10)创建自定义数据集(测试集,因为我们只对原始数据进行推理操作)(dataset.FinetuneCoTDataset(Dataset))
12)创建测试集的数据加载器
13)开始推理(根据不同模式生成模型输出结果并处理生成的输出结果)
14)预处理(如果所选模型为GPT2模型,则进一步后处理生成的结果,因为 GPT2 模型生成的结果往往是长篇大论,可能包含冗余信息(如问题本身、换行符等),而且输出格式可能不规范)
15)开始评估(记录测试准确率等)
16)数据处理和保存(从输出结果中提取推理链,并按照"input"、"chain"、"completion"、"answer"、"initial_correct"的格式存储增强结果)
17)输出最终的评估结果import os, sys
sys.path.append(os.getcwd())
import copy # 导入copy模块,用于深拷贝和浅拷贝操作
import json # 导入json模块,用于处理JSON数据的编码和解码
import torch
import argparse # 导入argparse模块,用于解析命令行参数
from tqdm.auto import tqdm # 从tqdm模块导入tqdm,自动适配Notebook和终端,显示循环进度条
from torch.utils.data import DataLoader
from src.evaluator import Evaluator
from src.dataset import FinetuneCoTDataset
from src.functions import *
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument(
"--mode", choices=["diverse_reasoning", "vanilla"], default="diverse_reasoning"
) # 模式选择,'diverse_reasoning' 或 'vanilla'(前者是输出多个不同推理结果,后者是输出单个推理结果)
parser.add_argument("--dataset_key", type=str, default="strategy_qa") # 数据集的键名
parser.add_argument("--rand_sampled", type=int, default=3) # 随机采样次数
parser.add_argument("--n_diversity", type=int, default=10) # 多样性数量
parser.add_argument(
"--model_type", type=str, required=True
) # 模型类型(如'T5', 'gpt2'等)
parser.add_argument(
"--model_size", type=str, default="large"
) # 模型大小(如'small', 'medium', 'large'等)
parser.add_argument("--model_max_length", type=int, default=512) # 模型最大输入长度
parser.add_argument("--temperature", type=float, default=1.3) # 采样温度
parser.add_argument("--batch_size", type=int, default=8) # 批次大小
parser.add_argument("--ft_cot_lr", type=float, default=1e-4) # 微调时的学习率
parser.add_argument("--seed", type=int, default=42) # 随机种子
args = parser.parse_args()
# 设置随机种子,确保结果可复现
seed_everything(args.seed)
device = "cuda" if torch.cuda.is_available() else "cpu"
# ----- 打印配置参数 ----- #
print("#" * 10, "Building Augmentation", "#" * 10)
print("\n".join(f"{k.ljust(25)}:{v}" for k, v in vars(args).items()))
# ----- 配置模型和分词器 ----- #
tokenizer_kwargs = {
"padding": "longest",
"max_length": args.model_max_length,
"truncation": True,
"return_tensors": "pt",
}
# 获取模型和分词器
model, tokenizer = get_model_and_tokenizer(
model_type=args.model_type,
model_size=args.model_size,
model_max_length=args.model_max_length,
tokenizer_kwargs=tokenizer_kwargs,
device=device,
)
# 创建评估器对象
evaluator = Evaluator(args.dataset_key, task_type="ft_cot_token")
# 加载预训练模型的权重
model_params = f"logs/models/{args.mode}/{args.model_type}_{args.model_size}/{args.dataset_key}_rand{args.rand_sampled}_lr{args.ft_cot_lr}_seed{args.seed}.pt"
model.load_state_dict(torch.load(model_params))
# ---- 配置数据集 ----- %
# 加载骨架数据集,这里使用的是训练集的骨架数据
skeleton_data_path = (
f"data/skeleton/{args.dataset_key}_train.json" # 使用原始数据,忽略模式选择
)
with open(skeleton_data_path) as f:
skeleton_data = json.load(f)
# 创建Fine-tune CoT 数据集
aug_dataset = FinetuneCoTDataset(
dataset_key=args.dataset_key,
dataset_type="test", # 数据集类型为测试集
data=skeleton_data,
model_type=args.model_type,
tokenizer=tokenizer,
tokenizer_kwargs=tokenizer_kwargs,
)
# 创建数据加载器
aug_dataloader = DataLoader(aug_dataset, batch_size=args.batch_size, shuffle=False)
# 存储解码后的输出结果
outputs_to_decode = []
with torch.no_grad():
model = model.eval() # 设置模型为评估模式
tqdm_format = tqdm(
aug_dataloader,
total=len(aug_dataloader),
bar_format="{l_bar}{bar:25}{r_bar}",
