







RNNs是很受欢迎的模型,在处理 NLP 任务方面很有前景。
结构
典型的RNN 全连接网络结构如下图所示:
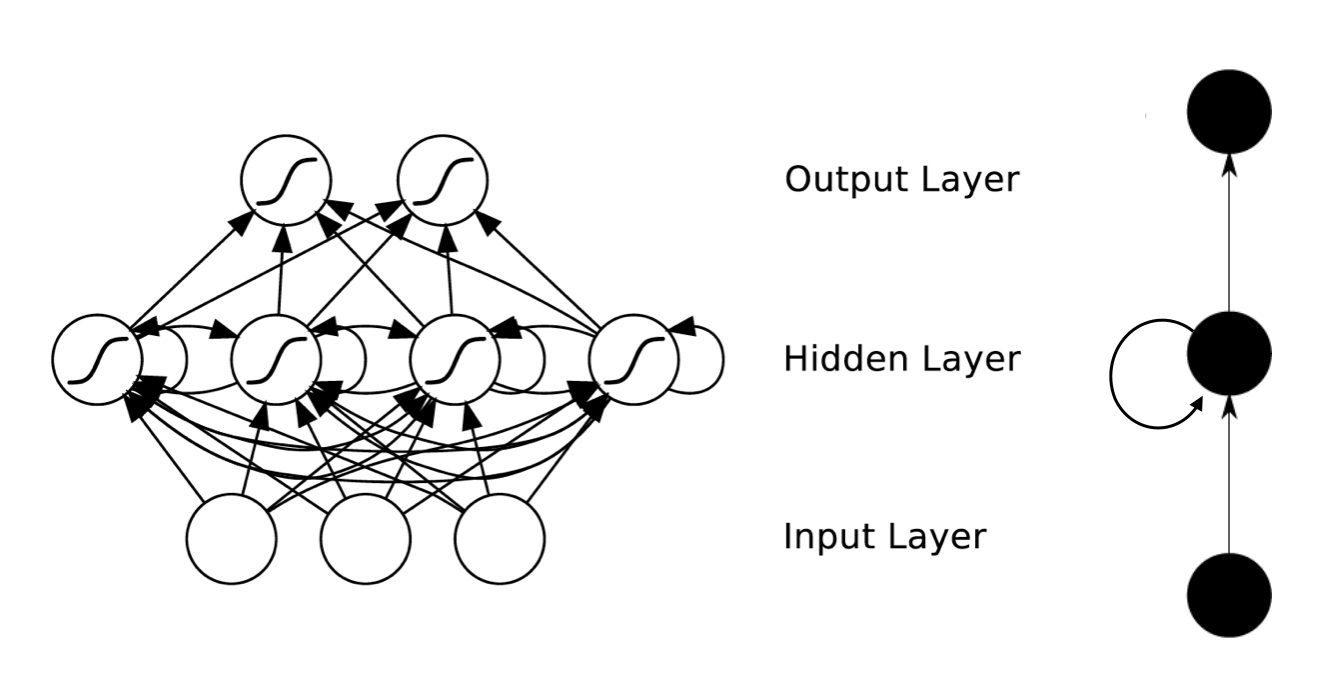
右边是对左边的结构的简单描述。
进一步可以描述为:
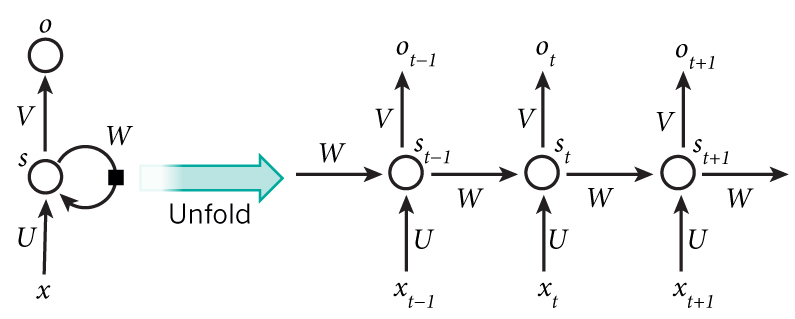
在上图中,
xt
是在 t 时间序列时刻的输入,例如:
x1
可以是 one-hot 向量对应的句子的第二个词。
st 是 隐藏层在时间步t的状态。是网络的记忆模块memory。
ot 是在时间步t 的输出。例如,想要预测句子中的下一个词,它的值将是字典中所有词的概率的向量。
根据上图流程,可知计算公式:
f 一般为tanh,ReLU
注: RNN 的 W,U,V 参数都是相同的。
对于记忆模块 st ,可以查看其记忆过程:
s1=f(Ux1+Ws0)
s2=f(Ux2+Ws1)=f(Ux2+Wf(Ux1+Ws0))
s3=f(Ux3+Ws2)=f(Ux3+Wf(Ux2+Wf(Ux1+Ws0)))
s4=f(Ux4+Ws3)=f(Ux4+Wf(Ux3+Wf(Ux2+Wf(Ux1+Ws0))))
假设
f(x)=x
, 上式可以写为:
s4=f(Ux3+Ws3)=Ux4+WUx3+W2Ux2+W3Ux1+W4s0
依次类推,可以知道,时间序列中,越早的输入与隐藏层状态前的权值 W 的幂次越大。也就是说存在如下两种情况:
1,
2 , W>1 (或者 f′>1 ),与上面情况相反,早先的序列值与状态对后面的影响越大。对权值求导后,影响还是类似,这种情况被称为梯度爆炸问题。
训练
跟传统的神经网络一样,使用方向传播算法进行训练。但是有一点不同,每一时间步的计算都会使用到前一步中的参数结果,如上式中所表示,这被称为Backpropagation Through Time (BPTT). 由于存在梯度消失/爆炸的问题,使用BPTT训练RNN 在学习长期依赖问题。目前存在一些方法来解决这个问题,看例如LSTM。
参考文章:
RNN
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