desc=f"{args.dataset_key}",
ascii=True,
)
for sample in tqdm_format:
generation_kwargs = {"max_length": 512}
if "gpt" in args.model_type:
generation_kwargs["pad_token_id"] = (
tokenizer.eos_token_id
) # GPT模型的填充标记ID
if args.mode == "vanilla": # 如果是'vanilla'模式,直接生成输出
outputs = model.generate(
input_ids=sample["input_ids"].to(device), max_length=512
).detach()
outputs_to_decode.append(outputs)
elif (
args.mode == "diverse_reasoning"
): # 如果是'diverse_reasoning'模式,生成多个不同的推理结果
outputs = model.generate(
input_ids=sample["input_ids"].to(device),
max_length=512,
do_sample=True,
temperature=args.temperature, # 设置温度以控制生成的多样性
num_return_sequences=args.n_diversity,
).detach()
batch_gens = tokenizer.batch_decode(outputs, skip_special_tokens=True)
outputs_to_decode.extend(batch_gens)
# 根据模式处理生成的原始预测结果
if args.mode == "vanilla":
raw_predictions = []
for output in outputs_to_decode:
generations = tokenizer.batch_decode(
output, skip_special_tokens=True
) # 解码生成的结果
raw_predictions.extend(generations)
elif args.mode == "diverse_reasoning":
raw_predictions = outputs_to_decode
# 对于GPT2模型,进一步后处理生成的结果
if args.model_type == "gpt2":
gpt_raw_predictions = []
aug_qs = aug_dataset.formatted_texts["input"] # 获取输入问题列表
for q, p in zip(aug_qs, raw_predictions):
p = p.replace(q, "") # 去除问题部分
p = p.replace("\n", " ") # 去除换行符
# 保留推理链和预测结果,只保留第一个"-->"之后的内容
split_p = p.split("-->")
try:
chain = split_p[0].strip()
pred = split_p[1].strip()
gpt_p = f"{chain} --> {pred}"
except:
gpt_p = chain
gpt_raw_predictions.append(gpt_p)
orig_predictions = copy.deepcopy(raw_predictions) # 保留原始预测结果
raw_predictions = gpt_raw_predictions # 用后处理结果替换原始预测结果
# 准备评估
raw_answers = [
element for element in aug_dataset.raw_answers for _ in range(args.n_diversity)
] # 复制答案以匹配多样性数量
evaluations, c_preds = return_evaluations_in_boolean(
evaluator, raw_predictions, raw_answers, return_cleansed_predictions=True
)
eval_correct = evaluations.count(True)
accuracy = eval_correct / len(evaluations)
# 提取推理链
raw_chains = [
s.split("-->")[0].strip() for s in raw_predictions
] # 保留推理链部分,去掉预测结果
# ----- 存储增强数据到目录 ----- #
# 准备存储的元素
inputs = [
s["input"] for s in skeleton_data for _ in range(args.n_diversity)
] # 输入文本
answers = [
s["answer"] for s in skeleton_data for _ in range(args.n_diversity)
] # 答案文本
# 创建增强后的数据
data_to_augment = [
{
"input": inp,
"chain": str(ch),
"completion": str(comp),
"answer": ans,
"initial_correct": v,
}
for inp, ch, comp, ans, v in zip(inputs, raw_chains, c_preds, answers, evaluations)
]
# 创建保存路径
aug_dir = f"data/aug/{args.mode}/{args.model_type}_{args.model_size}"
if not os.path.exists(aug_dir):
os.makedirs(aug_dir)
# 保存增强后的数据
aug_path = os.path.join(
aug_dir, f"{args.dataset_key}_rand{args.rand_sampled}_aug{args.n_diversity}.json"
)
with open(aug_path, "w") as f:
json.dump(data_to_augment, f, indent=4)
# 输出最终的评估结果
print(
f"{args.dataset_key} || Data: {eval_correct}/{len(data_to_augment) * args.n_diversity} || Acc: {accuracy*100:.4f}"
)
6.4.3 mentor_kd.py
这个脚本主要用于推理蒸馏(训练学生模型)。
完整的流程如下所示:
1)导包
2)定义软交叉熵损失函数
3)定义隐藏层的输出的均方误差损失函数
4)定义隐藏层的注意力矩阵的均方误差损失函数
5)定义命令行参数(数据集名称、从原始数据中随机采样的数量、每个问题由导师模型生成的多样化增强样本数量、训练批次大小、测试批次大小、导师模型类型、导师模型大小、学生模型类型、学生模型大小、模型最大输入长度、温度、λ、训练轮次、微调时的学习率、学习率、随机种子、训练模式)
6)设置随机种子
7)配置日志记录器
8)检测是否有GPU可用
9)输出配置信息
10)配置导师模型和学生模型以及各自的分词器(functions.get_model_and_tokenizer())
11)加载并准备数据集(训练集(main+aug)、测试集)
12)创建自定义数据集(训练集和测试集)(dataset.FinetuneCoTDataset(Dataset))
13)创建训练集和测试集的数据加载器
14)初始化评估器(evaluator.Evaluator())
15)配置权重衰减项(不对“偏置项、层归一化层的偏置和权重”进行权重衰减(惩罚、正则化),因为它们对正则化的需求较低,对模型性能的影响较小。)
16)配置优化器参数、初始化优化器
17)开始训练(根据不同模式["vanilla", "hidden", "mse", "ce", "none"],设置不同的总损失函数)
18)开始评估(记录测试准确率等)
19)保存最佳学生模型、打印最终信息、记录最佳准确率import os, sys
sys.path.append(os.getcwd())
import copy
import json
import warnings
import argparse
import torch
import torch.nn as nn
import datasets
import numpy as np
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from tqdm.auto import tqdm
from src.dataset import FinetuneCoTDataset
from src.kd_tools import VanillaKDLoss
from src.functions import *
from src.evaluator import Evaluator
warnings.filterwarnings("ignore")
# 定义软交叉熵损失函数,用于知识蒸馏
# 输入: 模型预测值 (predicts) 和目标值 (targets)
# 返回: 平均损失值
def soft_cross_entropy(predicts, targets):
student_likelihood = torch.nn.functional.log_softmax(
predicts, dim=-1
) # 学生模型的预测值的对数概率
targets_prob = torch.nn.functional.softmax(
targets, dim=-1
) # 导师模型的预测值的概率
loss = -targets_prob * student_likelihood # 交叉熵计算公式
loss = torch.sum(loss, dim=-1) # 对最后一维求和
return loss.mean()
# 定义隐藏层的知识蒸馏方法
# 输入: 导师模型隐藏层 (teacher_reps), 学生模型隐藏层 (student_reps), 线性映射层 (linear_layer), 其他参数 (kwargs)
# 返回: 平均均方误差 (MSE) 损失
def hidden_distillation(teacher_reps, student_reps, linear_layer, kwargs):
loss_mse = torch.nn.MSELoss() # 定义均方误差损失函数
layers_per_block = int(
(len(teacher_reps) - 1) / (len(student_reps) - 1)
) # 每个块包含的层数
student_layer_num = len(student_reps) - 1 # 学生模型的隐藏层数
# 对齐导师模型的隐藏层
new_teacher_reps = [
teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)
]
new_student_reps = student_reps
rep_loss = 0.0
for student_rep, teacher_rep in zip(new_student_reps, new_teacher_reps):
# 过滤掉标签为 0 的样本(标签为 0 表示填充(padding),即该位置没有实际内容,因此不对其计算损失)
student_rep = student_rep[kwargs["labels"] != 0]
teacher_rep = teacher_rep[kwargs["labels"] != 0]
# 计算隐藏层的 MSE 损失
rep_loss += loss_mse(student_rep, linear_layer(teacher_rep))
return rep_loss
# 定义注意力机制的知识蒸馏方法
# 输入: 导师模型注意力 (teacher_atts), 学生模型注意力 (student_atts)
# 返回: 平均均方误差 (MSE) 损失
def att_distillation(teacher_atts, student_atts):
loss_mse = torch.nn.MSELoss() # 定义均方误差损失函数
layers_per_block = int(len(teacher_atts) / len(student_atts)) # 每个块包含的层数
student_layer_num = len(student_atts) # 学生模型的注意力层数
# 对齐导师模型的注意力
new_teacher_atts = [
teacher_atts[i * layers_per_block + layers_per_block - 1]
for i in range(student_layer_num)
]
att_loss = 0.0
for student_att, teacher_att in zip(student_atts, new_teacher_atts):
# 处理填充的注意力值
student_att = torch.where(
student_att <= -1e2, torch.zeros_like(student_att).to(device), student_att
) # 将注意力矩阵中小于等于 -1e2 的值替换为 0,其余值保持不变,然后将结果移动到 GPU 上,以避免梯度溢出,因为这些值不会参与计算,所以可以将其设置为 0,以减少计算量
teacher_att = torch.where(
teacher_att <= -1e2, torch.zeros_like(teacher_att).to(device), teacher_att
)
# 计算注意力的 MSE 损失
att_loss += loss_mse(student_att, teacher_att)
return att_loss
# 设置命令行参数
parser = argparse.ArgumentParser()
parser.add_argument("--dataset_key", type=str, default="tracking_shuffled_objects")
parser.add_argument(
"--rand_sampled", type=int, default=3, help="从原始数据中随机采样的数量"
)
parser.add_argument(
"--n_aug_diversity",
type=int,
default=3,
help="每个问题由导师模型生成的多样化增强样本数量",
)
parser.add_argument("--batch_size", type=int, default=8)
parser.add_argument("--test_batch_size", type=int, default=16)
parser.add_argument("--teacher_model_type", type=str, default="flan-t5")
parser.add_argument("--teacher_model_size", type=str, default="large")
parser.add_argument("--student_model_type", type=str, default="flan-t5")
parser.add_argument("--student_model_size", type=str, default="base")
parser.add_argument("--model_max_length", type=int, default=512)
parser.add_argument("--kd_temperature", type=float, default=1.0)
parser.add_argument("--kd_lambda", type=float, default=0.3)
parser.add_argument("--epoch", type=int, default=20)
parser.add_argument("--ft_cot_lr", type=float, default=3e-4)
parser.add_argument("--lr", type=float, default=3e-4)
parser.add_argument("--seed", type=int, default=42)
parser.add_argument(
"--training_mode",
choices=["vanilla", "hidden", "mse", "ce", "none"],
default="vanilla",
)
args = parser.parse_args()
# 设置随机种子
seed_everything(args.seed)
# 配置 TensorBoard 写入器
writer = SummaryWriter(
comment=f" || KD_aug || {args.teacher_model_type}_{args.teacher_model_size}_{args.student_model_type}_{args.student_model_size}_{args.dataset_key}_{args.kd_temperature}_{args.kd_lambda}_{args.seed}_{args.training_mode}"
)
device = "cuda" if torch.cuda.is_available() else "cpu"
# 打印配置信息
print("#" * 10, "Mentor-KD Reasoning Distillation", "#" * 10)
print("\n".join(f"{k.ljust(25)}:{v}" for k, v in vars(args).items()))
# ----- 配置导师模型与学生模型、分词器 -----#
tokenizer_kwargs = {
"padding": "longest",
"max_length": args.model_max_length,
"truncation": True,
"return_tensors": "pt",
} # 配置分词器参数
# 获取导师模型和分词器
teacher_model, teacher_tokenizer = get_model_and_tokenizer(
model_type=args.teacher_model_type,
model_size=args.teacher_model_size,
model_max_length=args.model_max_length,
tokenizer_kwargs=tokenizer_kwargs,
device=device,
)
# 定义导师模型的保存路径
teacher_model_path = f"logs/models/ftcot/{args.teacher_model_type}_{args.teacher_model_size}/{args.dataset_key}_rand{args.rand_sampled}_lr{args.ft_cot_lr}_seed{args.seed}.pt"
# 加载导师模型的参数
teacher_model_params = torch.load(teacher_model_path)
teacher_model.load_state_dict(teacher_model_params)
# 将导师模型的所有参数设为不可训练
for p in teacher_model.parameters():
p.requires_grad = False
# 获取学生模型和分词器
student_model, student_tokenizer = get_model_and_tokenizer(
model_type=args.student_model_type,
model_size=args.student_model_size,
model_max_length=args.model_max_length,
tokenizer_kwargs=tokenizer_kwargs,
device=device,
)
# ----- 加载并准备数据集 ----- #
train_data_path = (
f"data/main/{args.dataset_key}_{args.rand_sampled}_train.json" # 训练数据路径
)
test_data_path = f"data/main/{args.dataset_key}_test.json" # 测试数据路径
aug_data_path = f"data/aug/diverse_reasoning/{args.student_model_type}_large/{args.dataset_key}_rand{args.rand_sampled}_aug{args.n_aug_diversity}.json" # 增强数据路径
# 加载数据集
with open(train_data_path) as f_train, open(test_data_path) as f_test, open(
aug_data_path
) as f_aug:
train_json_data = json.load(f_train)
test_json_data = json.load(f_test)
aug_json_data = json.load(f_aug)
train_json_data += aug_json_data # 将增强数据添加到训练数据中
train_json_data = [
s for s in train_json_data if s["initial_correct"] == True
] # 只保留初始正确的数据
# 构建训练数据集
train_dataset = FinetuneCoTDataset(
dataset_key=args.dataset_key,
dataset_type="train",
data=train_json_data,
model_type=args.student_model_type,
tokenizer=student_tokenizer,
tokenizer_kwargs=tokenizer_kwargs,
)
# 构建测试数据集
test_dataset = FinetuneCoTDataset(
dataset_key=args.dataset_key,
dataset_type="test",
data=test_json_data,
model_type=args.student_model_type,
tokenizer=student_tokenizer,
tokenizer_kwargs=tokenizer_kwargs,
)
# 创建训练和测试数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
loss_mse = torch.nn.MSELoss() # 均方误差损失函数
test_dataloader = DataLoader(
test_dataset, batch_size=args.test_batch_size, shuffle=False
)
# 创建评估器
evaluator = Evaluator(args.dataset_key, task_type="ft_cot_token")
# 删除不必要的变量以释放内存
del train_json_data
del aug_json_data
# ----- 配置与训练相关的元素 ----- #
param_optimizer = list(student_model.named_parameters()) # 获取学生模型的所有参数
no_decay = [
"bias",
"LayerNorm.bias",
"LayerNorm.weight",
] # 不进行权重衰减的参数(偏置项、层归一化层的偏置和权重)
# 配置优化器参数
optimizer_grouped_parameters = [
{
"params": [
p for n, p in param_optimizer if not any(nd in n for nd in no_decay)
],
"weight_decay": 0.01,
}, # 需要衰减的参数
{
"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
}, # 不需要衰减的参数
]
# 使用AdamW优化器
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.lr)
kd_criterion = VanillaKDLoss(temperature=args.kd_temperature) # 知识蒸馏损失函数
# ----- 训练学生模型 ----- #
linear_layer = nn.Linear(
teacher_model.config.hidden_size, student_model.config.hidden_size
).to(device)
model_save_dir = (
f"logs/models/kd/{args.dataset_key}/{args.training_mode}" # 设置模型保存路径
)
os.makedirs(model_save_dir, exist_ok=True)
rep_loss = 0.0 # 表示重复损失
step = 0 # 训练步骤计数
best_accuracy = 0 # 最佳准确率
best_gen = [] # 最佳生成结果
# 进行多轮训练
for epoch in range(1, args.epoch + 1):
student_model = student_model.train() # 设置学生模型为训练模式
total_loss = 0.0 # 总损失初始化为0
tqdm_format = tqdm(
train_dataloader,
total=len(train_dataloader),
bar_format="{l_bar}{bar:25}{r_bar}",
desc=f"Epoch #{epoch}",
ascii=True,
)
# 遍历训练数据进行训练
for train_data in tqdm_format:
kwargs = {
"input_ids": train_data["input_ids"],
"attention_mask": train_data["attention_mask"],
"labels": train_data["labels"],
}
if "t5" in args.student_model_type:
kwargs["decoder_attention_mask"] = train_data["decoder_attention_mask"]
kwargs = {k: v.to(device) for k, v in kwargs.items()} # 将数据移到GPU上
# 使用导师模型计算输出
with torch.no_grad():
teacher_output = teacher_model(**kwargs)
teacher_logits = teacher_output["logits"] # 导师模型的logits输出
# 使用学生模型计算输出
student_outputs = student_model(**kwargs)
student_logits = student_outputs["logits"]
optimizer.zero_grad() # 清空梯度
sft_loss = student_outputs["loss"] # 学生模型的SFT损失,和硬标签的交叉熵损失值
# 计算知识蒸馏损失
student_logits = student_logits[kwargs["labels"] != 0]
teacher_logits = teacher_logits[kwargs["labels"] != 0]
kd_loss = kd_criterion(
student_logits, teacher_logits
) # 导师模型和学生模型softmax后的KL散度损失值
custom_loss = 0.0 # 自定义损失初始化为0
if args.training_mode == "hidden":
# 隐藏层蒸馏
teacher_enc_hidden = teacher_output.encoder_hidden_states
teacher_dec_hidden = teacher_output.decoder_hidden_states
student_enc_hidden = student_outputs.encoder_hidden_states
student_dec_hidden = student_outputs.decoder_hidden_states
dec_hidden_loss = hidden_distillation(
teacher_dec_hidden, student_dec_hidden, linear_layer, kwargs
)
rep_loss = dec_hidden_loss # 中间隐藏层输出的均方误差损失
custom_loss = (
rep_loss * 0.5
+ ((1 - args.kd_lambda) * sft_loss)
+ (args.kd_lambda * kd_loss)
)
elif args.training_mode == "mse":
# 使用均方误差损失
kd_loss = loss_mse(student_logits, teacher_logits)
custom_loss = ((1 - args.kd_lambda) * sft_loss) + (args.kd_lambda * kd_loss)
elif args.training_mode == "ce":
# 使用交叉熵损失
kd_loss = soft_cross_entropy(student_logits, teacher_logits)
custom_loss = kd_loss
elif args.training_mode == "vanilla":
# 使用简单的蒸馏损失
custom_loss = ((1 - args.kd_lambda) * sft_loss) + (args.kd_lambda * kd_loss)
else:
custom_loss = sft_loss
custom_loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
total_loss += custom_loss # 累加损失
step += 1
if step % 50 == 0:
# 每50步记录一次损失
writer.add_scalar(
f"{args.dataset_key}/{args.seed}/sft_loss/step", sft_loss, step
)
writer.add_scalar(
f"{args.dataset_key}/{args.seed}/kd_loss/step", kd_loss, step
)
writer.add_scalar(
f"{args.dataset_key}/{args.seed}/rep_loss/step", rep_loss, step
)
writer.add_scalar(
f"{args.dataset_key}/{args.seed}/custom_loss/step", custom_loss, step
)
# 每个epoch结束时记录一次总损失
writer.add_scalar(f"{args.dataset_key}/{args.seed}/loss/epoch", total_loss, epoch)
raw_predictions = [] # 预测结果初始化为空列表
generation_kwargs = {"max_length": 512} # 设置生成的最大长度
if "gpt" in args.student_model_type:
generation_kwargs["pad_token_id"] = student_tokenizer.eos_token_id # 设置填充符
with torch.no_grad():
# 评估阶段,使用学生模型生成结果
student_model = student_model.eval() # 设置模型为评估模式
tqdm_format = tqdm(
test_dataloader,
total=len(test_dataloader),
bar_format="{l_bar}{bar:25}{r_bar}",
desc=f"Evaluating",
ascii=True,
)
outputs_to_decode = [] # 存储解码后的输出
total_test_loss = [] # 存储测试损失
for test_samples in tqdm_format:
outputs = student_model.generate(
test_samples["input_ids"].to(device), **generation_kwargs
).detach()
outputs_to_decode.append(outputs)
raw_predictions = []
for output in outputs_to_decode:
decoded_output = student_tokenizer.batch_decode(
output, skip_special_tokens=True
) # 解码生成的输出
raw_predictions.extend(decoded_output)
raw_answers = [s["answer"] for s in test_dataset] # 获取测试集的正确答案
evaluations, c_pred = return_evaluations_in_boolean(
evaluator, raw_predictions, raw_answers, return_cleansed_predictions=True
)
accuracy = evaluations.count(True) / len(evaluations) # 计算准确率
# 如果当前准确率更好,保存最佳模型
if accuracy > best_accuracy:
best_accuracy = accuracy
best_student_model = copy.copy(student_model.state_dict())
qs = [s["input"] for s in test_dataset] # 获取测试集中的问题
current_best_gen = []
for i in range(len(qs)):
instance = dict()
instance["input"] = qs[i]
instance["chain"] = raw_predictions[i]
instance["completion"] = c_pred[i]
instance["answer"] = raw_answers[i]
current_best_gen.append(instance)
best_gen = current_best_gen
print(
f"{args.dataset_key} || TEST Epoch #{epoch} accuracy: {accuracy} || Current Best: {best_accuracy}"
)
# 清理GPU缓存
torch.cuda.empty_cache()
# ----- 保存最佳学生模型 ----- #
student_model_name = f"{args.teacher_model_type}_{args.teacher_model_size}_{args.student_model_type}_{args.student_model_size}_rand{args.rand_sampled}_aug{args.n_aug_diversity}_lr{args.lr}_kd_temperature{args.kd_temperature}_kd_lambda{args.kd_lambda}_seed{args.seed}.pt"
student_model_save_path = os.path.join(model_save_dir, student_model_name)
torch.save(best_student_model, student_model_save_path)
# ---- 保存最佳epoch的生成结果 ----- #
gen_save_dir = f"logs/gen_outputs/kd/{args.dataset_key}" # 设置生成结果保存路径
os.makedirs(gen_save_dir, exist_ok=True)
gen_save_name = f"{args.teacher_model_type}_{args.teacher_model_size}_{args.student_model_type}_{args.student_model_size}_rand{args.rand_sampled}_aug{args.n_aug_diversity}_seed{args.seed}.json"
with open(os.path.join(gen_save_dir, gen_save_name), "w") as f:
json.dump(best_gen, f, indent=4) # 保存最佳生成结果
print(f"Saved best generation result on {args.dataset_key}.")
# ---- 方便的日志记录 ---- #
with open("./best_acc_kd.txt", "a") as f:
msg = f"{args.student_model_type}-{args.student_model_size} | {args.dataset_key} | seed_{args.seed} | kd_{args.kd_temperature}_{args.kd_lambda} | lr_{args.ft_cot_lr}_{args.lr} | acc: {best_accuracy}"
f.write(msg + "\n")
writer.flush() # 刷新日志
writer.close() # 关闭日志
注意,这里重点介绍一下training_mode这个超参数
首先来看一下以下几个损失值:
sft_loss = student_outputs["loss"] # 学生模型的SFT损失,和硬标签的交叉熵损失值;
kd_loss = kd_criterion(student_logits, teacher_logits) # 导师模型和学生模型softmax后的KL散度损失值。
然后我们来看一下training_mode设置为不同值时custom_loss是如何计算得到的:
1)"vanilla"时
# 使用简单的蒸馏损失
custom_loss = ((1 - args.kd_lambda) * sft_loss) + (args.kd_lambda * kd_loss)
2)"hidden"时:
# 中间隐藏层输出的均方误差损失
rep_loss = dec_hidden_loss
custom_loss = (
rep_loss * 0.5
+ ((1 - args.kd_lambda) * sft_loss)
+ (args.kd_lambda * kd_loss)
)
3)"mse"时:
# 使用均方误差损失取代KL散度损失
kd_loss = loss_mse(student_logits, teacher_logits)
custom_loss = ((1 - args.kd_lambda) * sft_loss) + (args.kd_lambda * kd_loss)
4)"ce"时:
# 使用交叉熵损失取代KL散度损失
kd_loss = soft_cross_entropy(student_logits, teacher_logits)
custom_loss = kd_loss
5)"none"时:
# 只使用和硬标签的交叉熵损失值
custom_loss = sft_loss
6.5 shells文件夹剖析
以下3个文件都是用于执行scripts文件夹下3个同名文件的sh脚本。
具体而言,在之前单纯设置argparse.ArgumentParser后需要在命令行手动输入传入参数的值。而使用 sh 脚本(即 Shell 脚本)来运行 Python 脚本,可以一次性定义好所有参数,避免重复输入,大大提高了实验的效率、可复现性和可维护性。
6.5.1 fine_tune_cot.sh
#!/bin/bash
# 设置脚本解释器为 Bash
set -e
# 启用错误检测模式,若脚本中任意命令返回非零状态(表示错误),脚本会立即退出
# 定义随机种子,确保实验结果的可复现性
seed=42
# 定义训练的轮数
epochs=20
# 定义要使用的 GPU 设备编号(0 表示第一张 GPU)
device=0
# 设置环境变量 CUDA_VISIBLE_DEVICES,用于指定使用的 GPU 设备
# 执行 fine_tune_cot.py 脚本,对模型进行微调
CUDA_VISIBLE_DEVICES=${device} python scripts/fine_tune_cot/fine_tune_cot.py \
--dataset_key tracking_shuffled_objects \
# 指定使用的数据集键,表示用于训练的具体任务或数据集
--num_random_selection 3 \
# 随机选择的样本数,用于指定一些数据采样策略
--batch_size 8 \
# 训练时使用的批量大小,每次输入的样本数量为 8
--model_type flan-t5 \
# 指定模型的类型,这里是 flan-t5 模型
--model_size small \
# 指定模型的规模,这里选择的是小型版本(small)
--test_batch_size 16 \
# 测试时使用的批量大小,每次输入的样本数量为 16
--epoch ${epochs} \
# 指定训练的总轮数,这里通过变量 epochs 传入值 20
--lr 0.0003 \
# 设置学习率,用于控制优化器参数更新的步长
--seed ${seed}
# 指定随机种子值,通过变量 seed 传入值 42
6.5.2 augment_train_data.sh
#!/bin/bash
set -e # 如果脚本中某个命令出错,立即退出脚本执行
# T5 模型的学习率字典
declare -A t5_lr_dict # 声明一个关联数组,用于存储 T5 模型的不同数据集对应的学习率
declare -A flant5_lr_dict # 声明一个关联数组,用于存储 Flan-T5 模型的不同数据集对应的学习率
# 为 T5 模型设置每个数据集的学习率
t5_lr_dict["asdiv"]=0.0001 # 数据集 asdiv 的学习率为 0.0001
t5_lr_dict["svamp"]=0.0003 # 数据集 svamp 的学习率为 0.0003
t5_lr_dict["last_letter_concatenation"]=0.0001 # 数据集 last_letter_concatenation 的学习率为 0.0001
t5_lr_dict["date_understanding"]=0.0002 # 数据集 date_understanding 的学习率为 0.0002
t5_lr_dict["commonsense_qa"]=0.0001 # 数据集 commonsense_qa 的学习率为 0.0001
t5_lr_dict["tracking_shuffled_objects"]=0.0002 # 数据集 tracking_shuffled_objects 的学习率为 0.0002
t5_lr_dict["strategy_qa"]=0.0001 # 数据集 strategy_qa 的学习率为 0.0001
# 为 Flan-T5 模型设置每个数据集的学习率
flant5_lr_dict["asdiv"]=0.0001 # 数据集 asdiv 的学习率为 0.0001
flant5_lr_dict["svamp"]=0.0001 # 数据集 svamp 的学习率为 0.0001
flant5_lr_dict["last_letter_concatenation"]=0.0002 # 数据集 last_letter_concatenation 的学习率为 0.0002
flant5_lr_dict["commonsense_qa"]=0.0001 # 数据集 commonsense_qa 的学习率为 0.0001
flant5_lr_dict["date_understanding"]=0.0001 # 数据集 date_understanding 的学习率为 0.0001
flant5_lr_dict["tracking_shuffled_objects"]=0.0001 # 数据集 tracking_shuffled_objects 的学习率为 0.0001
flant5_lr_dict["strategy_qa"]=0.0001 # 数据集 strategy_qa 的学习率为 0.0001
device=0 # 设置 GPU 的设备编号为 0
# 遍历所有的数据集键
for dataset_key in ${dataset_keys[@]}
do
# 使用指定的 CUDA 设备运行数据增强脚本
CUDA_VISIBLE_DEVICES=${device} python scripts/data/augment_train_data.py \
--mode diverse_reasoning \ # 数据增强的模式为多样化推理
--dataset_key ${dataset_key} \ # 当前运行的数据集键
--batch_size 16 \ # 数据增强的批量大小为 16
--rand_sampled 3 \ # 随机采样的数量为 3
--n_diversity 3 \ # 生成多样化数据的数量为 3
--temperature 0.7 \ # 生成数据的温度参数设置为 0.7
--model_type flan-t5 \ # 使用 Flan-T5 模型进行数据增强
--ft_cot_lr ${flant5_lr_dict[${dataset_key}]} # 读取 Flan-T5 模型对应数据集的学习率
done
6.5.3 mentor_kd.sh
#!/bin/bash
set -e # 如果脚本中某个命令出错,则立即退出脚本执行
# 设置基础参数
device=0 # 设置 GPU 的设备编号为 0
seed=42 # 设置随机数种子为 42,确保实验可复现
epochs=20 # 设置训练的轮数为 20
dataset_key="tracking_shuffled_objects" # 设置数据集的键为 "tracking_shuffled_objects"
# 定义 Flan-T5 模型的学习率字典
declare -A flant5_lr_dict # 声明一个关联数组用于存储 Flan-T5 模型的学习率
flant5_lr_dict["tracking_shuffled_objects"]=0.0001 # 为 "tracking_shuffled_objects" 数据集设置学习率为 0.0001
# 使用指定的 GPU 和参数运行知识蒸馏脚本
CUDA_VISIBLE_DEVICES=${device} python scripts/kd/mentor_kd.py \
--training_mode vanilla \ # 设置训练模式为 "vanilla"(基本训练模式)
--dataset_key $dataset_key \ # 指定训练使用的数据集键
--rand_sampled 3 \ # 设置随机采样的数量为 3
--n_aug_diversity 3 \ # 设置增强数据的多样性为 3
--teacher_model_type flan-t5 \ # 指定教师模型类型为 Flan-T5
--teacher_model_size large \ # 指定教师模型的大小为 "large"
--student_model_type flan-t5 \ # 指定学生模型类型为 Flan-T5
--student_model_size small \ # 指定学生模型的大小为 "small"
--batch_size 8 \ # 设置训练的批量大小为 8
--test_batch_size 16 \ # 设置测试的批量大小为 16
--epoch ${epochs} \ # 指定训练的轮数
--seed 42 \ # 指定随机种子,确保训练的可重复性
--kd_temperature 2.0 \ # 知识蒸馏的温度参数为 2.0
--kd_lambda 0.3 \ # 知识蒸馏的损失函数中蒸馏部分的权重为 0.3
--ft_cot_lr ${flant5_lr_dict[$dataset_key]} \ # 从字典中读取当前数据集的学习率
--lr 0.0002 # 设置学生模型的优化器学习率为 0.0002
6.6 mcckd文件夹剖析
如表2和表3所示,作者同时对比了Vanilla-KD(代码中有,scripts\data\augment_train_data.py中的模式选择,'diverse_reasoning' 或 'vanilla'(前者是输出多个不同推理结果,后者是输出单个推理结果))以及MCC-KD方法。该文件夹实现的就是MCC-KD方法(直接copy的MCC-KD项目源码),由于没了解过这个论文,所以这块就不再展开介绍,感兴趣的可以参见下方链接:
论文链接:2310.14747
源码链接:homzer/MCC-KD
7 总结
7.1 整体思路
其实整个框架的流程已经如论文的图1所示非常清晰了:
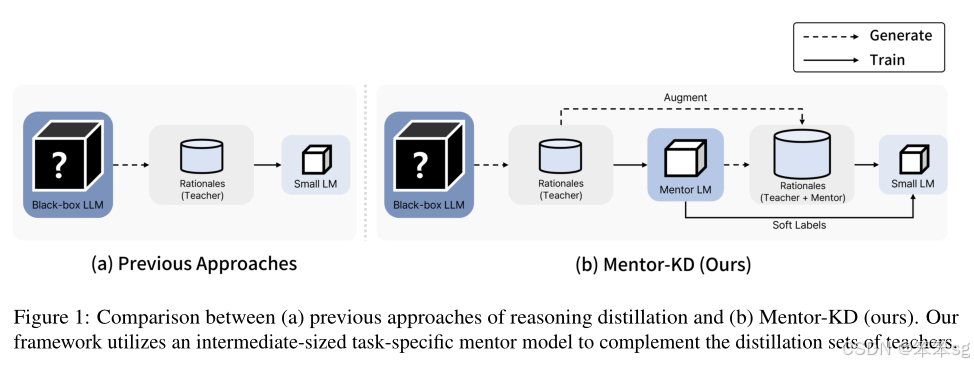
下面,我再画一幅流程图帮助大家理解,从左下角看起即可。
整体而言,这篇论文创新性地引入了一个导师模型,使得框架由传统的“老师-学生”扩展为“老师-导师-学生”的三层架构。其中,导师模型作为中转站发挥了重要作用。具体而言,论文通过原始的多任务大语言模型(LLM)训练出一个专精于特定任务的导师模型,导师模型进一步对原始数据集进行丰富扩充,并将其输出与LLM模型的结果拼接,生成一个增强版的数据集。
接下来,老师在这个框架中就没啥用了,你现在可以将”导师“视为传统架构中的“老师”,后续执行的是一样的操作来训练学生模型。由于导师模型专注于特定任务,提供了更具针对性的指导,同时扩充后的数据集提升了模型训练的多样性和质量,使得整体性能得到了显著提升。
7.2 遗留的2个问题
好了,现在我们已经充分理解了这篇论文,无论是整体的框架还是代码。除了作者在”4.5 Limitations(局限性) “中提到的那些问题外,目前留在我心里的还有两个疑问:
1)这个是我们之前就提到过的问题:教师模型生成的预测如果与黄金标签不匹配会被丢弃,而正如论文引言所提到的,GPT-3.5在StrategyQA数据集上的推理准确率仅为58%,这意味着可能会有大量QA对被舍弃。如果蒸馏数据集规模过小,能否支持训练出一个高质量的导师模型?是否有方法对这些预测错误的样本进行二次利用,以进一步提升模型性能?
2)我们了解到整体流程是”用数据集A通过LLM推理生成数据集B,训练导师模型后,A再经过导师生成数据集C,最终将B和C拼接形成新的数据集“。然而,由于C是导师基于A生成的,如果导师对A的处理过于简单或生成规则过于类似B,可能导致B和C之间冗余性高,甚至引入噪声。虽然导师模型经过微调从泛化模型变为专精模型,这确实可能提升对A的处理质量,但仅通过简单拼接B和C是否合理?是否需要设计更复杂的合并策略,以确保数据增量和互补性?
如果你对这些问题有什么想法,欢迎在评论区交流探讨!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









